 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dexterous In-Hand Manipulation
Jan 18, 2019
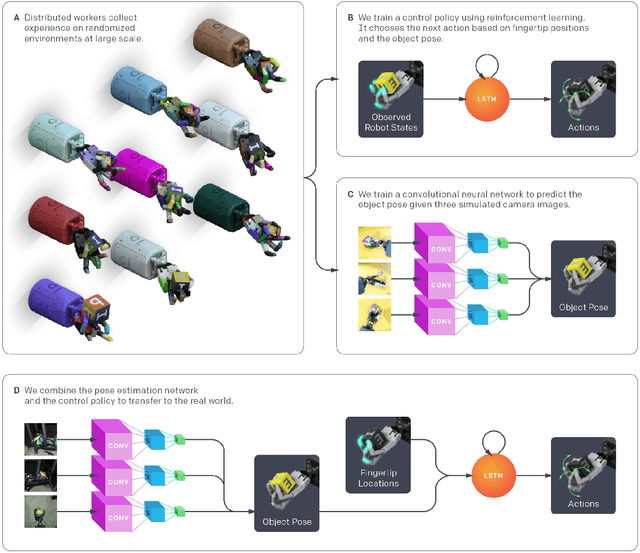
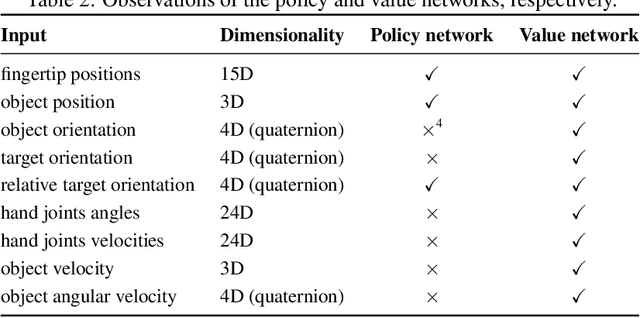

We use reinforcement learning (RL) to learn dexterous in-hand manipulation policies which can perform vision-based object reorientation on a physical Shadow Dexterous Hand. The training is performed in a simulated environment in which we randomize many of the physical properties of the system like friction coefficients and an object's appearance. Our policies transfer to the physical robot despite being trained entirely in simulation. Our method does not rely on any human demonstrations, but many behaviors found in human manipulation emerge naturally, including finger gaiting, multi-finger coordination, and the controlled use of gravity. Our results were obtained using the same distributed RL system that was used to train OpenAI Five. We also include a video of our results: https://youtu.be/jwSbzNHGflM
Learning to Generate Reviews and Discovering Sentiment
Apr 06, 2017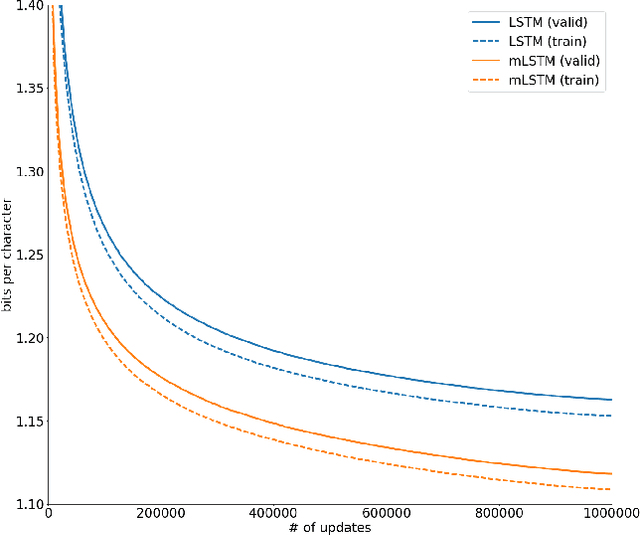
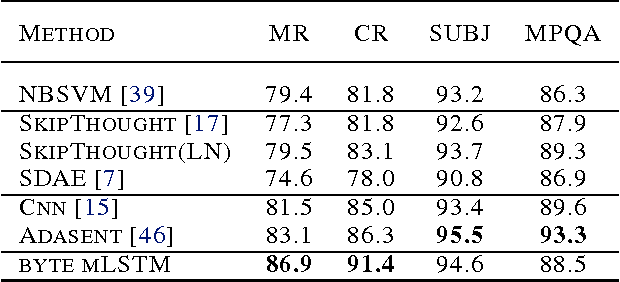
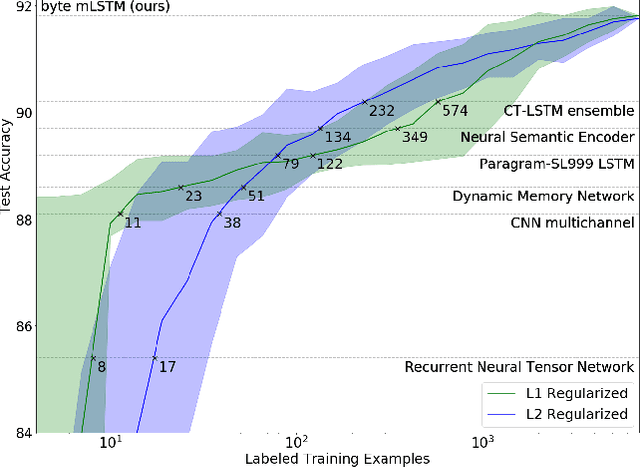

We explore the properties of byte-level recurrent language models. When given sufficient amounts of capacity, training data, and compute time, the representations learned by these models include disentangled features corresponding to high-level concepts. Specifically, we find a