 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM4Branch: Large Language Model for Discovering Efficient Branching Policies of Integer Programs
May 11, 2026Efficient branching policies are essential for accelerating Mixed Integer Linear Programming (MILP) solvers. Their design has long relied on hand-crafted heuristics, and now machine learning has emerged as a promising paradigm to automate this process. However, existing learning-based methods are often hindered by their dependence on expensive expert demonstrations and the gap between training objectives and the solver's end-to-end performance. In this work, we propose LLM4Branch, a novel framework that leverages Large Language Models (LLMs) to automate the discovery of efficient branching policies. Specifically, the discovered policy is an executable program with a program skeleton generated by the LLM and a parameter vector, which is optimized via a zeroth-order method over a few instances with their end-to-end performance feedback. Extensive experiments on standard MILP benchmarks demonstrate that LLM4Branch establishes a new state-of-the-art among CPU-based methods and achieves performance competitive with advanced GPU-based models. Codes are available at https://github.com/hzn18/LLM4Branch.
Compressed Proximal Federated Learning for Non-Convex Composite Optimization on Heterogeneous Data
Mar 08, 2026Federated Composite Optimization (FCO) has emerged as a promising framework for training models with structural constraints (e.g., sparsity) in distributed edge networks. However, simultaneously achieving communication efficiency and convergence robustness remains a significant challenge, particularly when dealing with non-smooth regularizers, statistical heterogeneity, and the restrictions of biased compression. To address these issues, we propose FedCEF (Federated Composite Error Feedback), a novel algorithm tailored for non-convex FCO. FedCEF introduces a decoupled proximal update scheme that separates the proximal operator from communication, enabling clients to handle non-smooth terms locally while transmitting compressed information. To mitigate the noise from aggressive quantization and the bias from non-IID data, FedCEF integrates a rigorous error feedback mechanism with control variates. Furthermore, we design a communication-efficient pre-proximal downlink strategy that allows clients to exactly reconstruct global control variables without explicit transmission. We theoretically establish that FedCEF achieves sublinear convergence to a bounded residual error under general non-convexity, which is controllable via the step size and batch size. Extensive experiments on real datasets validate FedCEF maintains competitive model accuracy even under extreme compression ratios (e.g., 1%), significantly reducing the total communication volume compared to uncompressed baselines.
ReLU Networks for Model Predictive Control: Network Complexity and Performance Guarantees
Jan 23, 2026Recent years have witnessed a resurgence in using ReLU neural networks (NNs) to represent model predictive control (MPC) policies. However, determining the required network complexity to ensure closed-loop performance remains a fundamental open problem. This involves a critical precision-complexity trade-off: undersized networks may fail to capture the MPC policy, while oversized ones may outweigh the benefits of ReLU network approximation. In this work, we propose a projection-based method to enforce hard constraints and establish a state-dependent Lipschitz continuity property for the optimal MPC cost function, which enables sharp convergence analysis of the closed-loop system. For the first time, we derive explicit bounds on ReLU network width and depth for approximating MPC policies with guaranteed closed-loop performance. To further reduce network complexity and enhance closed-loop performance, we propose a non-uniform error framework with a state-aware scaling function to adaptively adjust both the input and output of the ReLU network. Our contributions provide a foundational step toward certifiable ReLU NN-based MPC.
Deep Reinforcement Learning for Traveling Purchaser Problems
Apr 11, 2024



The traveling purchaser problem (TPP) is an important combinatorial optimization problem with broad applications. Due to the coupling between routing and purchasing, existing works on TPPs commonly address route construction and purchase planning simultaneously, which, however, leads to exact methods with high computational cost and heuristics with sophisticated design but limited performance. In sharp contrast, we propose a novel approach based on deep reinforcement learning (DRL), which addresses route construction and purchase planning separately, while evaluating and optimizing the solution from a global perspective. The key components of our approach include a bipartite graph representation for TPPs to capture the market-product relations, and a policy network that extracts information from the bipartite graph and uses it to sequentially construct the route. One significant benefit of our framework is that we can efficiently construct the route using the policy network, and once the route is determined, the associated purchasing plan can be easily derived through linear programming, while, leveraging DRL, we can train the policy network to optimize the global solution objective. Furthermore, by introducing a meta-learning strategy, the policy network can be trained stably on large-sized TPP instances, and generalize well across instances of varying sizes and distributions, even to much larger instances that are never seen during training. Experiments on various synthetic TPP instances and the TPPLIB benchmark demonstrate that our DRL-based approach can significantly outperform well-established TPP heuristics, reducing the optimality gap by 40%-90%, and also showing an advantage in runtime, especially on large-sized instances.
