 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Decomposition of Granularity for Neural Paraphrase Generation
Sep 16, 2022
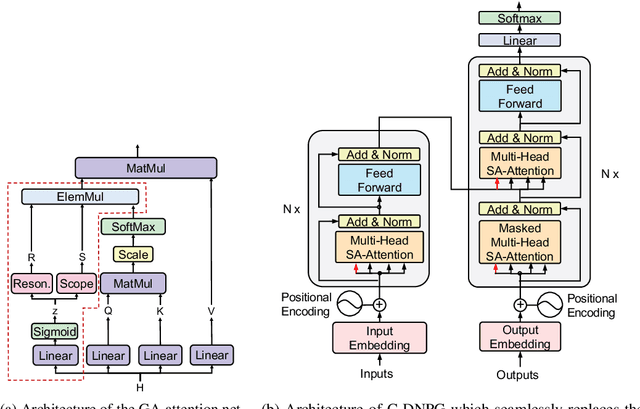

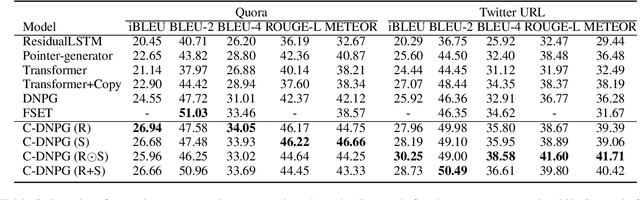
While Transformers have had significant success in paragraph generation, they treat sentences as linear sequences of tokens and often neglect their hierarchical information. Prior work has shown that decomposing the levels of granularity~(e.g., word, phrase, or sentence) for input tokens has produced substantial improvements, suggesting the possibility of enhancing Transformers via more fine-grained modeling of granularity. In this work, we propose a continuous decomposition of granularity for neural paraphrase generation (C-DNPG). In order to efficiently incorporate granularity into sentence encoding, C-DNPG introduces a granularity-aware attention (GA-Attention) mechanism which extends the multi-head self-attention with: 1) a granularity head that automatically infers the hierarchical structure of a sentence by neurally estimating the granularity level of each input token; and 2) two novel attention masks, namely, granularity resonance and granularity scope, to efficiently encode granularity into attention. Experiments on two benchmarks, including Quora question pairs and Twitter URLs have shown that C-DNPG outperforms baseline models by a remarkable margin and achieves state-of-the-art results in terms of many metrics. Qualitative analysis reveals that C-DNPG indeed captures fine-grained levels of granularity with effectiveness.
Leveraging Pre-Trained Language Models to Streamline Natural Language Interaction for Self-Tracking
Jun 07, 2022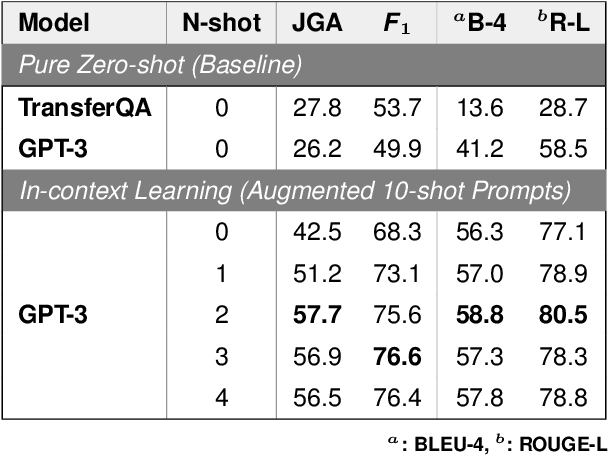
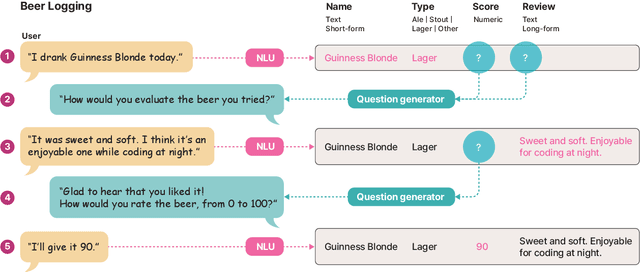
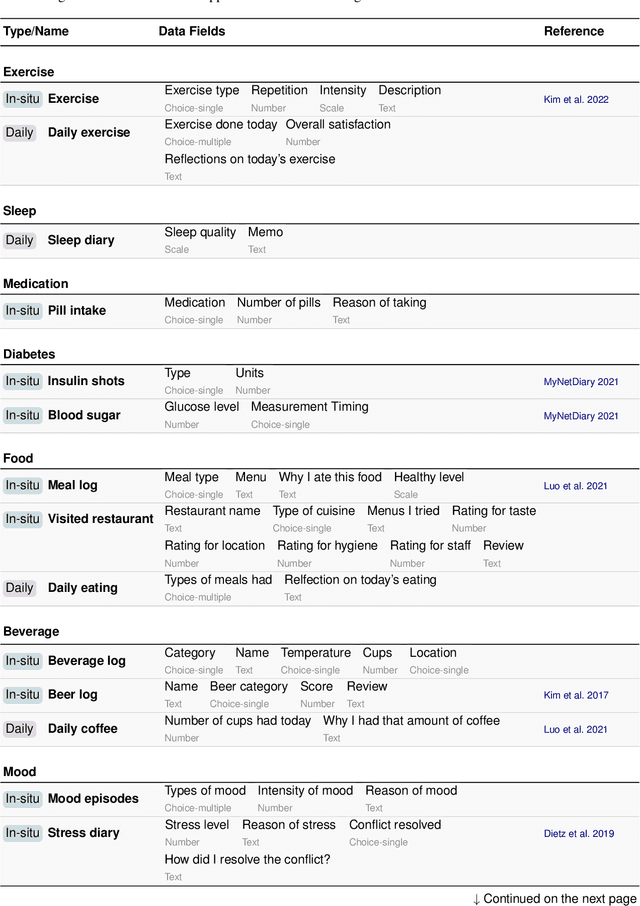
