 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware Captions from Context-agnostic Supervision
Jul 31, 2017

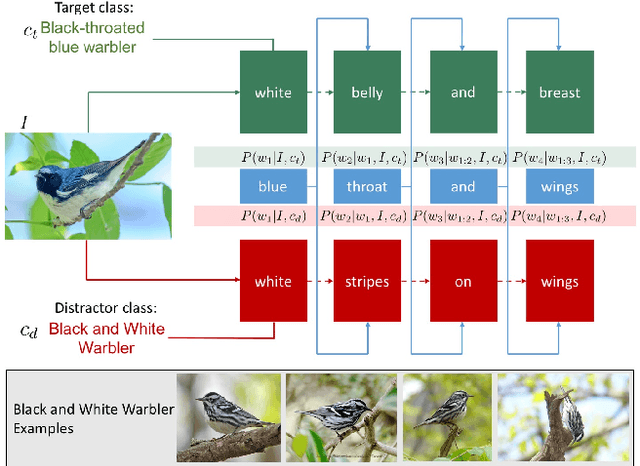

We introduce an inference technique to produce discriminative context-aware image captions (captions that describe differences between images or visual concepts) using only generic context-agnostic training data (captions that describe a concept or an image in isolation). For example, given images and captions of "siamese cat" and "tiger cat", we generate language that describes the "siamese cat" in a way that distinguishes it from "tiger cat". Our key novelty is that we show how to do joint inference over a language model that is context-agnostic and a listener which distinguishes closely-related concepts. We first apply our technique to a justification task, namely to describe why an image contains a particular fine-grained category as opposed to another closely-related category of the CUB-200-2011 dataset. We then study discriminative image captioning to generate language that uniquely refers to one of two semantically-similar images in the COCO dataset. Evaluations with discriminative ground truth for justification and human studies for discriminative image captioning reveal that our approach outperforms baseline generative and speaker-listener approaches for discrimination.
Device Placement Optimization with Reinforcement Learning
Jun 25, 2017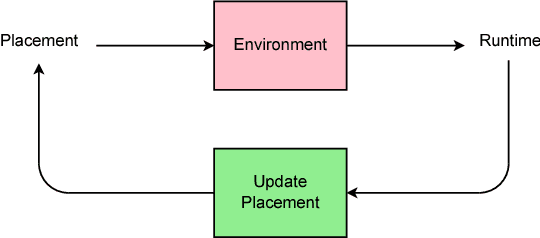
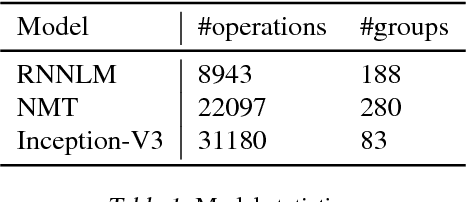
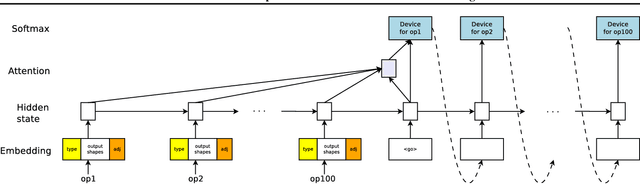
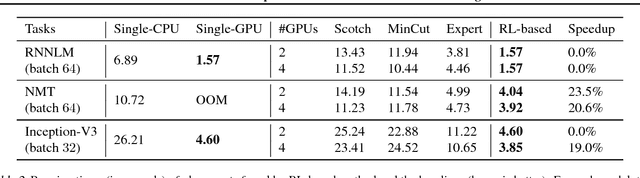
The past few years have witnessed a growth in size and computational requirements for training and inference with neural networks. Currently, a common approach to address these requirements is to use a heterogeneous distributed environment with a mixture of hardware devices such as CPUs and GPUs. Importantly, the decision of placing parts of the neural models on devices is often made by human experts based on simple heuristics and intuitions. In this paper, we propose a method which learns to optimize device placement for TensorFlow computational graphs. Key to our method is the use of a sequence-to-sequence model to predict which subsets of operations in a TensorFlow graph should run on which of the available devices. The execution time of the predicted placements is then used as the reward signal to optimize the parameters of the sequence-to-sequence model. Our main result is that on Inception-V3 for ImageNet classification, and on RNN LSTM, for language modeling and neural machine translation, our model finds non-trivial device placements that outperform hand-crafted heuristics and traditional algorithmic methods.
