 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Subclass Regularization for Semi-Supervised Semantic Segmentation
Mar 26, 2022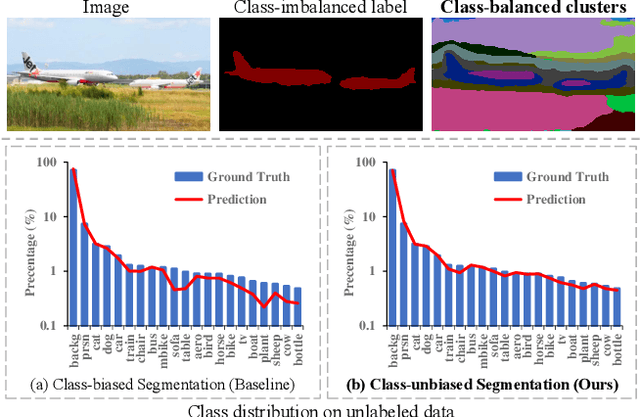
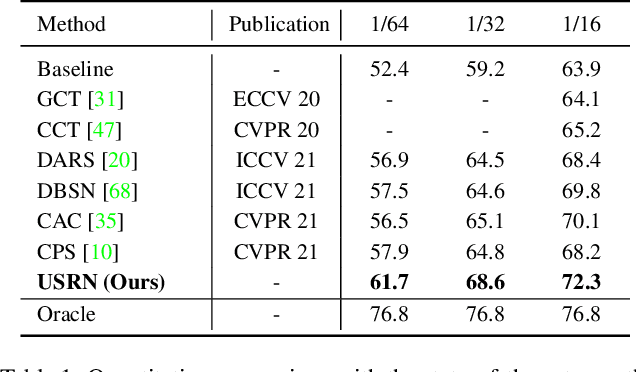
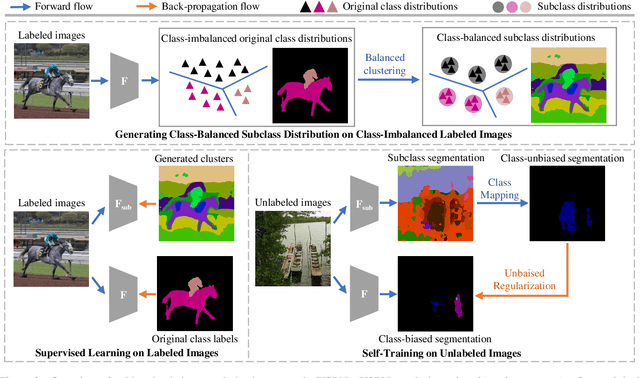
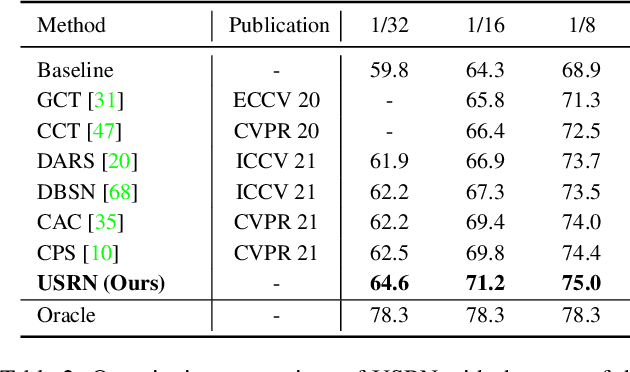
Semi-supervised semantic segmentation learns from small amounts of labelled images and large amounts of unlabelled images, which has witnessed impressive progress with the recent advance of deep neural networks. However, it often suffers from severe class-bias problem while exploring the unlabelled images, largely due to the clear pixel-wise class imbalance in the labelled images. This paper presents an unbiased subclass regularization network (USRN) that alleviates the class imbalance issue by learning class-unbiased segmentation from balanced subclass distributions. We build the balanced subclass distributions by clustering pixels of each original class into multiple subclasses of similar sizes, which provide class-balanced pseudo supervision to regularize the class-biased segmentation. In addition, we design an entropy-based gate mechanism to coordinate learning between the original classes and the clustered subclasses which facilitates subclass regularization effectively by suppressing unconfident subclass predictions. Extensive experiments over multiple public benchmarks show that USRN achieves superior performance as compared with the state-of-the-art.
