 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-distilled Knowledge Delegator for Exemplar-free Class Incremental Learning
May 23, 2022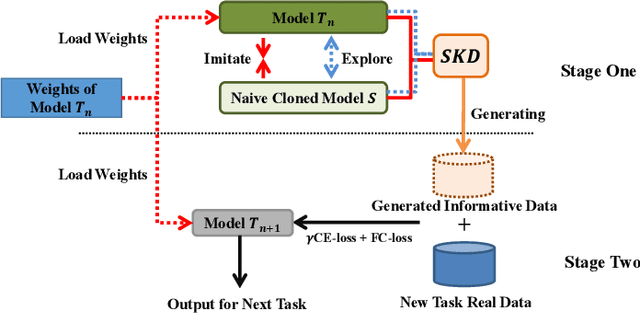
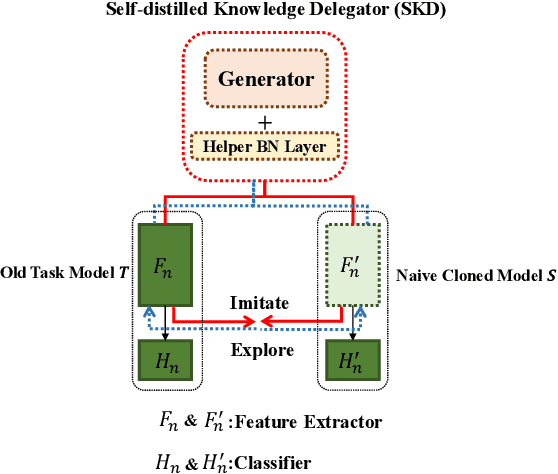
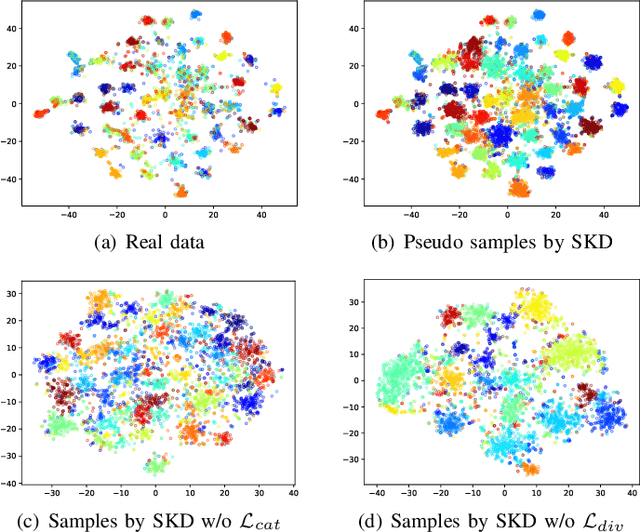
Exemplar-free incremental learning is extremely challenging due to inaccessibility of data from old tasks. In this paper, we attempt to exploit the knowledge encoded in a previously trained classification model to handle the catastrophic forgetting problem in continual learning. Specifically, we introduce a so-called knowledge delegator, which is capable of transferring knowledge from the trained model to a randomly re-initialized new model by generating informative samples. Given the previous model only, the delegator is effectively learned using a self-distillation mechanism in a data-free manner. The knowledge extracted by the delegator is then utilized to maintain the performance of the model on old tasks in incremental learning. This simple incremental learning framework surpasses existing exemplar-free methods by a large margin on four widely used class incremental benchmarks, namely CIFAR-100, ImageNet-Subset, Caltech-101 and Flowers-102. Notably, we achieve comparable performance to some exemplar-based methods without accessing any exemplars.
