 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Data-Driven Robotics
Sep 26, 2019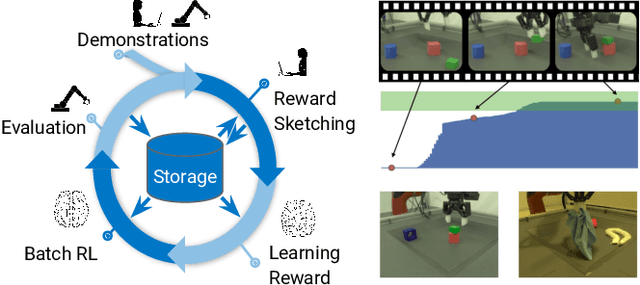
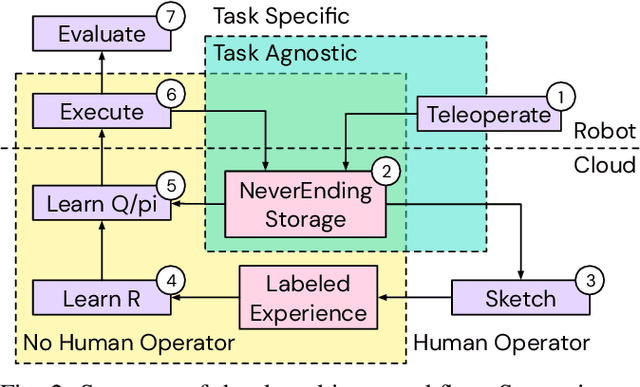
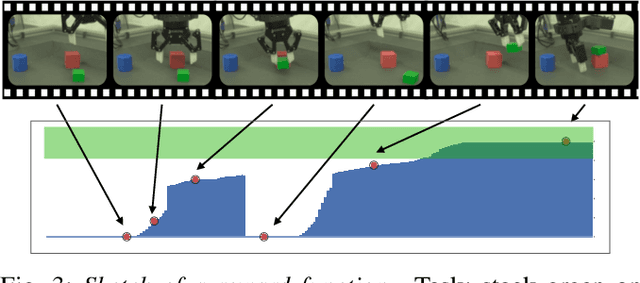
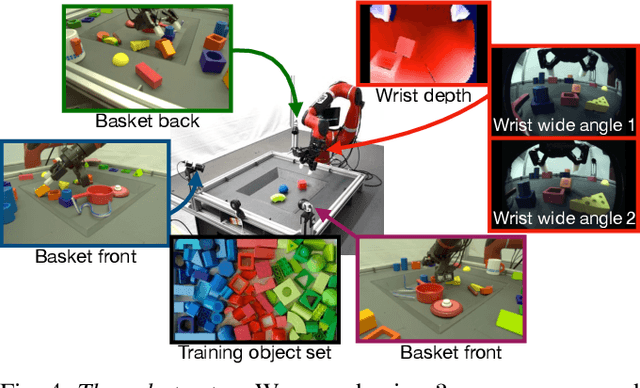
We present a framework for data-driven robotics that makes use of a large dataset of recorded robot experience and scales to several tasks using learned reward functions. We show how to apply this framework to accomplish three different object manipulation tasks on a real robot platform. Given demonstrations of a task together with task-agnostic recorded experience, we use a special form of human annotation as supervision to learn a reward function, which enables us to deal with real-world tasks where the reward signal cannot be acquired directly. Learned rewards are used in combination with a large dataset of experience from different tasks to learn a robot policy offline using batch RL. We show that using our approach it is possible to train agents to perform a variety of challenging manipulation tasks including stacking rigid objects and handling cloth.