Fourier Document Restoration for Robust Document Dewarping and Recognition
Mar 18, 2022
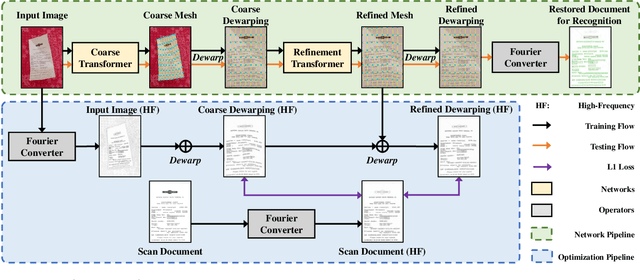
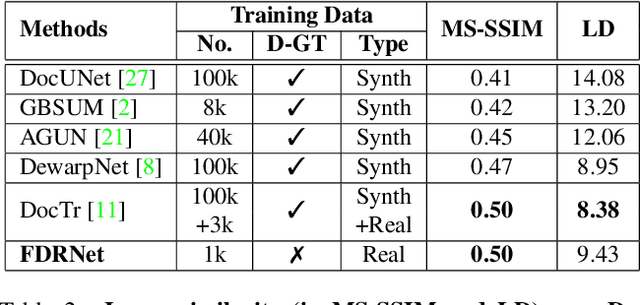
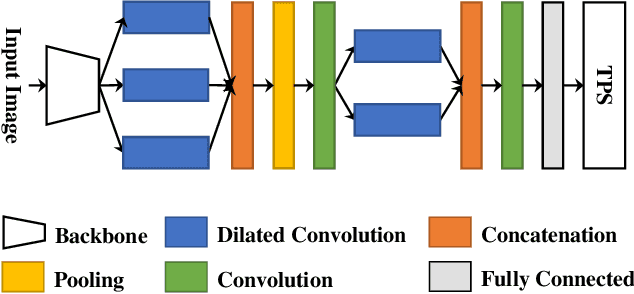
State-of-the-art document dewarping techniques learn to predict 3-dimensional information of documents which are prone to errors while dealing with documents with irregular distortions or large variations in depth. This paper presents FDRNet, a Fourier Document Restoration Network that can restore documents with different distortions and improve document recognition in a reliable and simpler manner. FDRNet focuses on high-frequency components in the Fourier space that capture most structural information but are largely free of degradation in appearance. It dewarps documents by a flexible Thin-Plate Spline transformation which can handle various deformations effectively without requiring deformation annotations in training. These features allow FDRNet to learn from a small amount of simply labeled training images, and the learned model can dewarp documents with complex geometric distortion and recognize the restored texts accurately. To facilitate document restoration research, we create a benchmark dataset consisting of over one thousand camera documents with different types of geometric and photometric distortion. Extensive experiments show that FDRNet outperforms the state-of-the-art by large margins on both dewarping and text recognition tasks. In addition, FDRNet requires a small amount of simply labeled training data and is easy to deploy.
Modulated Contrast for Versatile Image Synthesis
Mar 17, 2022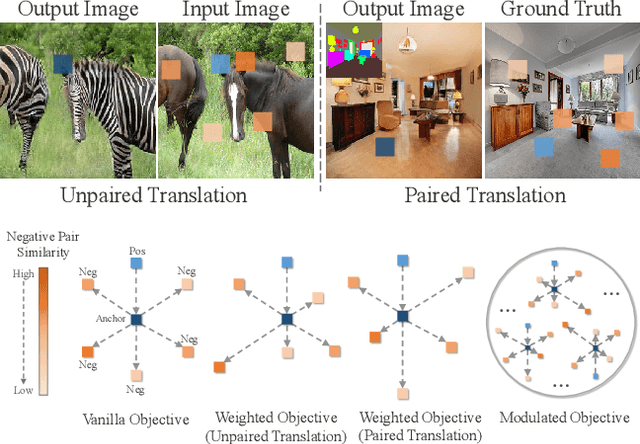
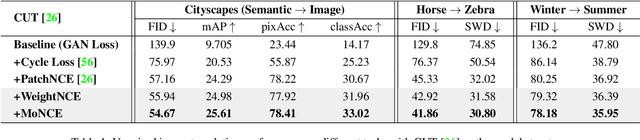

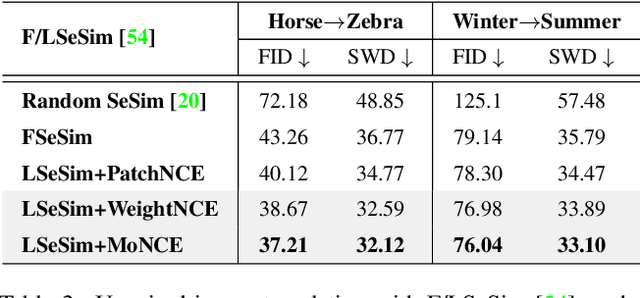
Perceiving the similarity between images has been a long-standing and fundamental problem underlying various visual generation tasks. Predominant approaches measure the inter-image distance by computing pointwise absolute deviations, which tends to estimate the median of instance distributions and leads to blurs and artifacts in the generated images. This paper presents MoNCE, a versatile metric that introduces image contrast to learn a calibrated metric for the perception of multifaceted inter-image distances. Unlike vanilla contrast which indiscriminately pushes negative samples from the anchor regardless of their similarity, we propose to re-weight the pushing force of negative samples adaptively according to their similarity to the anchor, which facilitates the contrastive learning from informative negative samples. Since multiple patch-level contrastive objectives are involved in image distance measurement, we introduce optimal transport in MoNCE to modulate the pushing force of negative samples collaboratively across multiple contrastive objectives. Extensive experiments over multiple image translation tasks show that the proposed MoNCE outperforms various prevailing metrics substantially. The code is available at https://github.com/fnzhan/MoNCE.