Weakly Supervised Regional and Temporal Learning for Facial Action Unit Recognition
Apr 01, 2022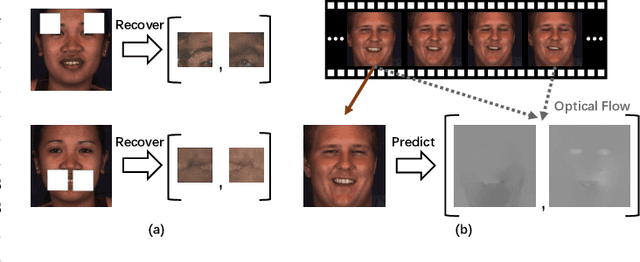
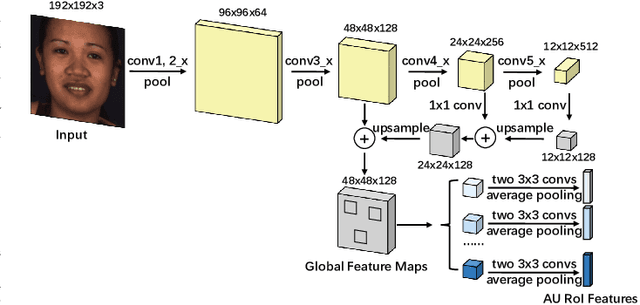
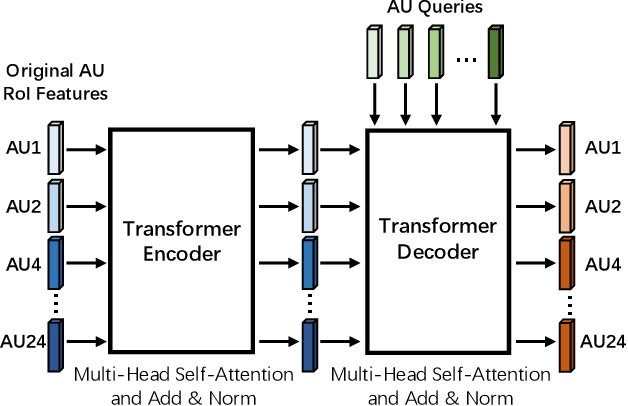
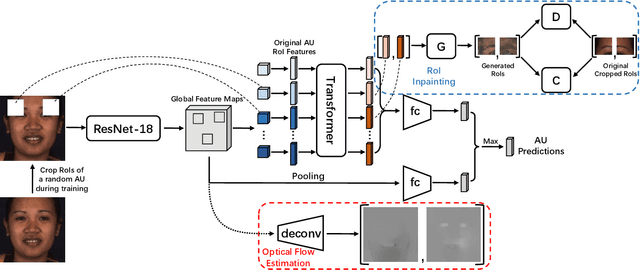
Automatic facial action unit (AU) recognition is a challenging task due to the scarcity of manual annotations. To alleviate this problem, a large amount of efforts has been dedicated to exploiting various weakly supervised methods which leverage numerous unlabeled data. However, many aspects with regard to some unique properties of AUs, such as the regional and relational characteristics, are not sufficiently explored in previous works. Motivated by this, we take the AU properties into consideration and propose two auxiliary AU related tasks to bridge the gap between limited annotations and the model performance in a self-supervised manner via the unlabeled data. Specifically, to enhance the discrimination of regional features with AU relation embedding, we design a task of RoI inpainting to recover the randomly cropped AU patches. Meanwhile, a single image based optical flow estimation task is proposed to leverage the dynamic change of facial muscles and encode the motion information into the global feature representation. Based on these two self-supervised auxiliary tasks, local features, mutual relation and motion cues of AUs are better captured in the backbone network. Furthermore, by incorporating semi-supervised learning, we propose an end-to-end trainable framework named weakly supervised regional and temporal learning (WSRTL) for AU recognition. Extensive experiments on BP4D and DISFA demonstrate the superiority of our method and new state-of-the-art performances are achieved.
