 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow ChatGPT is Solving Vulnerability Management Problem
Nov 11, 2023



Recently, ChatGPT has attracted great attention from the code analysis domain. Prior works show that ChatGPT has the capabilities of processing foundational code analysis tasks, such as abstract syntax tree generation, which indicates the potential of using ChatGPT to comprehend code syntax and static behaviors. However, it is unclear whether ChatGPT can complete more complicated real-world vulnerability management tasks, such as the prediction of security relevance and patch correctness, which require an all-encompassing understanding of various aspects, including code syntax, program semantics, and related manual comments. In this paper, we explore ChatGPT's capabilities on 6 tasks involving the complete vulnerability management process with a large-scale dataset containing 78,445 samples. For each task, we compare ChatGPT against SOTA approaches, investigate the impact of different prompts, and explore the difficulties. The results suggest promising potential in leveraging ChatGPT to assist vulnerability management. One notable example is ChatGPT's proficiency in tasks like generating titles for software bug reports. Furthermore, our findings reveal the difficulties encountered by ChatGPT and shed light on promising future directions. For instance, directly providing random demonstration examples in the prompt cannot consistently guarantee good performance in vulnerability management. By contrast, leveraging ChatGPT in a self-heuristic way -- extracting expertise from demonstration examples itself and integrating the extracted expertise in the prompt is a promising research direction. Besides, ChatGPT may misunderstand and misuse the information in the prompt. Consequently, effectively guiding ChatGPT to focus on helpful information rather than the irrelevant content is still an open problem.
Facial Data Minimization: Shallow Model as Your Privacy Filter
Oct 24, 2023



Face recognition service has been used in many fields and brings much convenience to people. However, once the user's facial data is transmitted to a service provider, the user will lose control of his/her private data. In recent years, there exist various security and privacy issues due to the leakage of facial data. Although many privacy-preserving methods have been proposed, they usually fail when they are not accessible to adversaries' strategies or auxiliary data. Hence, in this paper, by fully considering two cases of uploading facial images and facial features, which are very typical in face recognition service systems, we proposed a data privacy minimization transformation (PMT) method. This method can process the original facial data based on the shallow model of authorized services to obtain the obfuscated data. The obfuscated data can not only maintain satisfactory performance on authorized models and restrict the performance on other unauthorized models but also prevent original privacy data from leaking by AI methods and human visual theft. Additionally, since a service provider may execute preprocessing operations on the received data, we also propose an enhanced perturbation method to improve the robustness of PMT. Besides, to authorize one facial image to multiple service models simultaneously, a multiple restriction mechanism is proposed to improve the scalability of PMT. Finally, we conduct extensive experiments and evaluate the effectiveness of the proposed PMT in defending against face reconstruction, data abuse, and face attribute estimation attacks. These experimental results demonstrate that PMT performs well in preventing facial data abuse and privacy leakage while maintaining face recognition accuracy.
CP-BCS: Binary Code Summarization Guided by Control Flow Graph and Pseudo Code
Oct 24, 2023Automatically generating function summaries for binaries is an extremely valuable but challenging task, since it involves translating the execution behavior and semantics of the low-level language (assembly code) into human-readable natural language. However, most current works on understanding assembly code are oriented towards generating function names, which involve numerous abbreviations that make them still confusing. To bridge this gap, we focus on generating complete summaries for binary functions, especially for stripped binary (no symbol table and debug information in reality). To fully exploit the semantics of assembly code, we present a control flow graph and pseudo code guided binary code summarization framework called CP-BCS. CP-BCS utilizes a bidirectional instruction-level control flow graph and pseudo code that incorporates expert knowledge to learn the comprehensive binary function execution behavior and logic semantics. We evaluate CP-BCS on 3 different binary optimization levels (O1, O2, and O3) for 3 different computer architectures (X86, X64, and ARM). The evaluation results demonstrate CP-BCS is superior and significantly improves the efficiency of reverse engineering.
F$^2$AT: Feature-Focusing Adversarial Training via Disentanglement of Natural and Perturbed Patterns
Oct 23, 2023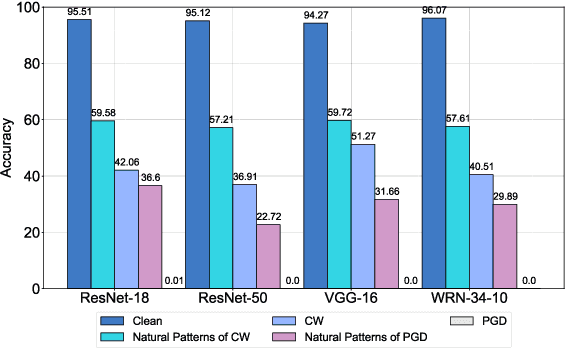

