 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCholecTriplet2021: A benchmark challenge for surgical action triplet recognition
Apr 10, 2022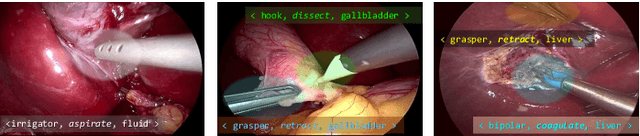

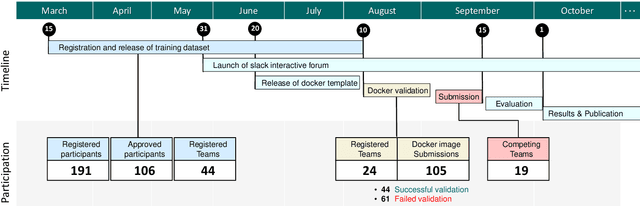
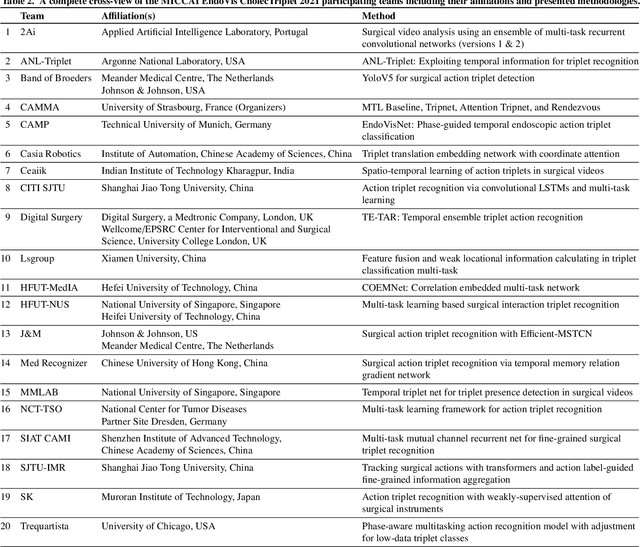
Context-aware decision support in the operating room can foster surgical safety and efficiency by leveraging real-time feedback from surgical workflow analysis. Most existing works recognize surgical activities at a coarse-grained level, such as phases, steps or events, leaving out fine-grained interaction details about the surgical activity; yet those are needed for more helpful AI assistance in the operating room. Recognizing surgical actions as triplets of <instrument, verb, target> combination delivers comprehensive details about the activities taking place in surgical videos. This paper presents CholecTriplet2021: an endoscopic vision challenge organized at MICCAI 2021 for the recognition of surgical action triplets in laparoscopic videos. The challenge granted private access to the large-scale CholecT50 dataset, which is annotated with action triplet information. In this paper, we present the challenge setup and assessment of the state-of-the-art deep learning methods proposed by the participants during the challenge. A total of 4 baseline methods from the challenge organizers and 19 new deep learning algorithms by competing teams are presented to recognize surgical action triplets directly from surgical videos, achieving mean average precision (mAP) ranging from 4.2% to 38.1%. This study also analyzes the significance of the results obtained by the presented approaches, performs a thorough methodological comparison between them, in-depth result analysis, and proposes a novel ensemble method for enhanced recognition. Our analysis shows that surgical workflow analysis is not yet solved, and also highlights interesting directions for future research on fine-grained surgical activity recognition which is of utmost importance for the development of AI in surgery.