Accelerating DETR Convergence via Semantic-Aligned Matching
Mar 14, 2022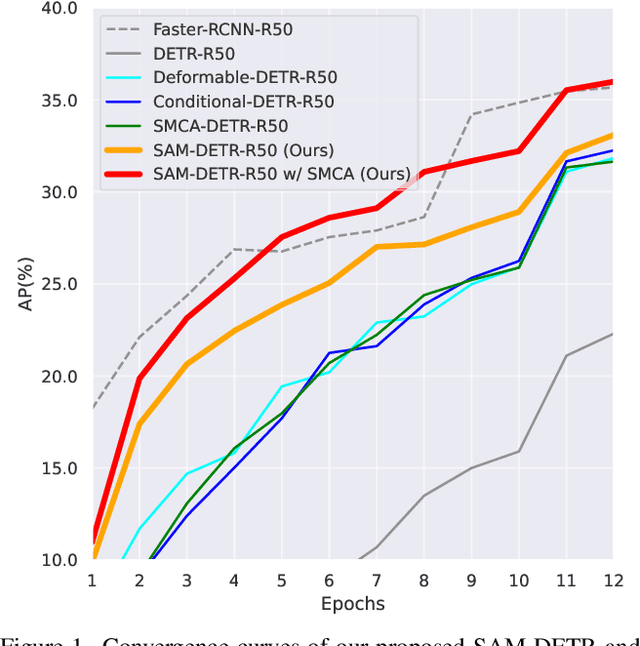
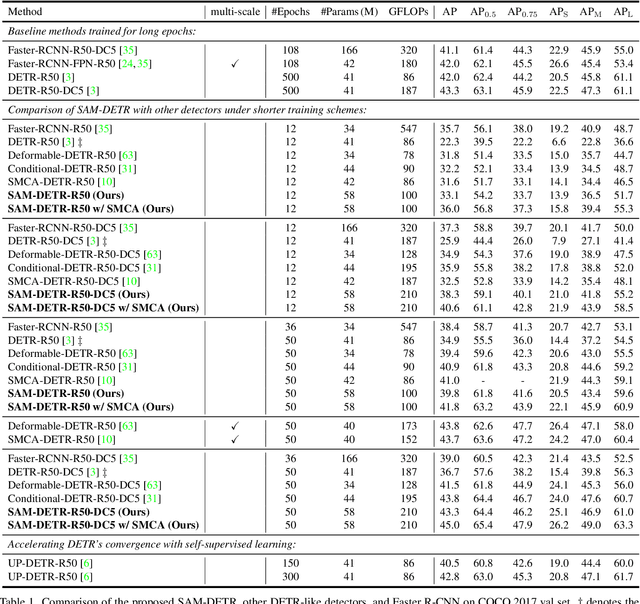
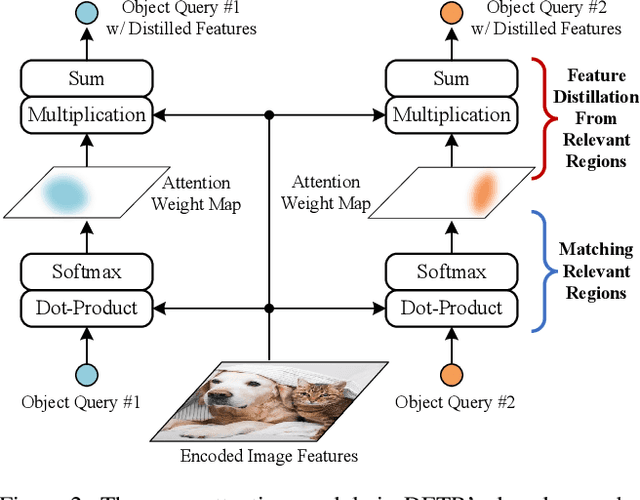
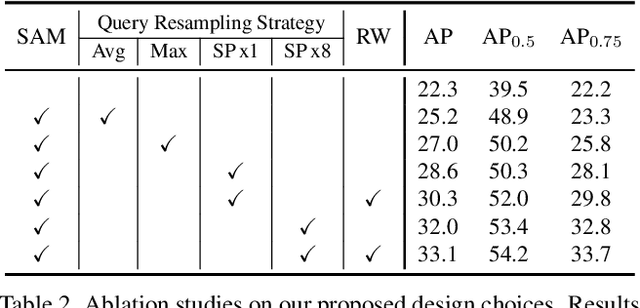
The recently developed DEtection TRansformer (DETR) establishes a new object detection paradigm by eliminating a series of hand-crafted components. However, DETR suffers from extremely slow convergence, which increases the training cost significantly. We observe that the slow convergence is largely attributed to the complication in matching object queries with target features in different feature embedding spaces. This paper presents SAM-DETR, a Semantic-Aligned-Matching DETR that greatly accelerates DETR's convergence without sacrificing its accuracy. SAM-DETR addresses the convergence issue from two perspectives. First, it projects object queries into the same embedding space as encoded image features, where the matching can be accomplished efficiently with aligned semantics. Second, it explicitly searches salient points with the most discriminative features for semantic-aligned matching, which further speeds up the convergence and boosts detection accuracy as well. Being like a plug and play, SAM-DETR complements existing convergence solutions well yet only introduces slight computational overhead. Extensive experiments show that the proposed SAM-DETR achieves superior convergence as well as competitive detection accuracy. The implementation codes are available at https://github.com/ZhangGongjie/SAM-DETR.
Language Matters: A Weakly Supervised Pre-training Approach for Scene Text Detection and Spotting
Mar 08, 2022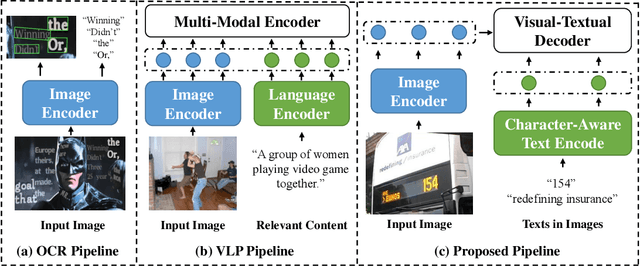