N-gram Language Modeling using Recurrent Neural Network Estimation
Jun 20, 2017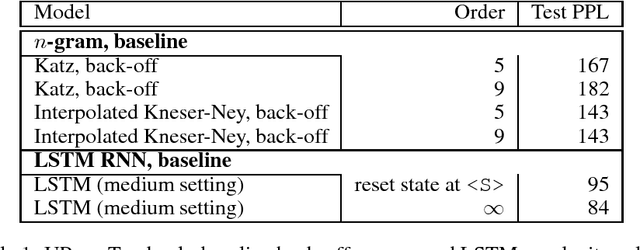
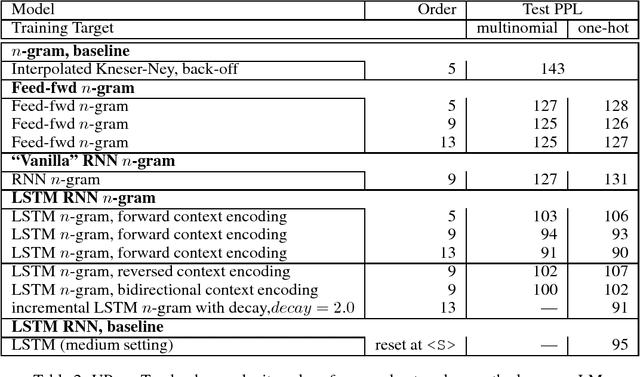


We investigate the effective memory depth of RNN models by using them for $n$-gram language model (LM) smoothing. Experiments on a small corpus (UPenn Treebank, one million words of training data and 10k vocabulary) have found the LSTM cell with dropout to be the best model for encoding the $n$-gram state when compared with feed-forward and vanilla RNN models. When preserving the sentence independence assumption the LSTM $n$-gram matches the LSTM LM performance for $n=9$ and slightly outperforms it for $n=13$. When allowing dependencies across sentence boundaries, the LSTM $13$-gram almost matches the perplexity of the unlimited history LSTM LM. LSTM $n$-gram smoothing also has the desirable property of improving with increasing $n$-gram order, unlike the Katz or Kneser-Ney back-off estimators. Using multinomial distributions as targets in training instead of the usual one-hot target is only slightly beneficial for low $n$-gram orders. Experiments on the One Billion Words benchmark show that the results hold at larger scale: while LSTM smoothing for short $n$-gram contexts does not provide significant advantages over classic N-gram models, it becomes effective with long contexts ($n > 5$); depending on the task and amount of data it can match fully recurrent LSTM models at about $n=13$. This may have implications when modeling short-format text, e.g. voice search/query LMs. Building LSTM $n$-gram LMs may be appealing for some practical situations: the state in a $n$-gram LM can be succinctly represented with $(n-1)*4$ bytes storing the identity of the words in the context and batches of $n$-gram contexts can be processed in parallel. On the downside, the $n$-gram context encoding computed by the LSTM is discarded, making the model more expensive than a regular recurrent LSTM LM.
