 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Pass Low Latency End-to-End Spoken Language Understanding
Jul 14, 2022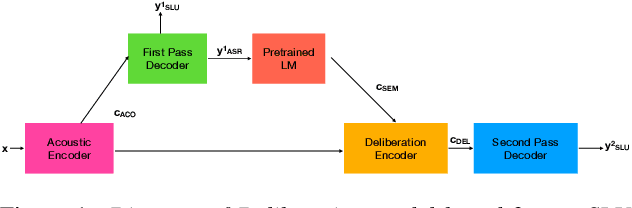
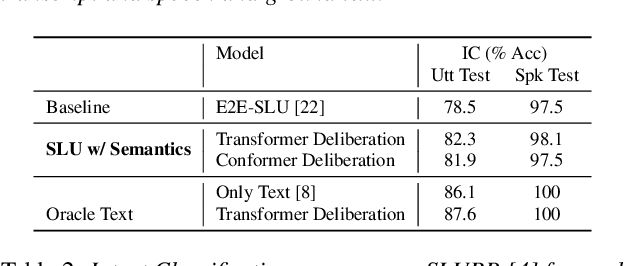

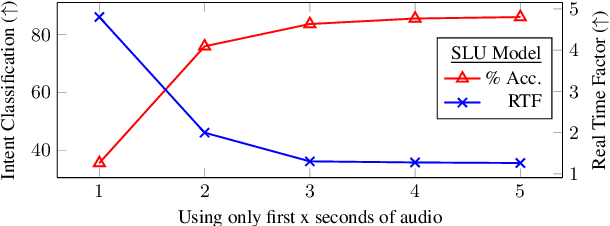
End-to-end (E2E) models are becoming increasingly popular for spoken language understanding (SLU) systems and are beginning to achieve competitive performance to pipeline-based approaches. However, recent work has shown that these models struggle to generalize to new phrasings for the same intent indicating that models cannot understand the semantic content of the given utterance. In this work, we incorporated language models pre-trained on unlabeled text data inside E2E-SLU frameworks to build strong semantic representations. Incorporating both semantic and acoustic information can increase the inference time, leading to high latency when deployed for applications like voice assistants. We developed a 2-pass SLU system that makes low latency prediction using acoustic information from the few seconds of the audio in the first pass and makes higher quality prediction in the second pass by combining semantic and acoustic representations. We take inspiration from prior work on 2-pass end-to-end speech recognition systems that attends on both audio and first-pass hypothesis using a deliberation network. The proposed 2-pass SLU system outperforms the acoustic-based SLU model on the Fluent Speech Commands Challenge Set and SLURP dataset and reduces latency, thus improving user experience. Our code and models are publicly available as part of the ESPnet-SLU toolkit.
Branchformer: Parallel MLP-Attention Architectures to Capture Local and Global Context for Speech Recognition and Understanding
Jul 06, 2022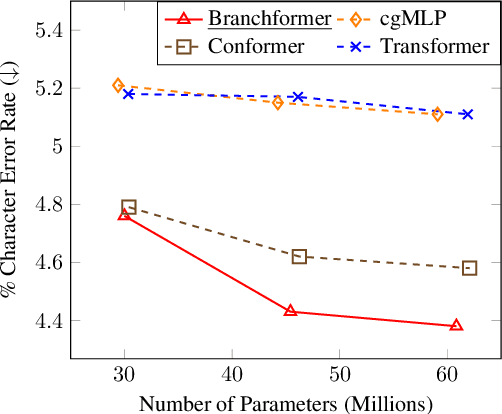
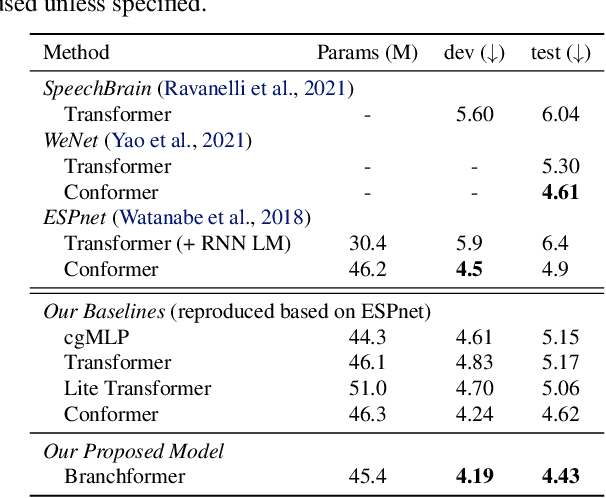
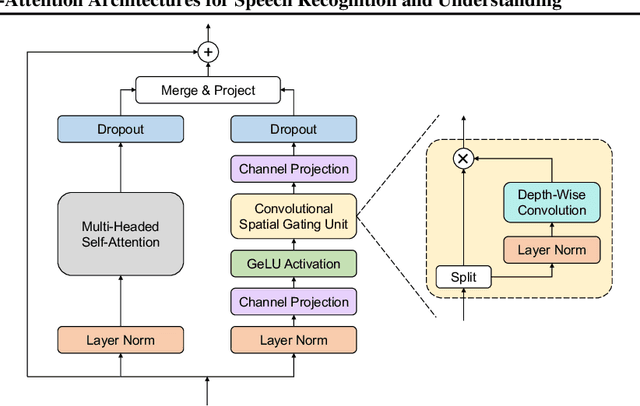
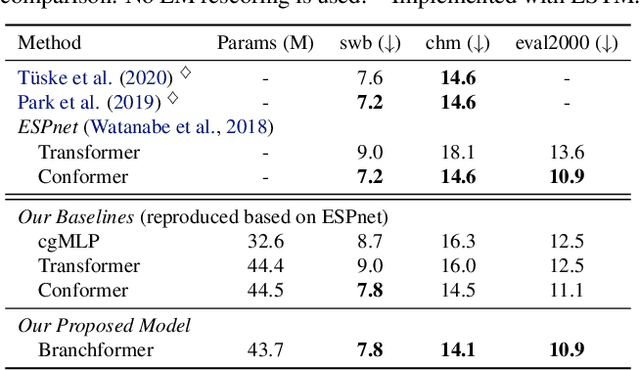