Few-shot One-class Domain Adaptation Based on Frequency for Iris Presentation Attack Detection
Apr 01, 2022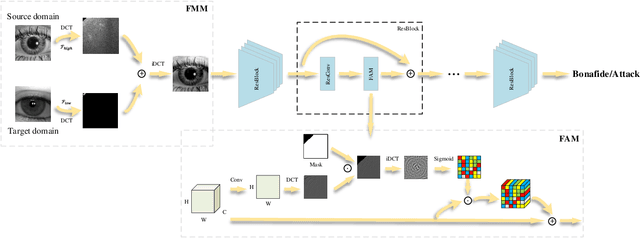
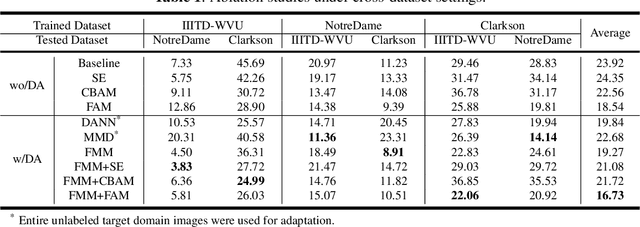
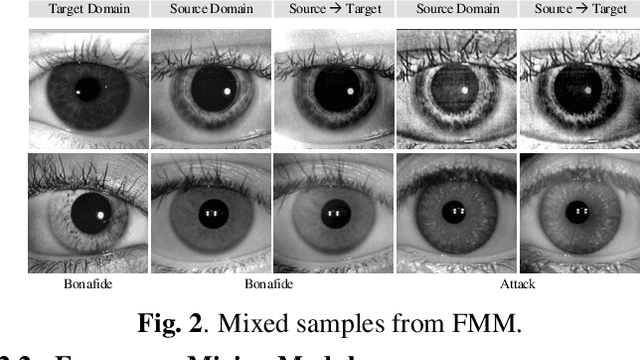
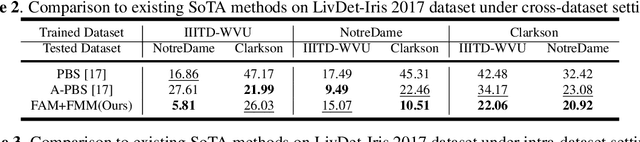
Iris presentation attack detection (PAD) has achieved remarkable success to ensure the reliability and security of iris recognition systems. Most existing methods exploit discriminative features in the spatial domain and report outstanding performance under intra-dataset settings. However, the degradation of performance is inevitable under cross-dataset settings, suffering from domain shift. In consideration of real-world applications, a small number of bonafide samples are easily accessible. We thus define a new domain adaptation setting called Few-shot One-class Domain Adaptation (FODA), where adaptation only relies on a limited number of target bonafide samples. To address this problem, we propose a novel FODA framework based on the expressive power of frequency information. Specifically, our method integrates frequency-related information through two proposed modules. Frequency-based Attention Module (FAM) aggregates frequency information into spatial attention and explicitly emphasizes high-frequency fine-grained features. Frequency Mixing Module (FMM) mixes certain frequency components to generate large-scale target-style samples for adaptation with limited target bonafide samples. Extensive experiments on LivDet-Iris 2017 dataset demonstrate the proposed method achieves state-of-the-art or competitive performance under both cross-dataset and intra-dataset settings.
Unimodal-Concentrated Loss: Fully Adaptive Label Distribution Learning for Ordinal Regression
Apr 01, 2022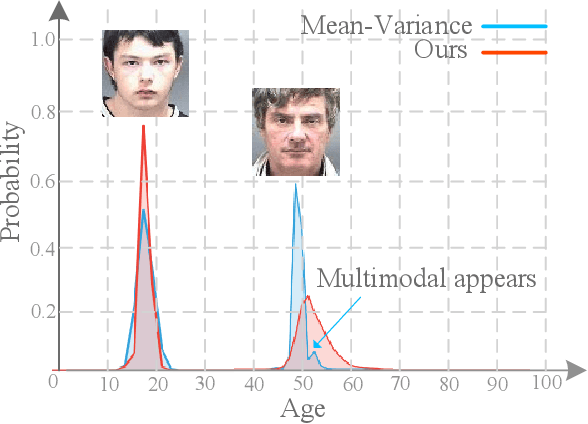
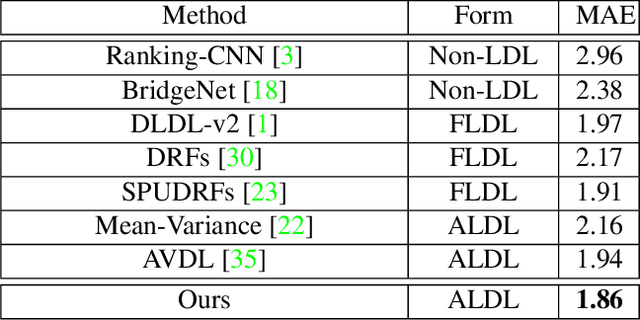
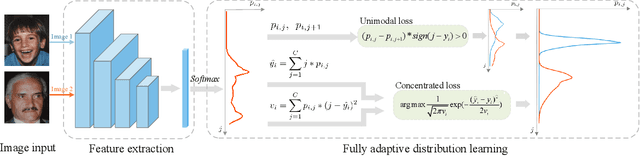
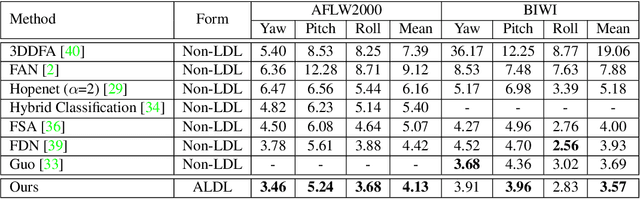
Learning from a label distribution has achieved promising results on ordinal regression tasks such as facial age and head pose estimation wherein, the concept of adaptive label distribution learning (ALDL) has drawn lots of attention recently for its superiority in theory. However, compared with the methods assuming fixed form label distribution, ALDL methods have not achieved better performance. We argue that existing ALDL algorithms do not fully exploit the intrinsic properties of ordinal regression. In this paper, we emphatically summarize that learning an adaptive label distribution on ordinal regression tasks should follow three principles. First, the probability corresponding to the ground-truth