Innovation Compression for Communication-efficient Distributed Optimization with Linear Convergence
May 14, 2021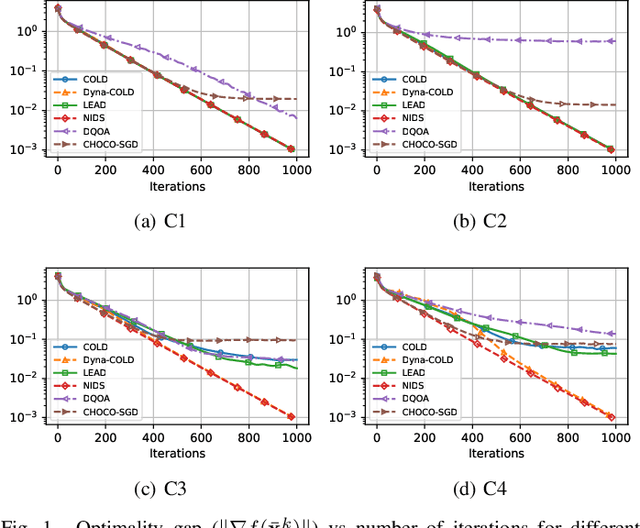
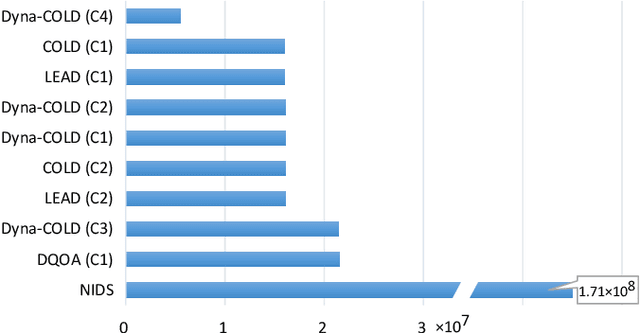
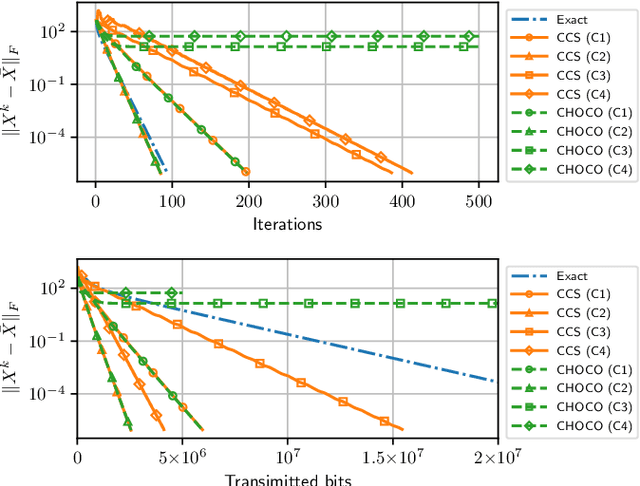

Information compression is essential to reduce communication cost in distributed optimization over peer-to-peer networks. This paper proposes a communication-efficient linearly convergent distributed (COLD) algorithm to solve strongly convex optimization problems. By compressing innovation vectors, which are the differences between decision vectors and their estimates, COLD is able to achieve linear convergence for a class of $\delta$-contracted compressors. We explicitly quantify how the compression affects the convergence rate and show that COLD matches the same rate of its uncompressed version. To accommodate a wider class of compressors that includes the binary quantizer, we further design a novel dynamical scaling mechanism and obtain the linearly convergent Dyna-COLD. Importantly, our results strictly improve existing results for the quantized consensus problem. Numerical experiments demonstrate the advantages of both algorithms under different compressors.
