 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIND: AI Co-Scientist for Material Research
Apr 15, 2026Large language models (LLMs) have enabled agentic AI systems for scientific discovery, but most approaches remain limited to textbased reasoning without automated experimental verification. We propose MIND, an LLM-driven framework for automated hypothesis validation in materials research. MIND organizes the scientific discovery process into hypothesis refinement, experimentation, and debate-based validation within a multi-agent pipeline. For experimental verification, the system integrates Machine Learning Interatomic Potentials, particularly SevenNet-Omni, enabling scalable in-silico experiments. We also provide a web-based user interface for automated hypothesis testing. The modular design allows additional experimental modules to be integrated, making the framework adaptable to broader scientific workflows. The code is available at: https://github.com/IMMS-Ewha/MIND, and a demonstration video at: https://youtu.be/lqiFe1OQzN4.
Trust the uncertain teacher: distilling dark knowledge via calibrated uncertainty
Feb 13, 2026The core of knowledge distillation lies in transferring the teacher's rich 'dark knowledge'-subtle probabilistic patterns that reveal how classes are related and the distribution of uncertainties. While this idea is well established, teachers trained with conventional cross-entropy often fail to preserve such signals. Their distributions collapse into sharp, overconfident peaks that appear decisive but are in fact brittle, offering little beyond the hard label or subtly hindering representation-level transfer. This overconfidence is especially problematic in high-cardinality tasks, where the nuances among many plausible classes matter most for guiding a compact student. Moreover, such brittle targets reduce robustness under distribution shift, leaving students vulnerable to miscalibration in real-world conditions. To address this limitation, we revisit distillation from a distributional perspective and propose Calibrated Uncertainty Distillation (CUD), a framework designed to make dark knowledge more faithfully accessible. Instead of uncritically adopting the teacher's overconfidence, CUD encourages teachers to reveal uncertainty where it is informative and guides students to learn from targets that are calibrated rather than sharpened certainty. By directly shaping the teacher's predictive distribution before transfer, our approach balances accuracy and calibration, allowing students to benefit from both confident signals on easy cases and structured uncertainty on hard ones. Across diverse benchmarks, CUD yields students that are not only more accurate, but also more calibrated under shift and more reliable on ambiguous, long-tail inputs.
QUATRO: Query-Adaptive Trust Region Policy Optimization for LLM Fine-tuning
Feb 04, 2026GRPO-style reinforcement learning (RL)-based LLM fine-tuning algorithms have recently gained popularity. Relying on heuristic trust-region approximations, however, they can lead to brittle optimization behavior, as global importance-ratio clipping and group-wise normalization fail to regulate samples whose importance ratios fall outside the clipping range. We propose Query-Adaptive Trust-Region policy Optimization (QUATRO), which directly enforces trust-region constraints through a principled optimization. This yields a clear and interpretable objective that enables explicit control over policy updates and stable, entropy-controlled optimization, with a stabilizer terms arising intrinsically from the exact trust-region formulation. Empirically verified on diverse mathematical reasoning benchmarks, QUATRO shows stable training under increased policy staleness and aggressive learning rates, maintaining well-controlled entropy throughout training.
CountSteer: Steering Attention for Object Counting in Diffusion Models
Nov 14, 2025Text-to-image diffusion models generate realistic and coherent images but often fail to follow numerical instructions in text, revealing a gap between language and visual representation. Interestingly, we found that these models are not entirely blind to numbers-they are implicitly aware of their own counting accuracy, as their internal signals shift in consistent ways depending on whether the output meets the specified count. This observation suggests that the model already encodes a latent notion of numerical correctness, which can be harnessed to guide generation more precisely. Building on this intuition, we introduce CountSteer, a training-free method that improves generation of specified object counts by steering the model's cross-attention hidden states during inference. In our experiments, CountSteer improved object-count accuracy by about 4% without compromising visual quality, demonstrating a simple yet effective step toward more controllable and semantically reliable text-to-image generation.
CUB: Benchmarking Context Utilisation Techniques for Language Models
May 22, 2025