single unit which performs sentiment analysis. These representations, learned in an unsupervised manner, achieve state of the art on the binary subset of the Stanford Sentiment Treebank. They are also very data efficient. When using only a handful of labeled examples, our approach matches the performance of strong baselines trained on full datasets. We also demonstrate the sentiment unit has a direct influence on the generative process of the model. Simply fixing its value to be positive or negative generates samples with the corresponding positive or negative sentiment.
Revisiting Distributed Synchronous SGD
Mar 21, 2017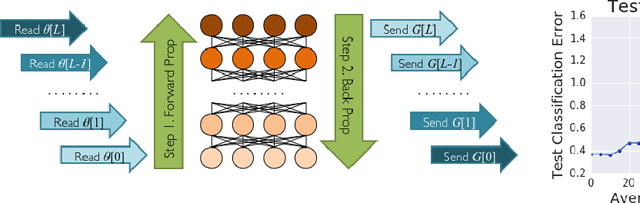
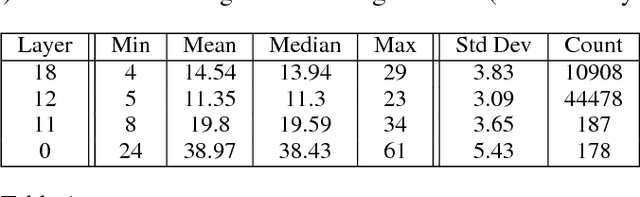

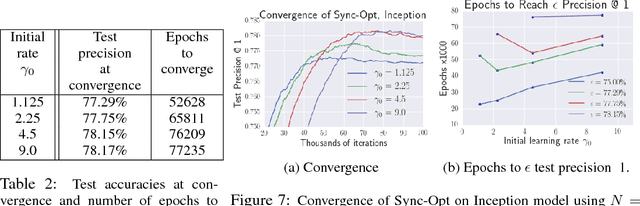
Distributed training of deep learning models on large-scale training data is typically conducted with asynchronous stochastic optimization to maximize the rate of updates, at the cost of additional noise introduced from asynchrony. In contrast, the synchronous approach is often thought to be impractical due to idle time wasted on waiting for straggling workers. We revisit these conventional beliefs in this paper, and examine the weaknesses of both approaches. We demonstrate that a third approach, synchronous optimization with backup workers, can avoid asynchronous noise while mitigating for the worst stragglers. Our approach is empirically validated and shown to converge faster and to better test accuracies.
