 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DStyleNet: Creating 3D Shapes with Geometric and Texture Style Variations
Aug 30, 2021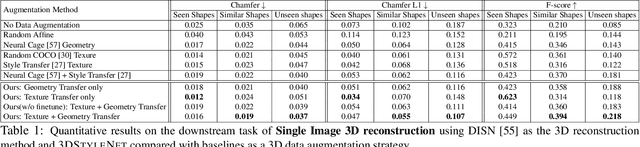
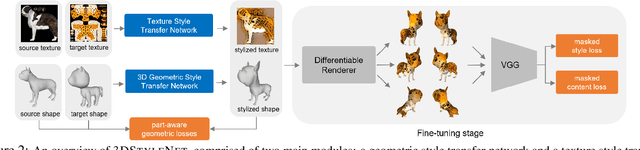
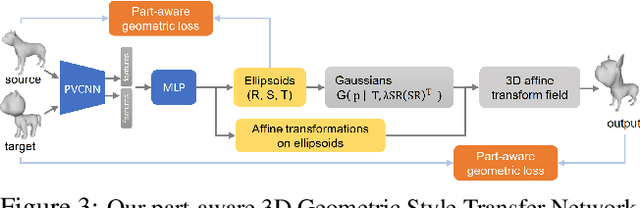
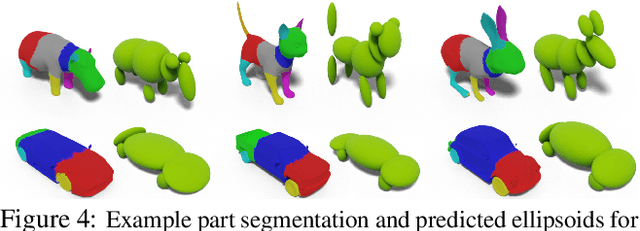
We propose a method to create plausible geometric and texture style variations of 3D objects in the quest to democratize 3D content creation. Given a pair of textured source and target objects, our method predicts a part-aware affine transformation field that naturally warps the source shape to imitate the overall geometric style of the target. In addition, the texture style of the target is transferred to the warped source object with the help of a multi-view differentiable renderer. Our model, 3DStyleNet, is composed of two sub-networks trained in two stages. First, the geometric style network is trained on a large set of untextured 3D shapes. Second, we jointly optimize our geometric style network and a pre-trained image style transfer network with losses defined over both the geometry and the rendering of the result. Given a small set of high-quality textured objects, our method can create many novel stylized shapes, resulting in effortless 3D content creation and style-ware data augmentation. We showcase our approach qualitatively on 3D content stylization, and provide user studies to validate the quality of our results. In addition, our method can serve as a valuable tool to create 3D data augmentations for computer vision tasks. Extensive quantitative analysis shows that 3DStyleNet outperforms alternative data augmentation techniques for the downstream task of single-image 3D reconstruction.
NP-DRAW: A Non-Parametric Structured Latent Variable Model for Image Generation
Jul 04, 2021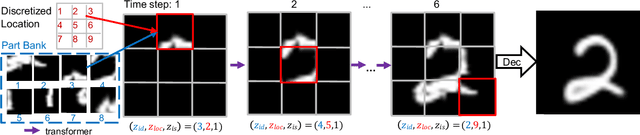
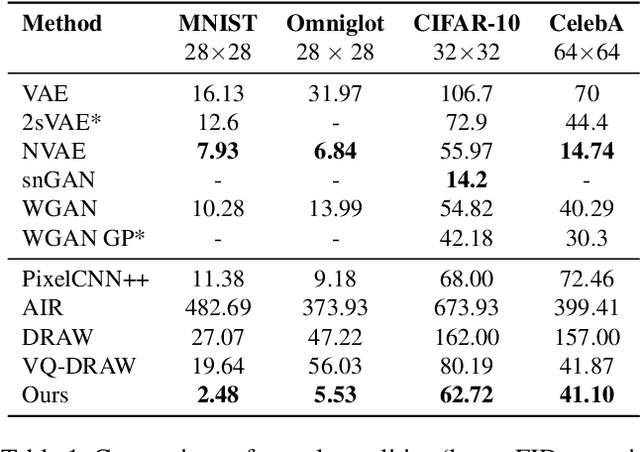
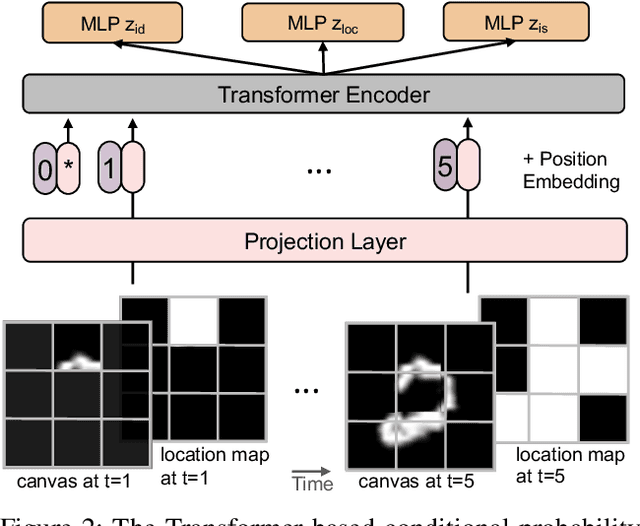
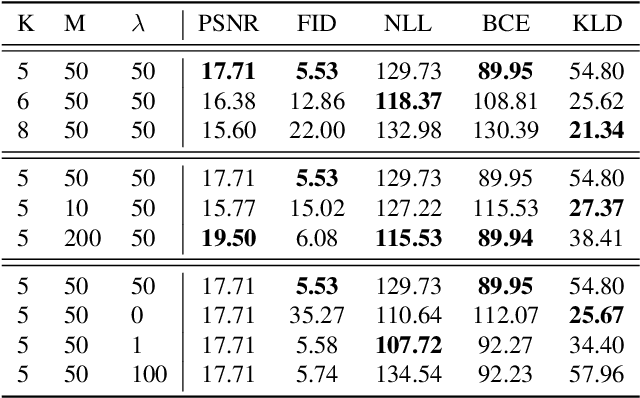
