 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSS: Open Suturing Skills Vision-Based Assessment Challenge 2024-2025
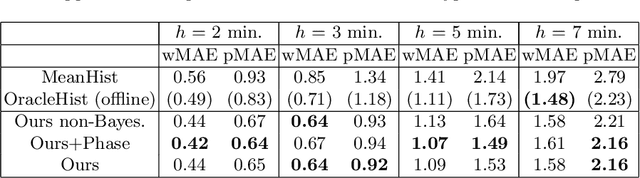
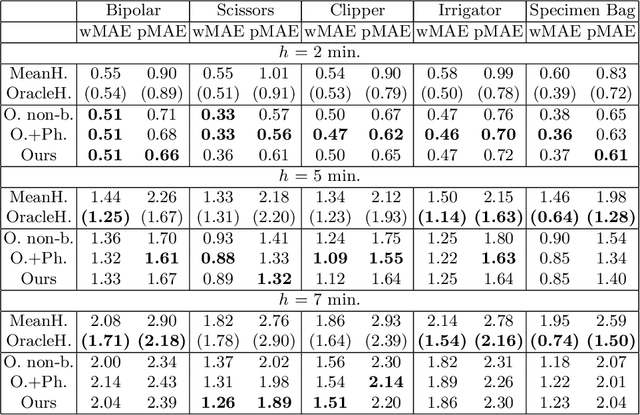
May 21, 2026Achieving high levels of surgical skill through effective training is essential for optimal patient outcomes. Automated, data-driven skill assessment holds significant potential to improve surgical training. While machine learning-based methods are increasingly popular for assessing skills in minimally invasive surgery, their application to open surgery remains limited. We present the results of a dedicated MICCAI challenge designed to benchmark and advance vision-based skill assessment in open surgery. The challenge dataset comprises videos of an open suturing training task recorded with a static GoPro camera in a dry-lab setting, with instrument trajectories available in addition to the primary video modality. The OSS Challenge was hosted over two consecutive years, comprising two and three independent tasks, respectively: (1) classifying skill level into four classes, (2) predicting the full Objective Structured Assessment of Technical Skills across eight categories, and (3) tracking hands and surgical tools. Participants submitted diverse solutions including deep learning-based video models, tracking-driven methods, and hybrid approaches. General-purpose spatiotemporal video models consistently achieved the strongest performance, though conceptually diverse approaches reached competitive levels when well-executed. Predicting fine-grained OSATS scores remains challenging but benefits substantially from increased training data. Keypoint tracking proves difficult given frequent occlusions and out-of-frame instances, limiting current applicability for motion-based skill analysis. This work benchmarks innovative and diverse solutions for surgical skill assessment, highlighting both the promise and current limitations of video-based evaluation in open surgery and identifying critical directions for advancing automated skill assessment toward clinical impact.
A benchmark for video-based laparoscopic skill analysis and assessment
Feb 10, 2026Laparoscopic surgery is a complex surgical technique that requires extensive training. Recent advances in deep learning have shown promise in supporting this training by enabling automatic video-based assessment of surgical skills. However, the development and evaluation of deep learning models is currently hindered by the limited size of available annotated datasets. To address this gap, we introduce the Laparoscopic Skill Analysis and Assessment (LASANA) dataset, comprising 1270 stereo video recordings of four basic laparoscopic training tasks. Each recording is annotated with a structured skill rating, aggregated from three independent raters, as well as binary labels indicating the presence or absence of task-specific errors. The majority of recordings originate from a laparoscopic training course, thereby reflecting a natural variation in the skill of participants. To facilitate benchmarking of both existing and novel approaches for video-based skill assessment and error recognition, we provide predefined data splits for each task. Furthermore, we present baseline results from a deep learning model as a reference point for future comparisons.