Improving Variational Inference with Inverse Autoregressive Flow
Jan 30, 2017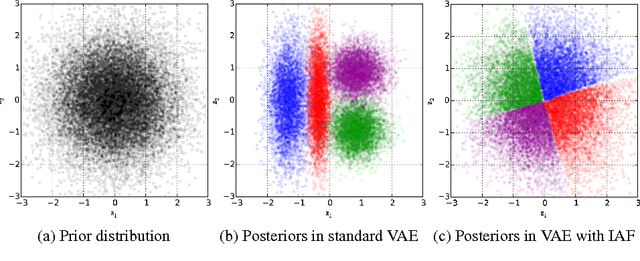
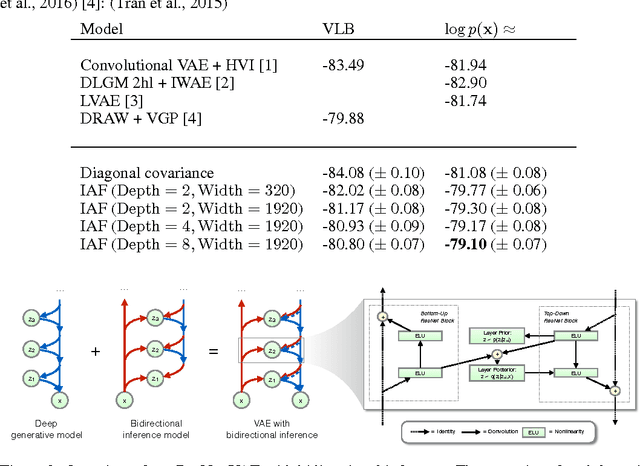
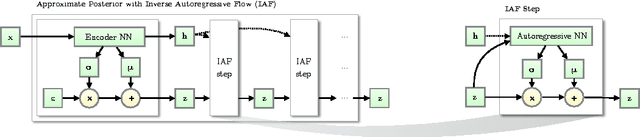
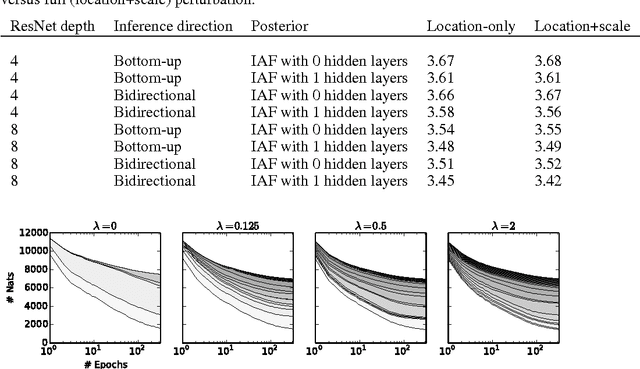
The framework of normalizing flows provides a general strategy for flexible variational inference of posteriors over latent variables. We propose a new type of normalizing flow, inverse autoregressive flow (IAF), that, in contrast to earlier published flows, scales well to high-dimensional latent spaces. The proposed flow consists of a chain of invertible transformations, where each transformation is based on an autoregressive neural network. In experiments, we show that IAF significantly improves upon diagonal Gaussian approximate posteriors. In addition, we demonstrate that a novel type of variational autoencoder, coupled with IAF, is competitive with neural autoregressive models in terms of attained log-likelihood on natural images, while allowing significantly faster synthesis.
LFADS - Latent Factor Analysis via Dynamical Systems
Aug 22, 2016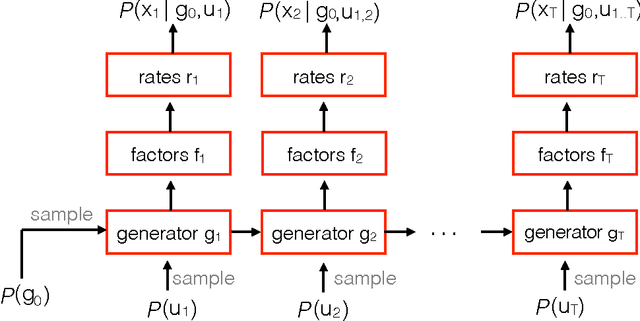
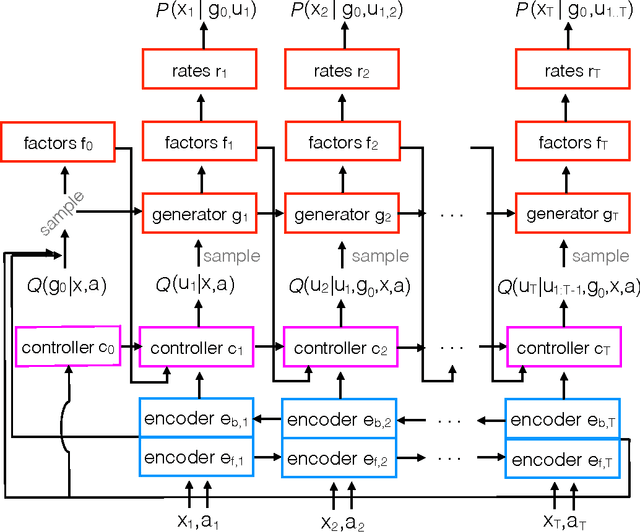

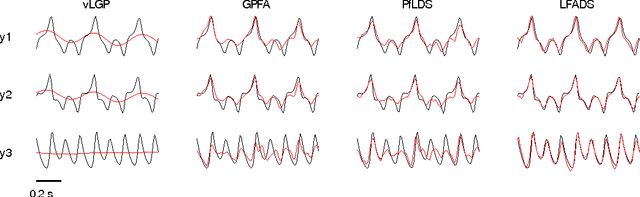
Neuroscience is experiencing a data revolution in which many hundreds or thousands of neurons are recorded simultaneously. Currently, there is little consensus on how such data should be analyzed. Here we introduce LFADS (Latent Factor Analysis via Dynamical Systems), a method to infer latent dynamics from simultaneously recorded, single-trial, high-dimensional neural spiking data. LFADS is a sequential model based on a variational auto-encoder. By making a dynamical systems hypothesis regarding the generation of the observed data, LFADS reduces observed spiking to a set of low-dimensional temporal factors, per-trial initial conditions, and inferred inputs. We compare LFADS to existing methods on synthetic data and show that it significantly out-performs them in inferring neural firing rates and latent dynamics.