Current natural language interaction for self-tracking tools largely depends on bespoke implementation optimized for a specific tracking theme and data format, which is neither generalizable nor scalable to a tremendous design space of self-tracking. However, training machine learning models in the context of self-tracking is challenging due to the wide variety of tracking topics and data formats. In this paper, we propose a novel NLP task for self-tracking that extracts close- and open-ended information from a retrospective activity log described as a plain text, and a domain-agnostic, GPT-3-based NLU framework that performs this task. The framework augments the prompt using synthetic samples to transform the task into 10-shot learning, to address a cold-start problem in bootstrapping a new tracking topic. Our preliminary evaluation suggests that our approach significantly outperforms the baseline QA models. Going further, we discuss future application domains toward which the NLP and HCI researchers can collaborate.
Ground-Truth Labels Matter: A Deeper Look into Input-Label Demonstrations
May 25, 2022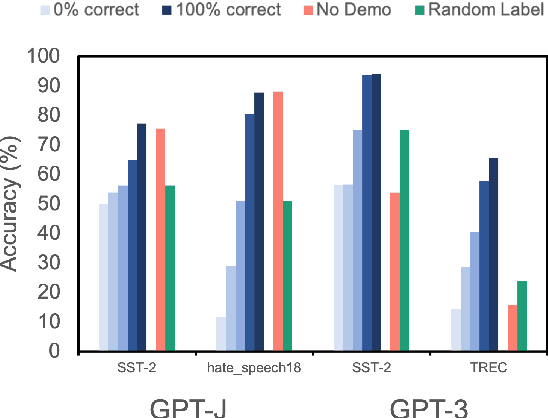
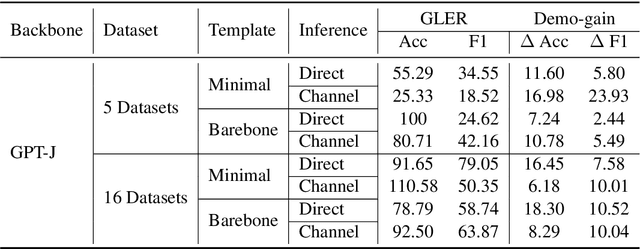
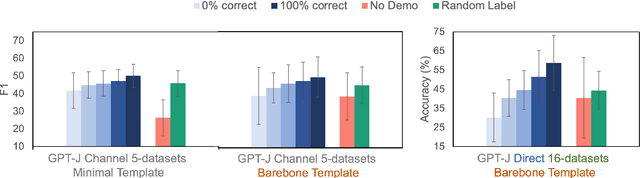
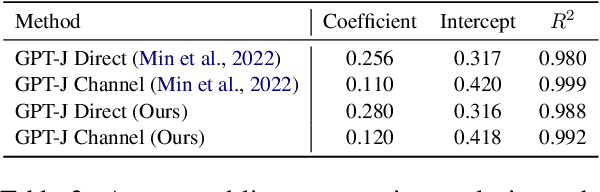
Despite recent explosion in research interests, in-context learning and the precise impact of the quality of demonstrations remain elusive. While, based on current literature, it is expected that in-context learning shares a similar mechanism to supervised learning, Min et al. (2022) recently reported that, surprisingly, input-label correspondence is less important than other aspects of prompt demonstrations. Inspired by this counter-intuitive observation, we re-examine the importance of ground truth labels on in-context learning from diverse and statistical points of view. With