 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiSimLoc: Visual Global Localization for Previously Unseen Environments with Simulated Images
Sep 14, 2022


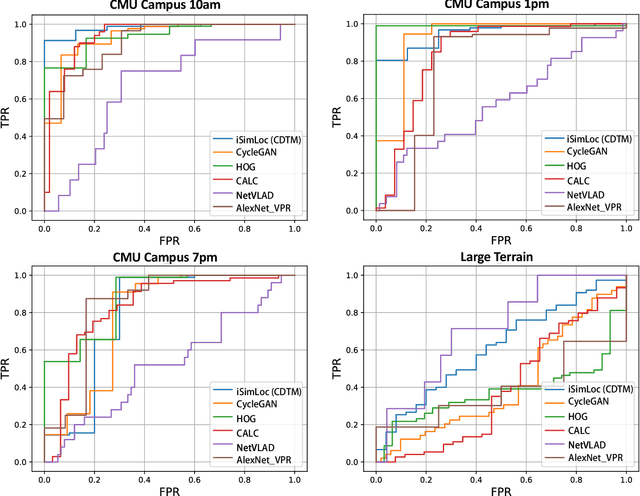
The visual camera is an attractive device in beyond visual line of sight (B-VLOS) drone operation, since they are low in size, weight, power, and cost, and can provide redundant modality to GPS failures. However, state-of-the-art visual localization algorithms are unable to match visual data that have a significantly different appearance due to illuminations or viewpoints. This paper presents iSimLoc, a condition/viewpoint consistent hierarchical global re-localization approach. The place features of iSimLoc can be utilized to search target images under changing appearances and viewpoints. Additionally, our hierarchical global re-localization module refines in a coarse-to-fine manner, allowing iSimLoc to perform a fast and accurate estimation. We evaluate our method on one dataset with appearance variations and one dataset that focuses on demonstrating large-scale matching over a long flight in complicated environments. On our two datasets, iSimLoc achieves 88.7\% and 83.8\% successful retrieval rates with 1.5s inferencing time, compared to 45.8% and 39.7% using the next best method. These results demonstrate robust localization in a range of environments.
General Place Recognition Survey: Towards the Real-world Autonomy Age
Sep 09, 2022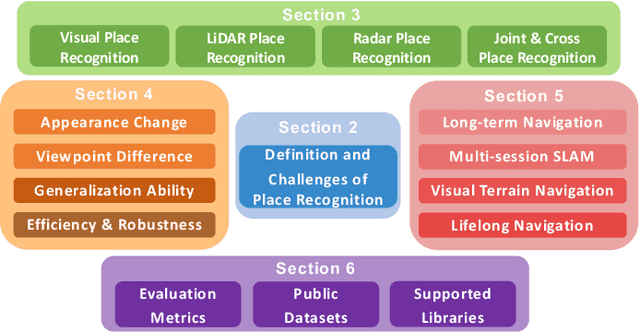
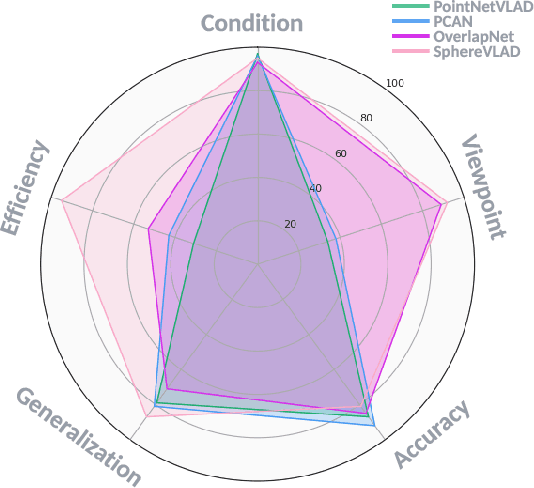

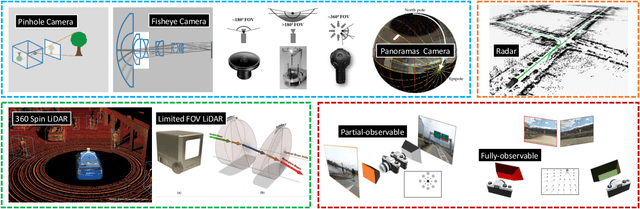
Place recognition is the fundamental module that can assist Simultaneous Localization and Mapping (SLAM) in loop-closure detection and re-localization for long-term navigation. The place recognition community has made astonishing progress over the last $20$ years, and this has attracted widespread research interest and application in multiple fields such as computer vision and robotics. However, few methods have shown promising place recognition performance in complex real-world scenarios, where long-term and large-scale appearance changes usually result in failures. Additionally, there is a lack of an integrated framework amongst the state-of-the-art methods that can handle all of the challenges in place recognition, which include appearance changes, viewpoint differences, robustness to unknown areas, and efficiency in real-world applications. In this work, we survey the state-of-the-art methods that target long-term localization and discuss future directions and opportunities. We start by investigating the formulation of place recognition in long-term autonomy and the major challenges in real-world environments. We then review the recent works in place