Generating Sentences from a Continuous Space
May 12, 2016
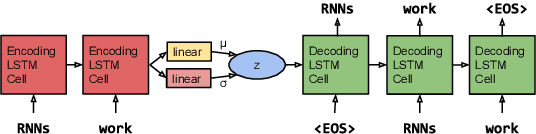
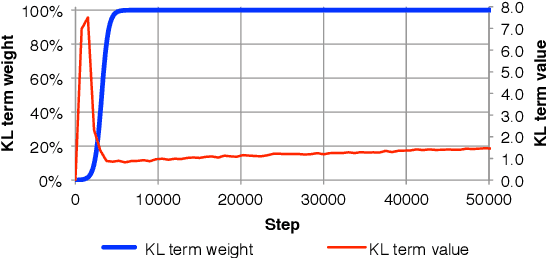

The standard recurrent neural network language model (RNNLM) generates sentences one word at a time and does not work from an explicit global sentence representation. In this work, we introduce and study an RNN-based variational autoencoder generative model that incorporates distributed latent representations of entire sentences. This factorization allows it to explicitly model holistic properties of sentences such as style, topic, and high-level syntactic features. Samples from the prior over these sentence representations remarkably produce diverse and well-formed sentences through simple deterministic decoding. By examining paths through this latent space, we are able to generate coherent novel sentences that interpolate between known sentences. We present techniques for solving the difficult learning problem presented by this model, demonstrate its effectiveness in imputing missing words, explore many interesting properties of the model's latent sentence space, and present negative results on the use of the model in language modeling.
* First two authors contributed equally. Work was done when all authors were at Google, Inc
TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
Mar 16, 2016

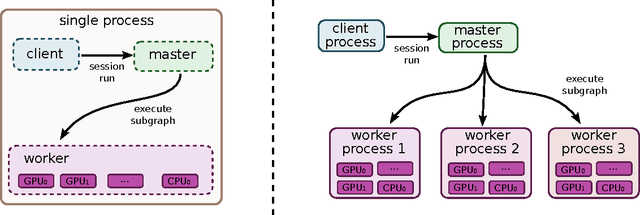
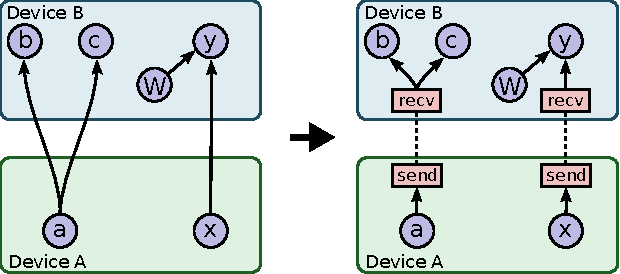
TensorFlow is an interface for expressing machine learning algorithms, and an implementation for executing such algorithms. A computation expressed using TensorFlow can be executed with little or no change on a wide variety of heterogeneous systems, ranging from mobile devices such as phones and tablets up to large-scale distributed systems of hundreds of machines and thousands of computational devices such as GPU cards. The system is flexible and can be used to express a wide variety of algorithms, including training and inference algorithms for deep neural network models, and it has been used for conducting research and for deploying machine learning systems into production across more than a dozen areas of computer science and other fields, including speech recognition, computer vision, robotics, information retrieval, natural language processing, geographic information extraction, and computational drug discovery. This paper describes the TensorFlow interface and an implementation of that interface that we have built at Google. The TensorFlow API and a reference implementation were released as an open-source package under the Apache 2.0 license in November, 2015 and are available at www.tensorflow.org.