Sharp Minima Can Generalize For Deep Nets
May 15, 2017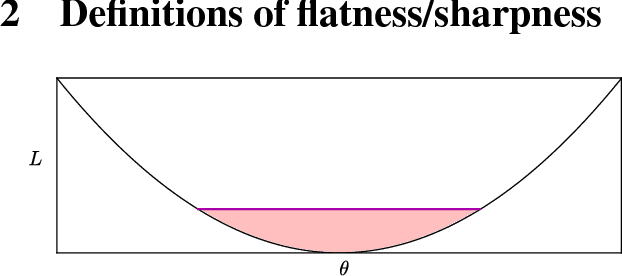
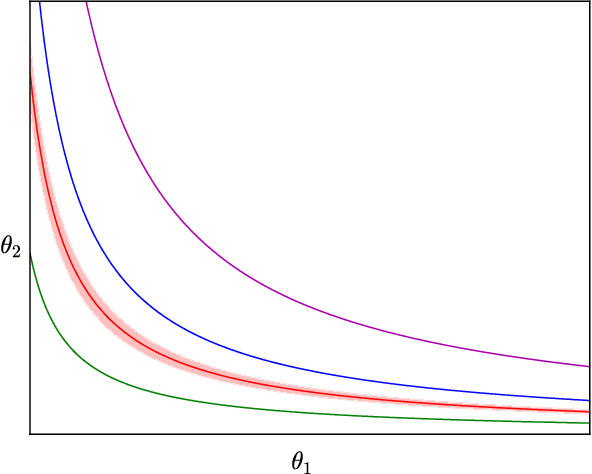
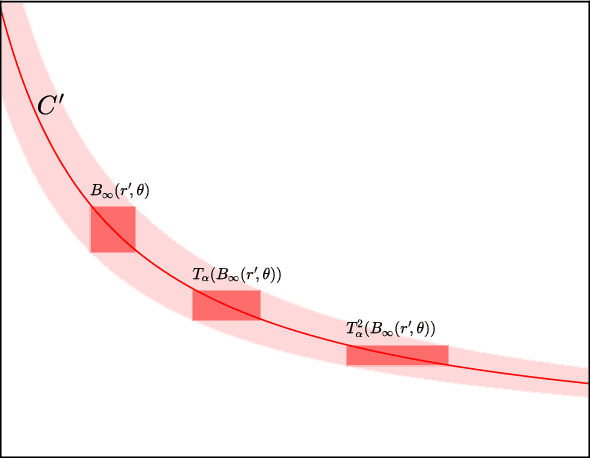
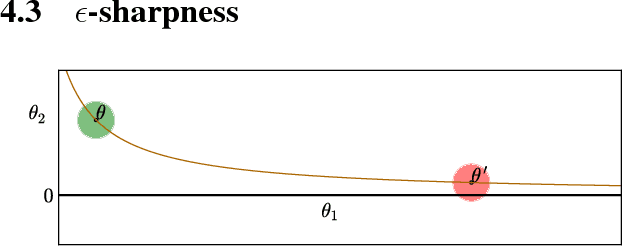
Despite their overwhelming capacity to overfit, deep learning architectures tend to generalize relatively well to unseen data, allowing them to be deployed in practice. However, explaining why this is the case is still an open area of research. One standing hypothesis that is gaining popularity, e.g. Hochreiter & Schmidhuber (1997); Keskar et al. (2017), is that the flatness of minima of the loss function found by stochastic gradient based methods results in good generalization. This paper argues that most notions of flatness are problematic for deep models and can not be directly applied to explain generalization. Specifically, when focusing on deep networks with rectifier units, we can exploit the particular geometry of parameter space induced by the inherent symmetries that these architectures exhibit to build equivalent models corresponding to arbitrarily sharper minima. Furthermore, if we allow to reparametrize a function, the geometry of its parameters can change drastically without affecting its generalization properties.
Tacotron: Towards End-to-End Speech Synthesis
Apr 06, 2017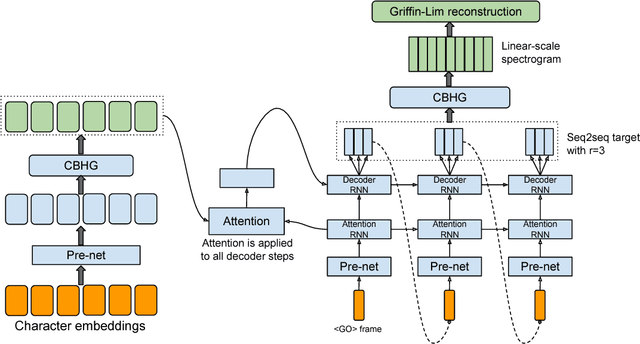
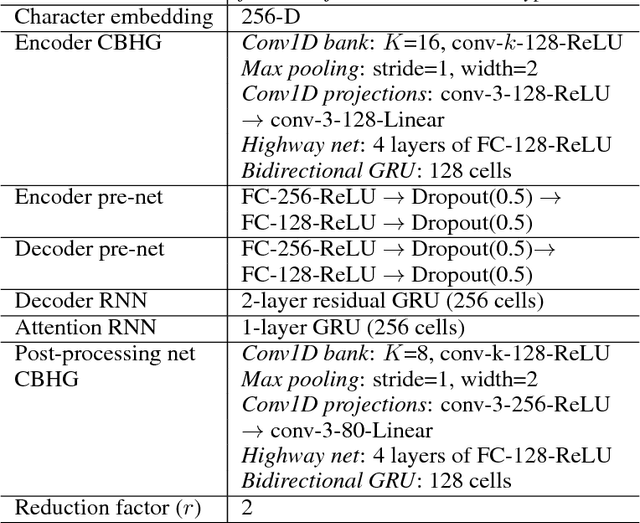
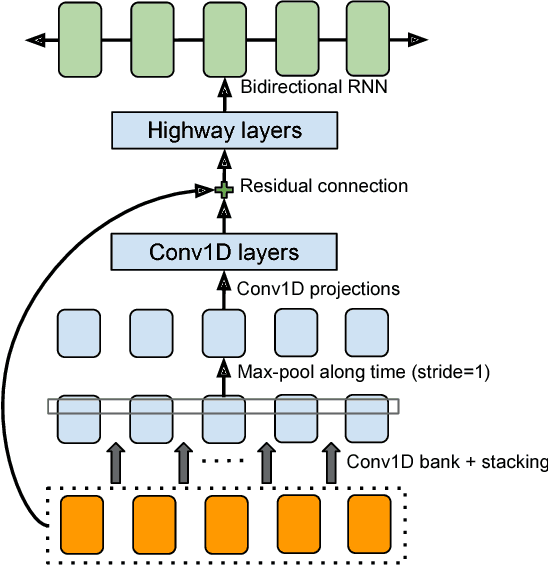
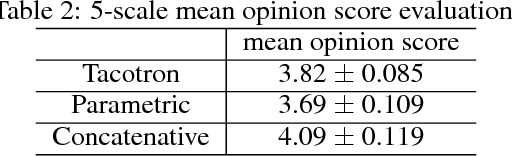
