 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystify Mamba in Vision: A Linear Attention Perspective
May 26, 2024



Mamba is an effective state space model with linear computation complexity. It has recently shown impressive efficiency in dealing with high-resolution inputs across various vision tasks. In this paper, we reveal that the powerful Mamba model shares surprising similarities with linear attention Transformer, which typically underperform conventional Transformer in practice. By exploring the similarities and disparities between the effective Mamba and subpar linear attention Transformer, we provide comprehensive analyses to demystify the key factors behind Mamba's success. Specifically, we reformulate the selective state space model and linear attention within a unified formulation, rephrasing Mamba as a variant of linear attention Transformer with six major distinctions: input gate, forget gate, shortcut, no attention normalization, single-head, and modified block design. For each design, we meticulously analyze its pros and cons, and empirically evaluate its impact on model performance in vision tasks. Interestingly, the results highlight the forget gate and block design as the core contributors to Mamba's success, while the other four designs are less crucial. Based on these findings, we propose a Mamba-Like Linear Attention (MLLA) model by incorporating the merits of these two key designs into linear attention. The resulting model outperforms various vision Mamba models in both image classification and high-resolution dense prediction tasks, while enjoying parallelizable computation and fast inference speed. Code is available at https://github.com/LeapLabTHU/MLLA.
ConvLLaVA: Hierarchical Backbones as Visual Encoder for Large Multimodal Models
May 24, 2024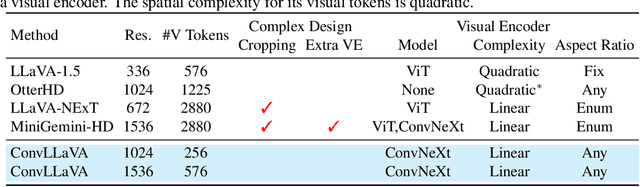
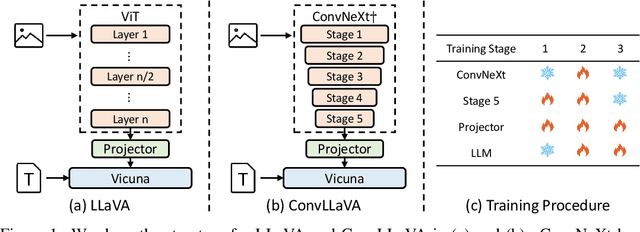
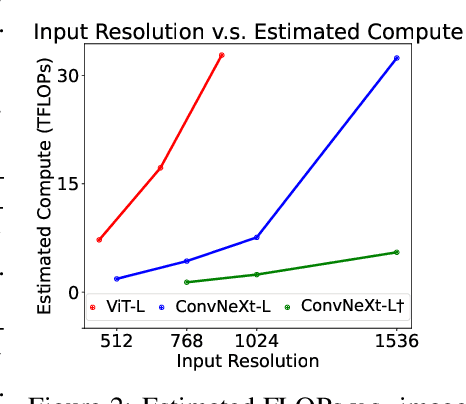

High-resolution Large Multimodal Models (LMMs) encounter the challenges of excessive visual tokens and quadratic visual complexity. Current high-resolution LMMs address the quadratic complexity while still generating excessive visual tokens. However, the redundancy in visual tokens is the key problem as it leads to more substantial compute. To mitigate this issue, we propose ConvLLaVA, which employs ConvNeXt, a hierarchical backbone, as the visual encoder of LMM to replace Vision Transformer (ViT). ConvLLaVA compresses high-resolution images into information-rich visual features, effectively preventing the generation of excessive visual tokens. To enhance the capabilities of ConvLLaVA, we propose two critical optimizations. Since the low-resolution pretrained ConvNeXt underperforms when directly applied on high resolution, we update it to bridge the gap. Moreover, since ConvNeXt's original compression ratio is inadequate for much higher resolution inputs, we train a successive stage to further compress the visual tokens, thereby reducing redundancy. These optimizations enable ConvLLaVA to support inputs of 1536x1536 resolution generating only 576 visual tokens, capable of handling images of arbitrary aspect ratios. Experimental results demonstrate that our method achieves competitive performance with state-of-the-art models on mainstream benchmarks. The ConvLLaVA model series are publicly available at https://github.com/alibaba/conv-llava.
Visual Attention Based Cognitive Human-Robot Collaboration for Pedicle Screw Placement in Robot-Assisted Orthopedic Surgery
May 15, 2024Current orthopedic robotic systems largely focus on navigation, aiding surgeons in positioning a guiding tube but still requiring manual drilling and screw placement. The automation of this task not only demands high precision and safety due to the intricate physical interactions between the surgical tool and bone but also poses significant risks when executed without adequate human oversight. As it involves continuous physical interaction, the robot should collaborate with the surgeon, understand the human intent, and always include the surgeon in the loop. To achieve this, this paper proposes a new cognitive human-robot collaboration framework, including the intuitive AR-haptic human-robot interface, the visual-attention-based surgeon model, and the shared interaction control scheme for the robot. User studies on a robotic platform for orthopedic surgery are presented to illustrate the performance of the proposed method. The results demonstrate that the proposed human-robot collaboration framework outperforms full robot and full human control in terms of safety and ergonomics.
EfficientTrain++: Generalized Curriculum Learning for Efficient Visual Backbone Training
May 14, 2024



