 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-free Compositional Action Generation via Decoupling Refinement
Jul 07, 2023Composing simple elements into complex concepts is crucial yet challenging, especially for 3D action generation. Existing methods largely rely on extensive neural language annotations to discern composable latent semantics, a process that is often costly and labor-intensive. In this study, we introduce a novel framework to generate compositional actions without reliance on language auxiliaries. Our approach consists of three main components: Action Coupling, Conditional Action Generation, and Decoupling Refinement. Action Coupling utilizes an energy model to extract the attention masks of each sub-action, subsequently integrating two actions using these attentions to generate pseudo-training examples. Then, we employ a conditional generative model, CVAE, to learn a latent space, facilitating the diverse generation. Finally, we propose Decoupling Refinement, which leverages a self-supervised pre-trained model MAE to ensure semantic consistency between the sub-actions and compositional actions. This refinement process involves rendering generated 3D actions into 2D space, decoupling these images into two sub-segments, using the MAE model to restore the complete image from sub-segments, and constraining the recovered images to match images rendered from raw sub-actions. Due to the lack of existing datasets containing both sub-actions and compositional actions, we created two new datasets, named HumanAct-C and UESTC-C, and present a corresponding evaluation metric. Both qualitative and quantitative assessments are conducted to show our efficacy.
Graph Inductive Biases in Transformers without Message Passing
May 27, 2023



Transformers for graph data are increasingly widely studied and successful in numerous learning tasks. Graph inductive biases are crucial for Graph Transformers, and previous works incorporate them using message-passing modules and/or positional encodings. However, Graph Transformers that use message-passing inherit known issues of message-passing, and differ significantly from Transformers used in other domains, thus making transfer of research advances more difficult. On the other hand, Graph Transformers without message-passing often perform poorly on smaller datasets, where inductive biases are more crucial. To bridge this gap, we propose the Graph Inductive bias Transformer (GRIT) -- a new Graph Transformer that incorporates graph inductive biases without using message passing. GRIT is based on several architectural changes that are each theoretically and empirically justified, including: learned relative positional encodings initialized with random walk probabilities, a flexible attention mechanism that updates node and node-pair representations, and injection of degree information in each layer. We prove that GRIT is expressive -- it can express shortest path distances and various graph propagation matrices. GRIT achieves state-of-the-art empirical performance across a variety of graph datasets, thus showing the power that Graph Transformers without message-passing can deliver.
Rapid Adaptation in Online Continual Learning: Are We Evaluating It Right?
May 16, 2023We revisit the common practice of evaluating adaptation of Online Continual Learning (OCL) algorithms through the metric of online accuracy, which measures the accuracy of the model on the immediate next few samples. However, we show that this metric is unreliable, as even vacuous blind classifiers, which do not use input images for prediction, can achieve unrealistically high online accuracy by exploiting spurious label correlations in the data stream. Our study reveals that existing OCL algorithms can also achieve high online accuracy, but perform poorly in retaining useful information, suggesting that they unintentionally learn spurious label correlations. To address this issue, we propose a novel metric for measuring adaptation based on the accuracy on the near-future samples, where spurious correlations are removed. We benchmark existing OCL approaches using our proposed metric on large-scale datasets under various computational budgets and find that better generalization can be achieved by retaining and reusing past seen information. We believe that our proposed metric can aid in the development of truly adaptive OCL methods. We provide code to reproduce our results at https://github.com/drimpossible/EvalOCL.
LASER: Neuro-Symbolic Learning of Semantic Video Representations
Apr 15, 2023Modern AI applications involving video, such as video-text alignment, video search, and video captioning, benefit from a fine-grained understanding of video semantics. Existing approaches for video understanding are either data-hungry and need low-level annotation, or are based on general embeddings that are uninterpretable and can miss important details. We propose LASER, a neuro-symbolic approach that learns semantic video representations by leveraging logic specifications that can capture rich spatial and temporal properties in video data. In particular, we formulate the problem in terms of alignment between raw videos and specifications. The alignment process efficiently trains low-level perception models to extract a fine-grained video representation that conforms to the desired high-level specification. Our pipeline can be trained end-to-end and can incorporate contrastive and semantic loss functions derived from specifications. We evaluate our method on two datasets with rich spatial and temporal specifications: 20BN-Something-Something and MUGEN. We demonstrate that our method not only learns fine-grained video semantics but also outperforms existing baselines on downstream tasks such as video retrieval.
