 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWarm-Started Reinforcement Learning for Iterative 3D/2D Liver Registration
Apr 11, 2026Registration between preoperative CT and intraoperative laparoscopic video plays a crucial role in augmented reality (AR) guidance for minimally invasive surgery. Learning-based methods have recently achieved registration errors comparable to optimization-based approaches while offering faster inference. However, many supervised methods produce coarse alignments that rely on additional optimization-based refinement, thereby increasing inference time. We present a discrete-action reinforcement learning (RL) framework that formulates CT-to-video registration as a sequential decision-making process. A shared feature encoder, warm-started from a supervised pose estimation network to provide stable geometric features and faster convergence, extracts representations from CT renderings and laparoscopic frames, while an RL policy head learns to choose rigid transformations along six degrees of freedom and to decide when to stop the iteration. Experiments on a public laparoscopic dataset demonstrated that our method achieved an average target registration error (TRE) of 15.70 mm, comparable to supervised approaches with optimization, while achieving faster convergence. The proposed RL-based formulation enables automated, efficient iterative registration without manually tuned step sizes or stopping criteria. This discrete framework provides a practical foundation for future continuous-action and deformable registration models in surgical AR applications.
FoundationPose-Initialized 3D-2D Liver Registration for Surgical Augmented Reality
Feb 19, 2026Augmented reality can improve tumor localization in laparoscopic liver surgery. Existing registration pipelines typically depend on organ contours; deformable (non-rigid) alignment is often handled with finite-element (FE) models coupled to dimensionality-reduction or machine-learning components. We integrate laparoscopic depth maps with a foundation pose estimator for camera-liver pose estimation and replace FE-based deformation with non-rigid iterative closest point (NICP) to lower engineering/modeling complexity and expertise requirements. On real patient data, the depth-augmented foundation pose approach achieved 9.91 mm mean registration error in 3 cases. Combined rigid-NICP registration outperformed rigid-only registration, demonstrating NICP as an efficient substitute for finite-element deformable models. This pipeline achieves clinically relevant accuracy while offering a lightweight, engineering-friendly alternative to FE-based deformation.
Generating large labeled data sets for laparoscopic image processing tasks using unpaired image-to-image translation
Jul 05, 2019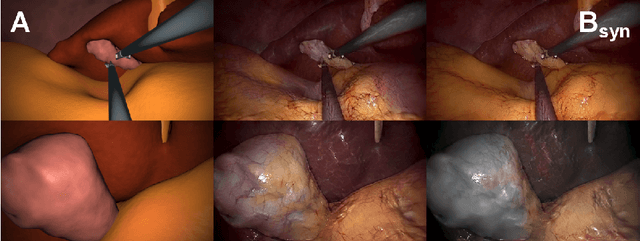
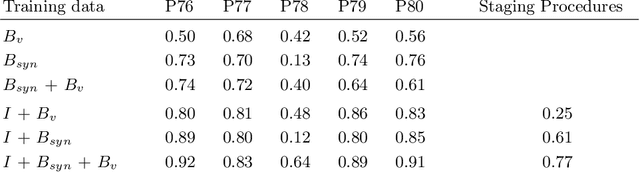
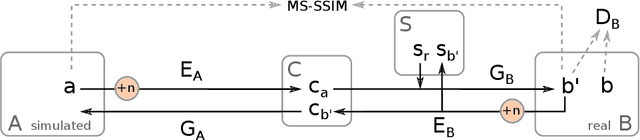
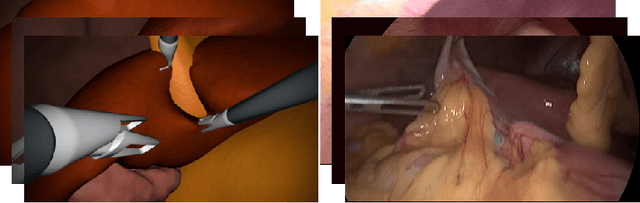
In the medical domain, the lack of large training data sets and benchmarks is often a limiting factor for training deep neural networks. In contrast to expensive manual labeling, computer simulations can generate large and fully labeled data sets with a minimum of manual effort. However, models that are trained on simulated data usually do not translate well to real scenarios. To bridge the domain gap between simulated and real laparoscopic images, we exploit recent advances in unpaired image-to-image translation. We extent an image-to-image translation method to generate a diverse multitude of realistically looking synthetic images based on images from a simple laparoscopy simulation. By incorporating means to ensure that the image content is preserved during the translation process, we ensure that the labels given for the simulated images remain valid for their realistically looking translations. This way, we are able to generate a large, fully labeled synthetic data set of laparoscopic images with realistic appearance. We show that this data set can be used to train models for the task of liver segmentation of laparoscopic images. We achieve average dice scores of up to 0.89 in some patients without manually labeling a single laparoscopic image and show that using our synthetic data to pre-train models can greatly improve their performance. The synthetic data set will be made publicly available, fully labeled with segmentation maps, depth maps, normal maps, and positions of tools and camera (http://opencas.dkfz.de/image2image).