Comparative Validation of Machine Learning Algorithms for Surgical Workflow and Skill Analysis with the HeiChole Benchmark
Sep 30, 2021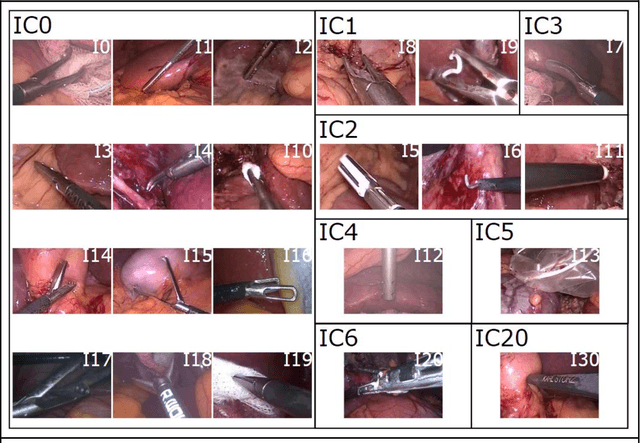
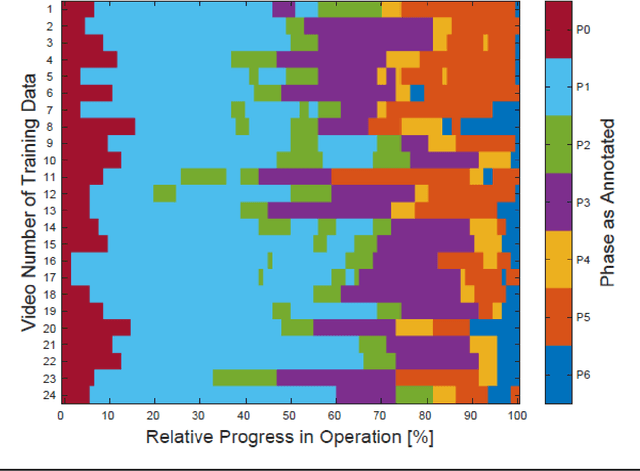
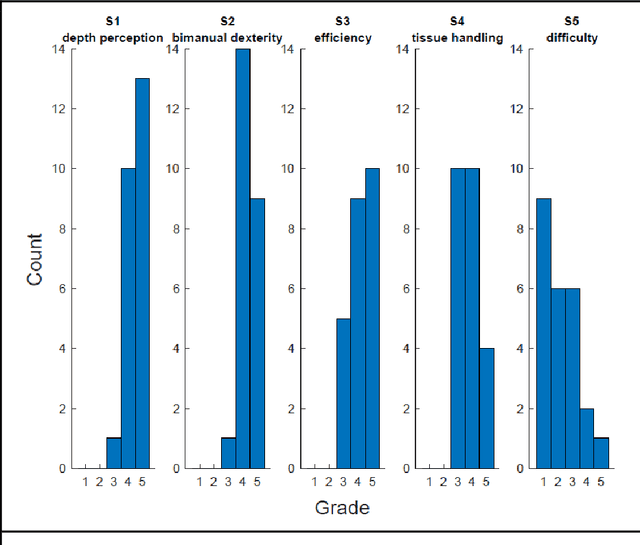
PURPOSE: Surgical workflow and skill analysis are key technologies for the next generation of cognitive surgical assistance systems. These systems could increase the safety of the operation through context-sensitive warnings and semi-autonomous robotic assistance or improve training of surgeons via data-driven feedback. In surgical workflow analysis up to 91% average precision has been reported for phase recognition on an open data single-center dataset. In this work we investigated the generalizability of phase recognition algorithms in a multi-center setting including more difficult recognition tasks such as surgical action and surgical skill. METHODS: To achieve this goal, a dataset with 33 laparoscopic cholecystectomy videos from three surgical centers with a total operation time of 22 hours was created. Labels included annotation of seven surgical phases with 250 phase transitions, 5514 occurences of four surgical actions, 6980 occurences of 21 surgical instruments from seven instrument categories and 495 skill classifications in five skill dimensions. The dataset was used in the 2019 Endoscopic Vision challenge, sub-challenge for surgical workflow and skill analysis. Here, 12 teams submitted their machine learning algorithms for recognition of phase, action, instrument and/or skill assessment. RESULTS: F1-scores were achieved for phase recognition between 23.9% and 67.7% (n=9 teams), for instrument presence detection between 38.5% and 63.8% (n=8 teams), but for action recognition only between 21.8% and 23.3% (n=5 teams). The average absolute error for skill assessment was 0.78 (n=1 team). CONCLUSION: Surgical workflow and skill analysis are promising technologies to support the surgical team, but are not solved yet, as shown by our comparison of algorithms. This novel benchmark can be used for comparable evaluation and validation of future work.
Rethinking Anticipation Tasks: Uncertainty-aware Anticipation of Sparse Surgical Instrument Usage for Context-aware Assistance
Jul 16, 2020
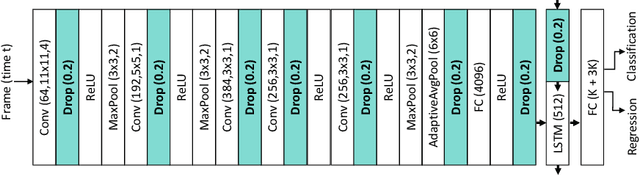
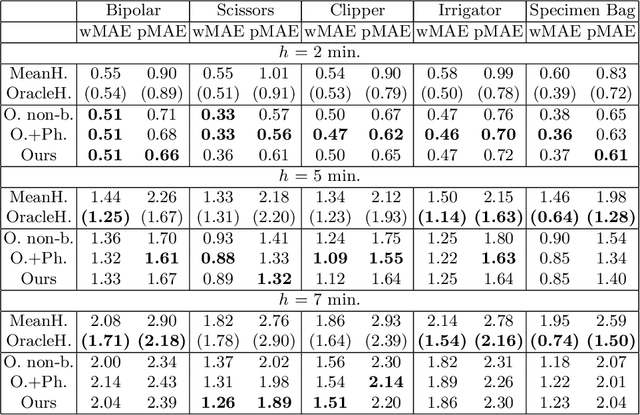
Intra-operative anticipation of instrument usage is a necessary component for context-aware assistance in surgery, e.g. for instrument preparation or semi-automation of robotic tasks. However, the sparsity of instrument occurrences in long videos poses a challenge. Current approaches are limited as they assume knowledge on the timing of future actions or require dense temporal segmentations during training and inference. We propose a novel learning task for anticipation of instrument usage in laparoscopic videos that overcomes these limitations. During training, only sparse instrument annotations are required and inference is done solely on image data. We train a probabilistic model to address the uncertainty associated with future events. Our approach outperforms several baselines and is competitive to a variant using richer annotations. We demonstrate the model's ability to quantify task-relevant uncertainties. To the best of our knowledge, we are the first to propose a method for anticipating instruments in surgery.