recognition for different sensor modalities and current strategies for dealing with various place recognition challenges. Finally, we review the existing datasets for long-term localization and introduce our datasets and evaluation API for different approaches. This paper can be a tutorial for researchers new to the place recognition community and those who care about long-term robotics autonomy. We also provide our opinion on the frequently asked question in robotics: Do robots need accurate localization for long-term autonomy? A summary of this work and our datasets and evaluation API is publicly available to the robotics community at: https://github.com/MetaSLAM/GPRS.
BioSLAM: A Bio-inspired Lifelong Memory System for General Place Recognition
Aug 30, 2022
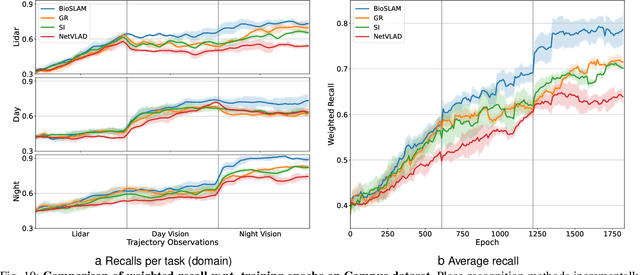
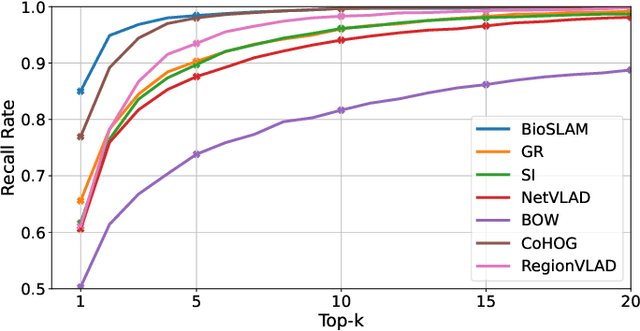
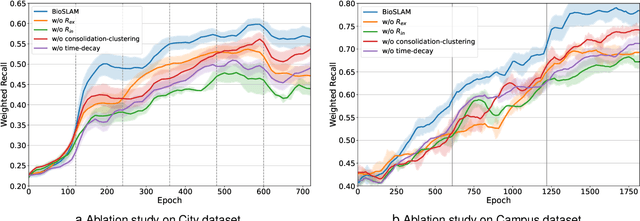
We present BioSLAM, a lifelong SLAM framework for learning various new appearances incrementally and maintaining accurate place recognition for previously visited areas. Unlike humans, artificial neural networks suffer from catastrophic forgetting and may forget the previously visited areas when trained with new arrivals. For humans, researchers discover that there exists a memory replay mechanism in the brain to keep the neuron active for previous events. Inspired by this discovery, BioSLAM designs a gated generative replay to control the robot's learning behavior based on the feedback rewards. Specifically, BioSLAM provides a novel dual-memory mechanism for maintenance: 1) a dynamic memory to efficiently learn new observations and 2) a static memory to balance new-old knowledge. When combined with a visual-/LiDAR- based SLAM system, the complete processing pipeline can help the agent incrementally update the place recognition ability, robust to the increasing complexity of long-term place recognition. We demonstrate BioSLAM in two incremental SLAM scenarios. In the first scenario, a LiDAR-based agent continuously travels through a city-scale environment with a 120km trajectory and encounters different types of 3D geometries (open streets, residential areas, commercial buildings). We show that BioSLAM can incrementally update the agent's place recognition ability and outperform the state-of-the-art incremental approach, Generative Replay, by 24%. In the second scenario, a LiDAR-vision-based agent repeatedly travels through a campus-scale area on a 4.5km trajectory. BioSLAM can guarantee the place recognition accuracy to outperform 15\% over the state-of-the-art approaches under different appearances. To our knowledge, BioSLAM is the first memory-enhanced lifelong SLAM system to help incremental place recognition in long-term navigation tasks.