Mission Balance: Generating Under-represented Class Samples using Video Diffusion Models
May 14, 2025Computer-assisted interventions can improve intra-operative guidance, particularly through deep learning methods that harness the spatiotemporal information in surgical videos. However, the severe data imbalance often found in surgical video datasets hinders the development of high-performing models. In this work, we aim to overcome the data imbalance by synthesizing surgical videos. We propose a unique two-stage, text-conditioned diffusion-based method to generate high-fidelity surgical videos for under-represented classes. Our approach conditions the generation process on text prompts and decouples spatial and temporal modeling by utilizing a 2D latent diffusion model to capture spatial content and then integrating temporal attention layers to ensure temporal consistency. Furthermore, we introduce a rejection sampling strategy to select the most suitable synthetic samples, effectively augmenting existing datasets to address class imbalance. We evaluate our method on two downstream tasks-surgical action recognition and intra-operative event prediction-demonstrating that incorporating synthetic videos from our approach substantially enhances model performance. We open-source our implementation at https://gitlab.com/nct_tso_public/surgvgen.
TUNeS: A Temporal U-Net with Self-Attention for Video-based Surgical Phase Recognition
Jul 19, 2023



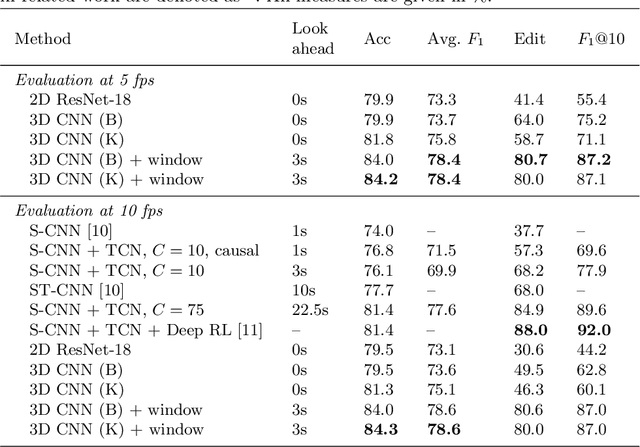
To enable context-aware computer assistance in the operating room of the future, cognitive systems need to understand automatically which surgical phase is being performed by the medical team. The primary source of information for surgical phase recognition is typically video, which presents two challenges: extracting meaningful features from the video stream and effectively modeling temporal information in the sequence of visual features. For temporal modeling, attention mechanisms have gained popularity due to their ability to capture long-range dependencies. In this paper, we explore design choices for attention in existing temporal models for surgical phase recognition and propose a novel approach that does not resort to local attention or regularization of attention weights: TUNeS is an efficient and simple temporal model that incorporates self-attention at the coarsest stage of a U-Net-like structure. In addition, we propose to train the feature extractor, a standard CNN, together with an LSTM on preferably long video segments, i.e., with long temporal context. In our experiments, all temporal models performed better on top of feature extractors that were trained with longer temporal context. On top of these contextualized features, TUNeS achieves state-of-the-art results on Cholec80.
Metrics Matter in Surgical Phase Recognition
May 23, 2023



Surgical phase recognition is a basic component for different context-aware applications in computer- and robot-assisted surgery. In recent years, several methods for automatic surgical phase recognition have been proposed, showing promising results. However, a meaningful comparison of these methods is difficult due to differences in the evaluation process and incomplete reporting of evaluation details. In particular, the details of metric computation can vary widely between different studies. To raise awareness of potential inconsistencies, this paper summarizes common deviations in the evaluation of phase recognition algorithms on the Cholec80 benchmark. In addition, a structured overview of previously reported evaluation results on Cholec80 is provided, taking known differences in evaluation protocols into account. Greater attention to evaluation details could help achieve more consistent and comparable results on the surgical phase recognition task, leading to more reliable conclusions about advancements in the field and, finally, translation into clinical practice.