should be the highest in label distribution. Second, the probabilities of neighboring labels should decrease with the increase of distance away from the ground-truth, i.e., the distribution is unimodal. Third, the label distribution should vary with samples changing, and even be distinct for different instances with the same label, due to the different levels of difficulty and ambiguity. Under the premise of these principles, we propose a novel loss function for fully adaptive label distribution learning, namely unimodal-concentrated loss. Specifically, the unimodal loss derived from the learning to rank strategy constrains the distribution to be unimodal. Furthermore, the estimation error and the variance of the predicted distribution for a specific sample are integrated into the proposed concentrated loss to make the predicted distribution maximize at the ground-truth and vary according to the predicting uncertainty. Extensive experimental results on typical ordinal regression tasks including age and head pose estimation, show the superiority of our proposed unimodal-concentrated loss compared with existing loss functions.
End-to-End Modeling via Information Tree for One-Shot Natural Language Spatial Video Grounding
Mar 15, 2022
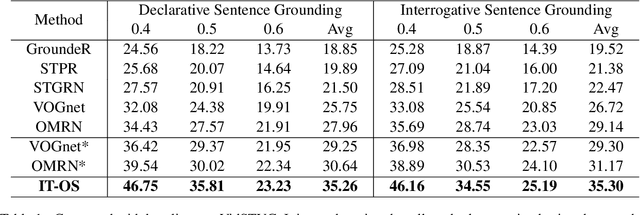
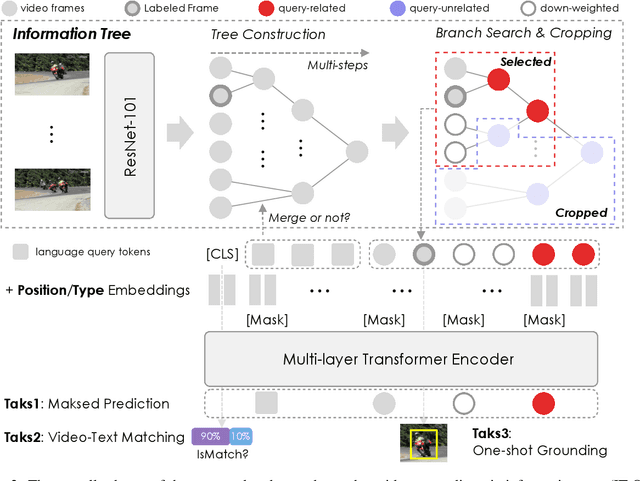
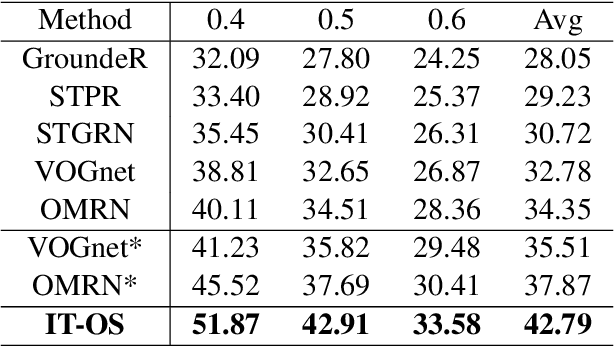
Natural language spatial video grounding aims to detect the relevant objects in video frames with descriptive sentences as the query. In spite of the great advances, most existing methods rely on dense video frame annotations, which require a tremendous amount of human effort. To achieve effective grounding under a limited annotation budget, we investigate one-shot video grounding, and learn to ground natural language in all video frames with solely one frame labeled, in an end-to-end manner. One major challenge of end-to-end one-shot video grounding is the existence of videos frames that are either irrelevant to the language query or the labeled frames. Another challenge relates to the limited supervision, which might result in ineffective representation learning. To address these challenges, we designed an end-to-end model via Information Tree for One-Shot video grounding (IT-OS). Its key module, the information tree, can eliminate the interference of irrelevant frames based on branch search and branch cropping techniques. In addition, several self-supervised tasks are proposed based on the information tree to improve the representation learning under insufficient labeling. Experiments on the benchmark dataset demonstrate the effectiveness of our model.