Heidelberg Colorectal Data Set for Surgical Data Science in the Sensor Operating Room
May 28, 2020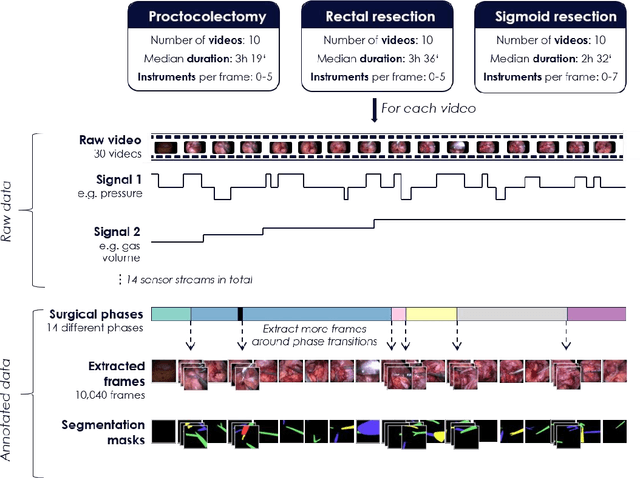
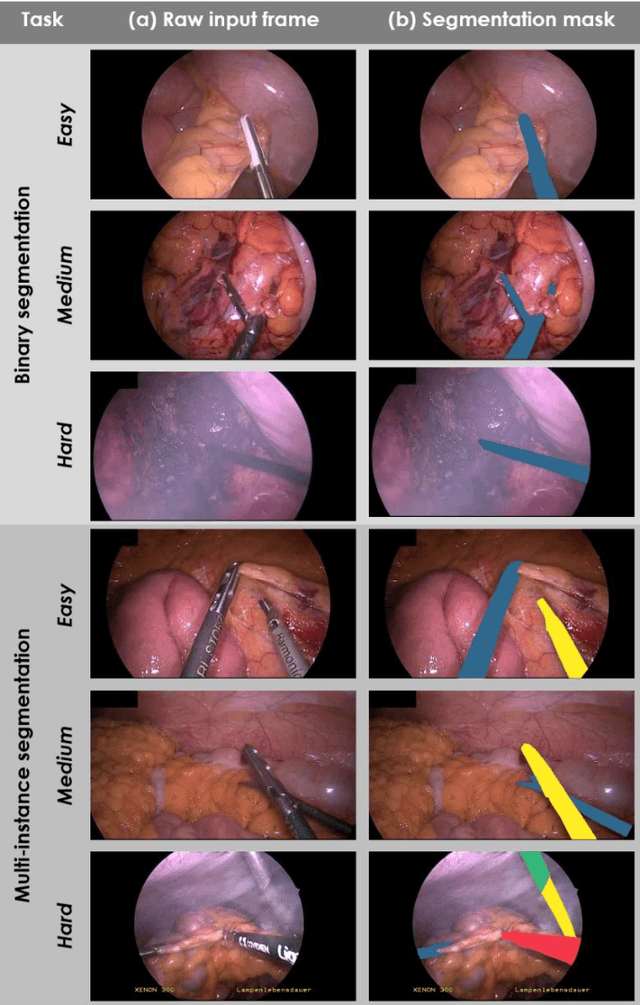
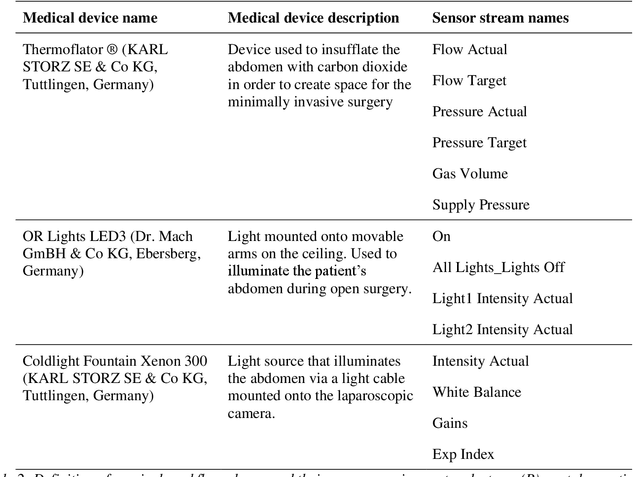
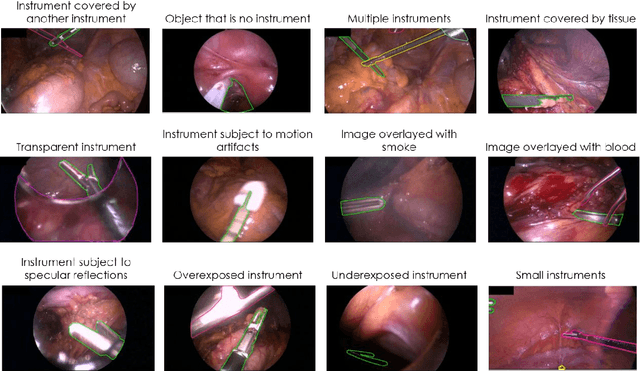
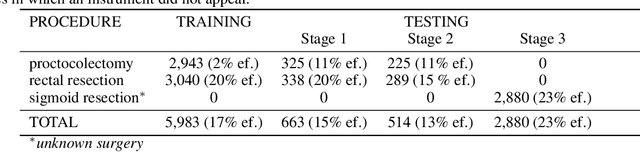
Image-based tracking of medical instruments is an integral part of many surgical data science applications. Previous research has addressed the tasks of detecting, segmenting and tracking medical instruments based on laparoscopic video data. However, the methods proposed still tend to fail when applied to challenging images and do not generalize well to data they have not been trained on. This paper introduces the Heidelberg Colorectal (HeiCo) data set - the first publicly available data set enabling comprehensive benchmarking of medical instrument detection and segmentation algorithms with a specific emphasis on robustness and generalization capabilities of the methods. Our data set comprises 30 laparoscopic videos and corresponding sensor data from medical devices in the operating room for three different types of laparoscopic surgery. Annotations include surgical phase labels for all frames in the videos as well as instance-wise segmentation masks for surgical instruments in more than 10,000 individual frames. The data has successfully been used to organize international competitions in the scope of the Endoscopic Vision Challenges (EndoVis) 2017 and 2019.
Robust Medical Instrument Segmentation Challenge 2019
Mar 23, 2020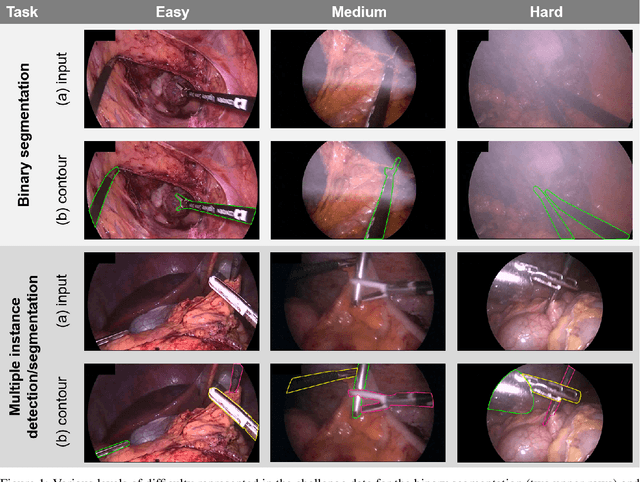
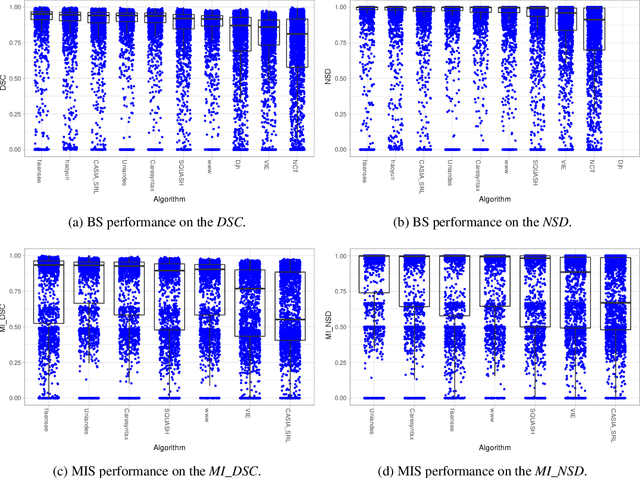
