 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA benchmark for video-based laparoscopic skill analysis and assessment
Feb 10, 2026Laparoscopic surgery is a complex surgical technique that requires extensive training. Recent advances in deep learning have shown promise in supporting this training by enabling automatic video-based assessment of surgical skills. However, the development and evaluation of deep learning models is currently hindered by the limited size of available annotated datasets. To address this gap, we introduce the Laparoscopic Skill Analysis and Assessment (LASANA) dataset, comprising 1270 stereo video recordings of four basic laparoscopic training tasks. Each recording is annotated with a structured skill rating, aggregated from three independent raters, as well as binary labels indicating the presence or absence of task-specific errors. The majority of recordings originate from a laparoscopic training course, thereby reflecting a natural variation in the skill of participants. To facilitate benchmarking of both existing and novel approaches for video-based skill assessment and error recognition, we provide predefined data splits for each task. Furthermore, we present baseline results from a deep learning model as a reference point for future comparisons.
Using 3D Convolutional Neural Networks to Learn Spatiotemporal Features for Automatic Surgical Gesture Recognition in Video
Jul 26, 2019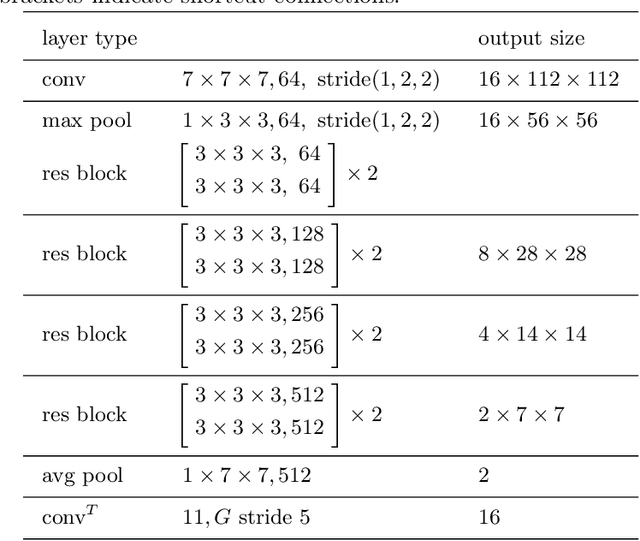


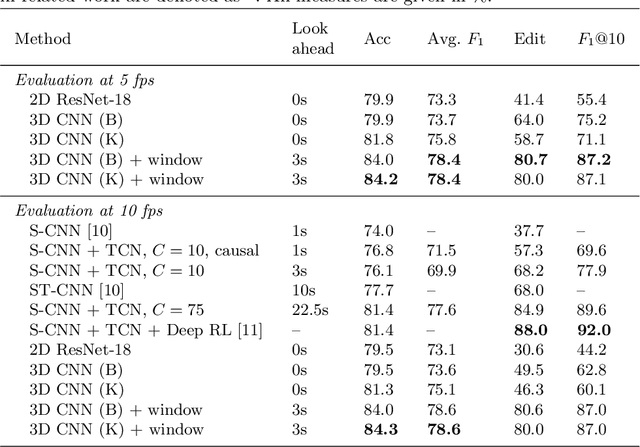
Automatically recognizing surgical gestures is a crucial step towards a thorough understanding of surgical skill. Possible areas of application include automatic skill assessment, intra-operative monitoring of critical surgical steps, and semi-automation of surgical tasks. Solutions that rely only on the laparoscopic video and do not require additional sensor hardware are especially attractive as they can be implemented at low cost in many scenarios. However, surgical gesture recognition based only on video is a challenging problem that requires effective means to extract both visual and temporal information from the video. Previous approaches mainly rely on frame-wise feature extractors, either handcrafted or learned, which fail to capture the dynamics in surgical video. To address this issue, we propose to use a 3D Convolutional Neural Network (CNN) to learn spatiotemporal features from consecutive video frames. We evaluate our approach on recordings of robot-assisted suturing on a bench-top model, which are taken from the publicly available JIGSAWS dataset. Our approach achieves high frame-wise surgical gesture recognition accuracies of more than 84%, outperforming comparable models that either extract only spatial features or model spatial and low-level temporal information separately. For the first time, these results demonstrate the benefit of spatiotemporal CNNs for video-based surgical gesture recognition.