 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Tokens: Semantic-Aware Speculative Decoding for Efficient Inference by Probing Internal States
Feb 03, 2026Large Language Models (LLMs) achieve strong performance across many tasks but suffer from high inference latency due to autoregressive decoding. The issue is exacerbated in Large Reasoning Models (LRMs), which generate lengthy chains of thought. While speculative decoding accelerates inference by drafting and verifying multiple tokens in parallel, existing methods operate at the token level and ignore semantic equivalence (i.e., different token sequences expressing the same meaning), leading to inefficient rejections. We propose SemanticSpec, a semantic-aware speculative decoding framework that verifies entire semantic sequences instead of tokens. SemanticSpec introduces a semantic probability estimation mechanism that probes the model's internal hidden states to assess the likelihood of generating sequences with specific meanings.Experiments on four benchmarks show that SemanticSpec achieves up to 2.7x speedup on DeepSeekR1-32B and 2.1x on QwQ-32B, consistently outperforming token-level and sequence-level baselines in both efficiency and effectiveness.
Towards Conversational Development Environments: Using Theory-of-Mind and Multi-Agent Architectures for Requirements Refinement
May 28, 2025



Foundation Models (FMs) have shown remarkable capabilities in various natural language tasks. However, their ability to accurately capture stakeholder requirements remains a significant challenge for using FMs for software development. This paper introduces a novel approach that leverages an FM-powered multi-agent system called AlignMind to address this issue. By having a cognitive architecture that enhances FMs with Theory-of-Mind capabilities, our approach considers the mental states and perspectives of software makers. This allows our solution to iteratively clarify the beliefs, desires, and intentions of stakeholders, translating these into a set of refined requirements and a corresponding actionable natural language workflow in the often-overlooked requirements refinement phase of software engineering, which is crucial after initial elicitation. Through a multifaceted evaluation covering 150 diverse use cases, we demonstrate that our approach can accurately capture the intents and requirements of stakeholders, articulating them as both specifications and a step-by-step plan of action. Our findings suggest that the potential for significant improvements in the software development process justifies these investments. Our work lays the groundwork for future innovation in building intent-first development environments, where software makers can seamlessly collaborate with AIs to create software that truly meets their needs.
The Hitchhikers Guide to Production-ready Trustworthy Foundation Model powered Software (FMware)
May 15, 2025
Foundation Models (FMs) such as Large Language Models (LLMs) are reshaping the software industry by enabling FMware, systems that integrate these FMs as core components. In this KDD 2025 tutorial, we present a comprehensive exploration of FMware that combines a curated catalogue of challenges with real-world production concerns. We first discuss the state of research and practice in building FMware. We further examine the difficulties in selecting suitable models, aligning high-quality domain-specific data, engineering robust prompts, and orchestrating autonomous agents. We then address the complex journey from impressive demos to production-ready systems by outlining issues in system testing, optimization, deployment, and integration with legacy software. Drawing on our industrial experience and recent research in the area, we provide actionable insights and a technology roadmap for overcoming these challenges. Attendees will gain practical strategies to enable the creation of trustworthy FMware in the evolving technology landscape.
Model Performance-Guided Evaluation Data Selection for Effective Prompt Optimization
May 15, 2025



Optimizing Large Language Model (LLM) performance requires well-crafted prompts, but manual prompt engineering is labor-intensive and often ineffective. Automated prompt optimization techniques address this challenge but the majority of them rely on randomly selected evaluation subsets, which fail to represent the full dataset, leading to unreliable evaluations and suboptimal prompts. Existing coreset selection methods, designed for LLM benchmarking, are unsuitable for prompt optimization due to challenges in clustering similar samples, high data collection costs, and the unavailability of performance data for new or private datasets. To overcome these issues, we propose IPOMP, an Iterative evaluation data selection for effective Prompt Optimization using real-time Model Performance. IPOMP is a two-stage approach that selects representative and diverse samples using semantic clustering and boundary analysis, followed by iterative refinement with real-time model performance data to replace redundant samples. Evaluations on the BIG-bench dataset show that IPOMP improves effectiveness by 1.6% to 5.3% and stability by at least 57% compared with SOTA baselines, with minimal computational overhead below 1%. Furthermore, the results demonstrate that our real-time performance-guided refinement approach can be universally applied to enhance existing coreset selection methods.
Engineering AI Judge Systems
Nov 26, 2024