A text-to-speech synthesis system typically consists of multiple stages, such as a text analysis frontend, an acoustic model and an audio synthesis module. Building these components often requires extensive domain expertise and may contain brittle design choices. In this paper, we present Tacotron, an end-to-end generative text-to-speech model that synthesizes speech directly from characters. Given <text, audio> pairs, the model can be trained completely from scratch with random initialization. We present several key techniques to make the sequence-to-sequence framework perform well for this challenging task. Tacotron achieves a 3.82 subjective 5-scale mean opinion score on US English, outperforming a production parametric system in terms of naturalness. In addition, since Tacotron generates speech at the frame level, it's substantially faster than sample-level autoregressive methods.
Revisiting Distributed Synchronous SGD
Mar 21, 2017

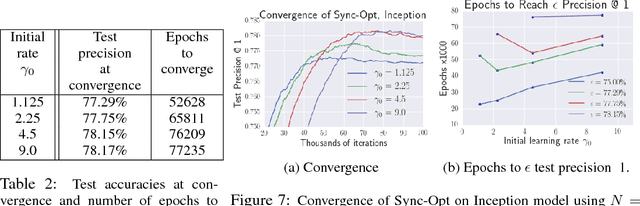
Distributed training of deep learning models on large-scale training data is typically conducted with asynchronous stochastic optimization to maximize the rate of updates, at the cost of additional noise introduced from asynchrony. In contrast, the synchronous approach is often thought to be impractical due to idle time wasted on waiting for straggling workers. We revisit these conventional beliefs in this paper, and examine the weaknesses of both approaches. We demonstrate that a third approach, synchronous optimization with backup workers, can avoid asynchronous noise while mitigating for the worst stragglers. Our approach is empirically validated and shown to converge faster and to better test accuracies.