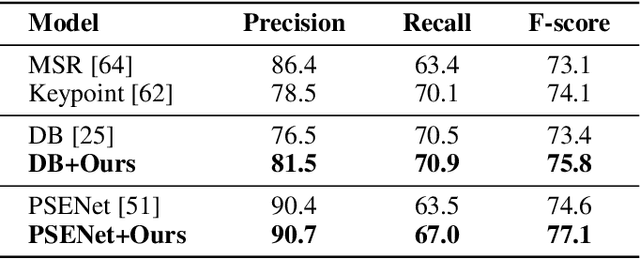
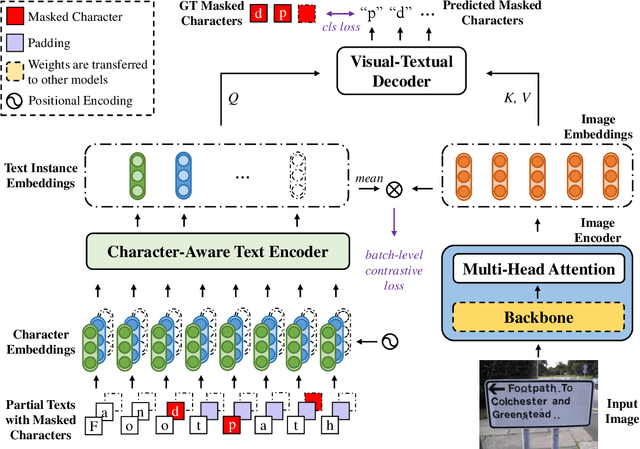

Recently, Vision-Language Pre-training (VLP) techniques have greatly benefited various vision-language tasks by jointly learning visual and textual representations, which intuitively helps in Optical Character Recognition (OCR) tasks due to the rich visual and textual information in scene text images. However, these methods cannot well cope with OCR tasks because of the difficulty in both instance-level text encoding and image-text pair acquisition (i.e. images and captured texts in them). This paper presents a weakly supervised pre-training method that can acquire effective scene text representations by jointly learning and aligning visual and textual information. Our network consists of an image encoder and a character-aware text encoder that extract visual and textual features, respectively, as well as a visual-textual decoder that models the interaction among textual and visual features for learning effective scene text representations. With the learning of textual features, the pre-trained model can attend texts in images well with character awareness. Besides, these designs enable the learning from weakly annotated texts (i.e. partial texts in images without text bounding boxes) which mitigates the data annotation constraint greatly. Experiments over the weakly annotated images in ICDAR2019-LSVT show that our pre-trained model improves F-score by +2.5% and +4.8% while transferring its weights to other text detection and spotting networks, respectively. In addition, the proposed method outperforms existing pre-training techniques consistently across multiple public datasets (e.g., +3.2% and +1.3% for Total-Text and CTW1500).