Conformer has proven to be effective in many speech processing tasks. It combines the benefits of extracting local dependencies using convolutions and global dependencies using self-attention. Inspired by this, we propose a more flexible, interpretable and customizable encoder alternative, Branchformer, with parallel branches for modeling various ranged dependencies in end-to-end speech processing. In each encoder layer, one branch employs self-attention or its variant to capture long-range dependencies, while the other branch utilizes an MLP module with convolutional gating (cgMLP) to extract local relationships. We conduct experiments on several speech recognition and spoken language understanding benchmarks. Results show that our model outperforms both Transformer and cgMLP. It also matches with or outperforms state-of-the-art results achieved by Conformer. Furthermore, we show various strategies to reduce computation thanks to the two-branch architecture, including the ability to have variable inference complexity in a single trained model. The weights learned for merging branches indicate how local and global dependencies are utilized in different layers, which benefits model designing.
LegoNN: Building Modular Encoder-Decoder Models
Jun 07, 2022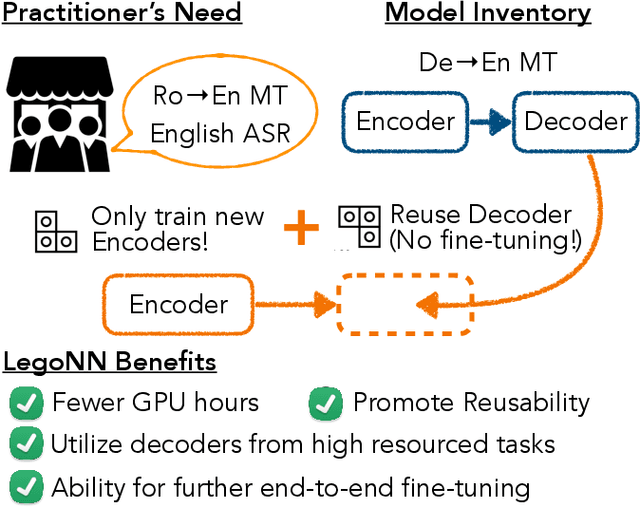
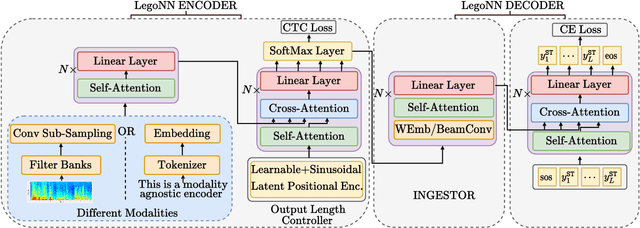
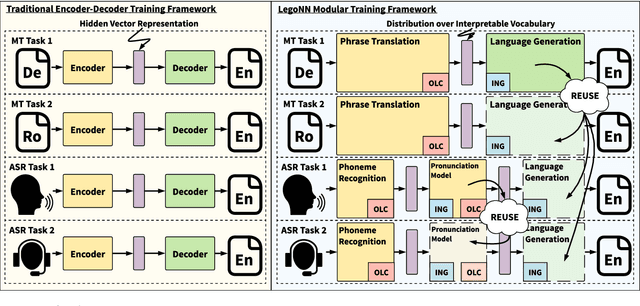
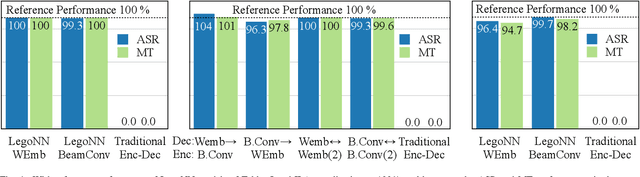
State-of-the-art encoder-decoder models (e.g. for machine translation (MT) or speech recognition (ASR)) are constructed and trained end-to-end as an atomic unit. No component of the model can be (re-)used without the others. We describe LegoNN, a procedure for building encoder-decoder architectures with decoder modules that can be reused across various MT and ASR tasks, without the need for any fine-tuning. To achieve reusability, the interface between each encoder and decoder modules is grounded to a sequence of marginal distributions over a discrete vocabulary pre-defined by the model designer. We present two approaches for ingesting these marginals; one is differentiable, allowing the flow of gradients