 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEO-Bench-2: From Performance to Capability, Rethinking Evaluation in Geospatial AI
Nov 19, 2025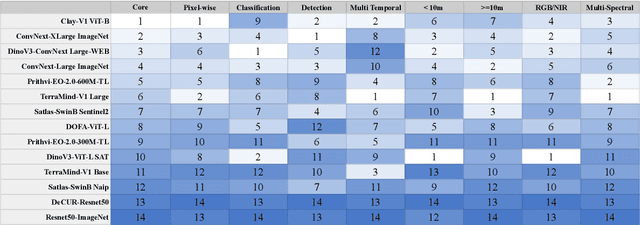


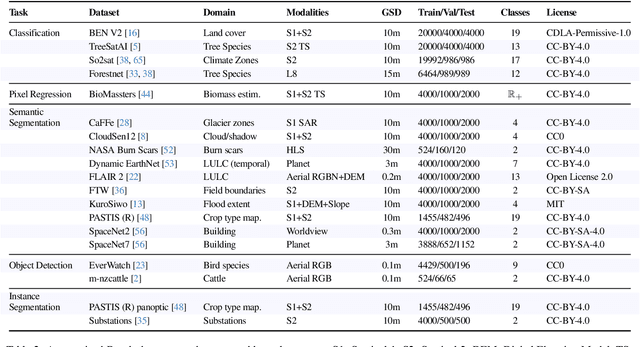
Geospatial Foundation Models (GeoFMs) are transforming Earth Observation (EO), but evaluation lacks standardized protocols. GEO-Bench-2 addresses this with a comprehensive framework spanning classification, segmentation, regression, object detection, and instance segmentation across 19 permissively-licensed datasets. We introduce ''capability'' groups to rank models on datasets that share common characteristics (e.g., resolution, bands, temporality). This enables users to identify which models excel in each capability and determine which areas need improvement in future work. To support both fair comparison and methodological innovation, we define a prescriptive yet flexible evaluation protocol. This not only ensures consistency in benchmarking but also facilitates research into model adaptation strategies, a key and open challenge in advancing GeoFMs for downstream tasks. Our experiments show that no single model dominates across all tasks, confirming the specificity of the choices made during architecture design and pretraining. While models pretrained on natural images (ConvNext ImageNet, DINO V3) excel on high-resolution tasks, EO-specific models (TerraMind, Prithvi, and Clay) outperform them on multispectral applications such as agriculture and disaster response. These findings demonstrate that optimal model choice depends on task requirements, data modalities, and constraints. This shows that the goal of a single GeoFM model that performs well across all tasks remains open for future research. GEO-Bench-2 enables informed, reproducible GeoFM evaluation tailored to specific use cases. Code, data, and leaderboard for GEO-Bench-2 are publicly released under a permissive license.
RainDiff: End-to-end Precipitation Nowcasting Via Token-wise Attention Diffusion
Oct 16, 2025Precipitation nowcasting, predicting future radar echo sequences from current observations, is a critical yet challenging task due to the inherently chaotic and tightly coupled spatio-temporal dynamics of the atmosphere. While recent advances in diffusion-based models attempt to capture both large-scale motion and fine-grained stochastic variability, they often suffer from scalability issues: latent-space approaches require a separately trained autoencoder, adding complexity and limiting generalization, while pixel-space approaches are computationally intensive and often omit attention mechanisms, reducing their ability to model long-range spatio-temporal dependencies. To address these limitations, we propose a Token-wise Attention integrated into not only the U-Net diffusion model but also the spatio-temporal encoder that dynamically captures multi-scale spatial interactions and temporal evolution. Unlike prior approaches, our method natively integrates attention into the architecture without incurring the high resource cost typical of pixel-space diffusion, thereby eliminating the need for separate latent modules. Our extensive experiments and visual evaluations across diverse datasets demonstrate that the proposed method significantly outperforms state-of-the-art approaches, yielding superior local fidelity, generalization, and robustness in complex precipitation forecasting scenarios.
Dr.LLM: Dynamic Layer Routing in LLMs
Oct 14, 2025Large Language Models (LLMs) process every token through all layers of a transformer stack, causing wasted computation on simple queries and insufficient flexibility for harder ones that need deeper reasoning. Adaptive-depth methods can improve efficiency, but prior approaches rely on costly inference-time search, architectural changes, or large-scale retraining, and in practice often degrade accuracy despite efficiency gains. We introduce Dr.LLM, Dynamic routing of Layers for LLMs, a retrofittable framework that equips pretrained models with lightweight per-layer routers deciding to skip, execute, or repeat a block. Routers are trained with explicit supervision: using Monte Carlo Tree Search (MCTS), we derive high-quality layer configurations that preserve or improve accuracy under a compute budget. Our design, windowed pooling for stable routing, focal loss with class balancing, and bottleneck MLP routers, ensures robustness under class imbalance and long sequences. On ARC (logic) and DART (math), Dr.LLM improves accuracy by up to +3.4%p while saving 5 layers per example on average. Routers generalize to out-of-domain tasks (MMLU, GSM8k, AIME, TruthfulQA, SQuADv2, GPQA, PIQA, AGIEval) with only 0.85% accuracy drop while retaining efficiency, and outperform prior routing methods by up to +7.7%p. Overall, Dr.LLM shows that explicitly supervised routers retrofit frozen LLMs for budget-aware, accuracy-driven inference without altering base weights.
