 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaPairAudioBench: Paralinguistic Pairwise Audio Benchmark for LALM-as-a-Judge
Jun 23, 2026Large Audio-Language Models (LALMs) have been widely used as judge models for the automatic evaluation of generated speech. However, prior approaches predominantly focus on holistic naturalness, leaving fine-grained paralinguistic distinctions underexplored. We introduce ParaPairAudioBench, a pairwise benchmark of 5,175 audio pairs across five paralinguistic dimensions: Style, Rate, Emphasis, Age, and Gender. Our experiments show that current LALM judges still lag behind human judgments by 32%p on average and exhibit severe calibration failures, particularly in Tie cases where the correct decision is to abstain. To further analyze lexical versus acoustic reliance, the benchmark includes both same-transcript and cross-transcript conditions. ParaPairAudioBench enables multi-dimensional, calibration-aware assessment of the reliability of LALM-as-a-Judge for paralinguistic speech evaluation.
What Models Know, How Well They Know It: Knowledge-Weighted Fine-Tuning for Learning When to Say "I Don't Know"
Apr 07, 2026While large language models (LLMs) demonstrate strong capabilities across diverse user queries, they still suffer from hallucinations, often arising from knowledge misalignment between pre-training and fine-tuning. To address this misalignment, we reliably estimate a fine-grained, instance-level knowledge score via multi-sampled inference. Using the knowledge score, we scale the learning signal according to the model's existing knowledge, while encouraging explicit "I don't know" responses for out-of-scope queries. Experimental results show that this approach allows the model to explicitly express uncertainty when it lacks knowledge, while maintaining accuracy on questions it can answer. Furthermore, we propose evaluation metrics for uncertainty, showing that accurate discrimination between known and unknown instances consistently improves performance.
OmniACBench: A Benchmark for Evaluating Context-Grounded Acoustic Control in Omni-Modal Models
Mar 25, 2026Most testbeds for omni-modal models assess multimodal understanding via textual outputs, leaving it unclear whether these models can properly speak their answers. To study this, we introduce OmniACBench, a benchmark for evaluating context-grounded acoustic control in omni-modal models. Given a spoken instruction, a text script, and an image, a model must read the script aloud with an appropriate tone and manner. OmniACBench comprises 3,559 verified instances covering six acoustic features: speech rate, phonation, pronunciation, emotion, global accent, and timbre. Extensive experiments on eight models reveal their limitations in the proposed setting, despite their strong performance on prior textual-output evaluations. Our analyses show that the main bottleneck lies not in processing individual modalities, but in integrating multimodal context for faithful speech generation. Moreover, we identify three common failure modes-weak direct control, failed implicit inference, and failed multimodal grounding-providing insights for developing models that can verbalize responses effectively.
Enhancing Hallucination Detection via Future Context
Jul 28, 2025



Large Language Models (LLMs) are widely used to generate plausible text on online platforms, without revealing the generation process. As users increasingly encounter such black-box outputs, detecting hallucinations has become a critical challenge. To address this challenge, we focus on developing a hallucination detection framework for black-box generators. Motivated by the observation that hallucinations, once introduced, tend to persist, we sample future contexts. The sampled future contexts provide valuable clues for hallucination detection and can be effectively integrated with various sampling-based methods. We extensively demonstrate performance improvements across multiple methods using our proposed sampling approach.
Investigating the Influence of Prompt-Specific Shortcuts in AI Generated Text Detection
Jun 24, 2024



AI Generated Text (AIGT) detectors are developed with texts from humans and LLMs of common tasks. Despite the diversity of plausible prompt choices, these datasets are generally constructed with a limited number of prompts. The lack of prompt variation can introduce prompt-specific shortcut features that exist in data collected with the chosen prompt, but do not generalize to others. In this paper, we analyze the impact of such shortcuts in AIGT detection. We propose Feedback-based Adversarial Instruction List Optimization (FAILOpt), an attack that searches for instructions deceptive to AIGT detectors exploiting prompt-specific shortcuts. FAILOpt effectively drops the detection performance of the target detector, comparable to other attacks based on adversarial in-context examples. We also utilize our method to enhance the robustness of the detector by mitigating the shortcuts. Based on the findings, we further train the classifier with the dataset augmented by FAILOpt prompt. The augmented classifier exhibits improvements across generation models, tasks, and attacks. Our code will be available at https://github.com/zxcvvxcz/FAILOpt.