across the entire network, and the other is gradient-isolating. To enable portability of decoder modules between MT tasks for different source languages and across other tasks like ASR, we introduce a modality agnostic encoder which consists of a length control mechanism to dynamically adapt encoders' output lengths in order to match the expected input length range of pre-trained decoders. We present several experiments to demonstrate the effectiveness of LegoNN models: a trained language generation LegoNN decoder module from German-English (De-En) MT task can be reused with no fine-tuning for the Europarl English ASR and the Romanian-English (Ro-En) MT tasks to match or beat respective baseline models. When fine-tuned towards the target task for few thousand updates, our LegoNN models improved the Ro-En MT task by 1.5 BLEU points, and achieved 12.5% relative WER reduction for the Europarl ASR task. Furthermore, to show its extensibility, we compose a LegoNN ASR model from three modules -- each has been learned within different end-to-end trained models on three different datasets -- boosting the WER reduction to 19.5%.
FLEURS: Few-shot Learning Evaluation of Universal Representations of Speech
May 25, 2022
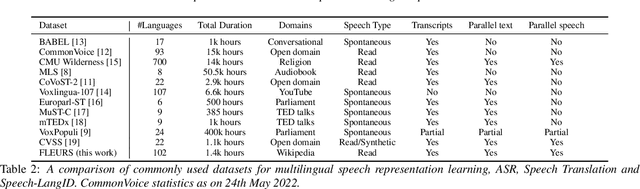
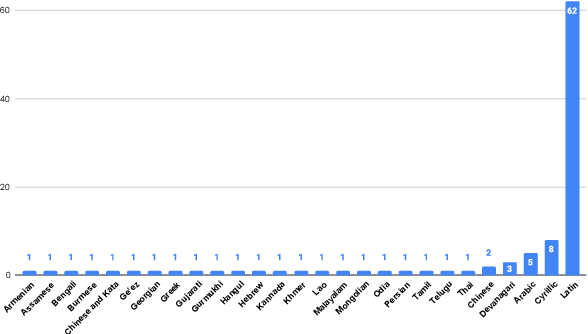
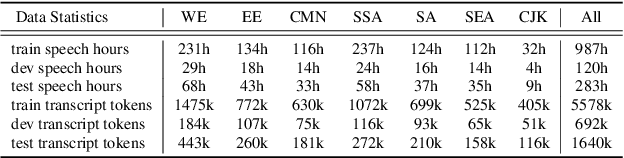
We introduce FLEURS, the Few-shot Learning Evaluation of Universal Representations of Speech benchmark. FLEURS is an n-way parallel speech dataset in 102 languages built on top of the machine translation FLoRes-101 benchmark, with approximately 12 hours of speech supervision per language. FLEURS can be used for a variety of speech tasks, including Automatic Speech Recognition (ASR), Speech Language Identification (Speech LangID), Translation and Retrieval. In this paper, we provide baselines for the tasks based on multilingual pre-trained models like mSLAM. The goal of FLEURS is to enable speech technology in more languages and catalyze research in low-resource speech understanding.