HNeRV: A Hybrid Neural Representation for Videos
Apr 05, 2023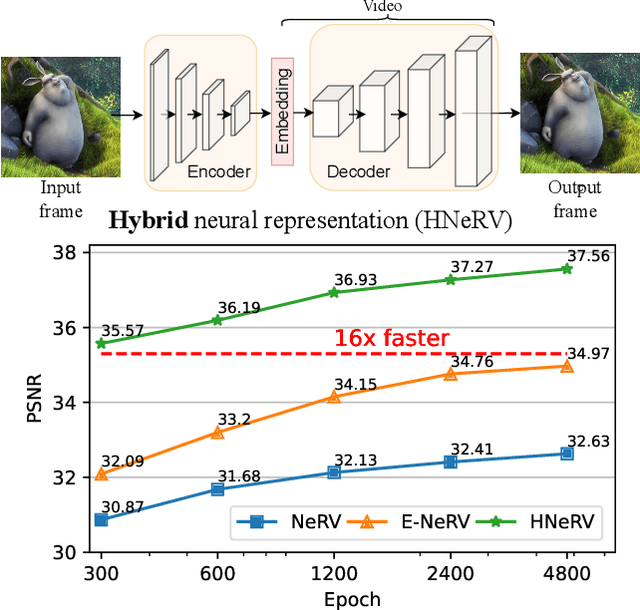



Implicit neural representations store videos as neural networks and have performed well for various vision tasks such as video compression and denoising. With frame index or positional index as input, implicit representations (NeRV, E-NeRV, \etc) reconstruct video from fixed and content-agnostic embeddings. Such embedding largely limits the regression capacity and internal generalization for video interpolation. In this paper, we propose a Hybrid Neural Representation for Videos (HNeRV), where a learnable encoder generates content-adaptive embeddings, which act as the decoder input. Besides the input embedding, we introduce HNeRV blocks, which ensure model parameters are evenly distributed across the entire network, such that higher layers (layers near the output) can have more capacity to store high-resolution content and video details. With content-adaptive embeddings and re-designed architecture, HNeRV outperforms implicit methods in video regression tasks for both reconstruction quality ($+4.7$ PSNR) and convergence speed ($16\times$ faster), and shows better internal generalization. As a simple and efficient video representation, HNeRV also shows decoding advantages for speed, flexibility, and deployment, compared to traditional codecs~(H.264, H.265) and learning-based compression methods. Finally, we explore the effectiveness of HNeRV on downstream tasks such as video compression and video inpainting. We provide project page at https://haochen-rye.github.io/HNeRV, and Code at https://github.com/haochen-rye/HNeRV
Detecting Everything in the Open World: Towards Universal Object Detection
Mar 27, 2023In this paper, we formally address universal object detection, which aims to detect every scene and predict every category. The dependence on human annotations, the limited visual information, and the novel categories in the open world severely restrict the universality of traditional detectors. We propose UniDetector, a universal object detector that has the ability to recognize enormous categories in the open world. The critical points for the universality of UniDetector are: 1) it leverages images of multiple sources and heterogeneous label spaces for training through the alignment of image and text spaces, which guarantees sufficient information for universal representations. 2) it generalizes to the open world easily while keeping the balance between seen and unseen classes, thanks to abundant information from both vision and language modalities. 3) it further promotes the generalization ability to novel categories through our proposed decoupling training manner and probability calibration. These contributions allow UniDetector to detect over 7k categories, the largest measurable category size so far, with only about 500 classes participating in training. Our UniDetector behaves the strong zero-shot generalization ability on large-vocabulary datasets like LVIS, ImageNetBoxes, and VisualGenome - it surpasses the traditional supervised baselines by more than 4\% on average without seeing any corresponding images. On 13 public detection datasets with various scenes, UniDetector also achieves state-of-the-art performance with only a 3\% amount of training data.