The superior performance of modern visual backbones usually comes with a costly training procedure. We contribute to this issue by generalizing the idea of curriculum learning beyond its original formulation, i.e., training models using easier-to-harder data. Specifically, we reformulate the training curriculum as a soft-selection function, which uncovers progressively more difficult patterns within each example during training, instead of performing easier-to-harder sample selection. Our work is inspired by an intriguing observation on the learning dynamics of visual backbones: during the earlier stages of training, the model predominantly learns to recognize some 'easier-to-learn' discriminative patterns in the data. These patterns, when observed through frequency and spatial domains, incorporate lower-frequency components, and the natural image contents without distortion or data augmentation. Motivated by these findings, we propose a curriculum where the model always leverages all the training data at every learning stage, yet the exposure to the 'easier-to-learn' patterns of each example is initiated first, with harder patterns gradually introduced as training progresses. To implement this idea in a computationally efficient way, we introduce a cropping operation in the Fourier spectrum of the inputs, enabling the model to learn from only the lower-frequency components. Then we show that exposing the contents of natural images can be readily achieved by modulating the intensity of data augmentation. Finally, we integrate these aspects and design curriculum schedules with tailored search algorithms. The resulting method, EfficientTrain++, is simple, general, yet surprisingly effective. It reduces the training time of a wide variety of popular models by 1.5-3.0x on ImageNet-1K/22K without sacrificing accuracy. It also demonstrates efficacy in self-supervised learning (e.g., MAE).
Deep Reinforcement Learning for Traveling Purchaser Problems
Apr 11, 2024



The traveling purchaser problem (TPP) is an important combinatorial optimization problem with broad applications. Due to the coupling between routing and purchasing, existing works on TPPs commonly address route construction and purchase planning simultaneously, which, however, leads to exact methods with high computational cost and heuristics with sophisticated design but limited performance. In sharp contrast, we propose a novel approach based on deep reinforcement learning (DRL), which addresses route construction and purchase planning separately, while evaluating and optimizing the solution from a global perspective. The key components of our approach include a bipartite graph representation for TPPs to capture the market-product relations, and a policy network that extracts information from the bipartite graph and uses it to sequentially construct the route. One significant benefit of our framework is that we can efficiently construct the route using the policy network, and once the route is determined, the associated purchasing plan can be easily derived through linear programming, while, leveraging DRL, we can train the policy network to optimize the global solution objective. Furthermore, by introducing a meta-learning strategy, the policy network can be trained stably on large-sized TPP instances, and generalize well across instances of varying sizes and distributions, even to much larger instances that are never seen during training. Experiments on various synthetic TPP instances and the TPPLIB benchmark demonstrate that our DRL-based approach can significantly outperform well-established TPP heuristics, reducing the optimality gap by 40%-90%, and also showing an advantage in runtime, especially on large-sized instances.
Probabilistic Contrastive Learning for Long-Tailed Visual Recognition
Mar 14, 2024