Joint Modeling of Code-Switched and Monolingual ASR via Conditional Factorization
Nov 29, 2021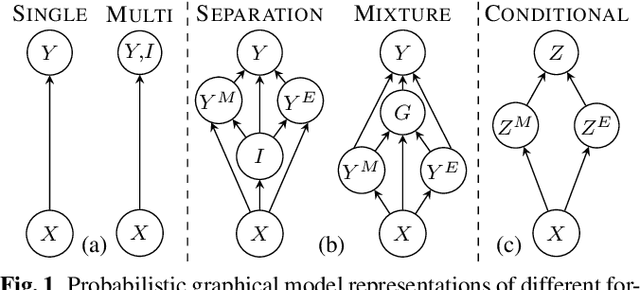
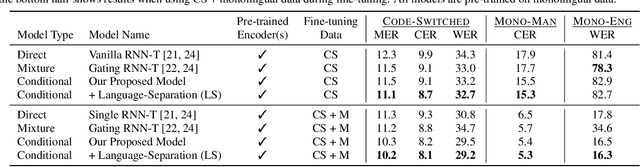
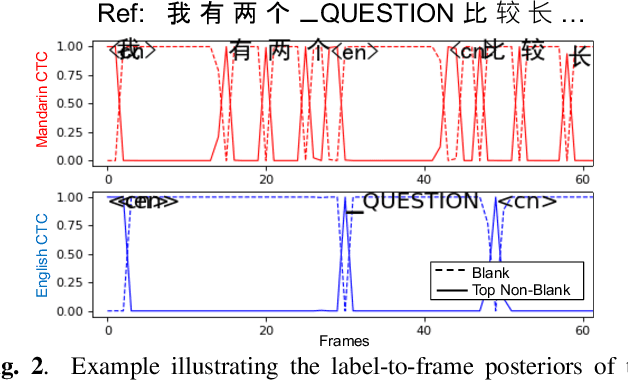
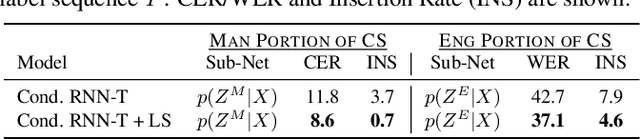
Conversational bilingual speech encompasses three types of utterances: two purely monolingual types and one intra-sententially code-switched type. In this work, we propose a general framework to jointly model the likelihoods of the monolingual and code-switch sub-tasks that comprise bilingual speech recognition. By defining the monolingual sub-tasks with label-to-frame synchronization, our joint modeling framework can be conditionally factorized such that the final bilingual output, which may or may not be code-switched, is obtained given only monolingual information. We show that this conditionally factorized joint framework can be modeled by an end-to-end differentiable neural network. We demonstrate the efficacy of our proposed model on bilingual Mandarin-English speech recognition across both monolingual and code-switched corpora.