On the Pitfalls of Batch Normalization for End-to-End Video Learning: A Study on Surgical Workflow Analysis
Mar 15, 2022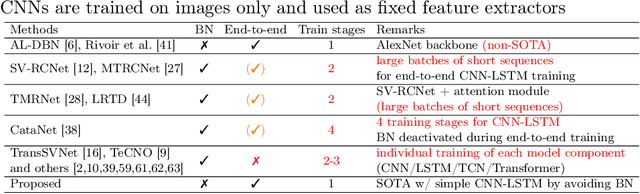
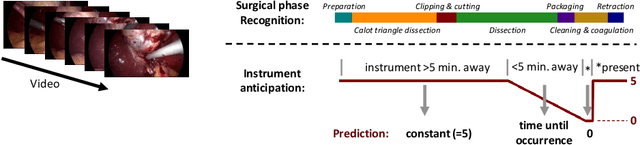
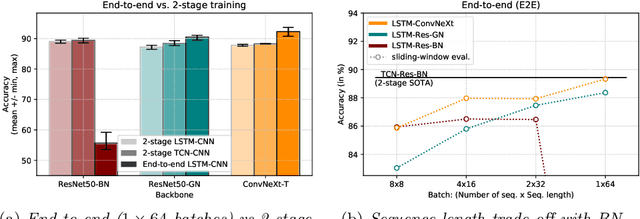
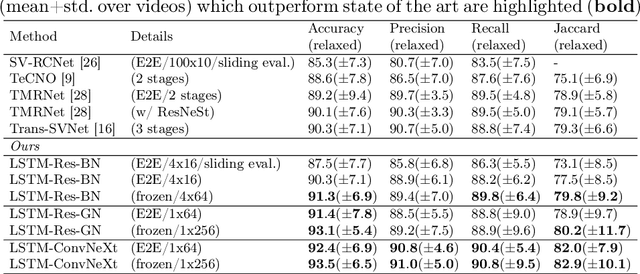
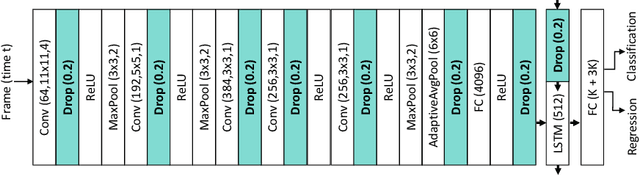
Batch Normalization's (BN) unique property of depending on other samples in a batch is known to cause problems in several tasks, including sequential modeling, and has led to the use of alternatives in these fields. In video learning, however, these problems are less studied, despite the ubiquitous use of BN in CNNs for visual feature extraction. We argue that BN's properties create major obstacles for training CNNs and temporal models end to end in video tasks. Yet, end-to-end learning seems preferable in specialized domains such as surgical workflow analysis, which lack well-pretrained feature extractors. While previous work in surgical workflow analysis has avoided BN-related issues through complex, multi-stage learning procedures, we show that even simple, end-to-end CNN-LSTMs can outperform the state of the art when CNNs without BN are used. Moreover, we analyze in detail when BN-related issues occur, including a "cheating" phenomenon in surgical anticipation tasks. We hope that a deeper understanding of BN's limitations and a reconsideration of end-to-end approaches can be beneficial for future research in surgical workflow analysis and general video learning.
Rethinking Anticipation Tasks: Uncertainty-aware Anticipation of Sparse Surgical Instrument Usage for Context-aware Assistance
Jul 16, 2020
Intra-operative anticipation of instrument usage is a necessary component for context-aware assistance in surgery, e.g. for instrument preparation or semi-automation of robotic tasks. However, the sparsity of instrument occurrences in long videos poses a challenge. Current approaches are limited as they assume knowledge on the timing of future actions or require dense temporal segmentations during training and inference. We propose a novel learning task for anticipation of instrument usage in laparoscopic videos that overcomes these limitations. During training, only sparse instrument annotations are required and inference is done solely on image data. We train a probabilistic model to address the uncertainty associated with future events. Our approach outperforms several baselines and is competitive to a variant using richer annotations. We demonstrate the model's ability to quantify task-relevant uncertainties. To the best of our knowledge, we are the first to propose a method for anticipating instruments in surgery.