Unsupervised Representation Learning for Point Clouds: A Survey
Feb 28, 2022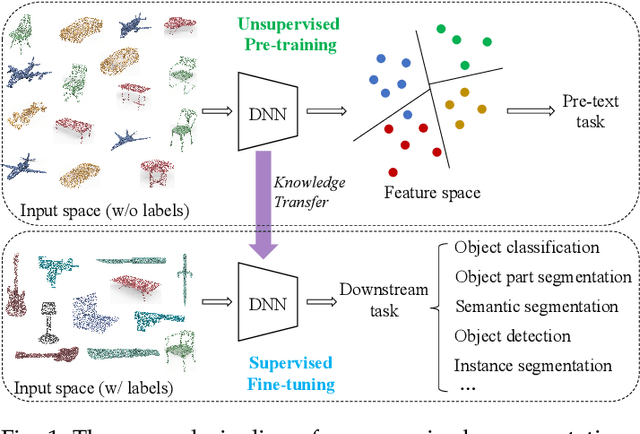

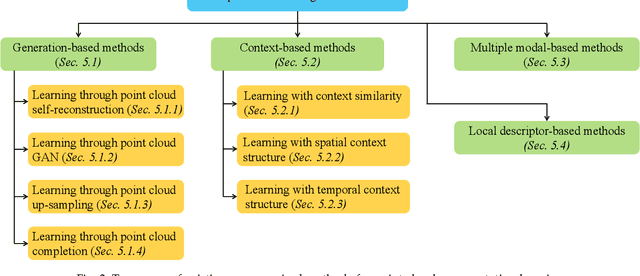
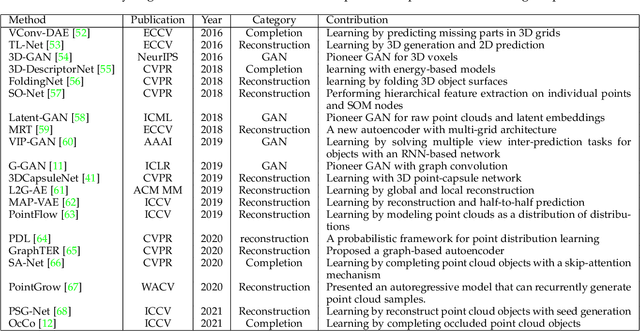
Point cloud data have been widely explored due to its superior accuracy and robustness under various adverse situations. Meanwhile, deep neural networks (DNNs) have achieved very impressive success in various applications such as surveillance and autonomous driving. The convergence of point cloud and DNNs has led to many deep point cloud models, largely trained under the supervision of large-scale and densely-labelled point cloud data. Unsupervised point cloud representation learning, which aims to learn general and useful point cloud representations from unlabelled point cloud data, has recently attracted increasing attention due to the constraint in large-scale point cloud labelling. This paper provides a comprehensive review of unsupervised point cloud representation learning using DNNs. It first describes the motivation, general pipelines as well as terminologies of the recent studies. Relevant background including widely adopted point cloud datasets and DNN architectures is then briefly presented. This is followed by an extensive discussion of existing unsupervised point cloud representation learning methods according to their technical approaches. We also quantitatively benchmark and discuss the reviewed methods over multiple widely adopted point cloud datasets. Finally, we share our humble opinion about several challenges and problems that could be pursued in the future research in unsupervised point cloud representation learning. A project associated with this survey has been built at https://github.com/xiaoaoran/3d_url_survey.