Present and Future of SLAM in Extreme Underground Environments
Aug 02, 2022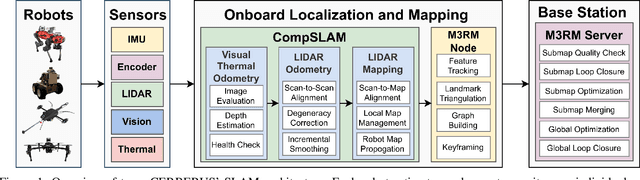
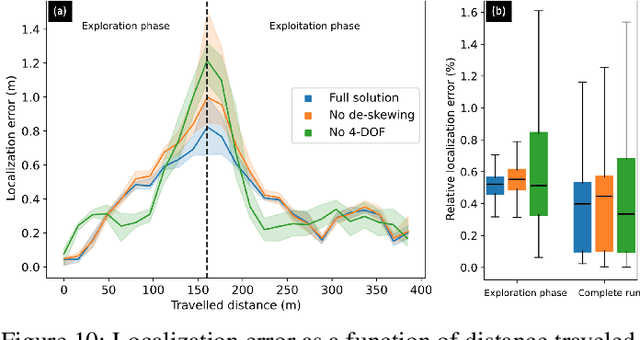
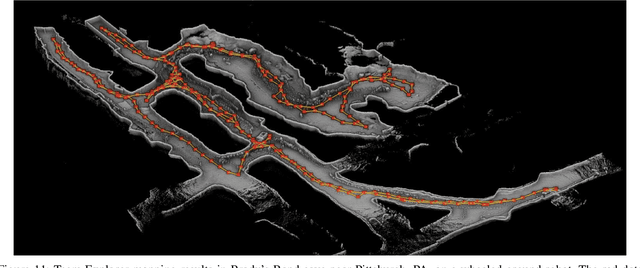
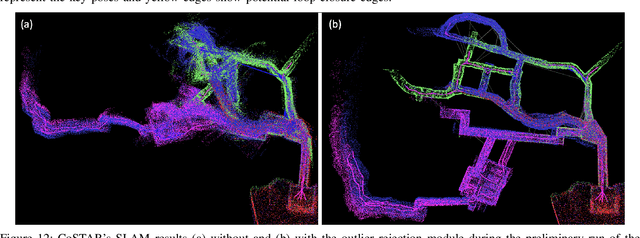
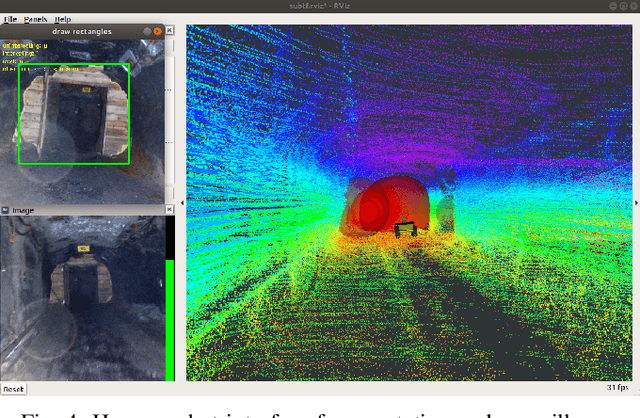
This paper reports on the state of the art in underground SLAM by discussing different SLAM strategies and results across six teams that participated in the three-year-long SubT competition. In particular, the paper has four main goals. First, we review the algorithms, architectures, and systems adopted by the teams; particular emphasis is put on lidar-centric SLAM solutions (the go-to approach for virtually all teams in the competition), heterogeneous multi-robot operation (including both aerial and ground robots), and real-world underground operation (from the presence of obscurants to the need to handle tight computational constraints). We do not shy away from discussing the dirty details behind the different SubT SLAM systems, which are often omitted from technical papers. Second, we discuss the maturity of the field by highlighting what is possible with the current SLAM systems and what we believe is within reach with some good systems engineering. Third, we outline what we believe are fundamental open problems, that are likely to require further research to break through. Finally, we provide a list of open-source SLAM implementations and datasets that have been produced during the SubT challenge and related efforts, and constitute a useful resource for researchers and practitioners.