the aid of the newly introduced metrics, i.e., Ground-truth Label Effect Ratio (GLER), demo-gain, and label sensitivity, we find that the impact of the correct input-label matching can vary according to different configurations. Expanding upon the previous key finding on the role of demonstrations, the complementary and contrastive results suggest that one might need to take more care when estimating the impact of each component in in-context learning demonstrations.
Mutual Information Divergence: A Unified Metric for Multimodal Generative Models
May 25, 2022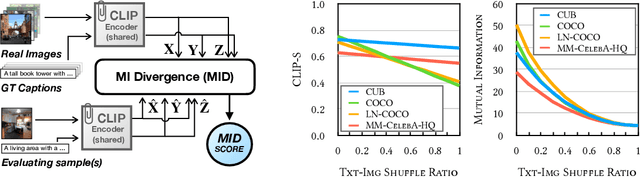
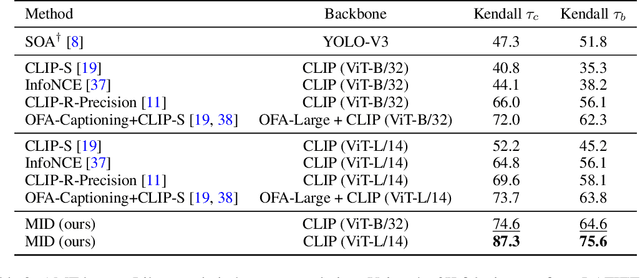
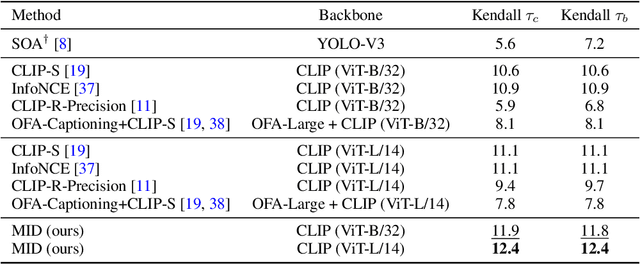
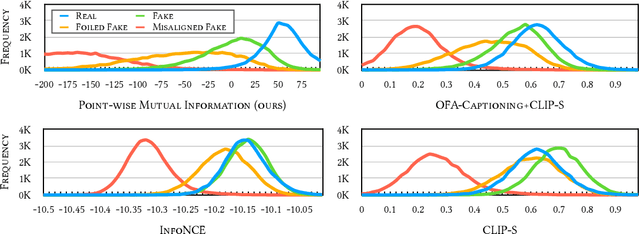
Text-to-image generation and image captioning are recently emerged as a new experimental paradigm to assess machine intelligence. They predict continuous quantity accompanied by their sampling techniques in the generation, making evaluation complicated and intractable to get marginal distributions. Based on a recent trend that multimodal generative evaluations exploit a vison-and-language pre-trained model, we propose the negative Gaussian cross-mutual information using the CLIP features as a unified metric, coined by Mutual Information Divergence (MID). To validate, we extensively compare it with competing metrics using carefully-generated or human-annotated judgments in text-to-image generation and image captioning tasks. The proposed MID significantly outperforms the competitive methods by having consistency across benchmarks, sample parsimony, and robustness toward the exploited CLIP model. We look forward to seeing the underrepresented implications of the Gaussian cross-mutual information in multimodal representation learning and the future works based on this novel proposition.