Intraoperative tracking of laparoscopic instruments is often a prerequisite for computer and robotic-assisted interventions. While numerous methods for detecting, segmenting and tracking of medical instruments based on endoscopic video images have been proposed in the literature, key limitations remain to be addressed: Firstly, robustness, that is, the reliable performance of state-of-the-art methods when run on challenging images (e.g. in the presence of blood, smoke or motion artifacts). Secondly, generalization; algorithms trained for a specific intervention in a specific hospital should generalize to other interventions or institutions. In an effort to promote solutions for these limitations, we organized the Robust Medical Instrument Segmentation (ROBUST-MIS) challenge as an international benchmarking competition with a specific focus on the robustness and generalization capabilities of algorithms. For the first time in the field of endoscopic image processing, our challenge included a task on binary segmentation and also addressed multi-instance detection and segmentation. The challenge was based on a surgical data set comprising 10,040 annotated images acquired from a total of 30 surgical procedures from three different types of surgery. The validation of the competing methods for the three tasks (binary segmentation, multi-instance detection and multi-instance segmentation) was performed in three different stages with an increasing domain gap between the training and the test data. The results confirm the initial hypothesis, namely that algorithm performance degrades with an increasing domain gap. While the average detection and segmentation quality of the best-performing algorithms is high, future research should concentrate on detection and segmentation of small, crossing, moving and transparent instrument(s) (parts).