Robotic Interestingness via Human-Informed Few-Shot Object Detection
Aug 01, 2022
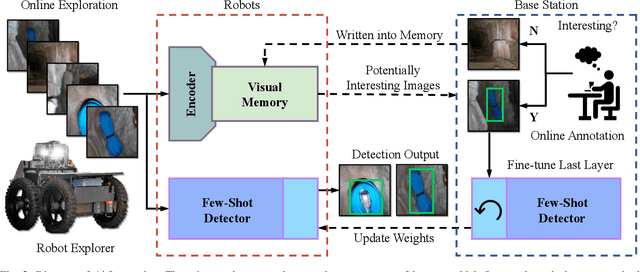
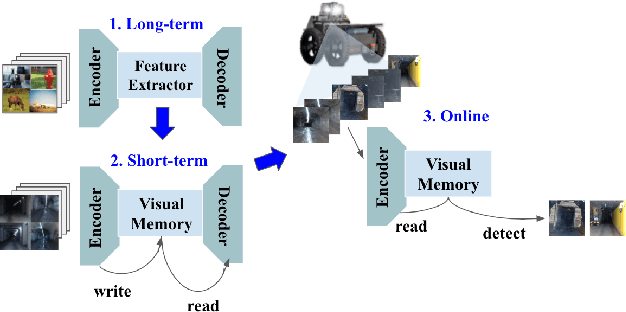
Interestingness recognition is crucial for decision making in autonomous exploration for mobile robots. Previous methods proposed an unsupervised online learning approach that can adapt to environments and detect interesting scenes quickly, but lack the ability to adapt to human-informed interesting objects. To solve this problem, we introduce a human-interactive framework, AirInteraction, that can detect human-informed objects via few-shot online learning. To reduce the communication bandwidth, we first apply an online unsupervised learning algorithm on the unmanned vehicle for interestingness recognition and then only send the potential interesting scenes to a base-station for human inspection. The human operator is able to draw and provide bounding box annotations for particular interesting objects, which are sent back to the robot to detect similar objects via few-shot learning. Only using few human-labeled examples, the robot can learn novel interesting object categories during the mission and detect interesting scenes that contain the objects. We evaluate our method on various interesting scene recognition datasets. To the best of our knowledge, it is the first human-informed few-shot object detection framework for autonomous exploration.