ZeroDL: Zero-shot Distribution Learning for Text Clustering via Large Language Models
Jun 19, 2024The recent advancements in large language models (LLMs) have brought significant progress in solving NLP tasks. Notably, in-context learning (ICL) is the key enabling mechanism for LLMs to understand specific tasks and grasping nuances. In this paper, we propose a simple yet effective method to contextualize a task toward a specific LLM, by (1) observing how a given LLM describes (all or a part of) target datasets, i.e., open-ended zero-shot inference, and (2) aggregating the open-ended inference results by the LLM, and (3) finally incorporate the aggregated meta-information for the actual task. We show the effectiveness of this approach in text clustering tasks, and also highlight the importance of the contextualization through examples of the above procedure.
Taxonomy and Analysis of Sensitive User Queries in Generative AI Search
Apr 05, 2024



Although there has been a growing interest among industries to integrate generative LLMs into their services, limited experiences and scarcity of resources acts as a barrier in launching and servicing large-scale LLM-based conversational services. In this paper, we share our experiences in developing and operating generative AI models within a national-scale search engine, with a specific focus on the sensitiveness of user queries. We propose a taxonomy for sensitive search queries, outline our approaches, and present a comprehensive analysis report on sensitive queries from actual users.
Ground-Truth Labels Matter: A Deeper Look into Input-Label Demonstrations
May 25, 2022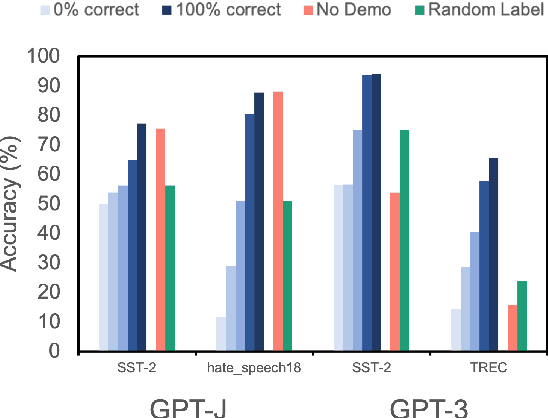
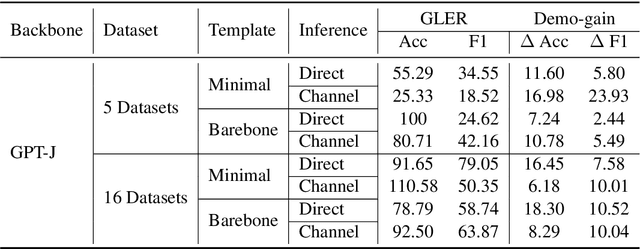
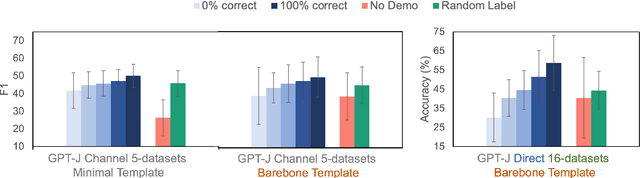
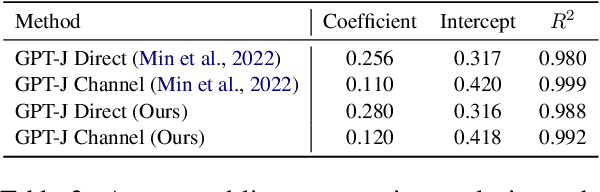
Despite recent explosion in research interests, in-context learning and the precise impact of the quality of demonstrations remain elusive. While, based on current literature, it is expected that in-context learning shares a similar mechanism to supervised learning, Min et al. (2022) recently reported that, surprisingly, input-label correspondence is less important than other aspects of prompt demonstrations. Inspired by this counter-intuitive observation, we re-examine the importance of ground truth labels on in-context learning from diverse and statistical points of view. With the aid of the newly introduced metrics, i.e., Ground-truth Label Effect Ratio (GLER), demo-gain, and label sensitivity, we find that the impact of the correct input-label matching can vary according to different configurations. Expanding upon the previous key finding on the role of demonstrations, the complementary and contrastive results suggest that one might need to take more care when estimating the impact of each component in in-context learning demonstrations.