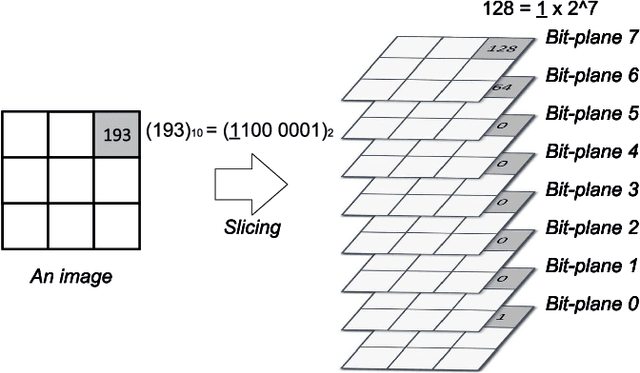
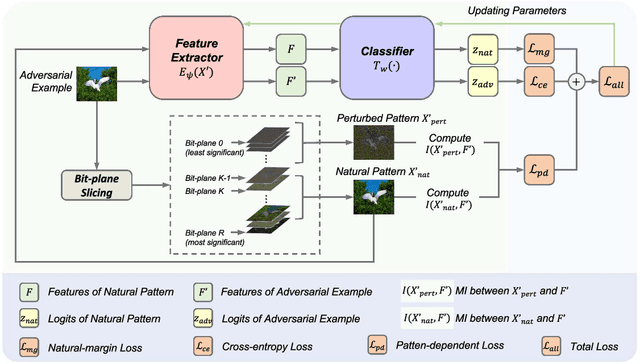
Deep neural networks (DNNs) are vulnerable to adversarial examples crafted by well-designed perturbations. This could lead to disastrous results on critical applications such as self-driving cars, surveillance security, and medical diagnosis. At present, adversarial training is one of the most effective defenses against adversarial examples. However, traditional adversarial training makes it difficult to achieve a good trade-off between clean accuracy and robustness since spurious features are still learned by DNNs. The intrinsic reason is that traditional adversarial training makes it difficult to fully learn core features from adversarial examples when adversarial noise and clean examples cannot be disentangled. In this paper, we disentangle the adversarial examples into natural and perturbed patterns by bit-plane slicing. We assume the higher bit-planes represent natural patterns and the lower bit-planes represent perturbed patterns, respectively. We propose a Feature-Focusing Adversarial Training (F$^2$AT), which differs from previous work in that it enforces the model to focus on the core features from natural patterns and reduce the impact of spurious features from perturbed patterns. The experimental results demonstrated that F$^2$AT outperforms state-of-the-art methods in clean accuracy and adversarial robustness.
Defending Pre-trained Language Models as Few-shot Learners against Backdoor Attacks
Sep 23, 2023



Pre-trained language models (PLMs) have demonstrated remarkable performance as few-shot learners. However, their security risks under such settings are largely unexplored. In this work, we conduct a pilot study showing that PLMs as few-shot learners are highly vulnerable to backdoor attacks while existing defenses are inadequate due to the unique challenges of few-shot scenarios. To address such challenges, we advocate MDP, a novel lightweight, pluggable, and effective defense for PLMs as few-shot learners. Specifically, MDP leverages the gap between the masking-sensitivity of poisoned and clean samples: with reference to the limited few-shot data as distributional anchors, it compares the representations of given samples under varying masking and identifies poisoned samples as ones with significant variations. We show analytically that MDP creates an interesting dilemma for the attacker to choose between attack effectiveness and detection evasiveness. The empirical evaluation using benchmark datasets and representative attacks validates the efficacy of MDP.
Efficient Query-Based Attack against ML-Based Android Malware Detection under Zero Knowledge Setting
Sep 06, 2023The widespread adoption of the Android operating system has made malicious Android applications an appealing target for attackers. Machine learning-based (ML-based) Android malware detection (AMD) methods are crucial in addressing this problem; however, their vulnerability to adversarial examples raises concerns. Current attacks against ML-based AMD methods demonstrate remarkable performance but rely on strong assumptions that may not be realistic in real-world scenarios, e.g., the knowledge requirements about feature space, model parameters, and training dataset. To address this limitation, we introduce AdvDroidZero, an efficient query-based attack framework against ML-based AMD methods that operates under the zero knowledge setting. Our extensive evaluation shows that AdvDroidZero is effective against various mainstream ML-based AMD methods, in particular, state-of-the-art such methods and real-world antivirus solutions.
ORL-AUDITOR: Dataset Auditing in Offline Deep Reinforcement Learning
Sep 06, 2023