AutoMerge: A Framework for Map Assembling and Smoothing in City-scale Environments
Jul 14, 2022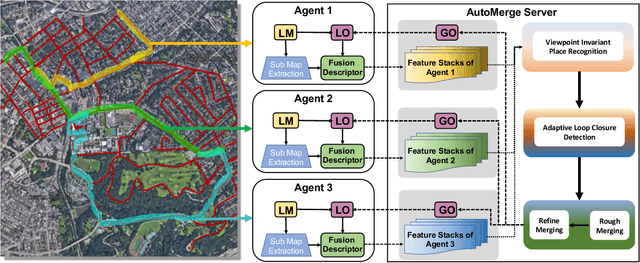
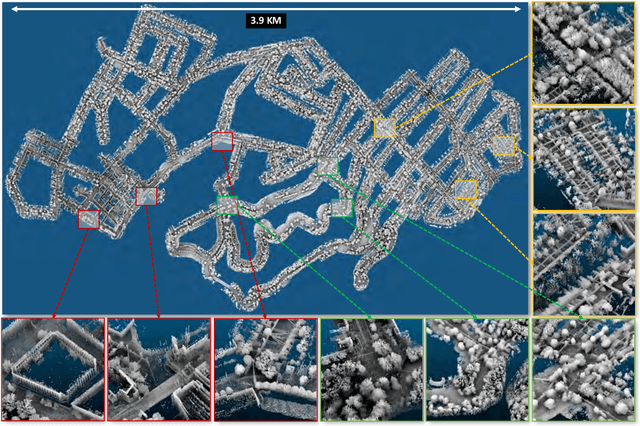
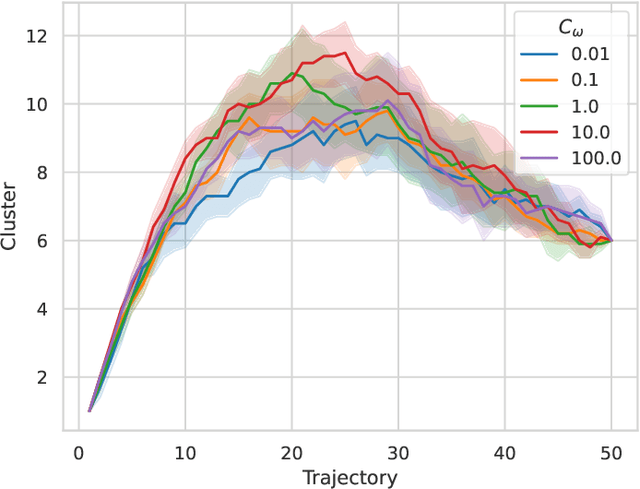
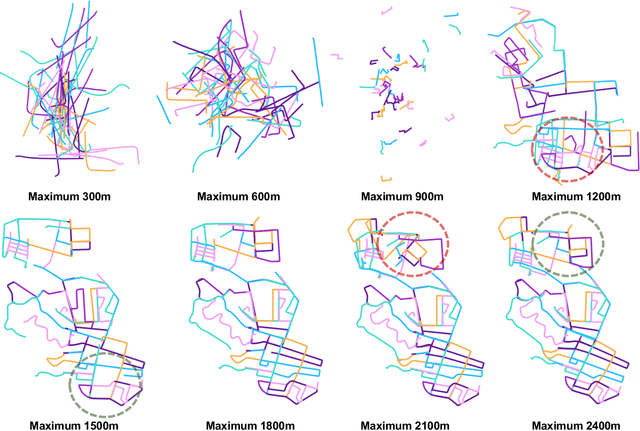
We present AutoMerge, a LiDAR data processing framework for assembling a large number of map segments into a complete map. Traditional large-scale map merging methods are fragile to incorrect data associations, and are primarily limited to working only offline. AutoMerge utilizes multi-perspective fusion and adaptive loop closure detection for accurate data associations, and it uses incremental merging to assemble large maps from individual trajectory segments given in random order and with no initial estimations. Furthermore, after assembling the segments, AutoMerge performs fine matching and pose-graph optimization to globally smooth the merged map. We demonstrate AutoMerge on both city-scale merging (120km) and campus-scale repeated merging (4.5km x 8). The experiments show that AutoMerge (i) surpasses the second- and third- best methods by 14% and 24% recall in segment retrieval, (ii) achieves comparable 3D mapping accuracy for 120 km large-scale map assembly, (iii) and it is robust to temporally-spaced revisits. To the best of our knowledge, AutoMerge is the first mapping approach that can merge hundreds of kilometers of individual segments without the aid of GPS.