Unsupervised Temporal Video Segmentation as an Auxiliary Task for Predicting the Remaining Surgery Duration
Feb 26, 2020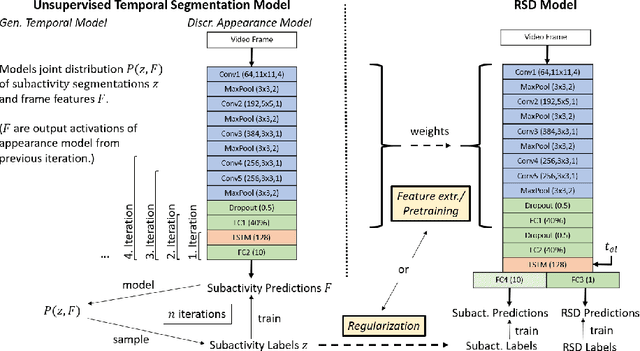
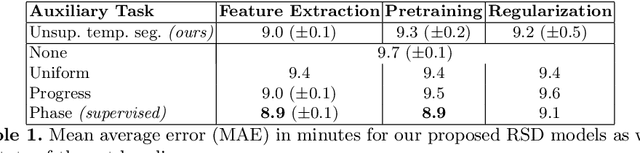

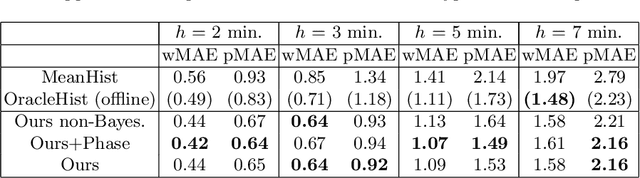
Estimating the remaining surgery duration (RSD) during surgical procedures can be useful for OR planning and anesthesia dose estimation. With the recent success of deep learning-based methods in computer vision, several neural network approaches have been proposed for fully automatic RSD prediction based solely on visual data from the endoscopic camera. We investigate whether RSD prediction can be improved using unsupervised temporal video segmentation as an auxiliary learning task. As opposed to previous work, which presented supervised surgical phase recognition as auxiliary task, we avoid the need for manual annotations by proposing a similar but unsupervised learning objective which clusters video sequences into temporally coherent segments. In multiple experimental setups, results obtained by learning the auxiliary task are incorporated into a deep RSD model through feature extraction, pretraining or regularization. Further, we propose a novel loss function for RSD training which attempts to counteract unfavorable characteristics of the RSD ground truth. Using our unsupervised method as an auxiliary task for RSD training, we outperform other self-supervised methods and are comparable to the supervised state-of-the-art. Combined with the novel RSD loss, we slightly outperform the supervised approach.