Data is a critical asset in AI, as high-quality datasets can significantly improve the performance of machine learning models. In safety-critical domains such as autonomous vehicles, offline deep reinforcement learning (offline DRL) is frequently used to train models on pre-collected datasets, as opposed to training these models by interacting with the real-world environment as the online DRL. To support the development of these models, many institutions make datasets publicly available with opensource licenses, but these datasets are at risk of potential misuse or infringement. Injecting watermarks to the dataset may protect the intellectual property of the data, but it cannot handle datasets that have already been published and is infeasible to be altered afterward. Other existing solutions, such as dataset inference and membership inference, do not work well in the offline DRL scenario due to the diverse model behavior characteristics and offline setting constraints. In this paper, we advocate a new paradigm by leveraging the fact that cumulative rewards can act as a unique identifier that distinguishes DRL models trained on a specific dataset. To this end, we propose ORL-AUDITOR, which is the first trajectory-level dataset auditing mechanism for offline RL scenarios. Our experiments on multiple offline DRL models and tasks reveal the efficacy of ORL-AUDITOR, with auditing accuracy over 95% and false positive rates less than 2.88%. We also provide valuable insights into the practical implementation of ORL-AUDITOR by studying various parameter settings. Furthermore, we demonstrate the auditing capability of ORL-AUDITOR on open-source datasets from Google and DeepMind, highlighting its effectiveness in auditing published datasets. ORL-AUDITOR is open-sourced at https://github.com/link-zju/ORL-Auditor.
Tram: A Token-level Retrieval-augmented Mechanism for Source Code Summarization
May 18, 2023



Automatically generating human-readable text describing the functionality of a program is the intent of source code summarization. Although Neural Language Models achieve significant performance in this field, an emerging trend is combining neural models with external knowledge. Most previous approaches rely on the sentence-level retrieval and combination paradigm (retrieval of similar code snippets and use of the corresponding code and summary pairs) on the encoder side. However, this paradigm is coarse-grained and cannot directly take advantage of the high-quality retrieved summary tokens on the decoder side. In this paper, we explore a fine-grained token-level retrieval-augmented mechanism on the decoder side to help the vanilla neural model generate a better code summary. Furthermore, to mitigate the limitation of token-level retrieval on capturing contextual code semantics, we propose to integrate code semantics into summary tokens. Extensive experiments and human evaluation reveal that our token-level retrieval-augmented approach significantly improves performance and is more interpretive.
On the Security Risks of Knowledge Graph Reasoning
May 03, 2023



Knowledge graph reasoning (KGR) -- answering complex logical queries over large knowledge graphs -- represents an important artificial intelligence task, entailing a range of applications (e.g., cyber threat hunting). However, despite its surging popularity, the potential security risks of KGR are largely unexplored, which is concerning, given the increasing use of such capability in security-critical domains. This work represents a solid initial step towards bridging the striking gap. We systematize the security threats to KGR according to the adversary's objectives, knowledge, and attack vectors. Further, we present ROAR, a new class of attacks that instantiate a variety of such threats. Through empirical evaluation in representative use cases (e.g., medical decision support, cyber threat hunting, and commonsense reasoning), we demonstrate that ROAR is highly effective to mislead KGR to suggest pre-defined answers for target queries, yet with negligible impact on non-target ones. Finally, we explore potential countermeasures against ROAR, including filtering of potentially poisoning knowledge and training with adversarially augmented queries, which leads to several promising research directions.
Deep Intellectual Property: A Survey
Apr 28, 2023With the widespread application in industrial manufacturing and commercial services, well-trained deep neural networks (DNNs) are becoming increasingly valuable and crucial assets due to the tremendous training cost and excellent generalization performance. These trained models can be utilized by users without much expert knowledge benefiting from the emerging ''Machine Learning as a Service'' (MLaaS) paradigm. However, this paradigm also exposes the expensive models to various potential threats like model stealing and abuse. As an urgent requirement to defend against these threats, Deep Intellectual Property (DeepIP), to protect private training data, painstakingly-tuned hyperparameters, or costly learned model weights, has been the consensus of both industry and academia. To this end, numerous approaches have been proposed to achieve this goal in recent years, especially to prevent or discover model stealing and unauthorized redistribution. Given this period of rapid evolution, the goal of this paper is to provide a comprehensive survey of the recent achievements in this field. More than 190 research contributions are included in this survey, covering many aspects of Deep IP Protection: challenges/threats, invasive solutions (watermarking), non-invasive solutions (fingerprinting), evaluation metrics, and performance. We finish the survey by identifying promising directions for future research.