Towards Scalable Neural Representation for Diverse Videos
Mar 24, 2023



Implicit neural representations (INR) have gained increasing attention in representing 3D scenes and images, and have been recently applied to encode videos (e.g., NeRV, E-NeRV). While achieving promising results, existing INR-based methods are limited to encoding a handful of short videos (e.g., seven 5-second videos in the UVG dataset) with redundant visual content, leading to a model design that fits individual video frames independently and is not efficiently scalable to a large number of diverse videos. This paper focuses on developing neural representations for a more practical setup -- encoding long and/or a large number of videos with diverse visual content. We first show that instead of dividing videos into small subsets and encoding them with separate models, encoding long and diverse videos jointly with a unified model achieves better compression results. Based on this observation, we propose D-NeRV, a novel neural representation framework designed to encode diverse videos by (i) decoupling clip-specific visual content from motion information, (ii) introducing temporal reasoning into the implicit neural network, and (iii) employing the task-oriented flow as intermediate output to reduce spatial redundancies. Our new model largely surpasses NeRV and traditional video compression techniques on UCF101 and UVG datasets on the video compression task. Moreover, when used as an efficient data-loader, D-NeRV achieves 3%-10% higher accuracy than NeRV on action recognition tasks on the UCF101 dataset under the same compression ratios.
Open-vocabulary Panoptic Segmentation with Embedding Modulation
Mar 20, 2023Open-vocabulary image segmentation is attracting increasing attention due to its critical applications in the real world. Traditional closed-vocabulary segmentation methods are not able to characterize novel objects, whereas several recent open-vocabulary attempts obtain unsatisfactory results, i.e., notable performance reduction on the closed vocabulary and massive demand for extra data. To this end, we propose OPSNet, an omnipotent and data-efficient framework for Open-vocabulary Panoptic Segmentation. Specifically, the exquisitely designed Embedding Modulation module, together with several meticulous components, enables adequate embedding enhancement and information exchange between the segmentation model and the visual-linguistic well-aligned CLIP encoder, resulting in superior segmentation performance under both open- and closed-vocabulary settings with much fewer need of additional data. Extensive experimental evaluations are conducted across multiple datasets (e.g., COCO, ADE20K, Cityscapes, and PascalContext) under various circumstances, where the proposed OPSNet achieves state-of-the-art results, which demonstrates the effectiveness and generality of the proposed approach. The code and trained models will be made publicly available.
ScribbleSeg: Scribble-based Interactive Image Segmentation
Mar 20, 2023Interactive segmentation enables users to extract masks by providing simple annotations to indicate the target, such as boxes, clicks, or scribbles. Among these interaction formats, scribbles are the most flexible as they can be of arbitrary shapes and sizes. This enables scribbles to provide more indications of the target object. However, previous works mainly focus on click-based configuration, and the scribble-based setting is rarely explored. In this work, we attempt to formulate a standard protocol for scribble-based interactive segmentation. Basically, we design diversified strategies to simulate scribbles for training, propose a deterministic scribble generator for evaluation, and construct a challenging benchmark. Besides, we build a strong framework ScribbleSeg, consisting of a Prototype Adaption Module(PAM) and a Corrective Refine Module (CRM), for the task. Extensive experiments show that ScribbleSeg performs notably better than previous click-based methods. We hope this could serve as a more powerful and general solution for interactive segmentation. Our code will be made available.
Computationally Budgeted Continual Learning: What Does Matter?
Mar 20, 2023Continual Learning (CL) aims to sequentially train models on streams of incoming data that vary in distribution by preserving previous knowledge while adapting to new data. Current CL literature focuses on restricted access to previously seen data, while imposing no constraints on the computational budget for training. This is unreasonable for applications in-the-wild, where systems are primarily constrained by computational and time budgets, not storage. We revisit this problem with a large-scale benchmark and analyze the performance of traditional CL approaches in a compute-constrained setting, where effective memory samples used in training can be implicitly restricted as a consequence of limited computation. We conduct experiments evaluating various CL sampling strategies, distillation losses, and partial fine-tuning on two large-scale datasets, namely ImageNet2K and Continual Google Landmarks V2 in data incremental, class incremental, and time incremental settings. Through extensive experiments amounting to a total of over 1500 GPU-hours, we find that, under compute-constrained setting, traditional CL approaches, with no exception, fail to outperform a simple minimal baseline that samples uniformly from memory. Our conclusions are consistent in a different number of stream time steps, e.g., 20 to 200, and under several computational budgets. This suggests that most existing CL methods are particularly too computationally expensive for realistic budgeted deployment. Code for this project is available at: https://github.com/drimpossible/BudgetCL.