Forward Compatible Few-Shot Class-Incremental Learning
Mar 14, 2022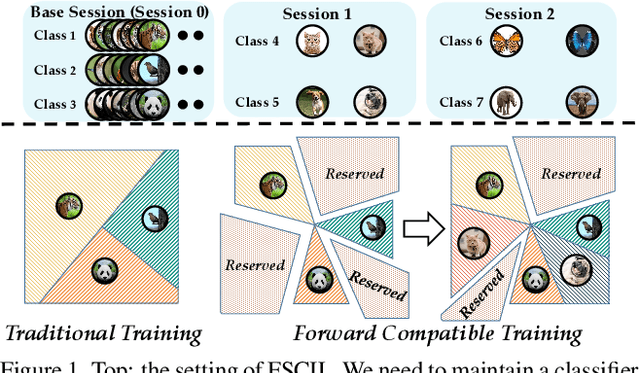
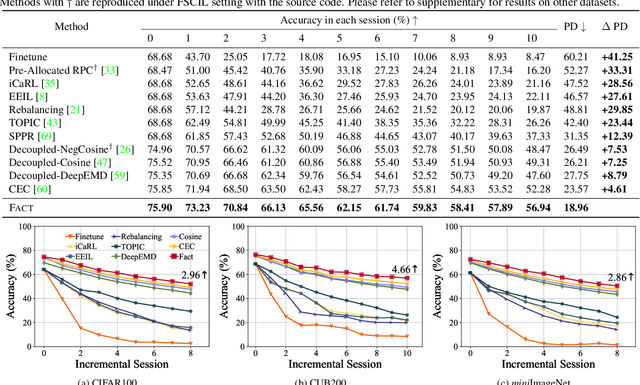
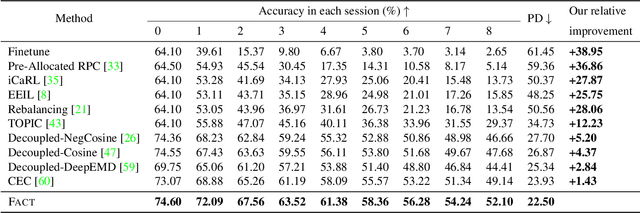
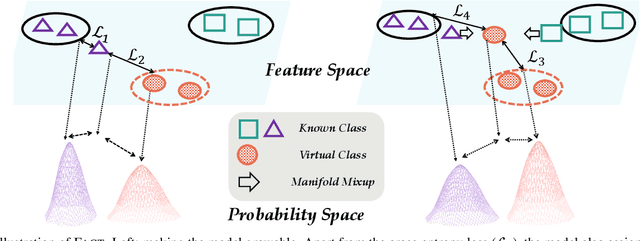
Novel classes frequently arise in our dynamically changing world, e.g., new users in the authentication system, and a machine learning model should recognize new classes without forgetting old ones. This scenario becomes more challenging when new class instances are insufficient, which is called few-shot class-incremental learning (FSCIL). Current methods handle incremental learning retrospectively by making the updated model similar to the old one. By contrast, we suggest learning prospectively to prepare for future updates, and propose ForwArd Compatible Training (FACT) for FSCIL. Forward compatibility requires future new classes to be easily incorporated into the current model based on the current stage data, and we seek to realize it by reserving embedding space for future new classes. In detail, we assign virtual prototypes to squeeze the embedding of known classes and reserve for new ones. Besides, we forecast possible new classes and prepare for the updating process. The virtual prototypes allow the model to accept possible updates in the future, which act as proxies scattered among embedding space to build a stronger classifier during inference. FACT efficiently incorporates new classes with forward compatibility and meanwhile resists forgetting of old ones. Extensive experiments validate FACT's state-of-the-art performance. Code is available at: https://github.com/zhoudw-zdw/CVPR22-Fact