Primal-dual Learning for the Model-free Risk-constrained Linear Quadratic Regulator
Dec 10, 2020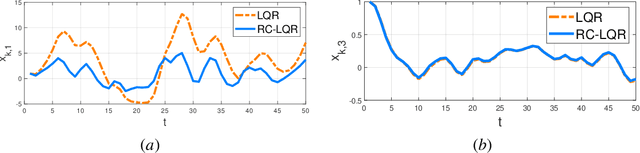
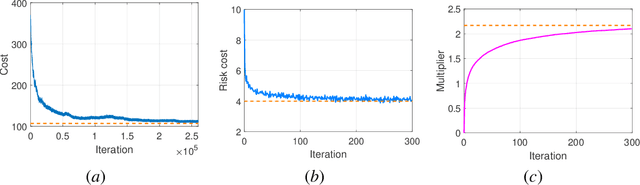
Risk-aware control, though with promise to tackle unexpected events, requires a known exact dynamical model. In this work, we propose a model-free framework to learn a risk-aware controller with a focus on the linear system. We formulate it as a discrete-time infinite-horizon LQR problem with a state predictive variance constraint. To solve it, we parameterize the policy with a feedback gain pair and leverage primal-dual methods to optimize it by solely using data. We first study the optimization landscape of the Lagrangian function and establish the strong duality in spite of its non-convex nature. Alongside, we find that the Lagrangian function enjoys an important local gradient dominance property, which is then exploited to develop a convergent random search algorithm to learn the dual function. Furthermore, we propose a primal-dual algorithm with global convergence to learn the optimal policy-multiplier pair. Finally, we validate our results via simulations.
Smart Train Operation Algorithms based on Expert Knowledge and Reinforcement Learning
Mar 06, 2020
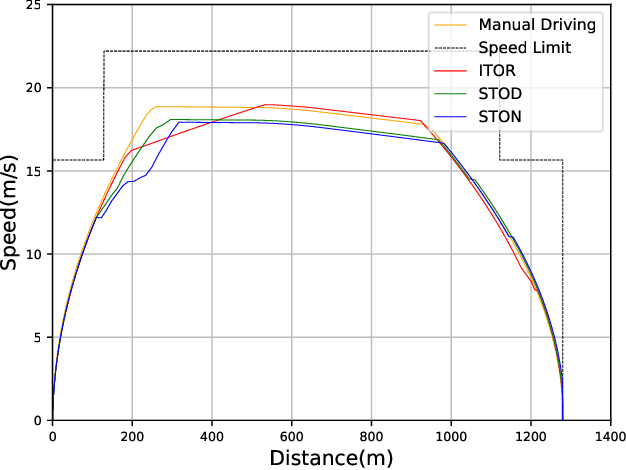
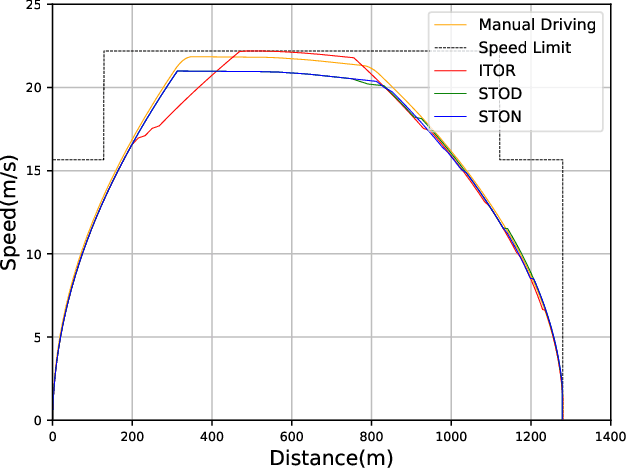
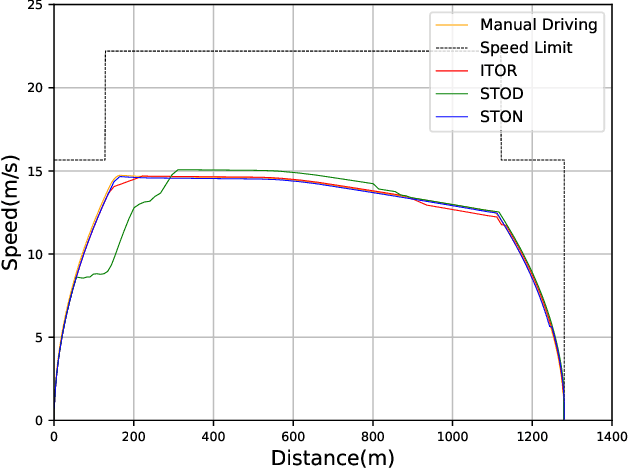
During recent decades, the automatic train operation (ATO) system has been gradually adopted in many subway systems. On the one hand, it is more intelligent than traditional manual driving; on the other hand, it increases the energy consumption and decreases the riding comfort of the subway system. This paper proposes two smart train operation algorithms based on the combination of expert knowledge and reinforcement learning algorithms. Compared with previous works, smart train operation algorithms can realize the control of continuous action for the subway system and satisfy multiple objectives (the safety, the punctuality, the energy efficiency, and the riding comfort) without using an offline optimized speed profile. Firstly, through analyzing historical data of experienced subway drivers, we summarize the expert knowledge