One-Shot High-Fidelity Imitation: Training Large-Scale Deep Nets with RL
Oct 11, 2018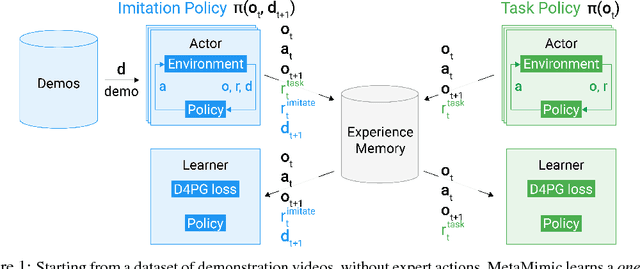
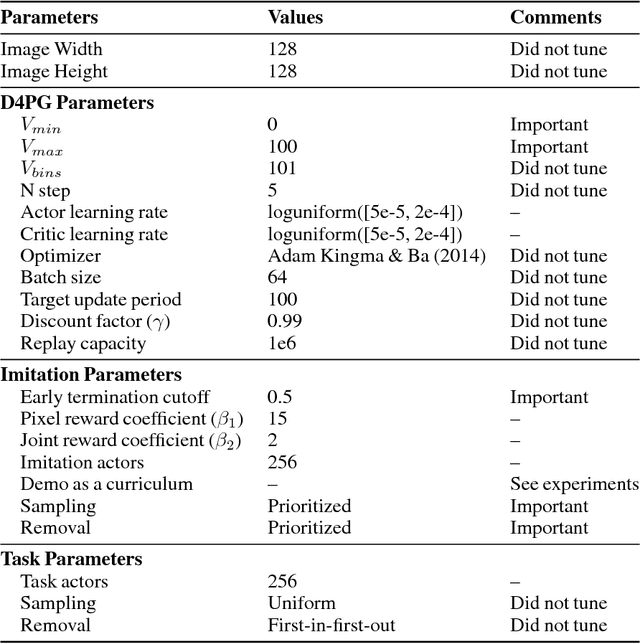
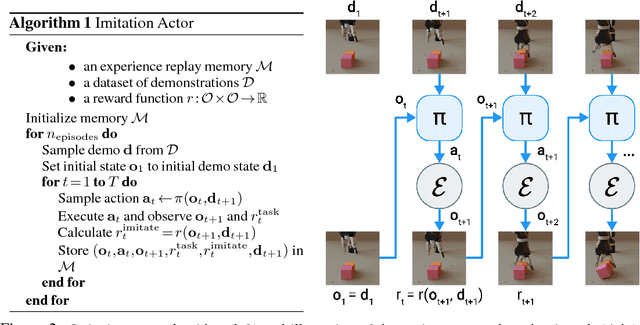
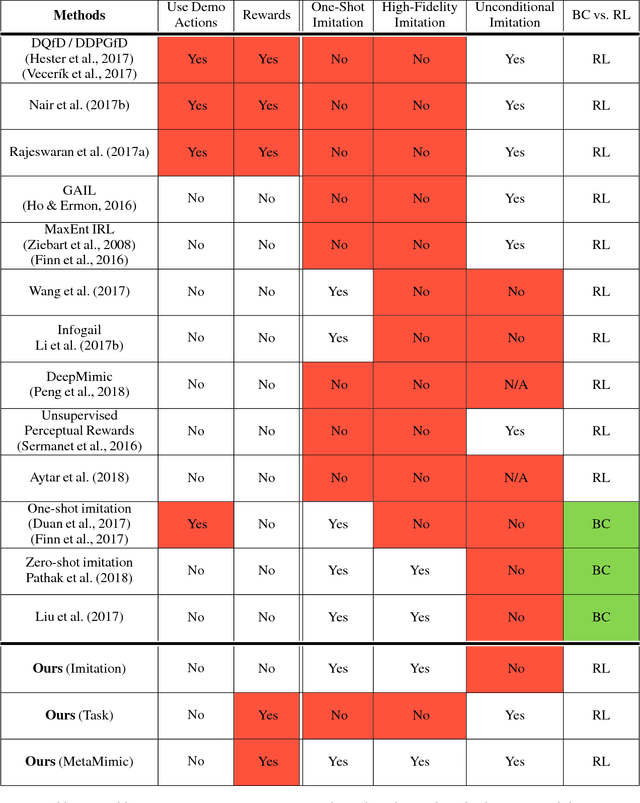
Humans are experts at high-fidelity imitation -- closely mimicking a demonstration, often in one attempt. Humans use this ability to quickly solve a task instance, and to bootstrap learning of new tasks. Achieving these abilities in autonomous agents is an open problem. In this paper, we introduce an off-policy RL algorithm (MetaMimic) to narrow this gap. MetaMimic can learn both (i) policies for high-fidelity one-shot imitation of diverse novel skills, and (ii) policies that enable the agent to solve tasks more efficiently than the demonstrators. MetaMimic relies on the principle of storing all experiences in a memory and replaying these to learn massive deep neural network policies by off-policy RL. This paper introduces, to the best of our knowledge, the largest existing neural networks for deep RL and shows that larger networks with normalization are needed to achieve one-shot high-fidelity imitation on a challenging manipulation task. The results also show that both types of policy can be learned from vision, in spite of the task rewards being sparse, and without access to demonstrator actions.