ESPnet-SLU: Advancing Spoken Language Understanding through ESPnet
Nov 29, 2021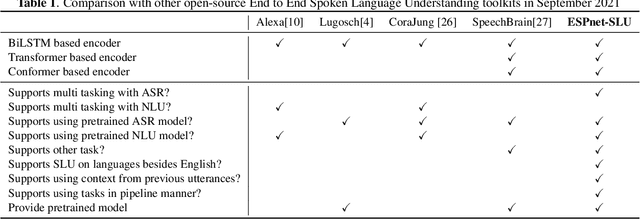
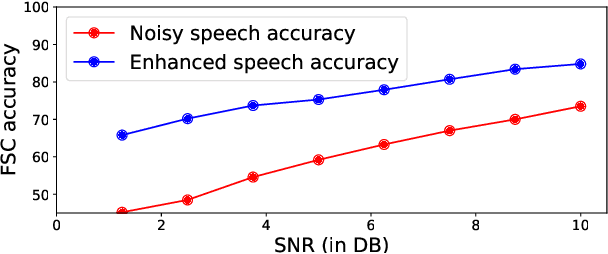
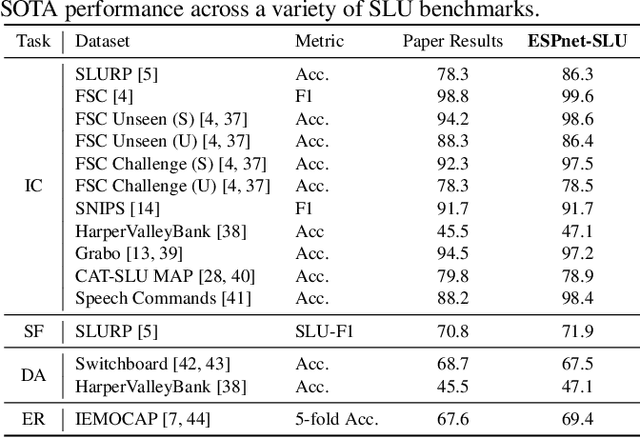

As Automatic Speech Processing (ASR) systems are getting better, there is an increasing interest of using the ASR output to do downstream Natural Language Processing (NLP) tasks. However, there are few open source toolkits that can be used to generate reproducible results on different Spoken Language Understanding (SLU) benchmarks. Hence, there is a need to build an open source standard that can be used to have a faster start into SLU research. We present ESPnet-SLU, which is designed for quick development of spoken language understanding in a single framework. ESPnet-SLU is a project inside end-to-end speech processing toolkit, ESPnet, which is a widely used open-source standard for various speech processing tasks like ASR, Text to Speech (TTS) and Speech Translation (ST). We enhance the toolkit to provide implementations for various SLU benchmarks that enable researchers to seamlessly mix-and-match different ASR and NLU models. We also provide pretrained models with intensively tuned hyper-parameters that can match or even outperform the current state-of-the-art performances. The toolkit is publicly available at https://github.com/espnet/espnet.
Fast-MD: Fast Multi-Decoder End-to-End Speech Translation with Non-Autoregressive Hidden Intermediates
Sep 27, 2021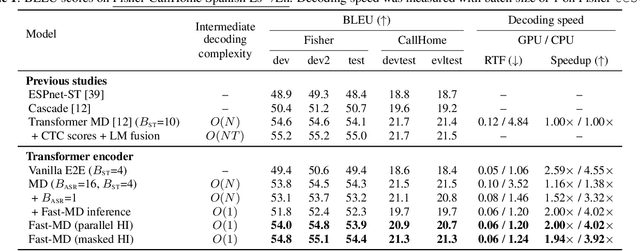
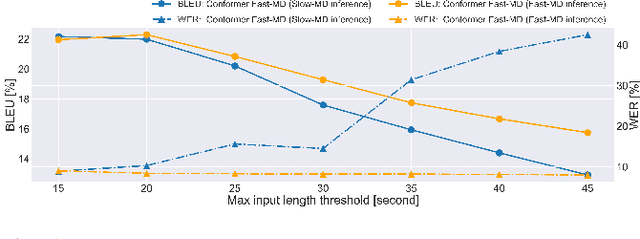
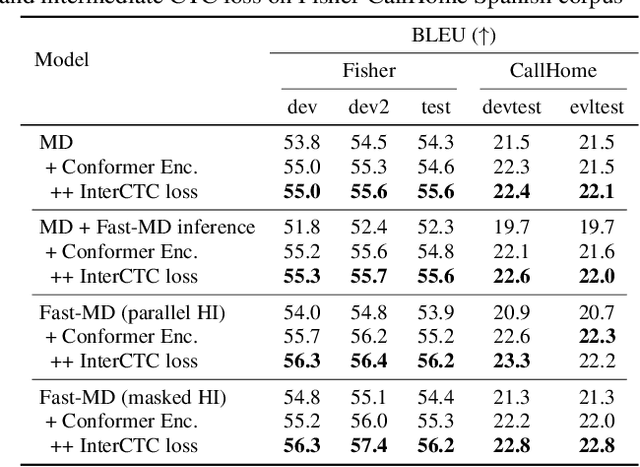
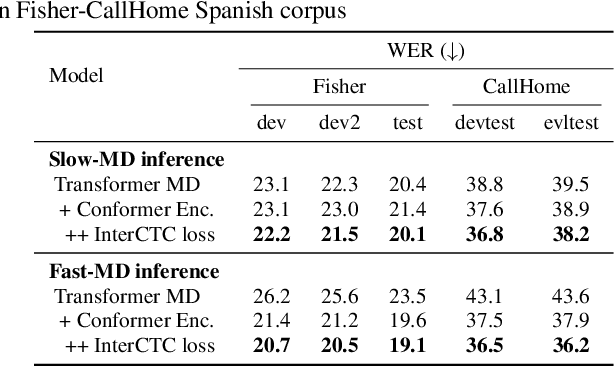
The multi-decoder (MD) end-to-end speech translation model has demonstrated high translation quality by searching for better intermediate automatic speech recognition (ASR) decoder states as hidden intermediates (HI). It is a two-pass decoding model decomposing the overall task into ASR and machine translation sub-tasks. However, the decoding speed is not fast enough for real-world applications because it conducts beam search for both sub-tasks during inference. We propose Fast-MD, a fast MD model that