Dual Learning Music Composition and Dance Choreography
Jan 28, 2022
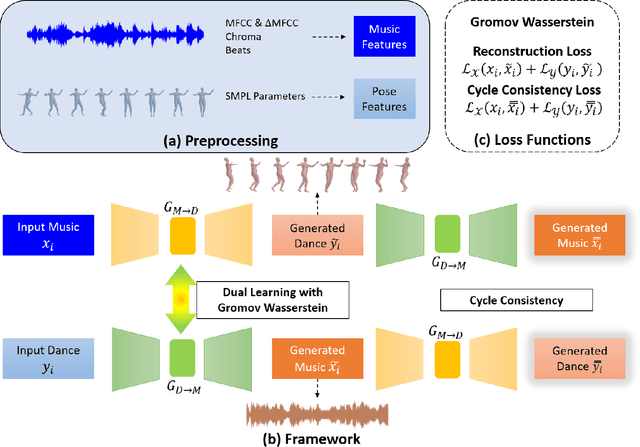
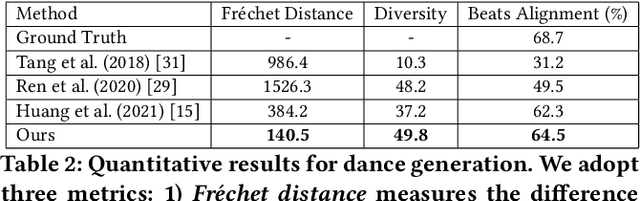
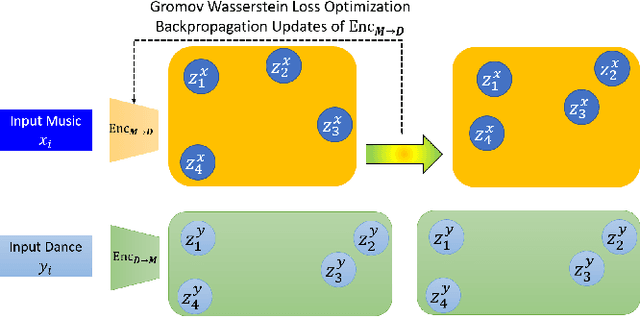
Music and dance have always co-existed as pillars of human activities, contributing immensely to the cultural, social, and entertainment functions in virtually all societies. Notwithstanding the gradual systematization of music and dance into two independent disciplines, their intimate connection is undeniable and one art-form often appears incomplete without the other. Recent research works have studied generative models for dance sequences conditioned on music. The dual task of composing music for given dances, however, has been largely overlooked. In this paper, we propose a novel extension, where we jointly model both tasks in a dual learning approach. To leverage the duality of the two modalities, we introduce an optimal transport objective to align feature embeddings, as well as a cycle consistency loss to foster overall consistency. Experimental results demonstrate that our dual learning framework improves individual task performance, delivering generated music compositions and dance choreographs that are realistic and faithful to the conditioned inputs.
Investigating Pose Representations and Motion Contexts Modeling for 3D Motion Prediction
Dec 30, 2021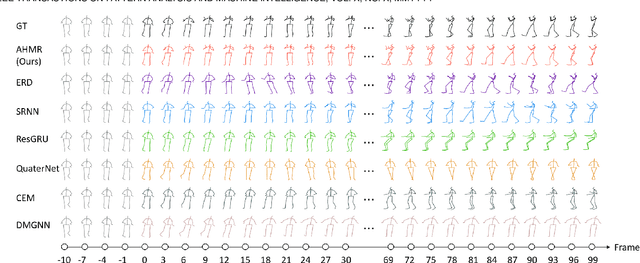
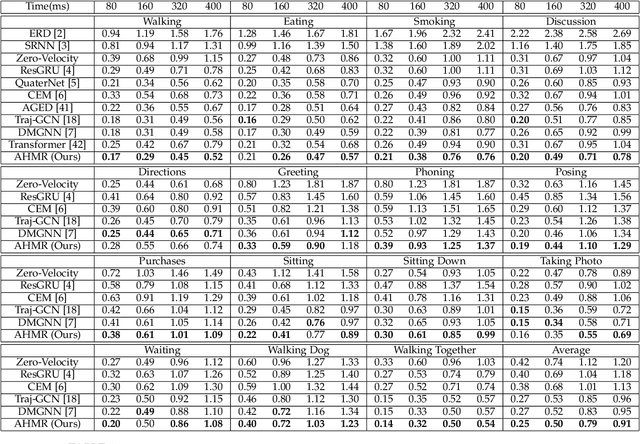

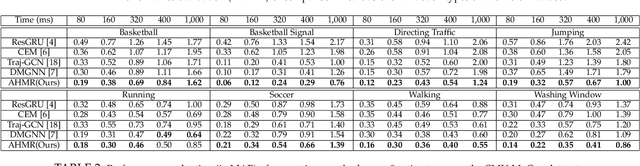
Predicting human motion from historical pose sequence is crucial for a machine to succeed in intelligent interactions with humans. One aspect that has been obviated so far, is the fact that how we represent the skeletal pose has a critical impact on the prediction results. Yet there is no effort that investigates across different pose representation schemes. We conduct an indepth study on various pose representations with a focus on their effects on the motion prediction task. Moreover, recent approaches build upon off-the-shelf RNN units for motion prediction. These approaches process input pose sequence sequentially and