In this paper, we present a non-parametric structured latent variable model for image generation, called NP-DRAW, which sequentially draws on a latent canvas in a part-by-part fashion and then decodes the image from the canvas. Our key contributions are as follows. 1) We propose a non-parametric prior distribution over the appearance of image parts so that the latent variable ``what-to-draw'' per step becomes a categorical random variable. This improves the expressiveness and greatly eases the learning compared to Gaussians used in the literature. 2) We model the sequential dependency structure of parts via a Transformer, which is more powerful and easier to train compared to RNNs used in the literature. 3) We propose an effective heuristic parsing algorithm to pre-train the prior. Experiments on MNIST, Omniglot, CIFAR-10, and CelebA show that our method significantly outperforms previous structured image models like DRAW and AIR and is competitive to other generic generative models. Moreover, we show that our model's inherent compositionality and interpretability bring significant benefits in the low-data learning regime and latent space editing. Code is available at https://github.com/ZENGXH/NPDRAW.
f-Domain-Adversarial Learning: Theory and Algorithms
Jun 21, 2021
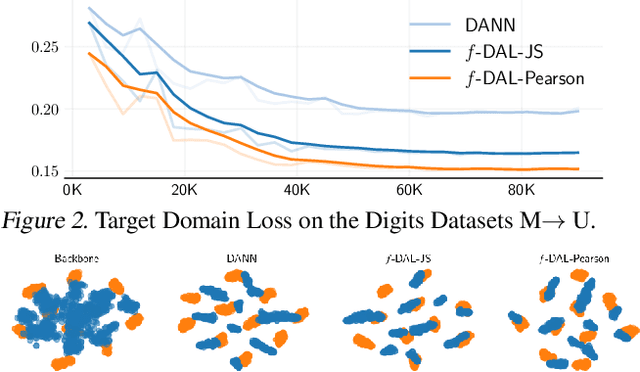

Unsupervised domain adaptation is used in many machine learning applications where, during training, a model has access to unlabeled data in the target domain, and a related labeled dataset. In this paper, we introduce a novel and general domain-adversarial framework. Specifically, we derive a novel generalization bound for domain adaptation that exploits a new measure of discrepancy between distributions based on a variational characterization of f-divergences. It recovers the theoretical results from Ben-David et al. (2010a) as a special case and supports divergences used in practice. Based on this bound, we derive a new algorithmic framework that introduces a key correction in the original adversarial training method of Ganin et al. (2016). We show that many regularizers and ad-hoc objectives introduced over the last years in this framework are then not required to achieve performance comparable to (if not better than) state-of-the-art domain-adversarial methods. Experimental analysis conducted on real-world natural language and computer vision datasets show that our framework outperforms existing baselines, and obtains the best results for f-divergences that were not considered previously in domain-adversarial learning.