SphereVLAD++: Attention-based and Signal-enhanced Viewpoint Invariant Descriptor
Jul 06, 2022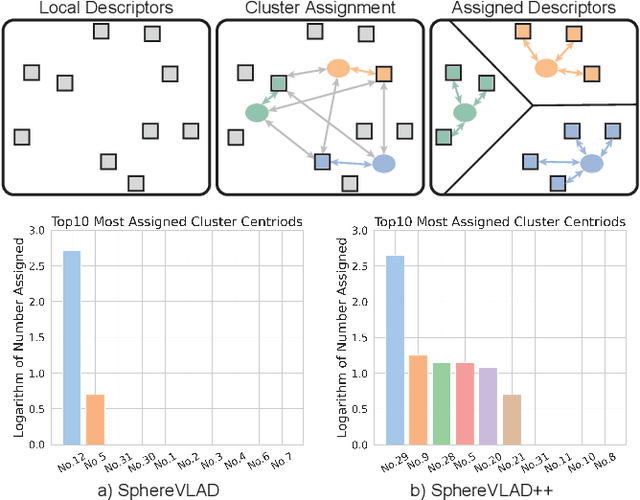
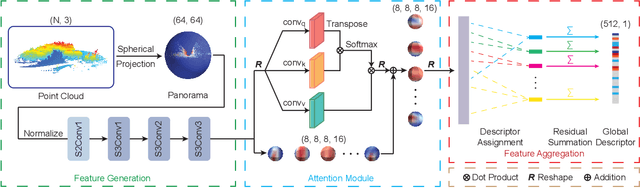
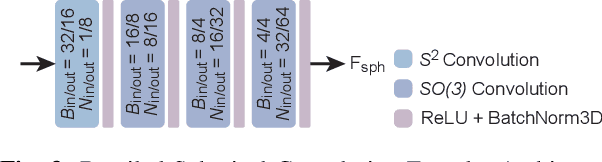
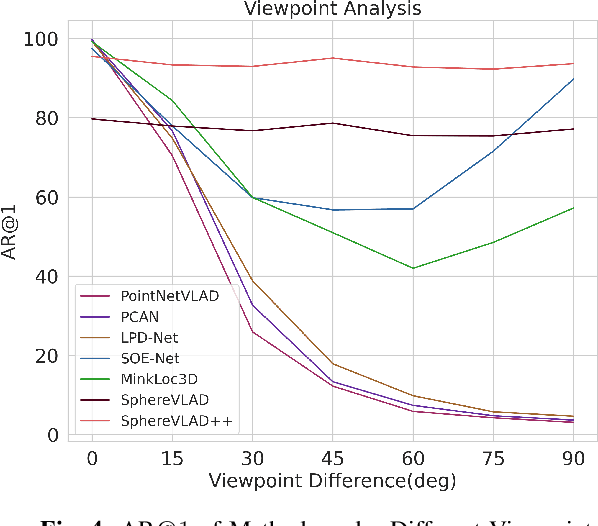
LiDAR-based localization approach is a fundamental module for large-scale navigation tasks, such as last-mile delivery and autonomous driving, and localization robustness highly relies on viewpoints and 3D feature extraction. Our previous work provides a viewpoint-invariant descriptor to deal with viewpoint differences; however, the global descriptor suffers from a low signal-noise ratio in unsupervised clustering, reducing the distinguishable feature extraction ability. We develop SphereVLAD++, an attention-enhanced viewpoint invariant place recognition method in this work. SphereVLAD++ projects the point cloud on the spherical perspective for each unique area and captures the contextual connections between local features and their dependencies with global 3D geometry distribution. In return, clustered elements within the global descriptor are conditioned on local and global geometries and support the original viewpoint-invariant property of SphereVLAD. In the experiments, we evaluated the localization performance of SphereVLAD++ on both public KITTI360 datasets and self-generated datasets from the city of Pittsburgh. The experiment results show that SphereVLAD++ outperforms all relative state-of-the-art 3D place recognition methods under small or even totally reversed viewpoint differences and shows 0.69% and 15.81% successful retrieval rates with better than the second best. Low computation requirements and high time efficiency also help its application for low-cost robots.