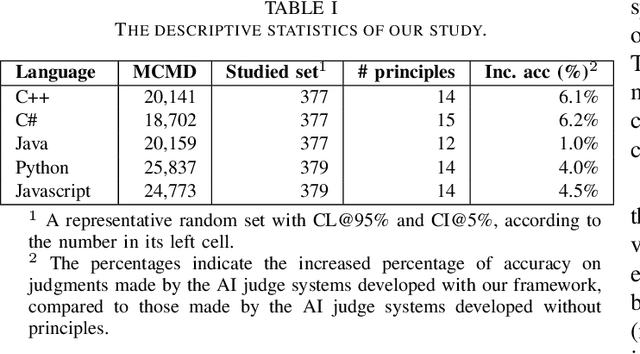
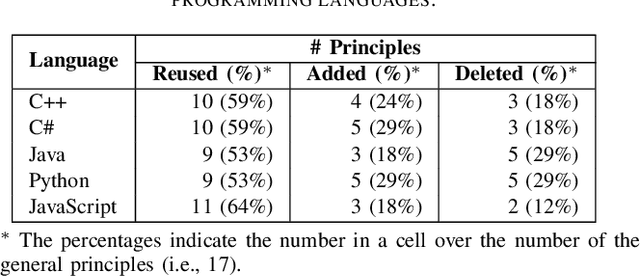
AI judge systems are designed to automatically evaluate Foundation Model-powered software (i.e., FMware). Due to the intrinsic dynamic and stochastic nature of FMware, the development of AI judge systems requires a unique engineering life cycle and presents new challenges. In this paper, we discuss the challenges based on our industrial experiences in developing AI judge systems for FMware. These challenges lead to substantial time consumption, cost and inaccurate judgments. We propose a framework that tackles the challenges with the goal of improving the productivity of developing high-quality AI judge systems. Finally, we evaluate our framework with a case study on judging a commit message generation FMware. The accuracy of the judgments made by the AI judge system developed with our framework outperforms those made by the AI judge system that is developed without our framework by up to 6.2%, with a significant reduction in development effort.
Real-time Adapting Routing (RAR): Improving Efficiency Through Continuous Learning in Software Powered by Layered Foundation Models
Nov 14, 2024



To balance the quality and inference cost of a Foundation Model (FM, such as large language models (LLMs)) powered software, people often opt to train a routing model that routes requests to FMs with different sizes and capabilities. Existing routing models rely on learning the optimal routing decision from carefully curated data, require complex computations to be updated, and do not consider the potential evolution of weaker FMs. In this paper, we propose Real-time Adaptive Routing (RAR), an approach to continuously adapt FM routing decisions while using guided in-context learning to enhance the capabilities of weaker FM. The goal is to reduce reliance on stronger, more expensive FMs. We evaluate our approach on different subsets of the popular MMLU benchmark. Over time, our approach routes 50.2% fewer requests to computationally expensive models while maintaining around 90.5% of the general response quality. In addition, the guides generated from stronger models have shown intra-domain generalization and led to a better quality of responses compared to an equivalent approach with a standalone weaker FM.
Watson: A Cognitive Observability Framework for the Reasoning of Foundation Model-Powered Agents
Nov 05, 2024