rules and build inference methods to guarantee the riding comfort, the punctuality and the safety of the subway system. Then we develop two algorithms to realize the control of continuous action and to ensure the energy efficiency of train operation. Among them, one is the smart train operation (STO) algorithm based on deep deterministic policy gradient named (STOD) and another is the smart train operation algorithm based on normalized advantage function (STON). Finally, we verify the performance of proposed algorithms via some numerical simulations with the real field data collected from the Yizhuang Line of the Beijing Subway and their performance will be compared with existing ATO algorithms. The results of numerical simulations show that the developed smart train operation systems are better than manual driving and existing ATO algorithms in respect of energy efficiency. In addition, STOD and STON have the ability to adapt to different trip times and different resistance conditions.
Asynchronous Policy Evaluation in Distributed Reinforcement Learning over Networks
Mar 01, 2020
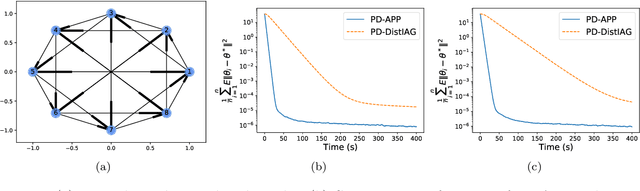
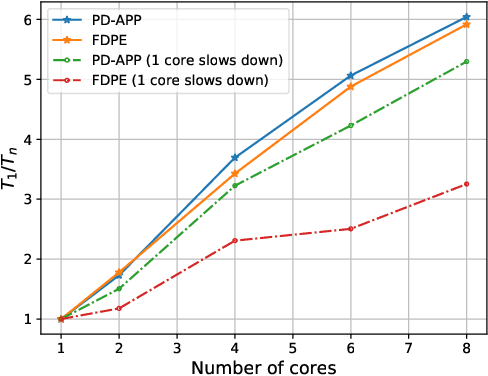
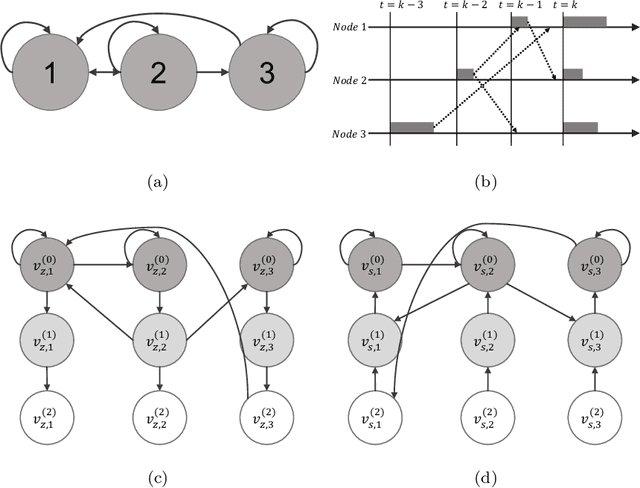
This paper proposes a \emph{fully asynchronous} scheme for policy evaluation of distributed reinforcement learning (DisRL) over peer-to-peer networks. Without any form of coordination, nodes can communicate with neighbors and compute their local variables using (possibly) delayed information at any time, which is in sharp contrast to the asynchronous gossip. Thus, the proposed scheme fully takes advantage of the distributed setting. We prove that our method converges at a linear rate $\mathcal{O}(c^k)$ where $c\in(0,1)$ and $k$ increases by one no matter on which node updates, showing the computational advantage by reducing the amount of synchronization. Numerical experiments show that our method speeds up linearly w.r.t. the number of nodes, and is robust to straggler nodes. To the best of our knowledge, our work is the first theoretical analysis for asynchronous update in DisRL, including the \emph{parallel RL} domain advocated by A3C.
A selected review on reinforcement learning based control for autonomous underwater vehicles