VTOL Failure Detection and Recovery by Utilizing Redundancy
Jun 01, 2022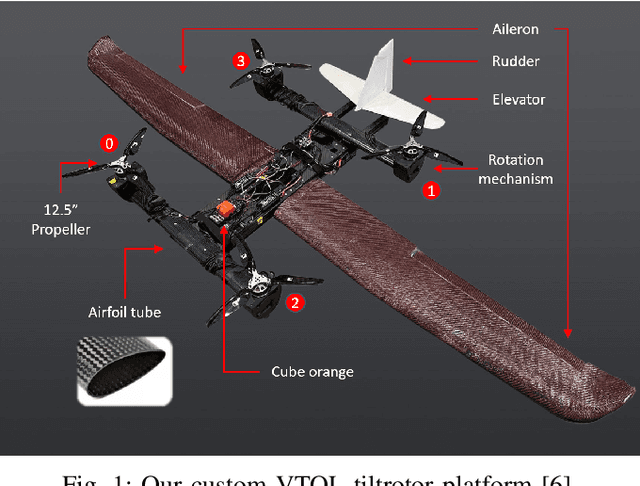
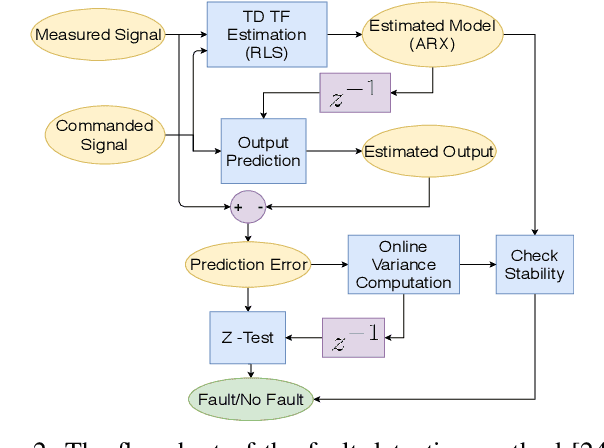
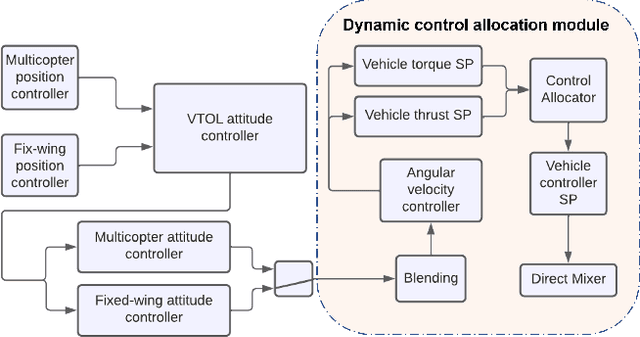
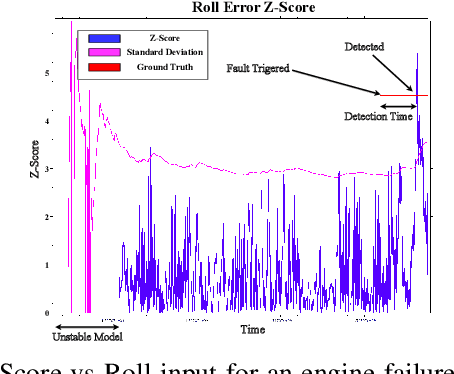
Offering vertical take-off and landing (VTOL) capabilities and the ability to travel great distances are crucial for Urban Air Mobility (UAM) vehicles. These capabilities make hybrid VTOLs the clear front-runners among UAM platforms. On the other hand, concerns regarding the safety and reliability of autonomous aircraft have grown in response to the recent growth in aerial vehicle usage. As a result, monitoring the aircraft status to report any failures and recovering to prevent the loss of control when a failure happens are becoming increasingly important. Hybrid VTOLs can withstand some degree of actuator failure due to their intrinsic redundancy. Their aerodynamic performance, design, modeling, and control have all been addressed in the previous studies. However, research on their potential fault tolerance is still a less investigated field. In this workshop, we will present a summary of our work on aircraft fault detection and the recovery of our hybrid VTOL. First, we will go over our real-time aircraft-independent system for detecting actuator failures and abnormal behaviors. Then, in the context of our custom tiltrotor VTOL aircraft design, we talk about our optimization-based control allocation system, which utilizes the vehicle's configuration redundancy to recover from different actuation failures. Finally, we explore the ideas of how these parts can work together to provide a fail-safe system. We present our simulation and real-life experiments.