inherently have difficulties in capturing long-term dependencies. In this paper, we propose a novel RNN architecture termed AHMR (Attentive Hierarchical Motion Recurrent network) for motion prediction which simultaneously models local motion contexts and a global context. We further explore a geodesic loss and a forward kinematics loss for the motion prediction task, which have more geometric significance than the widely employed L2 loss. Interestingly, we applied our method to a range of articulate objects including human, fish, and mouse. Empirical results show that our approach outperforms the state-of-the-art methods in short-term prediction and achieves much enhanced long-term prediction proficiency, such as retaining natural human-like motions over 50 seconds predictions. Our codes are released.
Multimodal Image Synthesis and Editing: A Survey
Dec 27, 2021

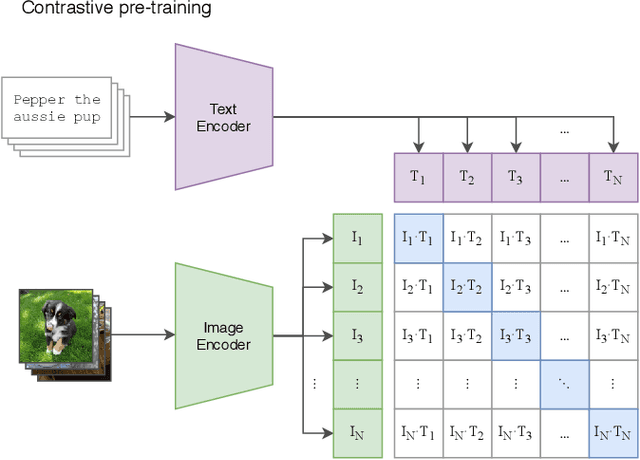
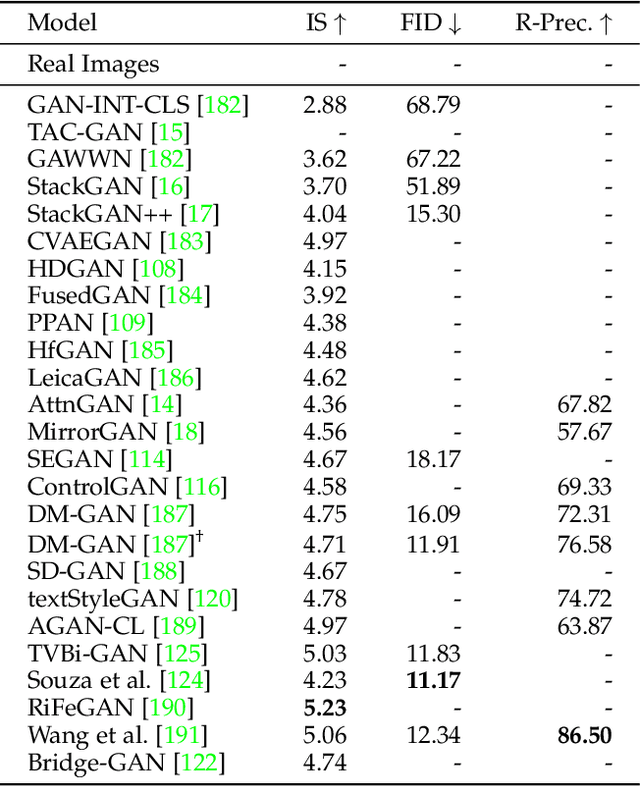
As information exists in various modalities in real world, effective interaction and fusion among multimodal information plays a key role for the creation and perception of multimodal data in computer vision and deep learning research. With superb power in modelling the interaction among multimodal information, multimodal image synthesis and editing have become a hot research topic in recent years. Different from traditional visual guidance which provides explicit clues, multimodal guidance offers intuitive and flexible means in image synthesis and editing. On the other hand, this field is also facing several challenges in alignment of features with inherent modality gaps, synthesis of high-resolution images, faithful evaluation metrics, etc. In this survey, we comprehensively contextualize the advance of the recent multimodal image synthesis \& editing and formulate taxonomies according to data modality and model architectures. We start with an introduction to different types of guidance modalities in image synthesis and editing. We then describe multimodal image synthesis and editing approaches extensively with detailed frameworks including Generative