Using 3D Convolutional Neural Networks to Learn Spatiotemporal Features for Automatic Surgical Gesture Recognition in Video
Jul 26, 2019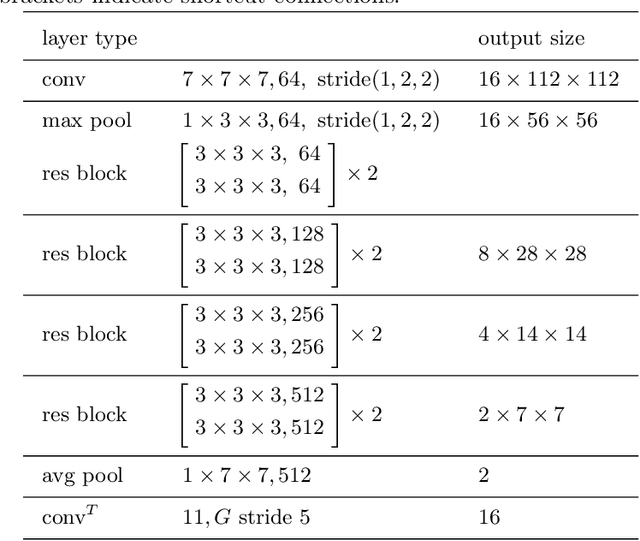


Automatically recognizing surgical gestures is a crucial step towards a thorough understanding of surgical skill. Possible areas of application include automatic skill assessment, intra-operative monitoring of critical surgical steps, and semi-automation of surgical tasks. Solutions that rely only on the laparoscopic video and do not require additional sensor hardware are especially attractive as they can be implemented at low cost in many scenarios. However, surgical gesture recognition based only on video is a challenging problem that requires effective means to extract both visual and temporal information from the video. Previous approaches mainly rely on frame-wise feature extractors, either handcrafted or learned, which fail to capture the dynamics in surgical video. To address this issue, we propose to use a 3D Convolutional Neural Network (CNN) to learn spatiotemporal features from consecutive video frames. We evaluate our approach on recordings of robot-assisted suturing on a bench-top model, which are taken from the publicly available JIGSAWS dataset. Our approach achieves high frame-wise surgical gesture recognition accuracies of more than 84%, outperforming comparable models that either extract only spatial features or model spatial and low-level temporal information separately. For the first time, these results demonstrate the benefit of spatiotemporal CNNs for video-based surgical gesture recognition.
Generating large labeled data sets for laparoscopic image processing tasks using unpaired image-to-image translation
Jul 05, 2019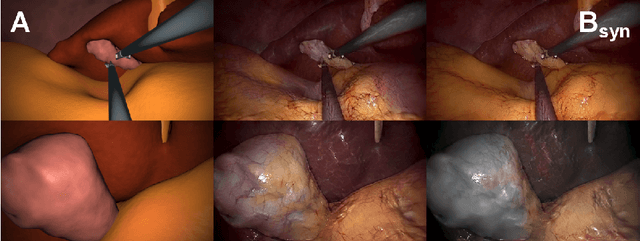
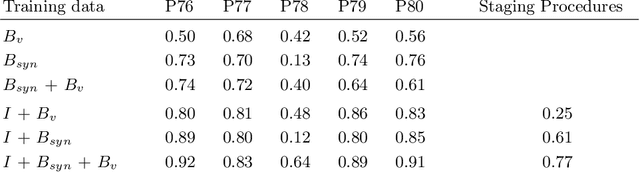
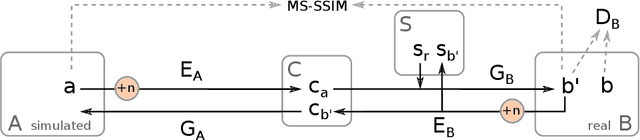
In the medical domain, the lack of large training data sets and benchmarks is often a limiting factor for training deep neural networks. In contrast to expensive manual labeling, computer simulations can generate large and fully labeled data sets with a minimum of manual effort. However, models that are trained on simulated data usually do not translate well to real scenarios. To bridge the domain gap between simulated and real laparoscopic images, we exploit recent advances in unpaired image-to-image translation. We extent an image-to-image translation method to generate a diverse multitude of realistically looking synthetic images based on images from a simple laparoscopy simulation. By incorporating means to ensure that the image content is preserved during the translation process, we ensure that the labels given for the simulated images remain valid for their realistically looking translations. This way, we are able to generate a large, fully labeled synthetic data set of laparoscopic images with realistic appearance. We show that this data set can be used to train models for the task of liver segmentation of laparoscopic images. We achieve average dice scores of up to 0.89 in some patients without manually labeling a single laparoscopic image and show that using our synthetic data to pre-train models can greatly improve their performance. The synthetic data set will be made publicly available, fully labeled with segmentation maps, depth maps, normal maps, and positions of tools and camera (http://opencas.dkfz.de/image2image).