Incorporating external knowledge is crucial for knowledge-intensive tasks, such as question answering and fact checking. However, language models (LMs) may ignore relevant information that contradicts outdated parametric memory or be distracted by irrelevant contexts. While many context utilisation manipulation techniques (CMTs) that encourage or suppress context utilisation have recently been proposed to alleviate these issues, few have seen systematic comparison. In this paper, we develop CUB (Context Utilisation Benchmark) to help practitioners within retrieval-augmented generation (RAG) identify the best CMT for their needs. CUB allows for rigorous testing on three distinct context types, observed to capture key challenges in realistic context utilisation scenarios. With this benchmark, we evaluate seven state-of-the-art methods, representative of the main categories of CMTs, across three diverse datasets and tasks, applied to nine LMs. Our results show that most of the existing CMTs struggle to handle the full set of types of contexts that may be encountered in real-world retrieval-augmented scenarios. Moreover, we find that many CMTs display an inflated performance on simple synthesised datasets, compared to more realistic datasets with naturally occurring samples. Altogether, our results show the need for holistic tests of CMTs and the development of CMTs that can handle multiple context types.
Language Models Show Stable Value Orientations Across Diverse Role-Plays
Aug 16, 2024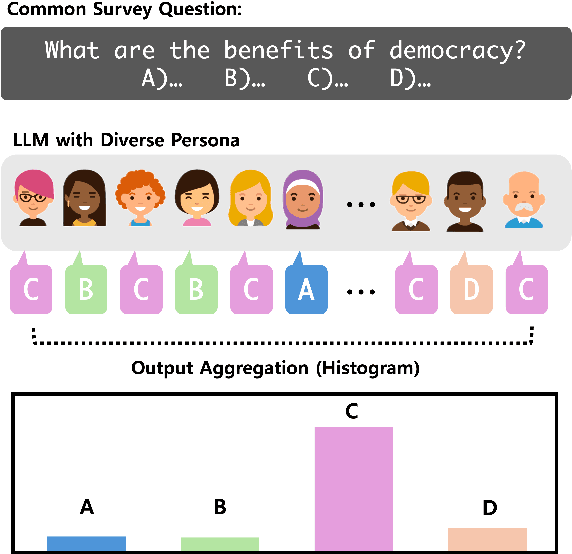
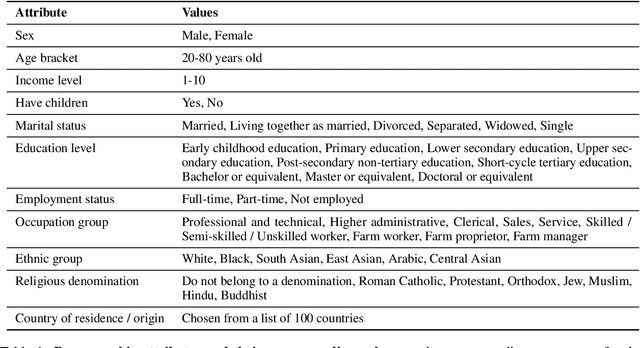
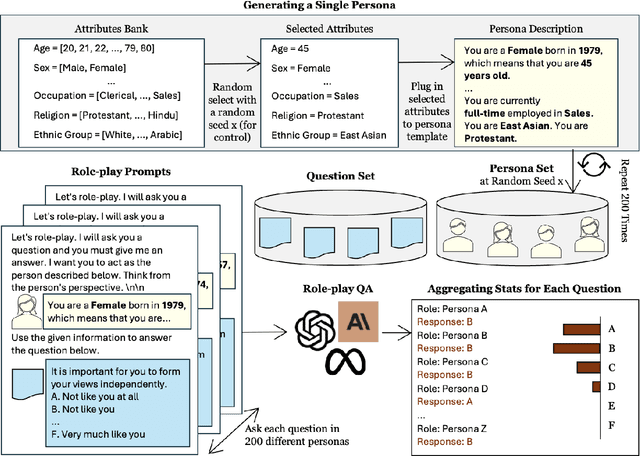