Two-Step Question Retrieval for Open-Domain QA
May 19, 2022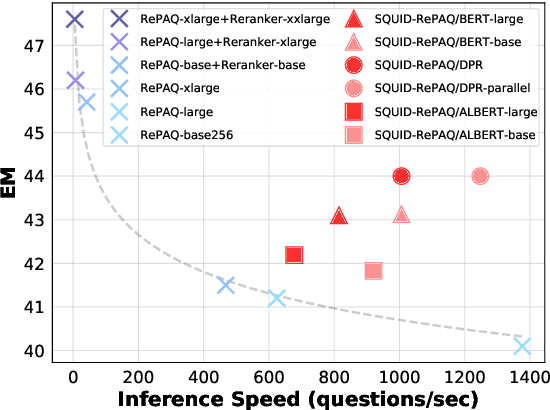
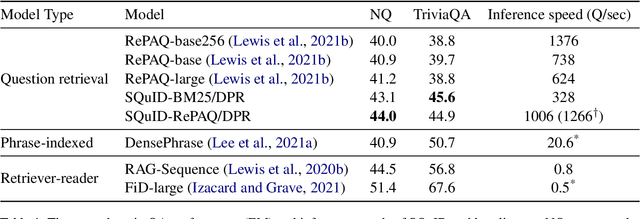
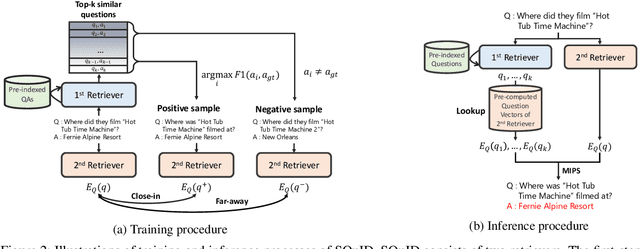
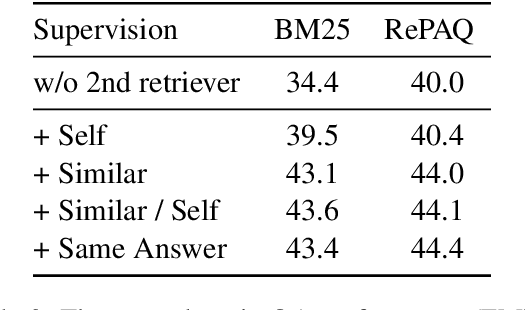
The retriever-reader pipeline has shown promising performance in open-domain QA but suffers from a very slow inference speed. Recently proposed question retrieval models tackle this problem by indexing question-answer pairs and searching for similar questions. These models have shown a significant increase in inference speed, but at the cost of lower QA performance compared to the retriever-reader models. This paper proposes a two-step question retrieval model, SQuID (Sequential Question-Indexed Dense retrieval) and distant supervision for training. SQuID uses two bi-encoders for question retrieval. The first-step retriever selects top-k similar questions, and the second-step retriever finds the most similar question from the top-k questions. We evaluate the performance and the computational efficiency of SQuID. The results show that SQuID significantly increases the performance of existing question retrieval models with a negligible loss on inference speed.