CAKE: A Scalable Commonsense-Aware Framework For Multi-View Knowledge Graph Completion
Mar 08, 2022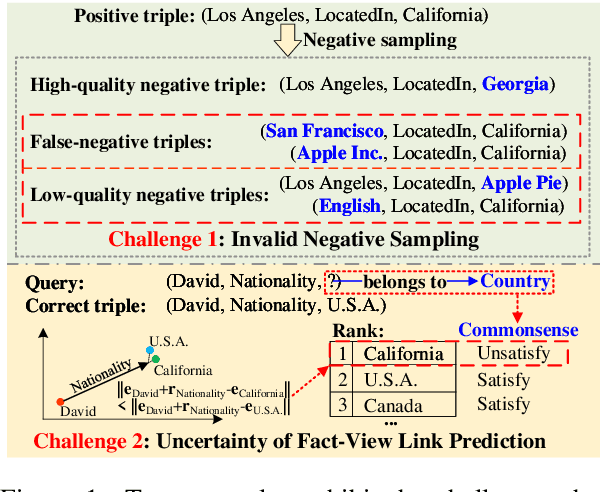
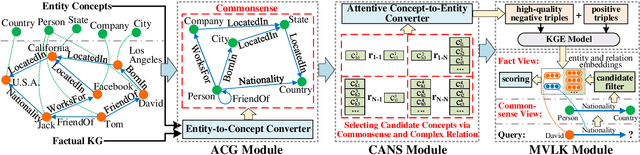
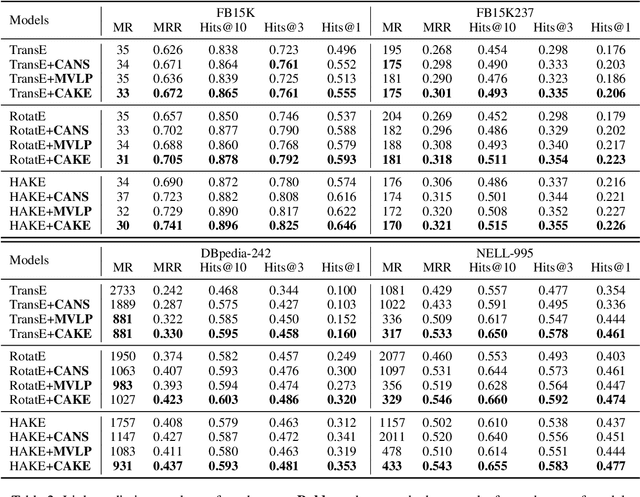
Knowledge graphs store a large number of factual triples while they are still incomplete, inevitably. The previous knowledge graph completion (KGC) models predict missing links between entities merely relying on fact-view data, ignoring the valuable commonsense knowledge. The previous knowledge graph embedding (KGE) techniques suffer from invalid negative sampling and the uncertainty of fact-view link prediction, limiting KGC's performance. To address the above challenges, we propose a novel and scalable Commonsense-Aware Knowledge Embedding (CAKE) framework to automatically extract commonsense from factual triples with entity concepts. The generated commonsense augments effective self-supervision to facilitate both high-quality negative sampling (NS) and joint commonsense and fact-view link prediction. Experimental results on the KGC task demonstrate that assembling our framework could enhance the performance of the original KGE models, and the proposed commonsense-aware NS module is superior to other NS techniques. Besides, our proposed framework could be easily adaptive to various KGE models and explain the predicted results.