Low Budget Active Learning via Wasserstein Distance: An Integer Programming Approach
Jun 12, 2021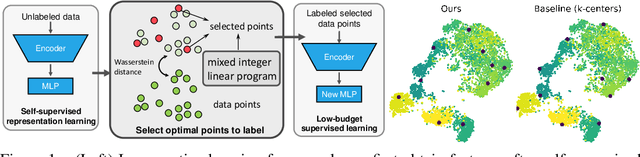
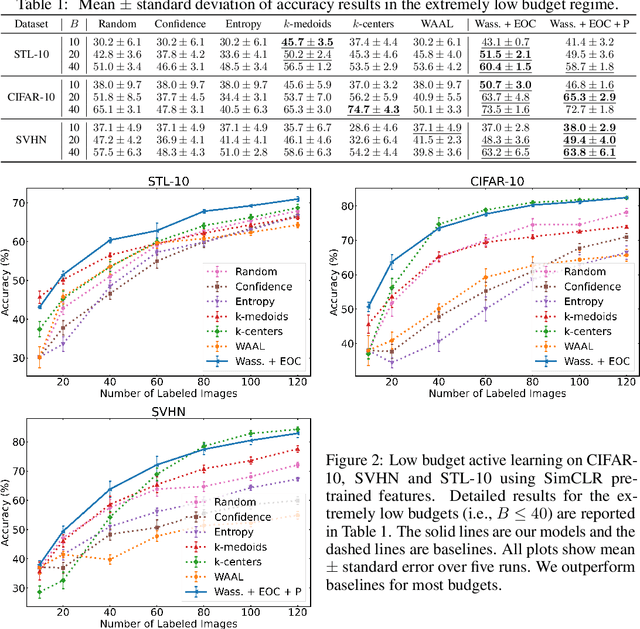
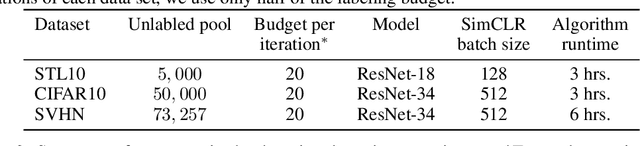
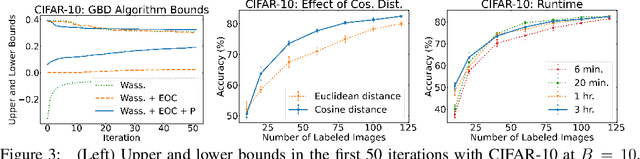
Given restrictions on the availability of data, active learning is the process of training a model with limited labeled data by selecting a core subset of an unlabeled data pool to label. Although selecting the most useful points for training is an optimization problem, the scale of deep learning data sets forces most selection strategies to employ efficient heuristics. Instead, we propose a new integer optimization problem for selecting a core set that minimizes the discrete Wasserstein distance from the unlabeled pool. We demonstrate that this problem can be tractably solved with a Generalized Benders Decomposition algorithm. Our strategy requires high-quality latent features which we obtain by unsupervised learning on the unlabeled pool. Numerical results on several data sets show that our optimization approach is competitive with baselines and particularly outperforms them in the low budget regime where less than one percent of the data set is labeled.