generates HI by non-autoregressive (NAR) decoding based on connectionist temporal classification (CTC) outputs followed by an ASR decoder. We investigated two types of NAR HI: (1) parallel HI by using an autoregressive Transformer ASR decoder and (2) masked HI by using Mask-CTC, which combines CTC and the conditional masked language model. To reduce a mismatch in the ASR decoder between teacher-forcing during training and conditioning on CTC outputs during testing, we also propose sampling CTC outputs during training. Experimental evaluations on three corpora show that Fast-MD achieved about 2x and 4x faster decoding speed than that of the na\"ive MD model on GPU and CPU with comparable translation quality. Adopting the Conformer encoder and intermediate CTC loss further boosts its quality without sacrificing decoding speed.
Differentiable Allophone Graphs for Language-Universal Speech Recognition
Jul 24, 2021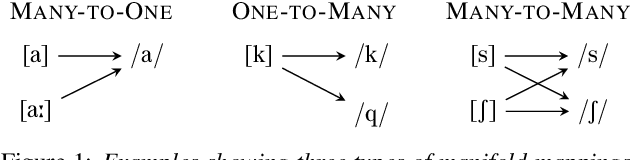

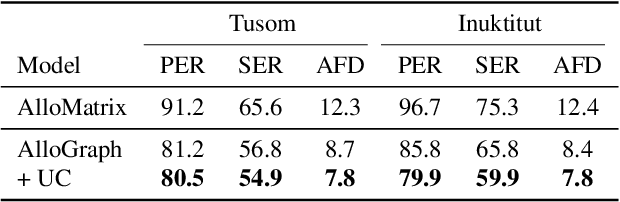
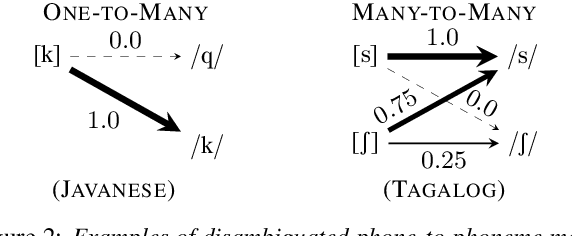
Building language-universal speech recognition systems entails producing phonological units of spoken sound that can be shared across languages. While speech annotations at the language-specific phoneme or surface levels are readily available, annotations at a universal phone level are relatively rare and difficult to produce. In this work, we present a general framework to derive phone-level supervision from only phonemic transcriptions and phone-to-phoneme mappings with learnable weights represented using weighted finite-state transducers, which we call differentiable allophone graphs. By training multilingually, we build a universal phone-based speech recognition model with interpretable probabilistic phone-to-phoneme mappings for each language. These phone-based systems with learned allophone graphs can be used by linguists to document new languages, build phone-based lexicons that capture rich pronunciation variations, and re-evaluate the allophone mappings of seen language. We demonstrate the aforementioned benefits of our proposed framework with a system trained on 7 diverse languages.