As foundation models (FMs) play an increasingly prominent role in complex software systems, such as FM-powered agentic software (i.e., Agentware), they introduce significant challenges for developers regarding observability. Unlike traditional software, agents operate autonomously, using extensive data and opaque implicit reasoning, making it difficult to observe and understand their behavior during runtime, especially when they take unexpected actions or encounter errors. In this paper, we highlight the limitations of traditional operational observability in the context of FM-powered software, and introduce cognitive observability as a new type of required observability that has emerged for such innovative systems. We then propose a novel framework that provides cognitive observability into the implicit reasoning processes of agents (a.k.a. reasoning observability), and demonstrate the effectiveness of our framework in boosting the debuggability of Agentware and, in turn, the abilities of an Agentware through a case study on AutoCodeRover, a cuttingedge Agentware for autonomous program improvement.
From Cool Demos to Production-Ready FMware: Core Challenges and a Technology Roadmap
Oct 28, 2024

The rapid expansion of foundation models (FMs), such as large language models (LLMs), has given rise to FMware--software systems that integrate FMs as core components. While building demonstration-level FMware is relatively straightforward, transitioning to production-ready systems presents numerous challenges, including reliability, high implementation costs, scalability, and compliance with privacy regulations. This paper provides a thematic analysis of the key obstacles in productionizing FMware, synthesized from industry experience and diverse data sources, including hands-on involvement in the Open Platform for Enterprise AI (OPEA) and FMware lifecycle engineering. We identify critical issues in FM selection, data and model alignment, prompt engineering, agent orchestration, system testing, and deployment, alongside cross-cutting concerns such as memory management, observability, and feedback integration. We discuss needed technologies and strategies to address these challenges and offer guidance on how to enable the transition from demonstration systems to scalable, production-ready FMware solutions. Our findings underscore the importance of continued research and multi-industry collaboration to advance the development of production-ready FMware.
PromptExp: Multi-granularity Prompt Explanation of Large Language Models
Oct 16, 2024



Large Language Models excel in tasks like natural language understanding and text generation. Prompt engineering plays a critical role in leveraging LLM effectively. However, LLMs black-box nature hinders its interpretability and effective prompting engineering. A wide range of model explanation approaches have been developed for deep learning models, However, these local explanations are designed for single-output tasks like classification and regression,and cannot be directly applied to LLMs, which generate sequences of tokens. Recent efforts in LLM explanation focus on natural language explanations, but they are prone to hallucinations and inaccuracies. To address this, we introduce OurTool, a framework for multi-granularity prompt explanations by aggregating token-level insights. OurTool introduces two token-level explanation approaches: 1.an aggregation-based approach combining local explanation techniques, and 2. a perturbation-based approach with novel techniques to evaluate token masking impact. OurTool supports both white-box and black-box explanations and extends explanations to higher granularity levels, enabling flexible analysis. We evaluate OurTool in case studies such as sentiment analysis, showing the perturbation-based approach performs best using semantic similarity to assess perturbation impact. Furthermore, we conducted a user study to confirm OurTool's accuracy and practical value, and demonstrate its potential to enhance LLM interpretability.
Towards AI-Native Software Engineering (SE 3.0): A Vision and a Challenge Roadmap
Oct 08, 2024



The rise of AI-assisted software engineering (SE 2.0), powered by Foundation Models (FMs) and FM-powered copilots, has shown promise in improving developer productivity. However, it has also exposed inherent limitations, such as cognitive overload on developers and inefficiencies. We propose a shift towards Software Engineering 3.0 (SE 3.0), an AI-native approach characterized by intent-first, conversation-oriented development between human developers and AI teammates. SE 3.0 envisions AI systems evolving beyond task-driven copilots into intelligent collaborators, capable of deeply understanding and reasoning about software engineering principles and intents. We outline the key components of the SE 3.0 technology stack, which includes Teammate.next for adaptive and personalized AI partnership, IDE.next for intent-first conversation-oriented development, Compiler.next for multi-objective code synthesis, and Runtime.next for SLA-aware execution with edge-computing support. Our vision addresses the inefficiencies and cognitive strain of SE 2.0 by fostering a symbiotic relationship between human developers and AI, maximizing their complementary strengths. We also present a roadmap of challenges that must be overcome to realize our vision of SE 3.0. This paper lays the foundation for future discussions on the role of AI in the next era of software engineering.