DriveGAN: Towards a Controllable High-Quality Neural Simulation
Apr 30, 2021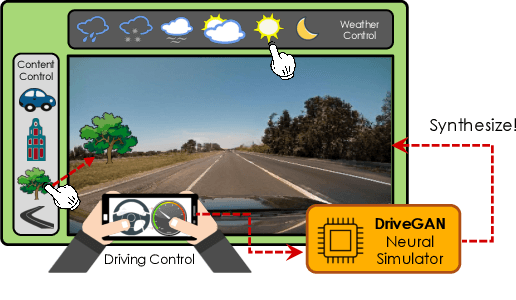
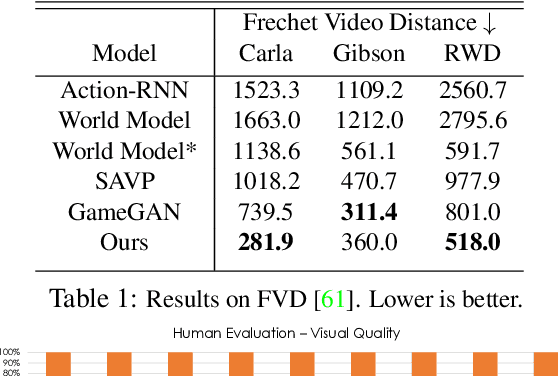
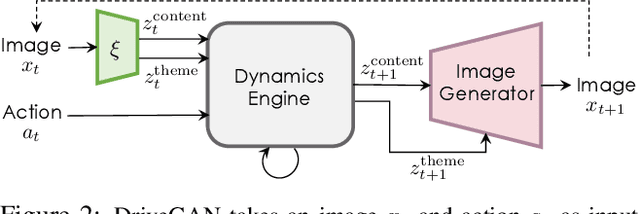
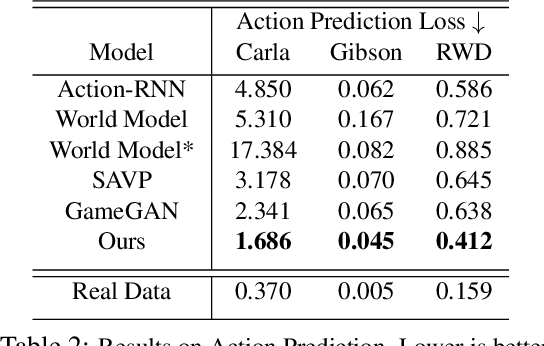
Realistic simulators are critical for training and verifying robotics systems. While most of the contemporary simulators are hand-crafted, a scaleable way to build simulators is to use machine learning to learn how the environment behaves in response to an action, directly from data. In this work, we aim to learn to simulate a dynamic environment directly in pixel-space, by watching unannotated sequences of frames and their associated action pairs. We introduce a novel high-quality neural simulator referred to as DriveGAN that achieves controllability by disentangling different components without supervision. In addition to steering controls, it also includes controls for sampling features of a scene, such as the weather as well as the location of non-player objects. Since DriveGAN is a fully differentiable simulator, it further allows for re-simulation of a given video sequence, offering an agent to drive through a recorded scene again, possibly taking different actions. We train DriveGAN on multiple datasets, including 160 hours of real-world driving data. We showcase that our approach greatly surpasses the performance of previous data-driven simulators, and allows for new features not explored before.
Towards Good Practices for Efficiently Annotating Large-Scale Image Classification Datasets
Apr 26, 2021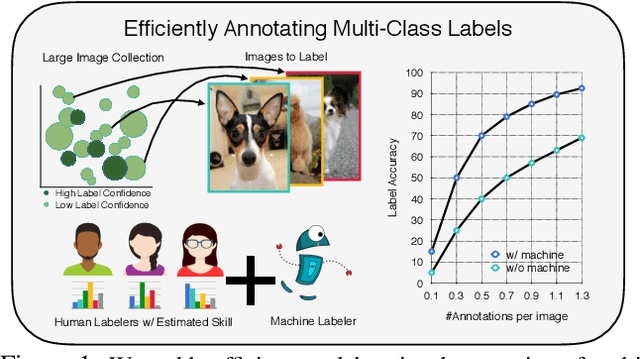

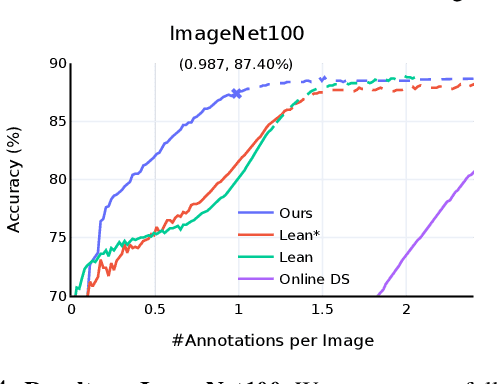
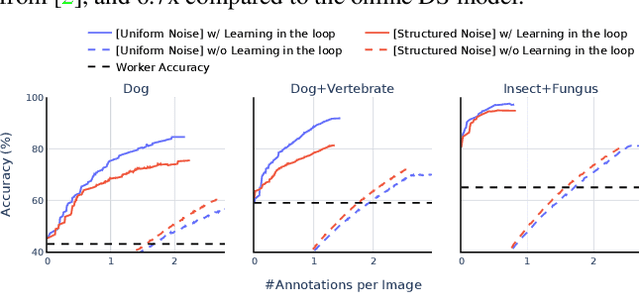
Data is the engine of modern computer vision, which necessitates collecting large-scale datasets. This is expensive, and guaranteeing the quality of the labels is a major challenge. In this paper, we investigate efficient annotation strategies for collecting multi-class classification labels for a large collection of images. While methods that exploit learnt models for labeling exist, a surprisingly prevalent approach is to query humans for a fixed number of labels per datum and aggregate them, which is expensive. Building on prior work on online joint probabilistic modeling of human annotations and machine-generated