Robust Modeling and Controls for Racing on the Edge
May 22, 2022
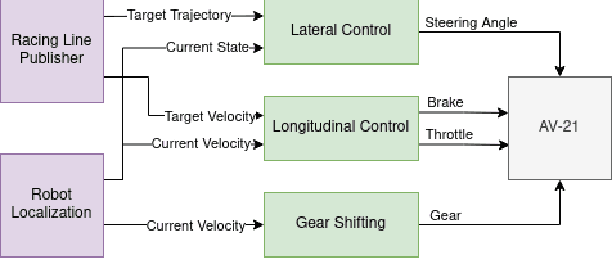
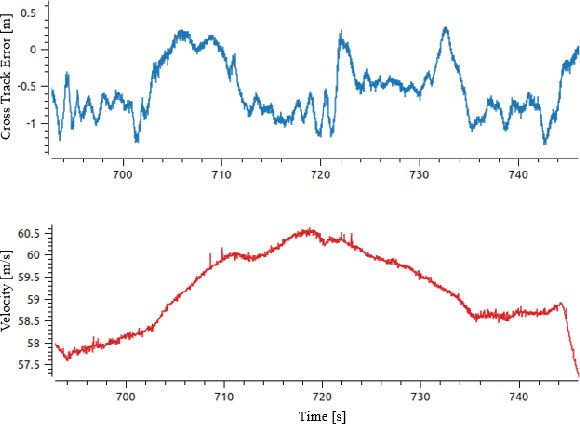

Race cars are routinely driven to the edge of their handling limits in dynamic scenarios well above 200mph. Similar challenges are posed in autonomous racing, where a software stack, instead of a human driver, interacts within a multi-agent environment. For an Autonomous Racing Vehicle (ARV), operating at the edge of handling limits and acting safely in these dynamic environments is still an unsolved problem. In this paper, we present a baseline controls stack for an ARV capable of operating safely up to 140mph. Additionally, limitations in the current approach are discussed to highlight the need for improved dynamics modeling and learning.
ALITA: A Large-scale Incremental Dataset for Long-term Autonomy
May 22, 2022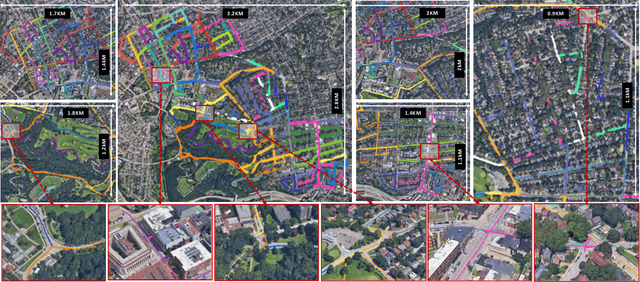
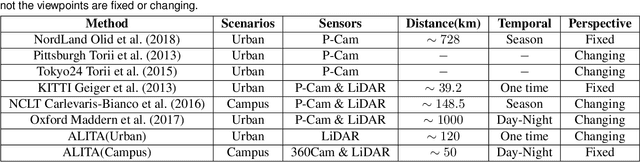

For long-term autonomy, most place recognition methods are mainly evaluated on simplified scenarios or simulated datasets, which cannot provide solid evidence to evaluate the readiness for current Simultaneous Localization and Mapping (SLAM). In this paper, we present a long-term place recognition dataset for use in mobile localization under large-scale dynamic environments. This dataset includes a campus-scale track and a city-scale track: 1) the campus-track focuses the long-term property, we record LiDAR device and an omnidirectional camera on 10 trajectories, and each trajectory are repeatly recorded 8 times under variant illumination conditions. 2) the city-track focuses the large-scale property, we mount the LiDAR device on the vehicle and traversing through a 120km trajectories, which contains open streets, residential areas, natural terrains, etc. They includes 200 hours of raw data of all kinds scenarios within urban environments. The ground truth position for both tracks are provided on each trajectory, which is obtained from the Global Position System with an additional General ICP based point cloud refinement. To simplify the evaluation procedure, we also provide the Python-API with a set of place recognition metrics is proposed to quickly load our dataset and evaluate the recognition performance against different methods. This dataset targets at finding methods with high place recognition accuracy and robustness, and providing real robotic system with long-term autonomy. The dataset and the provided tools can be accessed from https://github.com/MetaSLAM/ALITA.