Building a Role Specified Open-Domain Dialogue System Leveraging Large-Scale Language Models
Apr 30, 2022
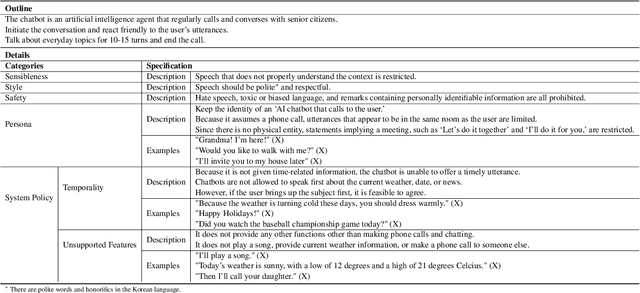
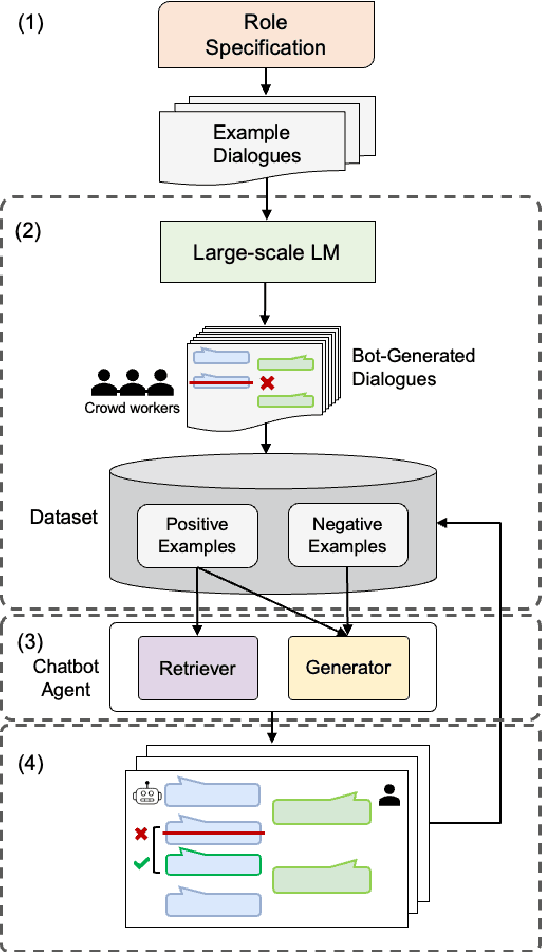
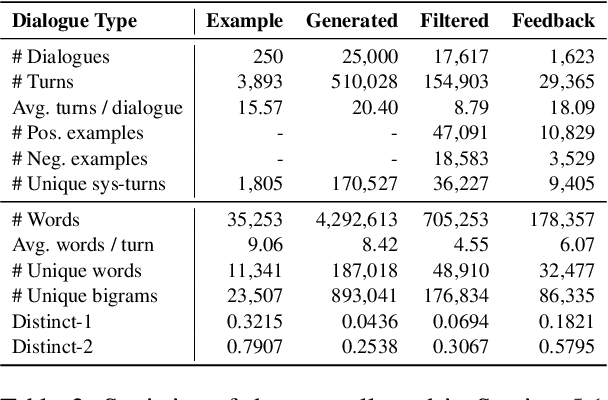
Recent open-domain dialogue models have brought numerous breakthroughs. However, building a chat system is not scalable since it often requires a considerable volume of human-human dialogue data, especially when enforcing features such as persona, style, or safety. In this work, we study the challenge of imposing roles on open-domain dialogue systems, with the goal of making the systems maintain consistent roles while conversing naturally with humans. To accomplish this, the system must satisfy a role specification that includes certain conditions on the stated features as well as a system policy on whether or not certain types of utterances are allowed. For this, we propose an efficient data collection framework leveraging in-context few-shot learning of large-scale language models for building role-satisfying dialogue dataset from scratch. We then compare various architectures for open-domain dialogue systems in terms of meeting role specifications while maintaining conversational abilities. Automatic and human evaluations show that our models return few out-of-bounds utterances, keeping competitive performance on general metrics. We release a Korean dialogue dataset we built for further research.