Video-based surgical skill assessment using 3D convolutional neural networks
Mar 06, 2019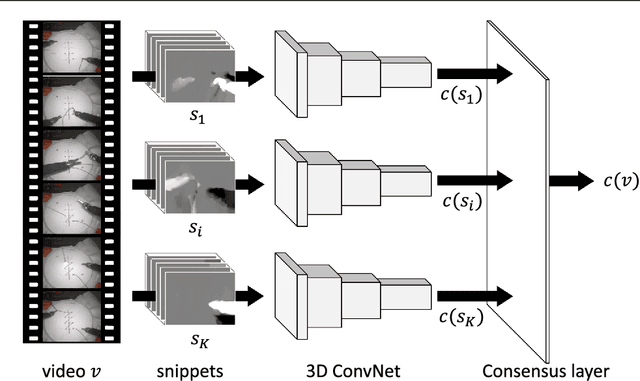
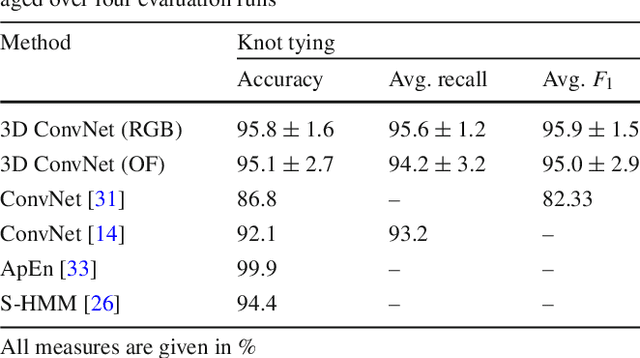

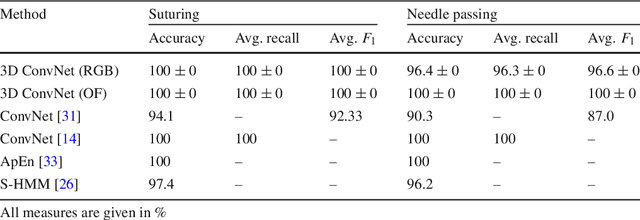
Purpose: A profound education of novice surgeons is crucial to ensure that surgical interventions are effective and safe. One important aspect is the teaching of technical skills for minimally invasive or robot-assisted procedures. This includes the objective and preferably automatic assessment of surgical skill. Recent studies presented good results for automatic, objective skill evaluation by collecting and analyzing motion data such as trajectories of surgical instruments. However, obtaining the motion data generally requires additional equipment for instrument tracking or the availability of a robotic surgery system to capture kinematic data. In contrast, we investigate a method for automatic, objective skill assessment that requires video data only. This has the advantage that video can be collected effortlessly during minimally invasive and robot-assisted training scenarios. Methods: Our method builds on recent advances in deep learning-based video classification. Specifically, we propose to use an inflated 3D ConvNet to classify snippets of optical flow extracted from surgical video. The network is extended into a Temporal Segment Network during training. Results: On the publicly available JIGSAWS dataset, our approach achieves high skill classification accuracies ranging from 95.1% to 100.0%. Conclusions: Our results demonstrate the feasibility of deep learning-based assessment of technical skill from surgical video. The 3D ConvNet is able to learn meaningful patterns directly from the data, alleviating the need for manual feature engineering. Further evaluation will require more annotated data for training and testing.