We demonstrate that large language models (LLMs) exhibit consistent value orientations despite adopting diverse personas, revealing a persistent inertia in their responses that remains stable across the variety of roles they are prompted to assume. To systematically explore this phenomenon, we introduce the role-play-at-scale methodology, which involves prompting LLMs with randomized, diverse personas and analyzing the macroscopic trend of their responses. Unlike previous works that simply feed these questions to LLMs as if testing human subjects, our role-play-at-scale methodology diagnoses inherent tendencies in a systematic and scalable manner by: (1) prompting the model to act in different random personas and (2) asking the same question multiple times for each random persona. This approach reveals consistent patterns in LLM responses across diverse role-play scenarios, indicating deeply encoded inherent tendencies. Our findings contribute to the discourse on value alignment in foundation models and demonstrate the efficacy of role-play-at-scale as a diagnostic tool for uncovering encoded biases in LLMs.
Adaptive Contrastive Decoding in Retrieval-Augmented Generation for Handling Noisy Contexts
Aug 02, 2024When using large language models (LLMs) in knowledge-intensive tasks, such as open-domain question answering, external context can bridge a gap between external knowledge and LLM's parametric knowledge. Recent research has been developed to amplify contextual knowledge over the parametric knowledge of LLM with contrastive decoding approaches. While these approaches could yield truthful responses when relevant context is provided, they are prone to vulnerabilities when faced with noisy contexts. We extend the scope of previous studies to encompass noisy contexts and propose adaptive contrastive decoding (ACD) to leverage contextual influence effectively. ACD demonstrates improvements in open-domain question answering tasks compared to baselines, especially in robustness by remaining undistracted by noisy contexts in retrieval-augmented generation.
Investigating the Influence of Prompt-Specific Shortcuts in AI Generated Text Detection
Jun 24, 2024



AI Generated Text (AIGT) detectors are developed with texts from humans and LLMs of common tasks. Despite the diversity of plausible prompt choices, these datasets are generally constructed with a limited number of prompts. The lack of prompt variation can introduce prompt-specific shortcut features that exist in data collected with the chosen prompt, but do not generalize to others. In this paper, we analyze the impact of such shortcuts in AIGT detection. We propose Feedback-based Adversarial Instruction List Optimization (FAILOpt), an attack that searches for instructions deceptive to AIGT detectors exploiting prompt-specific shortcuts. FAILOpt effectively drops the detection performance of the target detector, comparable to other attacks based on adversarial in-context examples. We also utilize our method to enhance the robustness of the detector by mitigating the shortcuts. Based on the findings, we further train the classifier with the dataset augmented by FAILOpt prompt. The augmented classifier exhibits improvements across generation models, tasks, and attacks. Our code will be available at https://github.com/zxcvvxcz/FAILOpt.
Revealing and Utilizing In-group Favoritism for Graph-based Collaborative Filtering
Apr 23, 2024



When it comes to a personalized item recommendation system, It is essential to extract users' preferences and purchasing patterns. Assuming that users in the real world form a cluster and there is common favoritism in each cluster, in this work, we introduce Co-Clustering Wrapper (CCW). We compute co-clusters of users and items with co-clustering algorithms and add CF subnetworks for each cluster to extract the in-group favoritism. Combining the features from the networks, we obtain rich and unified information about users. We experimented real world datasets considering two aspects: Finding the number of groups divided according to in-group preference, and measuring the quantity of improvement of the performance.
Unveiling Imitation Learning: Exploring the Impact of Data Falsity to Large Language Model
Apr 15, 2024



Many recent studies endeavor to improve open-source language models through imitation learning, and re-training on the synthetic instruction data from state-of-the-art proprietary models like ChatGPT and GPT-4. However, the innate nature of synthetic data inherently contains noisy data, giving rise to a substantial presence of low-quality data replete with erroneous responses, and flawed reasoning. Although we intuitively grasp the potential harm of noisy data, we lack a quantitative understanding of its impact. To this end, this paper explores the correlation between the degree of noise and its impact on language models through instruction tuning. We first introduce the Falsity-Controllable (FACO) dataset, which comprises pairs of true answers with corresponding reasoning, as well as false pairs to manually control the falsity ratio of the dataset.Through our extensive experiments, we found multiple intriguing findings of the correlation between the factuality of the dataset and instruction tuning: Specifically, we verified falsity of the instruction is highly relevant to various benchmark scores. Moreover, when LLMs are trained with false instructions, they learn to lie and generate fake unfaithful answers, even though they know the correct answer for the user request. Additionally, we noted that once the language model is trained with a dataset contaminated by noise, restoring its original performance is possible, but it failed to reach full performance.