Learning Multiple Explainable and Generalizable Cues for Face Anti-spoofing
Feb 21, 2022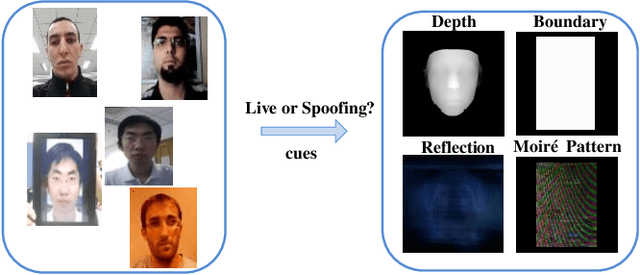
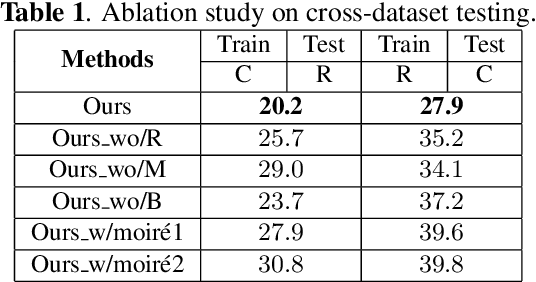
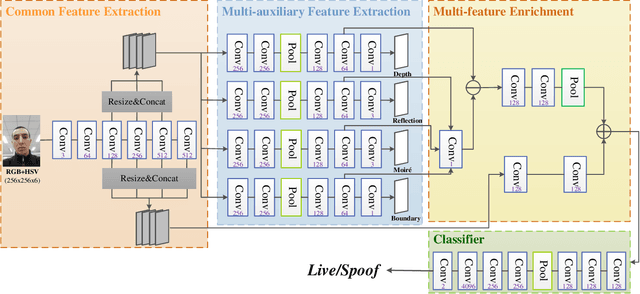
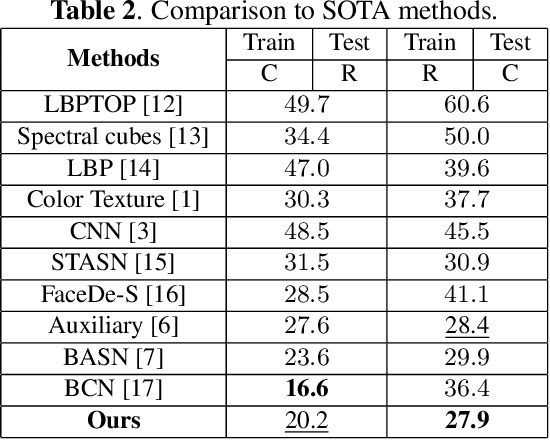
Although previous CNN based face anti-spoofing methods have achieved promising performance under intra-dataset testing, they suffer from poor generalization under cross-dataset testing. The main reason is that they learn the network with only binary supervision, which may learn arbitrary cues overfitting on the training dataset. To make the learned feature explainable and more generalizable, some researchers introduce facial depth and reflection map as the auxiliary supervision. However, many other generalizable cues are unexplored for face anti-spoofing, which limits their performance under cross-dataset testing. To this end, we propose a novel framework to learn multiple explainable and generalizable cues (MEGC) for face anti-spoofing. Specifically, inspired by the process of human decision, four mainly used cues by humans are introduced as auxiliary supervision including the boundary of spoof medium, moir\'e pattern, reflection artifacts and facial depth in addition to the binary supervision. To avoid extra labelling cost, corresponding synthetic methods are proposed to generate these auxiliary supervision maps. Extensive experiments on public datasets validate the effectiveness of these cues, and state-of-the-art performances are achieved by our proposed method.
UWC: Unit-wise Calibration Towards Rapid Network Compression
Jan 17, 2022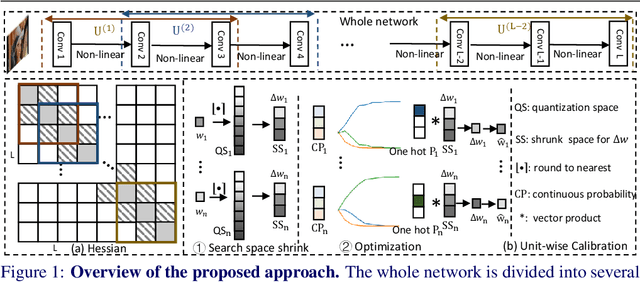
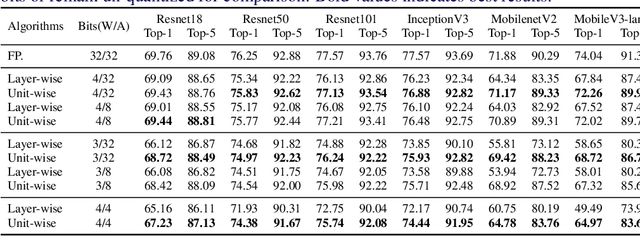
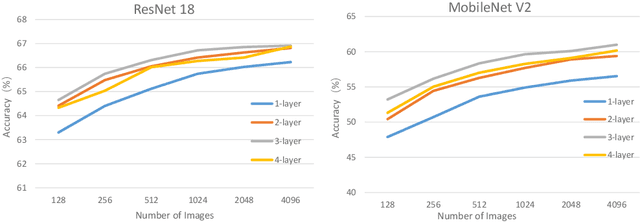
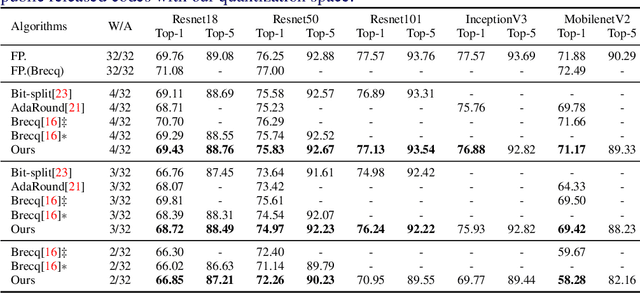
This paper introduces a post-training quantization~(PTQ) method achieving highly efficient Convolutional Neural Network~ (CNN) quantization with high performance. Previous PTQ methods usually reduce compression error via performing layer-by-layer parameters calibration. However, with lower representational ability of extremely compressed parameters (e.g., the bit-width goes less than 4), it is hard to eliminate all the layer-wise errors. This work addresses this issue via proposing a unit-wise feature reconstruction algorithm based on an observation of second order Taylor series expansion of the unit-wise error. It indicates that leveraging the interaction between adjacent layers' parameters could compensate layer-wise errors better. In this paper, we define several adjacent layers as a Basic-Unit, and present a unit-wise post-training algorithm which can minimize quantization error. This method achieves near-original accuracy on ImageNet and COCO when quantizing FP32 models to INT4 and INT3.