Reinforcement and Imitation Learning for Diverse Visuomotor Skills
May 27, 2018
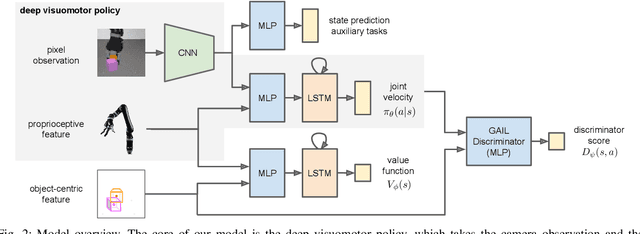
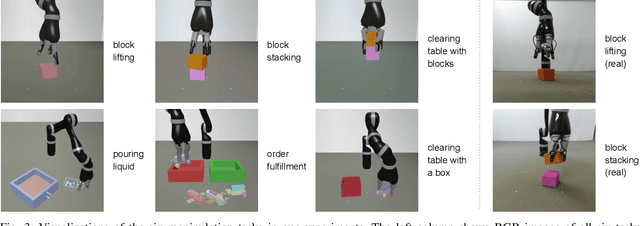
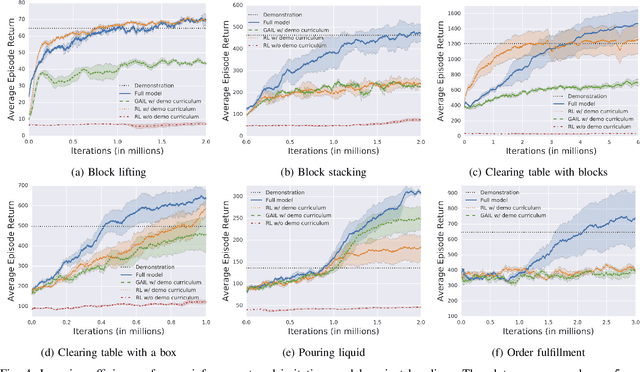
We propose a model-free deep reinforcement learning method that leverages a small amount of demonstration data to assist a reinforcement learning agent. We apply this approach to robotic manipulation tasks and train end-to-end visuomotor policies that map directly from RGB camera inputs to joint velocities. We demonstrate that our approach can solve a wide variety of visuomotor tasks, for which engineering a scripted controller would be laborious. In experiments, our reinforcement and imitation agent achieves significantly better performances than agents trained with reinforcement learning or imitation learning alone. We also illustrate that these policies, trained with large visual and dynamics variations, can achieve preliminary successes in zero-shot sim2real transfer. A brief visual description of this work can be viewed in https://youtu.be/EDl8SQUNjj0
Learning Awareness Models
Apr 17, 2018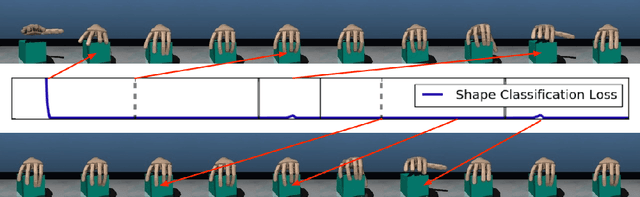
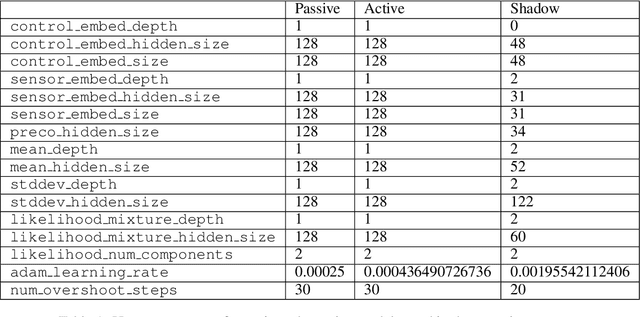

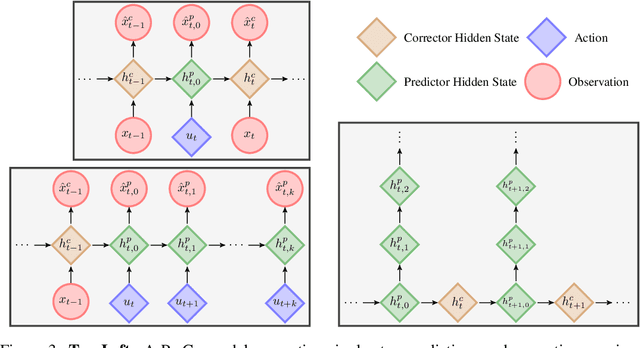
We consider the setting of an agent with a fixed body interacting with an unknown and uncertain external world. We show that models trained to predict proprioceptive information about the agent's body come to represent objects in the external world. In spite of being trained with only internally available signals, these dynamic body models come to represent external objects through the necessity of predicting their effects on the agent's own body. That is, the model learns holistic persistent representations of objects in the world, even though the only training signals are body signals. Our dynamics model is able to successfully predict distributions over 132 sensor readings over 100 steps into the future and we demonstrate that even when the body is no longer in contact with an object, the latent variables of the dynamics model continue to represent its shape. We show that active data collection by maximizing the entropy of predictions about the body---touch sensors, proprioception and vestibular information---leads to learning of dynamic models that show superior performance when used for control. We also collect data from a real robotic hand and show that the same models can be used to answer questions about properties of objects in the real world. Videos with qualitative results of our models are available at https://goo.gl/mZuqAV.