beliefs, we propose modifications and best practices aimed at minimizing human labeling effort. Specifically, we make use of advances in self-supervised learning, view annotation as a semi-supervised learning problem, identify and mitigate pitfalls and ablate several key design choices to propose effective guidelines for labeling. Our analysis is done in a more realistic simulation that involves querying human labelers, which uncovers issues with evaluation using existing worker simulation methods. Simulated experiments on a 125k image subset of the ImageNet100 show that it can be annotated to 80% top-1 accuracy with 0.35 annotations per image on average, a 2.7x and 6.7x improvement over prior work and manual annotation, respectively. Project page: https://fidler-lab.github.io/efficient-annotation-cookbook
DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort
Apr 20, 2021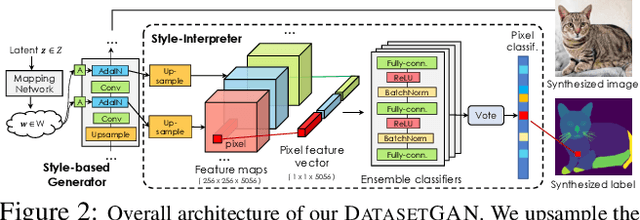
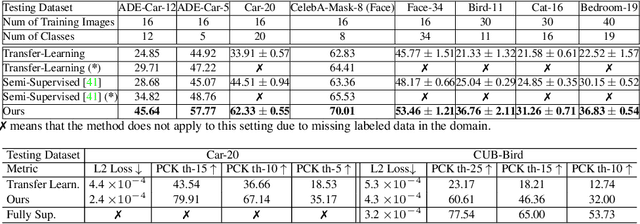
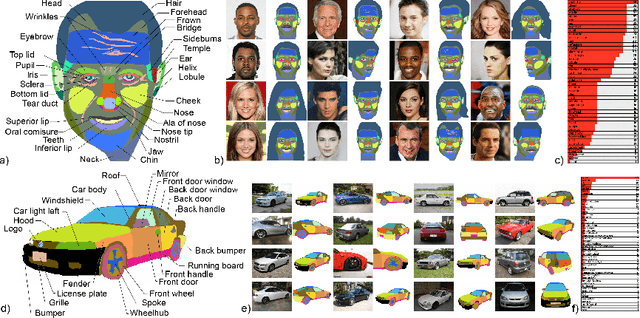
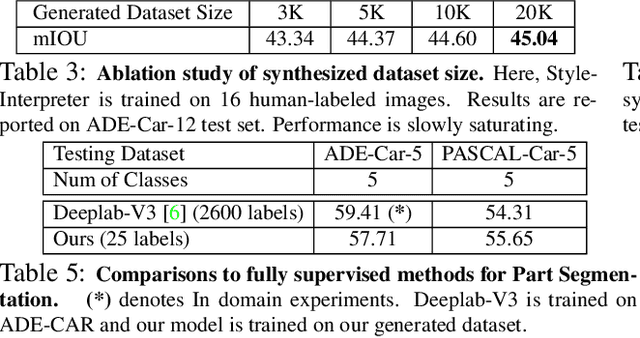
We introduce DatasetGAN: an automatic procedure to generate massive datasets of high-quality semantically segmented images requiring minimal human effort. Current deep networks are extremely data-hungry, benefiting from training on large-scale datasets, which are time consuming to annotate. Our method relies on the power of recent GANs to generate realistic images. We show how the GAN latent code can be decoded to produce a semantic segmentation of the image. Training the decoder only needs a few labeled examples to generalize to the rest of the latent space, resulting in an infinite annotated dataset generator! These generated datasets can then be used for training any computer vision architecture just as real datasets are. As only a few images need to be manually segmented, it becomes possible to annotate images in extreme detail and generate datasets with rich object and part segmentations. To showcase the power of our approach, we generated datasets for 7 image segmentation tasks which include pixel-level labels for 34 human face parts, and 32 car parts. Our approach outperforms all semi-supervised baselines significantly and is on par with fully supervised methods, which in some cases require as much as 100x more annotated data as our method.