Learning to Remember Rare Events
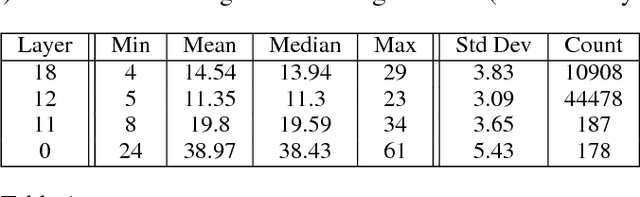
Mar 09, 2017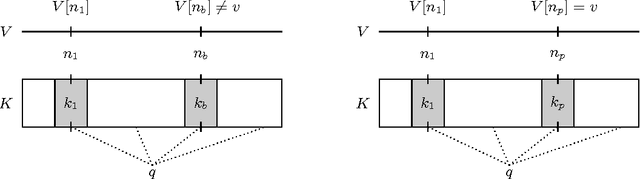

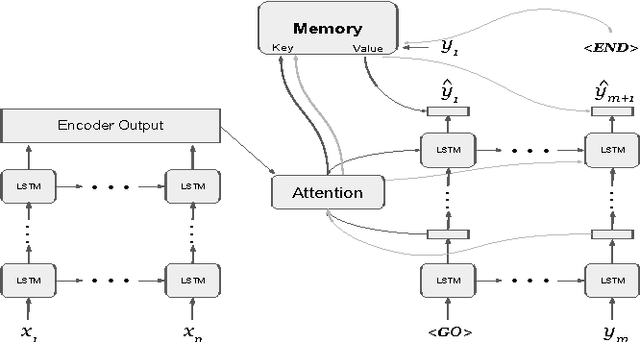

Despite recent advances, memory-augmented deep neural networks are still limited when it comes to life-long and one-shot learning, especially in remembering rare events. We present a large-scale life-long memory module for use in deep learning. The module exploits fast nearest-neighbor algorithms for efficiency and thus scales to large memory sizes. Except for the nearest-neighbor query, the module is fully differentiable and trained end-to-end with no extra supervision. It operates in a life-long manner, i.e., without the need to reset it during training. Our memory module can be easily added to any part of a supervised neural network. To show its versatility we add it to a number of networks, from simple convolutional ones tested on image classification to deep sequence-to-sequence and recurrent-convolutional models. In all cases, the enhanced network gains the ability to remember and do life-long one-shot learning. Our module remembers training examples shown many thousands of steps in the past and it can successfully generalize from them. We set new state-of-the-art for one-shot learning on the Omniglot dataset and demonstrate, for the first time, life-long one-shot learning in recurrent neural networks on a large-scale machine translation task.
Can Active Memory Replace Attention?
Mar 07, 2017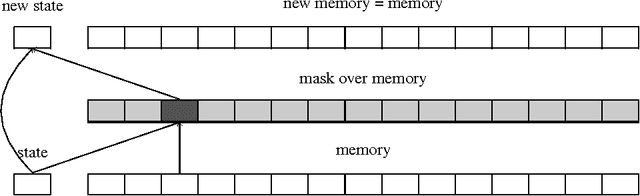
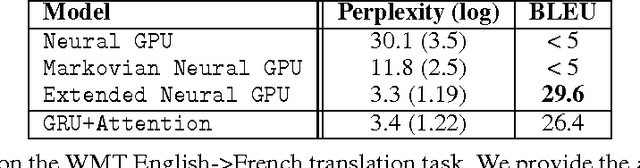

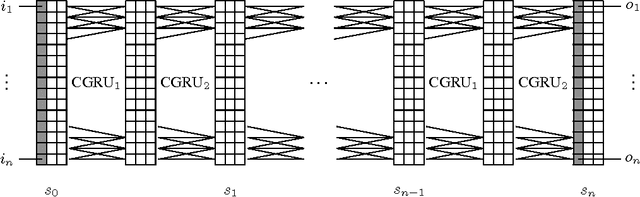
Several mechanisms to focus attention of a neural network on selected parts of its input or memory have been used successfully in deep learning models in recent years. Attention has improved image classification, image captioning, speech recognition, generative models, and learning algorithmic tasks, but it had probably the largest impact on neural machine translation. Recently, similar improvements have been obtained using alternative mechanisms that do not focus on a single part of a memory but operate on all of it in parallel, in a uniform way. Such mechanism, which we call active memory, improved over attention in algorithmic tasks, image processing, and in generative modelling. So far, however, active memory has not improved over attention for most natural language processing tasks, in particular for machine translation. We analyze this shortcoming in this paper and propose an extended model of active memory that matches existing attention models on neural machine translation and generalizes better to longer sentences. We investigate this model and explain why previous active memory models did not succeed. Finally, we discuss when active memory brings most benefits and where attention can be a better choice.