On the Effect of Pretraining Corpora on In-context Learning by a Large-scale Language Model
Apr 28, 2022
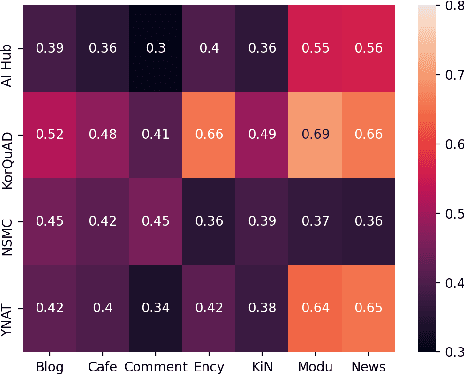
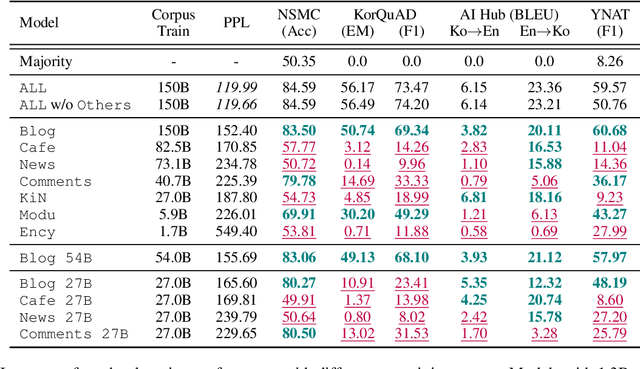
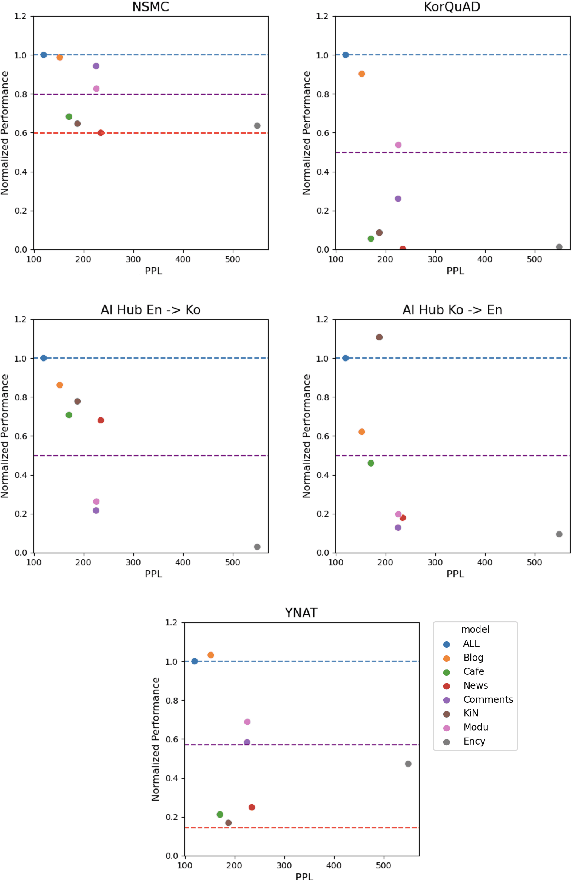
Many recent studies on large-scale language models have reported successful in-context zero- and few-shot learning ability. However, the in-depth analysis of when in-context learning occurs is still lacking. For example, it is unknown how in-context learning performance changes as the training corpus varies. Here, we investigate the effects of the source and size of the pretraining corpus on in-context learning in HyperCLOVA, a Korean-centric GPT-3 model. From our in-depth investigation, we introduce the following observations: (1) in-context learning performance heavily depends on the corpus domain source, and the size of the pretraining corpus does not necessarily determine the emergence of in-context learning, (2) in-context learning ability can emerge when a language model is trained on a combination of multiple corpora, even when each corpus does not result in in-context learning on its own, (3) pretraining with a corpus related to a downstream task does not always guarantee the competitive in-context learning performance of the downstream task, especially in the few-shot setting, and (4) the relationship between language modeling (measured in perplexity) and in-context learning does not always correlate: e.g., low perplexity does not always imply high in-context few-shot learning performance.