Semantic Segmentation with Generative Models: Semi-Supervised Learning and Strong Out-of-Domain Generalization
Apr 12, 2021



Training deep networks with limited labeled data while achieving a strong generalization ability is key in the quest to reduce human annotation efforts. This is the goal of semi-supervised learning, which exploits more widely available unlabeled data to complement small labeled data sets. In this paper, we propose a novel framework for discriminative pixel-level tasks using a generative model of both images and labels. Concretely, we learn a generative adversarial network that captures the joint image-label distribution and is trained efficiently using a large set of unlabeled images supplemented with only few labeled ones. We build our architecture on top of StyleGAN2, augmented with a label synthesis branch. Image labeling at test time is achieved by first embedding the target image into the joint latent space via an encoder network and test-time optimization, and then generating the label from the inferred embedding. We evaluate our approach in two important domains: medical image segmentation and part-based face segmentation. We demonstrate strong in-domain performance compared to several baselines, and are the first to showcase extreme out-of-domain generalization, such as transferring from CT to MRI in medical imaging, and photographs of real faces to paintings, sculptures, and even cartoons and animal faces. Project Page: \url{https://nv-tlabs.github.io/semanticGAN/}
Image-Level or Object-Level? A Tale of Two Resampling Strategies for Long-Tailed Detection
Apr 12, 2021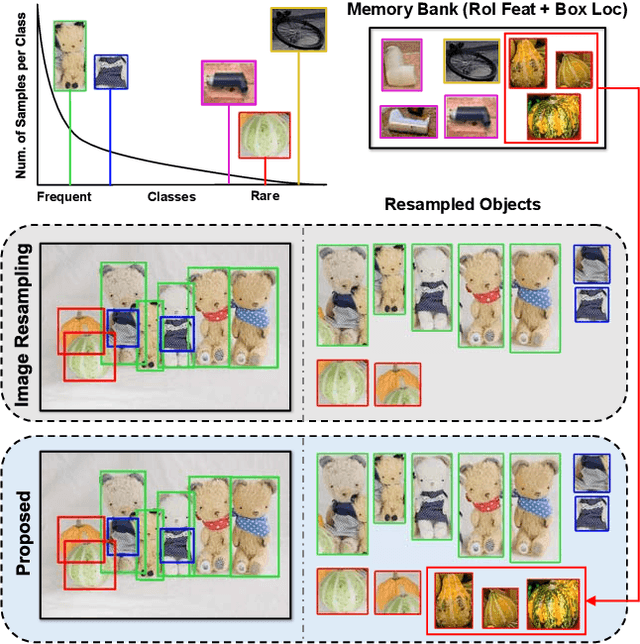
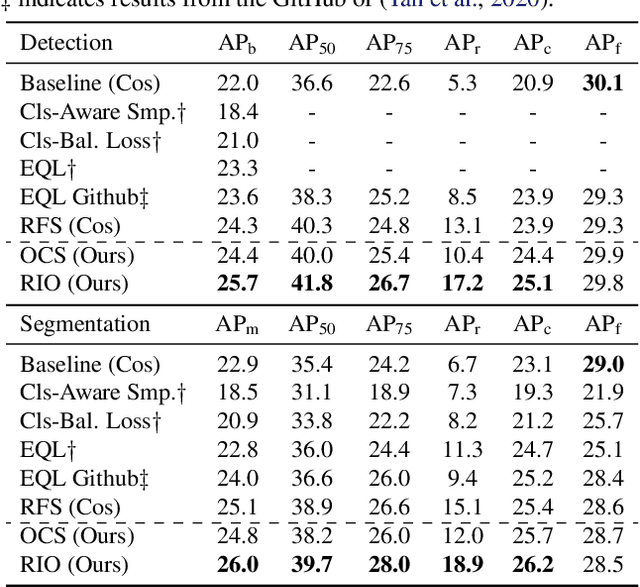

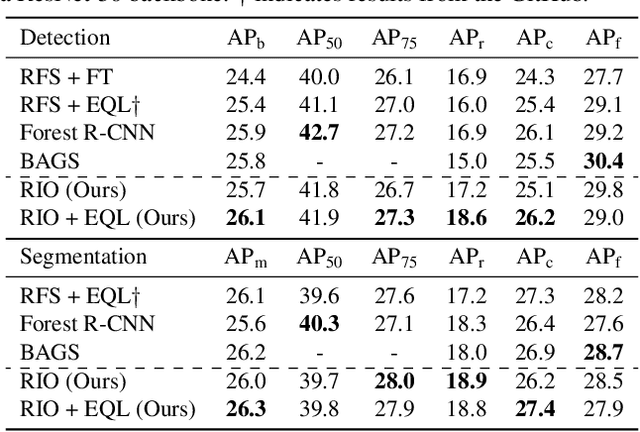