Long-tailed distributions frequently emerge in real-world data, where a large number of minority categories contain a limited number of samples. Such imbalance issue considerably impairs the performance of standard supervised learning algorithms, which are mainly designed for balanced training sets. Recent investigations have revealed that supervised contrastive learning exhibits promising potential in alleviating the data imbalance. However, the performance of supervised contrastive learning is plagued by an inherent challenge: it necessitates sufficiently large batches of training data to construct contrastive pairs that cover all categories, yet this requirement is difficult to meet in the context of class-imbalanced data. To overcome this obstacle, we propose a novel probabilistic contrastive (ProCo) learning algorithm that estimates the data distribution of the samples from each class in the feature space, and samples contrastive pairs accordingly. In fact, estimating the distributions of all classes using features in a small batch, particularly for imbalanced data, is not feasible. Our key idea is to introduce a reasonable and simple assumption that the normalized features in contrastive learning follow a mixture of von Mises-Fisher (vMF) distributions on unit space, which brings two-fold benefits. First, the distribution parameters can be estimated using only the first sample moment, which can be efficiently computed in an online manner across different batches. Second, based on the estimated distribution, the vMF distribution allows us to sample an infinite number of contrastive pairs and derive a closed form of the expected contrastive loss for efficient optimization. Our code is available at https://github.com/LeapLabTHU/ProCo.
LLM Agents for Psychology: A Study on Gamified Assessments
Feb 19, 2024Psychological measurement is essential for mental health, self-understanding, and personal development. Traditional methods, such as self-report scales and psychologist interviews, often face challenges with engagement and accessibility. While game-based and LLM-based tools have been explored to improve user interest and automate assessment, they struggle to balance engagement with generalizability. In this work, we propose PsychoGAT (Psychological Game AgenTs) to achieve a generic gamification of psychological assessment. The main insight is that powerful LLMs can function both as adept psychologists and innovative game designers. By incorporating LLM agents into designated roles and carefully managing their interactions, PsychoGAT can transform any standardized scales into personalized and engaging interactive fiction games. To validate the proposed method, we conduct psychometric evaluations to assess its effectiveness and employ human evaluators to examine the generated content across various psychological constructs, including depression, cognitive distortions, and personality traits. Results demonstrate that PsychoGAT serves as an effective assessment tool, achieving statistically significant excellence in psychometric metrics such as reliability, convergent validity, and discriminant validity. Moreover, human evaluations confirm PsychoGAT's enhancements in content coherence, interactivity, interest, immersion, and satisfaction.
A Reinforcement-Learning-Based Multiple-Column Selection Strategy for Column Generation
Dec 29, 2023



Column generation (CG) is one of the most successful approaches for solving large-scale linear programming (LP) problems. Given an LP with a prohibitively large number of variables (i.e., columns), the idea of CG is to explicitly consider only a subset of columns and iteratively add potential columns to improve the objective value. While adding the column with the most negative reduced cost can guarantee the convergence of CG, it has been shown that adding multiple columns per iteration rather than a single column can lead to faster convergence. However, it remains a challenge to design a multiple-column selection strategy to select the most promising columns from a large number of candidate columns. In this paper, we propose a novel reinforcement-learning-based (RL) multiple-column selection strategy. To the best of our knowledge, it is the first RL-based multiple-column selection strategy for CG. The effectiveness of our approach is evaluated on two sets of problems: the cutting stock problem and the graph coloring problem. Compared to several widely used single-column and multiple-column selection strategies, our RL-based multiple-column selection strategy leads to faster convergence and achieves remarkable reductions in the number of CG iterations and runtime.
Segment3D: Learning Fine-Grained Class-Agnostic 3D Segmentation without Manual Labels
Dec 28, 2023Current 3D scene segmentation methods are heavily dependent on manually annotated 3D training datasets. Such manual annotations are labor-intensive, and often lack fine-grained details. Importantly, models trained on this data typically struggle to recognize object classes beyond the annotated classes, i.e., they do not generalize well to unseen domains and require additional domain-specific annotations. In contrast, 2D foundation models demonstrate strong generalization and impressive zero-shot abilities, inspiring us to incorporate these characteristics from 2D models into 3D models. Therefore, we explore the use of image segmentation foundation models to automatically generate training labels for 3D segmentation. We propose Segment3D, a method for class-agnostic 3D scene segmentation that produces high-quality 3D segmentation masks. It improves over existing 3D segmentation models (especially on fine-grained masks), and enables easily adding new training data to further boost the segmentation performance -- all without the need for manual training labels.
Agent Attention: On the Integration of Softmax and Linear Attention
Dec 22, 2023



The attention module is the key component in Transformers. While the global attention mechanism offers high expressiveness, its excessive computational cost restricts its applicability in various scenarios. In this paper, we propose a novel attention paradigm, Agent Attention, to strike a favorable balance between computational efficiency and representation power. Specifically, the Agent Attention, denoted as a quadruple $(Q, A, K, V)$, introduces an additional set of agent tokens $A$ into the conventional attention module. The agent tokens first act as the agent for the query tokens $Q$ to aggregate information from $K$ and $V$, and then broadcast the information back to $Q$. Given the number of agent tokens can be designed to be much smaller than the number of query tokens, the agent attention is significantly more efficient than the widely adopted Softmax attention, while preserving global context modelling capability. Interestingly, we show that the proposed agent attention is equivalent to a generalized form of linear attention. Therefore, agent attention seamlessly integrates the powerful Softmax attention and the highly efficient linear attention. Extensive experiments demonstrate the effectiveness of agent attention with various vision Transformers and across diverse vision tasks, including image classification, object detection, semantic segmentation and image generation. Notably, agent attention has shown remarkable performance in high-resolution scenarios, owning to its linear attention nature. For instance, when applied to Stable Diffusion, our agent attention accelerates generation and substantially enhances image generation quality without any additional training. Code is available at https://github.com/LeapLabTHU/Agent-Attention.