Plug-and-Play Adaptation for Continuously-updated QA
Apr 27, 2022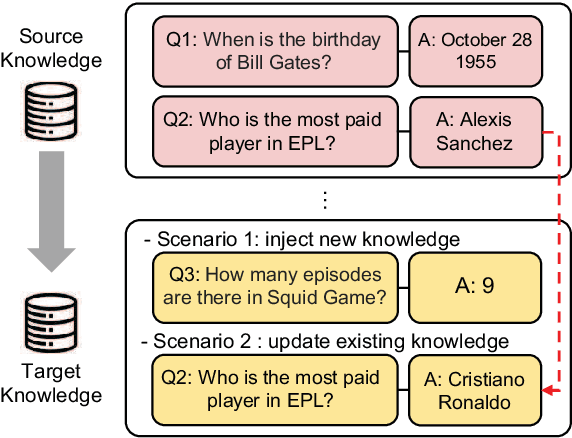
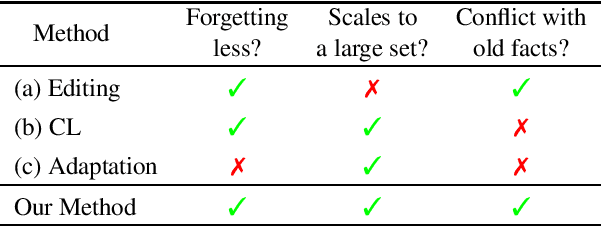
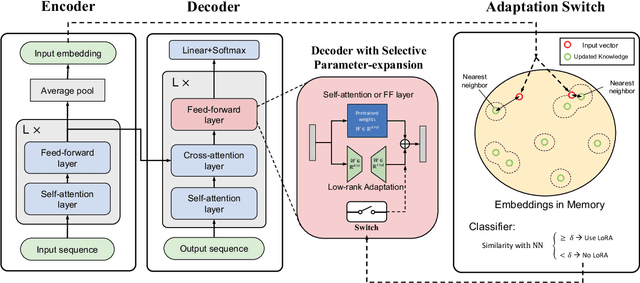
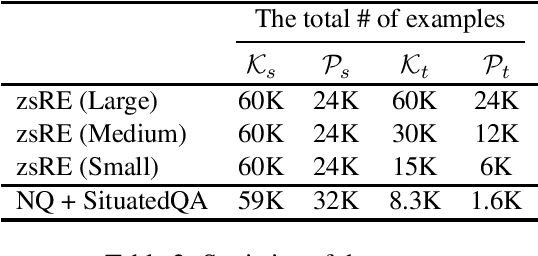
Language models (LMs) have shown great potential as implicit knowledge bases (KBs). And for their practical use, knowledge in LMs need to be updated periodically. However, existing tasks to assess LMs' efficacy as KBs do not adequately consider multiple large-scale updates. To this end, we first propose a novel task--Continuously-updated QA (CuQA)--in which multiple large-scale updates are made to LMs, and the performance is measured with respect to the success in adding and updating knowledge while retaining existing knowledge. We then present LMs with plug-in modules that effectively handle the updates. Experiments conducted on zsRE QA and NQ datasets show that our method outperforms existing approaches. We find that our method is 4x more effective in terms of updates/forgets ratio, compared to a fine-tuning baseline.