Training on datasets with long-tailed distributions has been challenging for major recognition tasks such as classification and detection. To deal with this challenge, image resampling is typically introduced as a simple but effective approach. However, we observe that long-tailed detection differs from classification since multiple classes may be present in one image. As a result, image resampling alone is not enough to yield a sufficiently balanced distribution at the object level. We address object-level resampling by introducing an object-centric memory replay strategy based on dynamic, episodic memory banks. Our proposed strategy has two benefits: 1) convenient object-level resampling without significant extra computation, and 2) implicit feature-level augmentation from model updates. We show that image-level and object-level resamplings are both important, and thus unify them with a joint resampling strategy (RIO). Our method outperforms state-of-the-art long-tailed detection and segmentation methods on LVIS v0.5 across various backbones.
gradSim: Differentiable simulation for system identification and visuomotor control
Apr 06, 2021
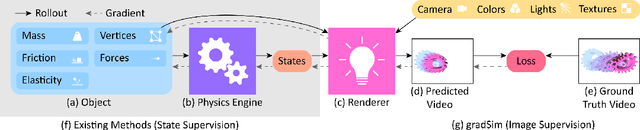
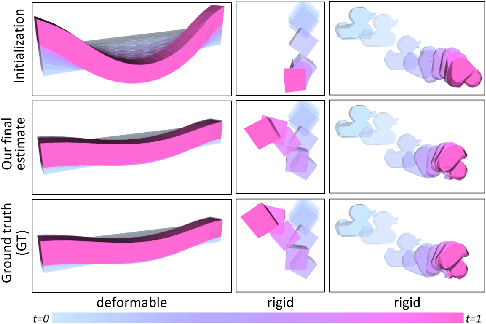

We consider the problem of estimating an object's physical properties such as mass, friction, and elasticity directly from video sequences. Such a system identification problem is fundamentally ill-posed due to the loss of information during image formation. Current solutions require precise 3D labels which are labor-intensive to gather, and infeasible to create for many systems such as deformable solids or cloth. We present gradSim, a framework that overcomes the dependence on 3D supervision by leveraging differentiable multiphysics simulation and differentiable rendering to jointly model the evolution of scene dynamics and image formation. This novel combination enables backpropagation from pixels in a video sequence through to the underlying physical attributes that generated them. Moreover, our unified computation graph -- spanning from the dynamics and through the rendering process -- enables learning in challenging visuomotor control tasks, without relying on state-based (3D) supervision, while obtaining performance competitive to or better than techniques that rely on precise 3D labels.