2018 Robotic Scene Segmentation Challenge
Feb 03, 2020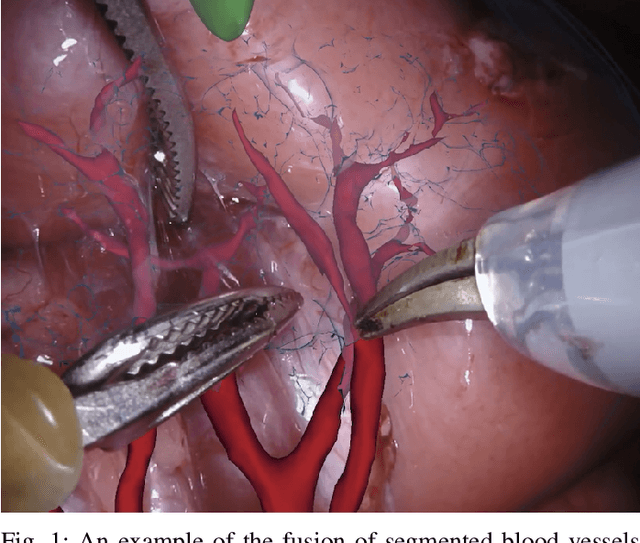
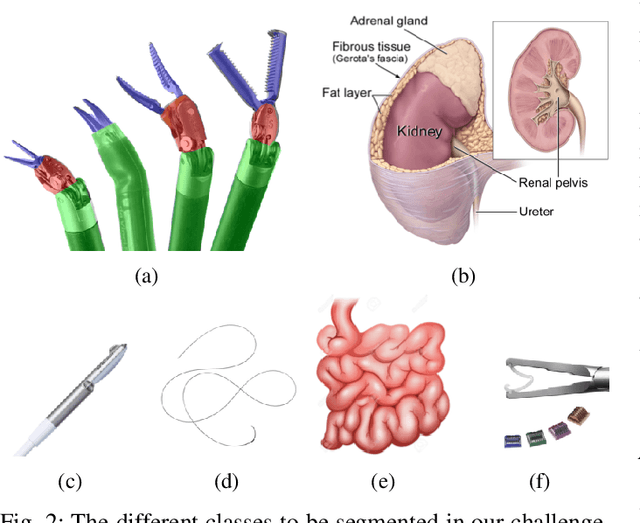
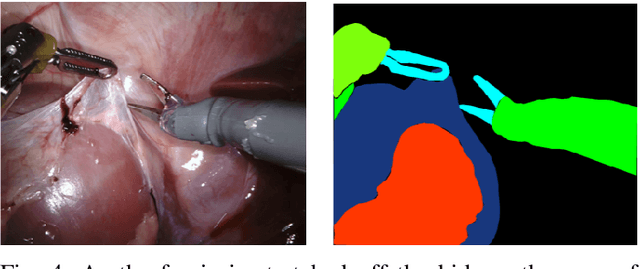
In 2015 we began a sub-challenge at the EndoVis workshop at MICCAI in Munich using endoscope images of ex-vivo tissue with automatically generated annotations from robot forward kinematics and instrument CAD models. However, the limited background variation and simple motion rendered the dataset uninformative in learning about which techniques would be suitable for segmentation in real surgery. In 2017, at the same workshop in Quebec we introduced the robotic instrument segmentation dataset with 10 teams participating in the challenge to perform binary, articulating parts and type segmentation of da Vinci instruments. This challenge included realistic instrument motion and more complex porcine tissue as background and was widely addressed with modifications on U-Nets and other popular CNN architectures. In 2018 we added to the complexity by introducing a set of anatomical objects and medical devices to the segmented classes. To avoid over-complicating the challenge, we continued with porcine data which is dramatically simpler than human tissue due to the lack of fatty tissue occluding many organs.
Using 3D Convolutional Neural Networks to Learn Spatiotemporal Features for Automatic Surgical Gesture Recognition in Video
Jul 26, 2019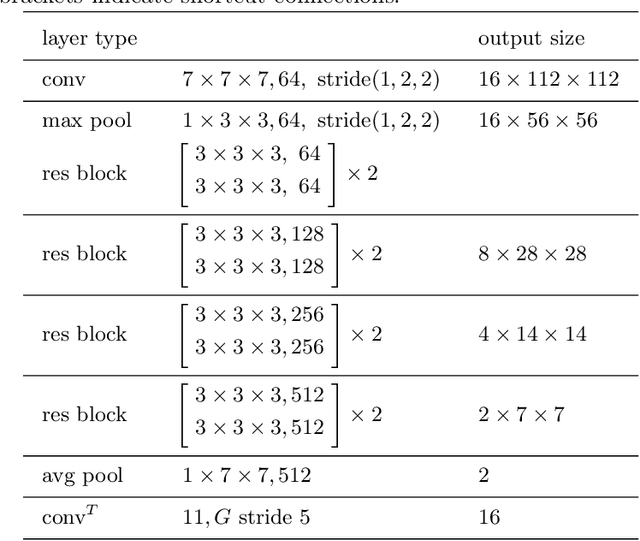


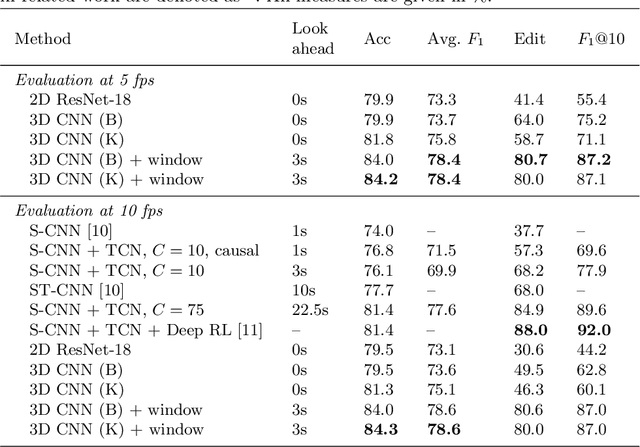
Automatically recognizing surgical gestures is a crucial step towards a thorough understanding of surgical skill. Possible areas of application include automatic skill assessment, intra-operative monitoring of critical surgical steps, and semi-automation of surgical tasks. Solutions that rely only on the laparoscopic video and do not require additional sensor hardware are especially attractive as they can be implemented at low cost in many scenarios. However, surgical gesture recognition based only on video is a challenging problem that requires effective means to extract both visual and temporal information from the video. Previous approaches mainly rely on frame-wise feature extractors, either handcrafted or learned, which fail to capture the dynamics in surgical video. To address this issue, we propose to use a 3D Convolutional Neural Network (CNN) to learn spatiotemporal features from consecutive video frames. We evaluate our approach on recordings of robot-assisted suturing on a bench-top model, which are taken from the publicly available JIGSAWS dataset. Our approach achieves high frame-wise surgical gesture recognition accuracies of more than 84%, outperforming comparable models that either extract only spatial features or model spatial and low-level temporal information separately. For the first time, these results demonstrate the benefit of spatiotemporal CNNs for video-based surgical gesture recognition.