Human-Like Active Learning: Machines Simulating the Human Learning Process
Nov 07, 2020
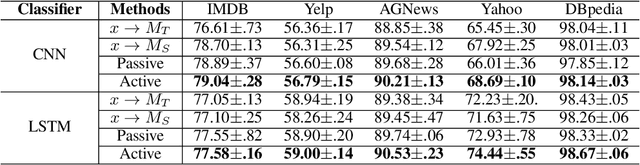
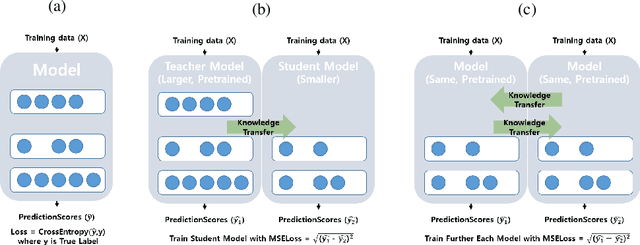
Although the use of active learning to increase learners' engagement has recently been introduced in a variety of methods, empirical experiments are lacking. In this study, we attempted to align two experiments in order to (1) make a hypothesis for machine and (2) empirically confirm the effect of active learning on learning. In Experiment 1, we compared the effect of a passive form of learning to active form of learning. The results showed that active learning had a greater learning outcomes than passive learning. In the machine experiment based on the human result, we imitated the human active learning as a form of knowledge distillation. The active learning framework performed better than the passive learning framework. In the end, we showed not only that we can make build better machine training framework through the human experiment result, but also empirically confirm the result of human experiment through imitated machine experiments; human-like active learning have crucial effect on learning performance.
Ruminating Word Representations with Random Noised Masker
Nov 08, 2019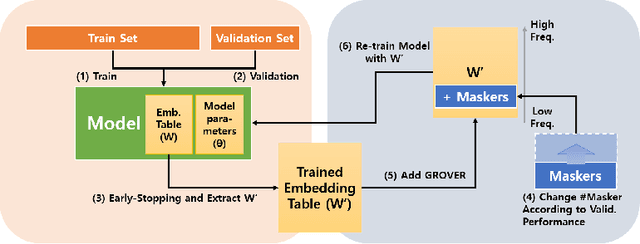
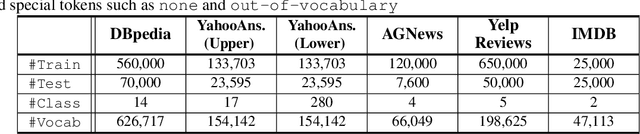
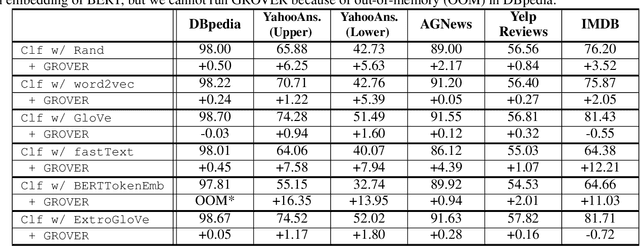
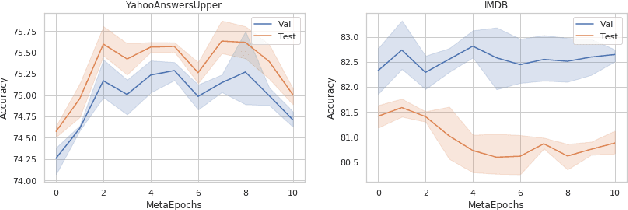
We introduce a training method for both better word representation and performance, which we call GROVER (Gradual Rumination On the Vector with maskERs). The method is to gradually and iteratively add random noises to word embeddings while training a model. GROVER first starts from conventional training process, and then extracts the fine-tuned representations. Next, we gradually add random noises to the word representations and repeat the training process from scratch, but initialize with the noised word representations. Through the re-training process, we can mitigate some noises to be compensated and utilize other noises to learn better representations. As a result, we can get word representations further fine-tuned and specialized on the task. When we experiment with our method on 5 text classification datasets, our method improves model performances on most of the datasets. Moreover, we show that our method can be combined with other regularization techniques, further improving the model performance.