Exploring the Limits of Language Modeling
Feb 11, 2016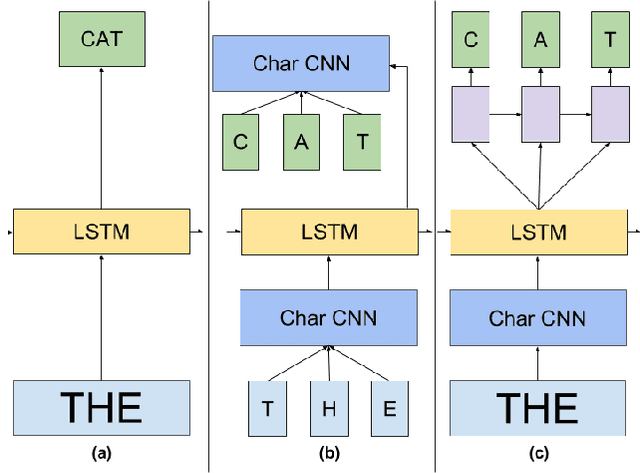
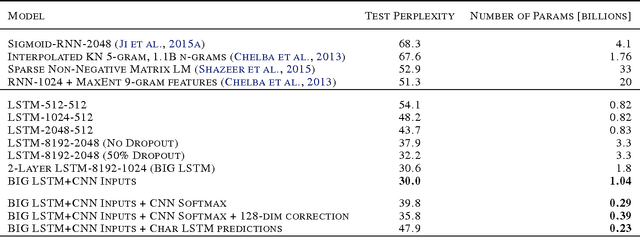
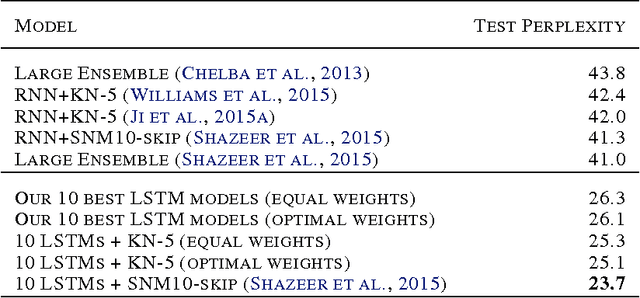
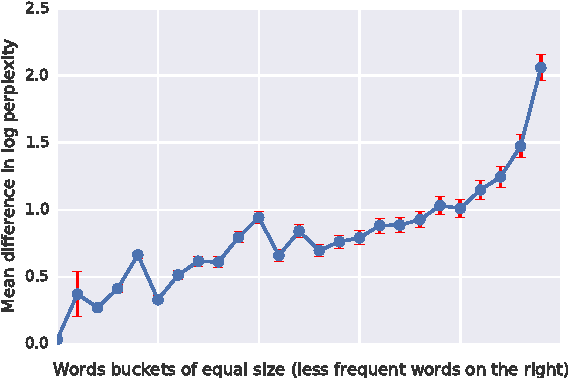
In this work we explore recent advances in Recurrent Neural Networks for large scale Language Modeling, a task central to language understanding. We extend current models to deal with two key challenges present in this task: corpora and vocabulary sizes, and complex, long term structure of language. We perform an exhaustive study on techniques such as character Convolutional Neural Networks or Long-Short Term Memory, on the One Billion Word Benchmark. Our best single model significantly improves state-of-the-art perplexity from 51.3 down to 30.0 (whilst reducing the number of parameters by a factor of 20), while an ensemble of models sets a new record by improving perplexity from 41.0 down to 23.7. We also release these models for the NLP and ML community to study and improve upon.