Generating large labeled data sets for laparoscopic image processing tasks using unpaired image-to-image translation
Jul 05, 2019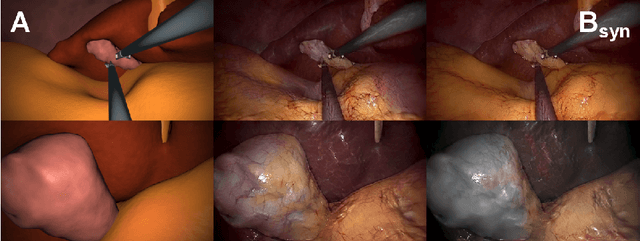
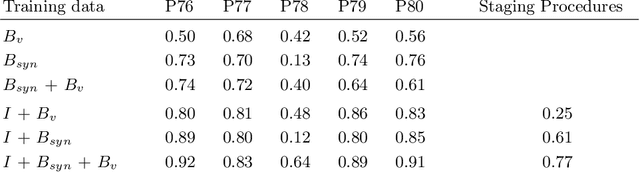
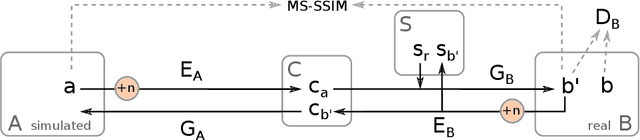
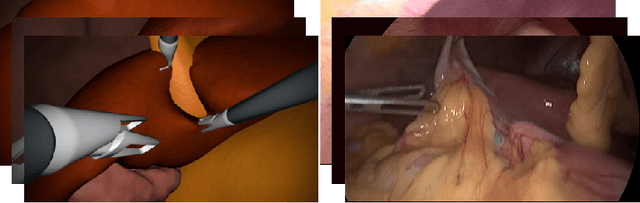
In the medical domain, the lack of large training data sets and benchmarks is often a limiting factor for training deep neural networks. In contrast to expensive manual labeling, computer simulations can generate large and fully labeled data sets with a minimum of manual effort. However, models that are trained on simulated data usually do not translate well to real scenarios. To bridge the domain gap between simulated and real laparoscopic images, we exploit recent advances in unpaired image-to-image translation. We extent an image-to-image translation method to generate a diverse multitude of realistically looking synthetic images based on images from a simple laparoscopy simulation. By incorporating means to ensure that the image content is preserved during the translation process, we ensure that the labels given for the simulated images remain valid for their realistically looking translations. This way, we are able to generate a large, fully labeled synthetic data set of laparoscopic images with realistic appearance. We show that this data set can be used to train models for the task of liver segmentation of laparoscopic images. We achieve average dice scores of up to 0.89 in some patients without manually labeling a single laparoscopic image and show that using our synthetic data to pre-train models can greatly improve their performance. The synthetic data set will be made publicly available, fully labeled with segmentation maps, depth maps, normal maps, and positions of tools and camera (http://opencas.dkfz.de/image2image).