Adversarial Networks (GANs), GAN Inversion, Transformers, and other methods such as NeRF and Diffusion models. This is followed by a comprehensive description of benchmark datasets and corresponding evaluation metrics as widely adopted in multimodal image synthesis and editing, as well as detailed comparisons of different synthesis methods with analysis of respective advantages and limitations. Finally, we provide insights into the current research challenges and possible future research directions. A project associated with this survey is available at https://github.com/fnzhan/MISE
PTTR: Relational 3D Point Cloud Object Tracking with Transformer
Dec 07, 2021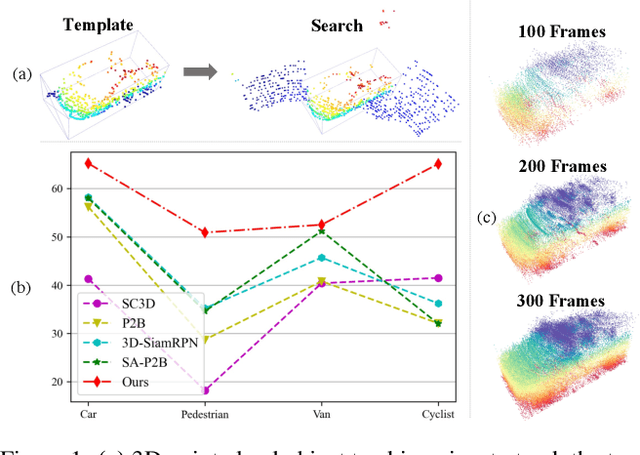
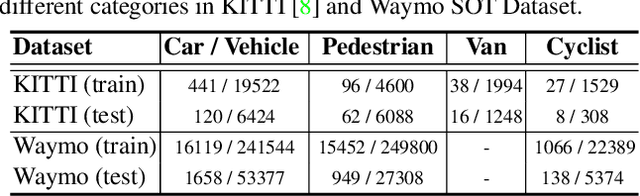
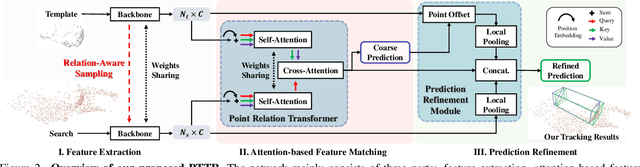
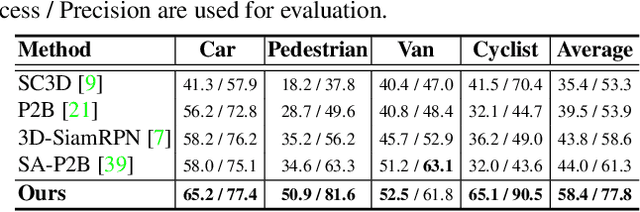
In a point cloud sequence, 3D object tracking aims to predict the location and orientation of an object in the current search point cloud given a template point cloud. Motivated by the success of transformers, we propose Point Tracking TRansformer (PTTR), which efficiently predicts high-quality 3D tracking results in a coarse-to-fine manner with the help of transformer operations. PTTR consists of three novel designs. 1) Instead of random sampling, we design Relation-Aware Sampling to preserve relevant points to given templates during subsampling. 2) Furthermore, we propose a Point Relation Transformer (PRT) consisting of a self-attention and a cross-attention module. The global self-attention operation captures long-range dependencies to enhance encoded point features for the search area and the template, respectively. Subsequently, we generate the coarse tracking results by matching the two sets of point features via cross-attention. 3) Based on the coarse tracking results, we employ a novel Prediction Refinement Module to obtain the final refined prediction. In addition, we create a large-scale point cloud single object tracking benchmark based on the Waymo Open Dataset. Extensive experiments show that PTTR achieves superior point cloud tracking in both accuracy and efficiency.