Towards Principled Unsupervised Learning
Dec 03, 2015
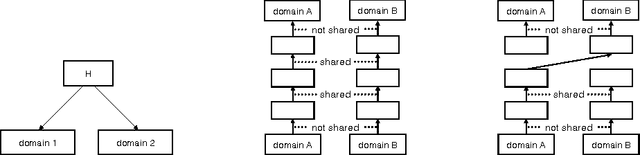

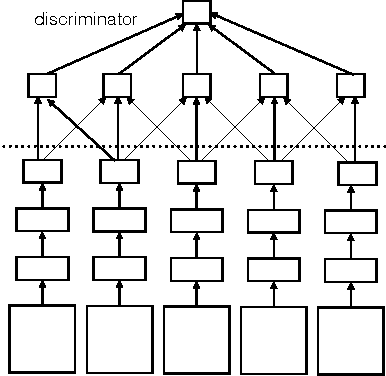
General unsupervised learning is a long-standing conceptual problem in machine learning. Supervised learning is successful because it can be solved by the minimization of the training error cost function. Unsupervised learning is not as successful, because the unsupervised objective may be unrelated to the supervised task of interest. For an example, density modelling and reconstruction have often been used for unsupervised learning, but they did not produced the sought-after performance gains, because they have no knowledge of the supervised tasks. In this paper, we present an unsupervised cost function which we name the Output Distribution Matching (ODM) cost, which measures a divergence between the distribution of predictions and distributions of labels. The ODM cost is appealing because it is consistent with the supervised cost in the following sense: a perfect supervised classifier is also perfect according to the ODM cost. Therefore, by aggressively optimizing the ODM cost, we are almost guaranteed to improve our supervised performance whenever the space of possible predictions is exponentially large. We demonstrate that the ODM cost works well on number of small and semi-artificial datasets using no (or almost no) labelled training cases. Finally, we show that the ODM cost can be used for one-shot domain adaptation, which allows the model to classify inputs that differ from the input distribution in significant ways without the need for prior exposure to the new domain.
Fast optimization of Multithreshold Entropy Linear Classifier
Apr 18, 2015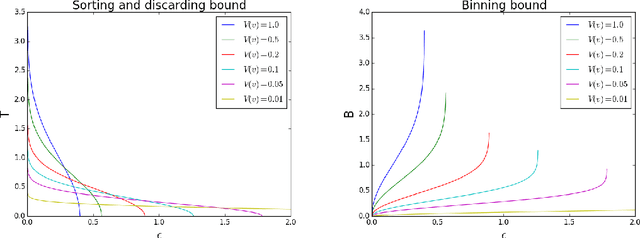
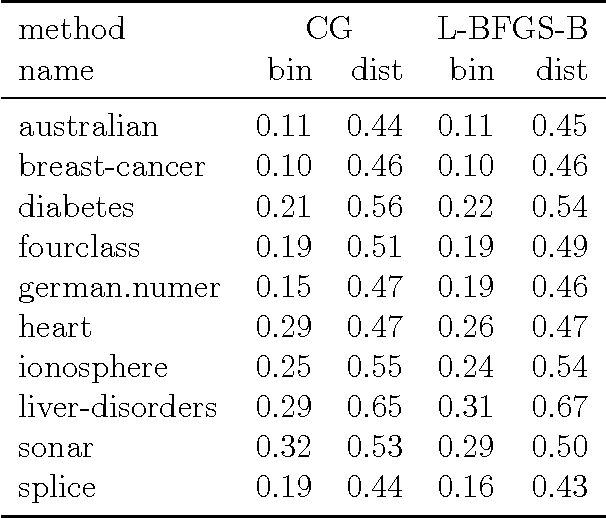
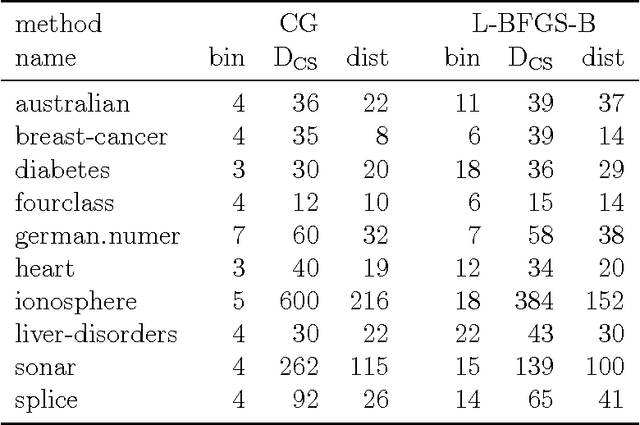
Multithreshold Entropy Linear Classifier (MELC) is a density based model which searches for a linear projection maximizing the Cauchy-Schwarz Divergence of dataset kernel density estimation. Despite its good empirical results, one of its drawbacks is the optimization speed. In this paper we analyze how one can speed it up through solving an approximate problem. We analyze two methods, both similar to the approximate solutions of the Kernel Density Estimation querying and provide adaptive schemes for selecting a crucial parameters based on user-specified acceptable error. Furthermore we show how one can exploit well known conjugate gradients and L-BFGS optimizers despite the fact that the original optimization problem should be solved on the sphere. All above methods and modifications are tested on 10 real life datasets from UCI repository to confirm their practical usability.