The Intentional Unintentional Agent: Learning to Solve Many Continuous Control Tasks Simultaneously
Jul 11, 2017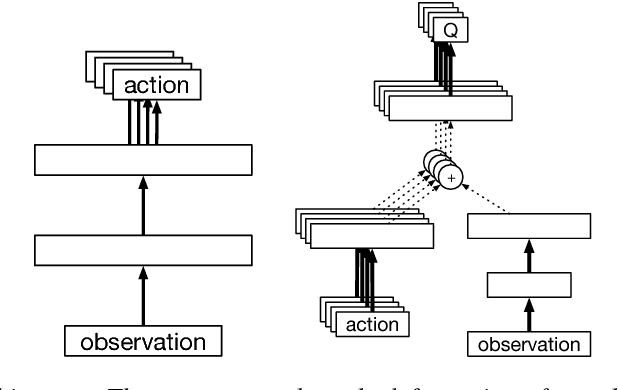

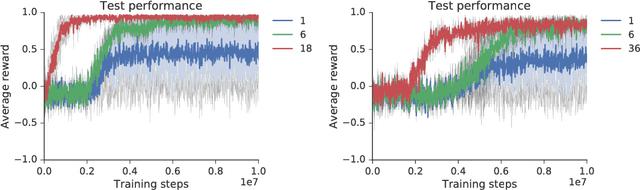
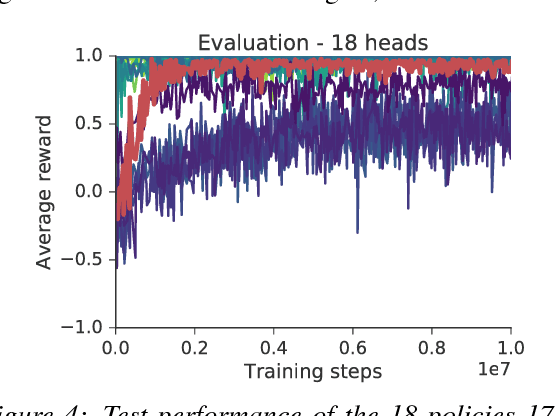
This paper introduces the Intentional Unintentional (IU) agent. This agent endows the deep deterministic policy gradients (DDPG) agent for continuous control with the ability to solve several tasks simultaneously. Learning to solve many tasks simultaneously has been a long-standing, core goal of artificial intelligence, inspired by infant development and motivated by the desire to build flexible robot manipulators capable of many diverse behaviours. We show that the IU agent not only learns to solve many tasks simultaneously but it also learns faster than agents that target a single task at-a-time. In some cases, where the single task DDPG method completely fails, the IU agent successfully solves the task. To demonstrate this, we build a playroom environment using the MuJoCo physics engine, and introduce a grounded formal language to automatically generate tasks.
Programmable Agents
Jun 20, 2017
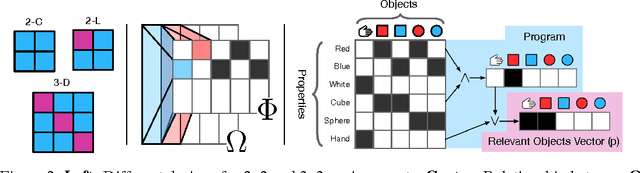

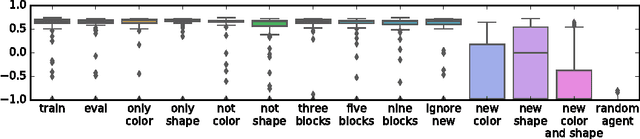
We build deep RL agents that execute declarative programs expressed in formal language. The agents learn to ground the terms in this language in their environment, and can generalize their behavior at test time to execute new programs that refer to objects that were not referenced during training. The agents develop disentangled interpretable representations that allow them to generalize to a wide variety of zero-shot semantic tasks.