ESPnet-ST IWSLT 2021 Offline Speech Translation System
Jul 06, 2021
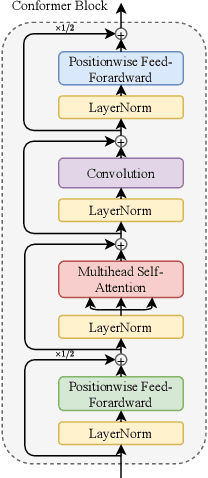
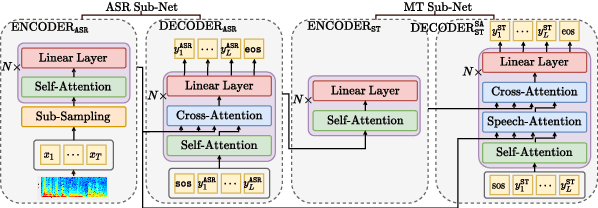
This paper describes the ESPnet-ST group's IWSLT 2021 submission in the offline speech translation track. This year we made various efforts on training data, architecture, and audio segmentation. On the data side, we investigated sequence-level knowledge distillation (SeqKD) for end-to-end (E2E) speech translation. Specifically, we used multi-referenced SeqKD from multiple teachers trained on different amounts of bitext. On the architecture side, we adopted the Conformer encoder and the Multi-Decoder architecture, which equips dedicated decoders for speech recognition and translation tasks in a unified encoder-decoder model and enables search in both source and target language spaces during inference. We also significantly improved audio segmentation by using the pyannote.audio toolkit and merging multiple short segments for long context modeling. Experimental evaluations showed that each of them contributed to large improvements in translation performance. Our best E2E system combined all the above techniques with model ensembling and achieved 31.4 BLEU on the 2-ref of tst2021 and 21.2 BLEU and 19.3 BLEU on the two single references of tst2021.
Rethinking End-to-End Evaluation of Decomposable Tasks: A Case Study on Spoken Language Understanding
Jun 29, 2021
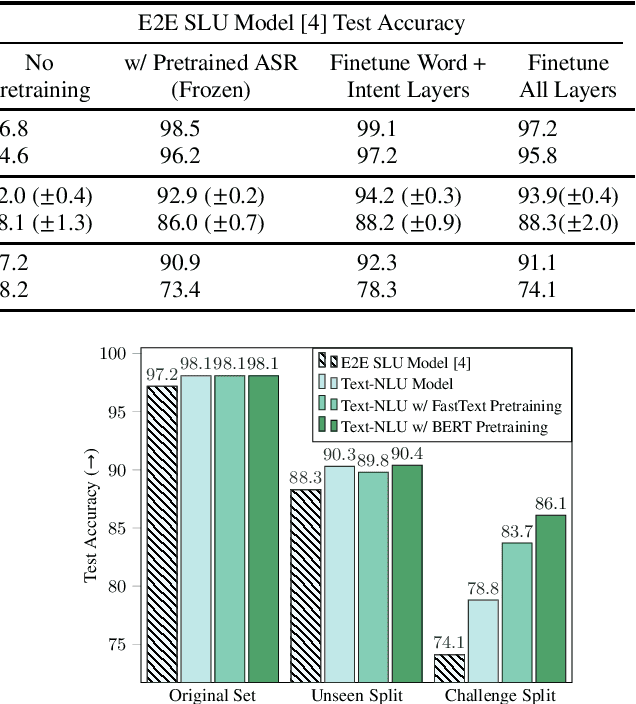
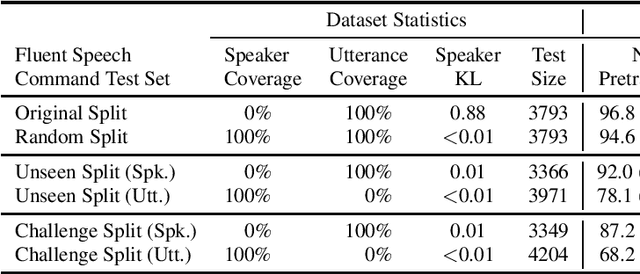

Decomposable tasks are complex and comprise of a hierarchy of sub-tasks. Spoken intent prediction, for example, combines automatic speech recognition and natural language understanding. Existing benchmarks, however, typically hold out examples for only the surface-level sub-task. As a result, models with similar performance on these benchmarks may have unobserved performance differences on the other sub-tasks. To allow insightful comparisons between competitive end-to-end architectures, we propose a framework to construct robust test sets using coordinate ascent over sub-task specific utility functions. Given a dataset for a decomposable task, our method optimally creates a test set for each sub-task to individually assess sub-components of the end-to-end model. Using spoken language understanding as a case study, we generate new splits for the Fluent Speech Commands and Snips SmartLights datasets. Each split has two test sets: one with held-out utterances assessing natural language understanding abilities, and one with held-out speakers to test speech processing skills. Our splits identify performance gaps up to 10% between end-to-end systems that were within 1% of each other on the original test sets. These performance gaps allow more realistic and actionable comparisons between different architectures, driving future model development. We release our splits and tools for the community.