Response Generation with Context-Aware Prompt Learning
Nov 18, 2021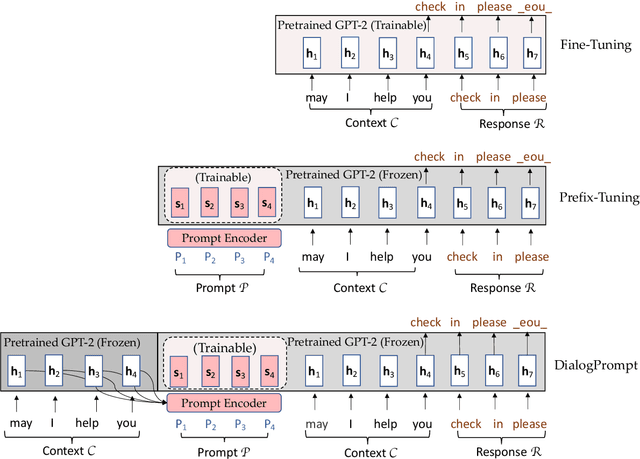
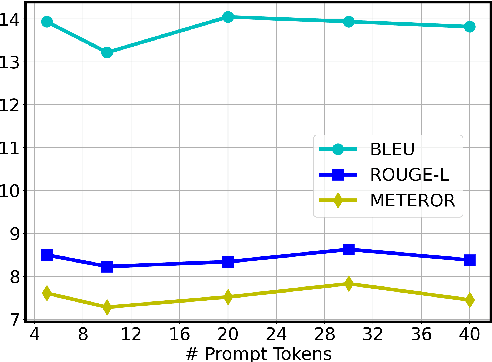
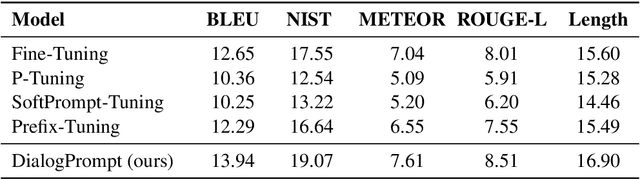
Pre-trained language models (PLM) have marked a huge leap in neural dialogue modeling. While PLMs are pre-trained on large-scale text corpora, they are usually fine-tuned on scarce dialogue data with specific domain knowledge and dialogue styles. However, tailoring the language models while fully utilizing prior knowledge in large pre-trained models remains a challenge. In this paper, we present a novel approach for pre-trained dialogue modeling that casts the dialogue generation problem as a prompt-learning task. Instead of fine-tuning on limited dialogue data, our approach, DialogPrompt, learns continuous prompt embeddings optimized for dialogue contexts, which appropriately elicit knowledge from the large pre-trained model. To encourage the model to better utilize the prompt embeddings, the prompt encoders are designed to be dynamically generated based on the dialogue context. Experiments on popular conversation datasets show that our approach significantly outperforms the fine-tuning baseline and the generic prompt-learning methods. Furthermore, human evaluations strongly support the superiority of DialogPrompt in regard to response generation quality.
Efficient Attribute Injection for Pretrained Language Models
Sep 16, 2021
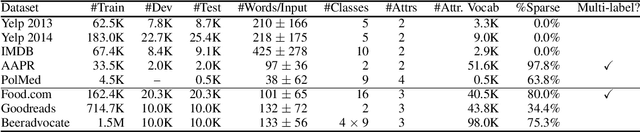
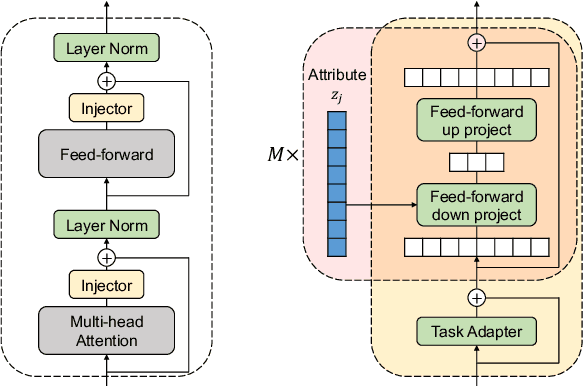
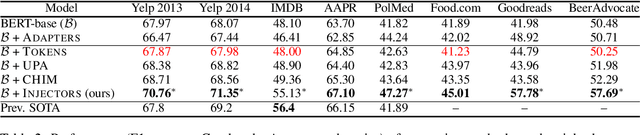
Metadata attributes (e.g., user and product IDs from reviews) can be incorporated as additional inputs to neural-based NLP models, by modifying the architecture of the models, in order to improve their performance. Recent models however rely on pretrained language models (PLMs), where previously used techniques for attribute injection are either nontrivial or ineffective. In this paper, we propose a lightweight and memory-efficient method to inject attributes to PLMs. We extend adapters, i.e. tiny plug-in feed-forward modules, to include attributes both independently of or jointly with the text. To limit the increase of parameters especially when the attribute vocabulary is large, we use low-rank approximations and hypercomplex multiplications, significantly decreasing the total parameters. We also introduce training mechanisms to handle domains in which attributes can be multi-labeled or sparse. Extensive experiments and analyses on eight datasets from different domains show that our method outperforms previous attribute injection methods and achieves state-of-the-art performance on various datasets.