Nov 27, 2019
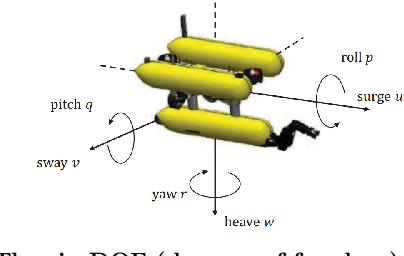


Recently, reinforcement learning (RL) has been extensively studied and achieved promising results in a wide range of control tasks. Meanwhile, autonomous underwater vehicle (AUV) is an important tool for executing complex and challenging underwater tasks. The advances in RL offers ample opportunities for developing intelligent AUVs. This paper provides a selected review on RL based control for AUVs with the focus on applications of RL to low-level control tasks for underwater regulation and tracking. To this end, we first present a concise introduction to the RL based control framework. Then, we provide an overview of RL methods for AUVs control problems, where the main challenges and recent progresses are discussed. Finally, two representative cases of RL-based controllers are given in detail for the model-free RL methods on AUVs.
Decentralized Stochastic Gradient Tracking for Empirical Risk Minimization
Sep 06, 2019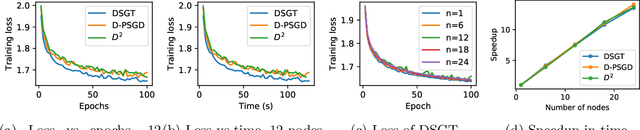

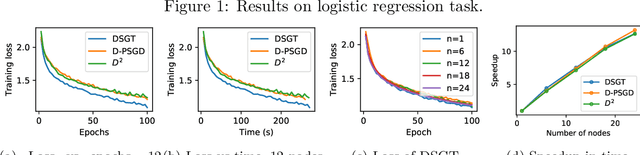
Recent works have shown superiorities of decentralized SGD to centralized counterparts in large-scale machine learning, but their theoretical gap is still not fully understood. In this paper, we propose a decentralized stochastic gradient tracking (DSGT) algorithm over peer-to-peer networks for empirical risk minimization problems, and explicitly evaluate its convergence rate in terms of key parameters of the problem, e.g., algebraic connectivity of the communication network, mini-batch size, and gradient variance. Importantly, it is the first theoretical result that can \emph{exactly} recover the rate of the centralized SGD, and has optimal dependence on the algebraic connectivity of the networks when using stochastic gradients. Moreover, we explicitly quantify how the network affects speedup and the rate improvement over existing works. Interestingly, we also point out for the first time that both linear and sublinear speedup can be possible. We empirically validate DSGT on neural networks and logistic regression problems, and show its advantage over the state-of-the-art algorithms.