Cross-Modal ASR Post-Processing System for Error Correction and Utterance Rejection
Jan 10, 2022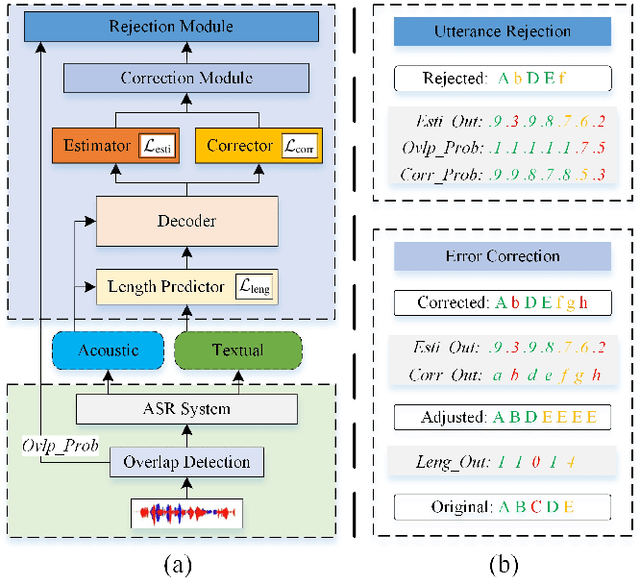

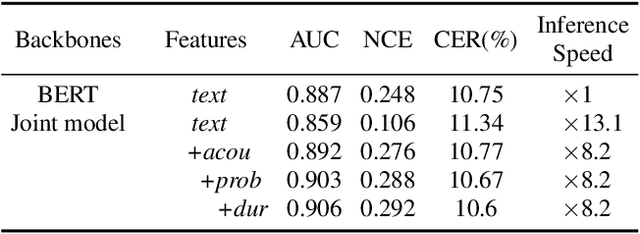
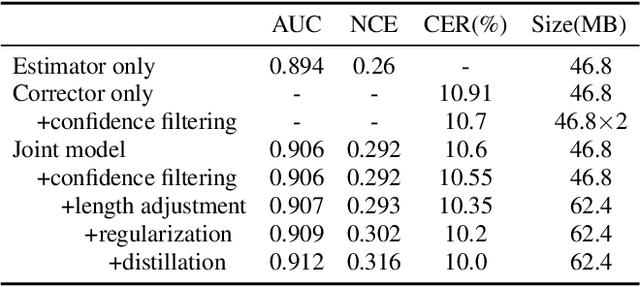
Although modern automatic speech recognition (ASR) systems can achieve high performance, they may produce errors that weaken readers' experience and do harm to downstream tasks. To improve the accuracy and reliability of ASR hypotheses, we propose a cross-modal post-processing system for speech recognizers, which 1) fuses acoustic features and textual features from different modalities, 2) joints a confidence estimator and an error corrector in multi-task learning fashion and 3) unifies error correction and utterance rejection modules. Compared with single-modal or single-task models, our proposed system is proved to be more effective and efficient. Experiment result shows that our post-processing system leads to more than 10% relative reduction of character error rate (CER) for both single-speaker and multi-speaker speech on our industrial ASR system, with about 1.7ms latency for each token, which ensures that extra latency introduced by post-processing is acceptable in streaming speech recognition.