2017 Robotic Instrument Segmentation Challenge
Feb 21, 2019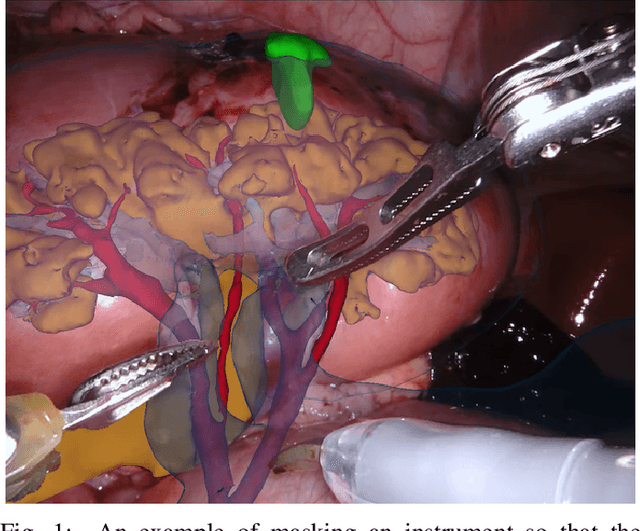
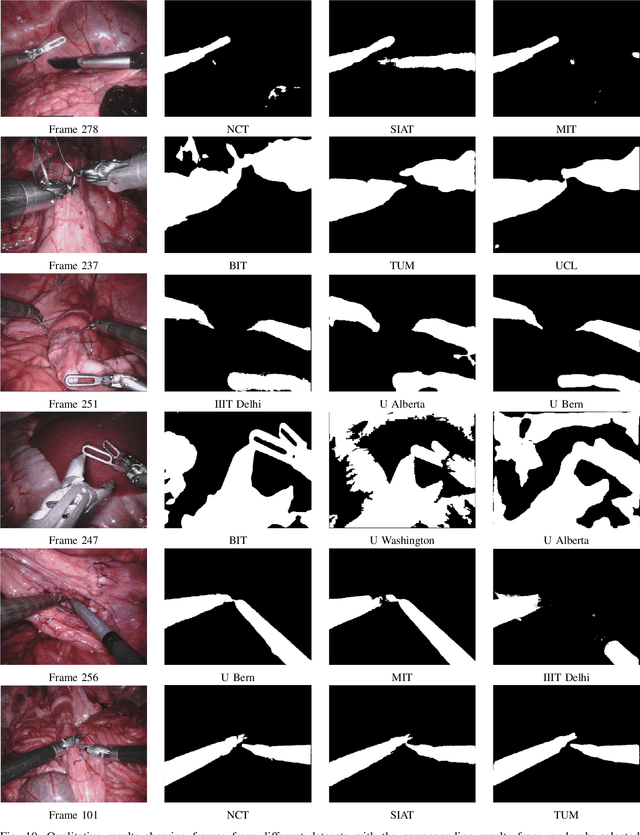
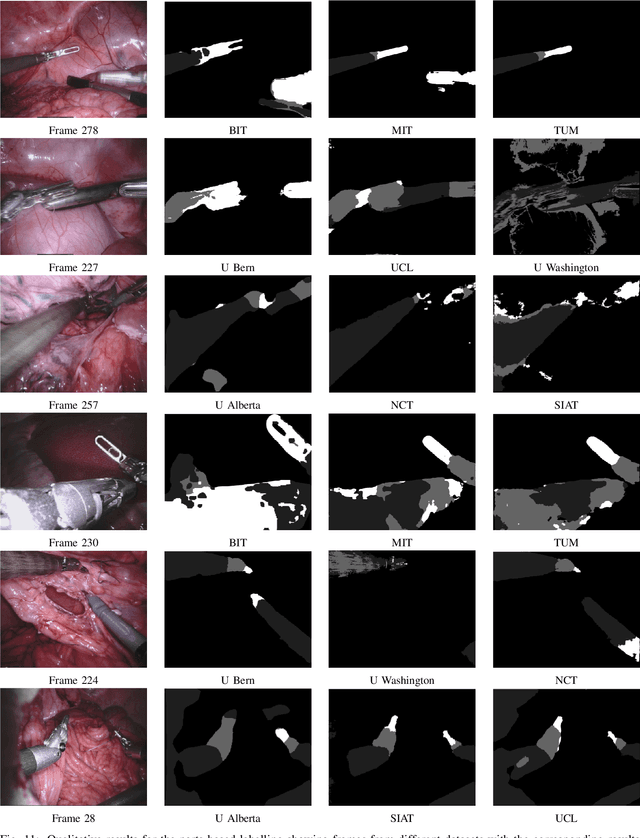

In mainstream computer vision and machine learning, public datasets such as ImageNet, COCO and KITTI have helped drive enormous improvements by enabling researchers to understand the strengths and limitations of different algorithms via performance comparison. However, this type of approach has had limited translation to problems in robotic assisted surgery as this field has never established the same level of common datasets and benchmarking methods. In 2015 a sub-challenge was introduced at the EndoVis workshop where a set of robotic images were provided with automatically generated annotations from robot forward kinematics. However, there were issues with this dataset due to the limited background variation, lack of complex motion and inaccuracies in the annotation. In this work we present the results of the 2017 challenge on robotic instrument segmentation which involved 10 teams participating in binary, parts and type based segmentation of articulated da Vinci robotic instruments.