Density estimation using Real NVP
Feb 27, 2017
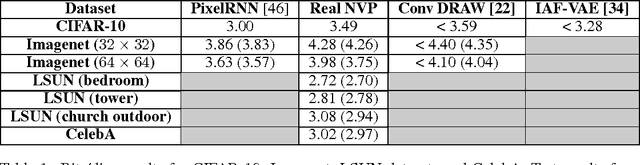


Unsupervised learning of probabilistic models is a central yet challenging problem in machine learning. Specifically, designing models with tractable learning, sampling, inference and evaluation is crucial in solving this task. We extend the space of such models using real-valued non-volume preserving (real NVP) transformations, a set of powerful invertible and learnable transformations, resulting in an unsupervised learning algorithm with exact log-likelihood computation, exact sampling, exact inference of latent variables, and an interpretable latent space. We demonstrate its ability to model natural images on four datasets through sampling, log-likelihood evaluation and latent variable manipulations.
Understanding deep learning requires rethinking generalization
Feb 26, 2017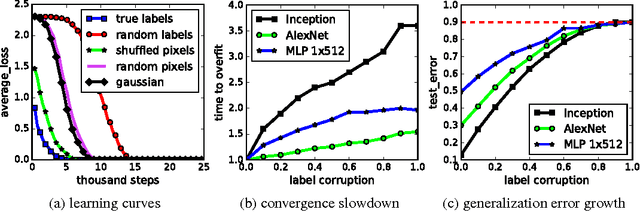
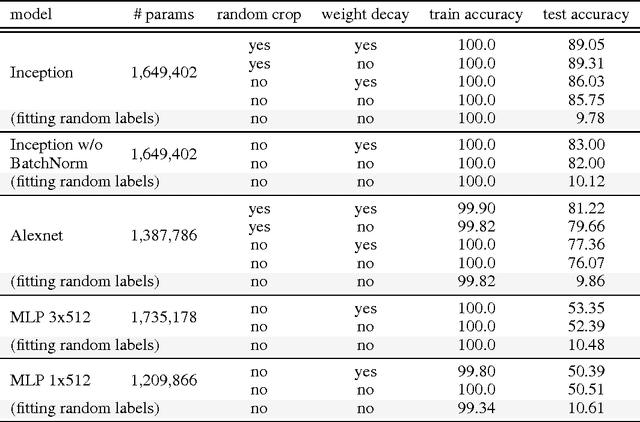
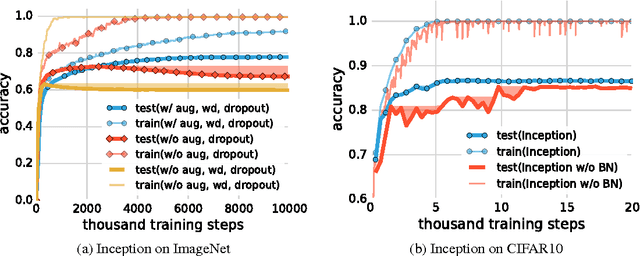
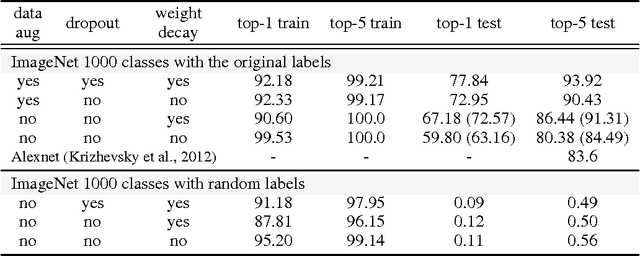
Despite their massive size, successful deep artificial neural networks can exhibit a remarkably small difference between training and test performance. Conventional wisdom attributes small generalization error either to properties of the model family, or to the regularization techniques used during training. Through extensive systematic experiments, we show how these traditional approaches fail to explain why large neural networks generalize well in practice. Specifically, our experiments establish that state-of-the-art convolutional networks for image classification trained with stochastic gradient methods easily fit a random labeling of the training data. This phenomenon is qualitatively unaffected by explicit regularization, and occurs even if we replace the true images by completely unstructured random noise. We corroborate these experimental findings with a theoretical construction showing that simple depth two neural networks already have perfect finite sample expressivity as soon as the number of parameters exceeds the number of data points as it usually does in practice. We interpret our experimental findings by comparison with traditional models.