MATRIX: Multimodal Agent Tuning for Robust Tool-Use Reasoning
Oct 09, 2025Vision language models (VLMs) are increasingly deployed as controllers with access to external tools for complex reasoning and decision-making, yet their effectiveness remains limited by the scarcity of high-quality multimodal trajectories and the cost of manual annotation. We address this challenge with a vision-centric agent tuning framework that automatically synthesizes multimodal trajectories, generates step-wise preference pairs, and trains a VLM controller for robust tool-use reasoning. Our pipeline first constructs M-TRACE, a large-scale dataset of 28.5K multimodal tasks with 177K verified trajectories, enabling imitation-based trajectory tuning. Building on this, we develop MATRIX Agent, a controller finetuned on M-TRACE for step-wise tool reasoning. To achieve finer alignment, we further introduce Pref-X, a set of 11K automatically generated preference pairs, and optimize MATRIX on it via step-wise preference learning. Across three benchmarks, Agent-X, GTA, and GAIA, MATRIX consistently surpasses both open- and closed-source VLMs, demonstrating scalable and effective multimodal tool use. Our data and code is avaliable at https://github.com/mbzuai-oryx/MATRIX.
How Good are Foundation Models in Step-by-Step Embodied Reasoning?
Sep 18, 2025



Embodied agents operating in the physical world must make decisions that are not only effective but also safe, spatially coherent, and grounded in context. While recent advances in large multimodal models (LMMs) have shown promising capabilities in visual understanding and language generation, their ability to perform structured reasoning for real-world embodied tasks remains underexplored. In this work, we aim to understand how well foundation models can perform step-by-step reasoning in embodied environments. To this end, we propose the Foundation Model Embodied Reasoning (FoMER) benchmark, designed to evaluate the reasoning capabilities of LMMs in complex embodied decision-making scenarios. Our benchmark spans a diverse set of tasks that require agents to interpret multimodal observations, reason about physical constraints and safety, and generate valid next actions in natural language. We present (i) a large-scale, curated suite of embodied reasoning tasks, (ii) a novel evaluation framework that disentangles perceptual grounding from action reasoning, and (iii) empirical analysis of several leading LMMs under this setting. Our benchmark includes over 1.1k samples with detailed step-by-step reasoning across 10 tasks and 8 embodiments, covering three different robot types. Our results highlight both the potential and current limitations of LMMs in embodied reasoning, pointing towards key challenges and opportunities for future research in robot intelligence. Our data and code will be made publicly available.
Distributed Deep Learning with RIS Grouping for Accurate Cascaded Channel Estimation
Sep 17, 2025Reconfigurable Intelligent Surface (RIS) panels are envisioned as a key technology for sixth-generation (6G) wireless networks, providing a cost-effective means to enhance coverage and spectral efficiency. A critical challenge is the estimation of the cascaded base station (BS)-RIS-user channel, since the passive nature of RIS elements prevents direct channel acquisition, incurring prohibitive pilot overhead, computational complexity, and energy consumption. To address this, we propose a deep learning (DL)-based channel estimation framework that reduces pilot overhead by grouping RIS elements and reconstructing the cascaded channel from partial pilot observations. Furthermore, conventional DL models trained under single-user settings suffer from poor generalization across new user locations and propagation scenarios. We develop a distributed machine learning (DML) strategy in which the BS and users collaboratively train a shared neural network using diverse channel datasets collected across the network, thereby achieving robust generalization. Building on this foundation, we design a hierarchical DML neural architecture that first classifies propagation conditions and then employs scenario-specific feature extraction to further improve estimation accuracy. Simulation results confirm that the proposed framework substantially reduces pilot overhead and complexity while outperforming conventional methods and single-user models in channel estimation accuracy. These results demonstrate the practicality and effectiveness of the proposed approach for 6G RIS-assisted systems.
Promptception: How Sensitive Are Large Multimodal Models to Prompts?
Sep 04, 2025Despite the success of Large Multimodal Models (LMMs) in recent years, prompt design for LMMs in Multiple-Choice Question Answering (MCQA) remains poorly understood. We show that even minor variations in prompt phrasing and structure can lead to accuracy deviations of up to 15% for certain prompts and models. This variability poses a challenge for transparent and fair LMM evaluation, as models often report their best-case performance using carefully selected prompts. To address this, we introduce Promptception, a systematic framework for evaluating prompt sensitivity in LMMs. It consists of 61 prompt types, spanning 15 categories and 6 supercategories, each targeting specific aspects of prompt formulation, and is used to evaluate 10 LMMs ranging from lightweight open-source models to GPT-4o and Gemini 1.5 Pro, across 3 MCQA benchmarks: MMStar, MMMU-Pro, MVBench. Our findings reveal that proprietary models exhibit greater sensitivity to prompt phrasing, reflecting tighter alignment with instruction semantics, while open-source models are steadier but struggle with nuanced and complex phrasing. Based on this analysis, we propose Prompting Principles tailored to proprietary and open-source LMMs, enabling more robust and fair model evaluation.
Beyond Simple Edits: Composed Video Retrieval with Dense Modifications
Aug 19, 2025Composed video retrieval is a challenging task that strives to retrieve a target video based on a query video and a textual description detailing specific modifications. Standard retrieval frameworks typically struggle to handle the complexity of fine-grained compositional queries and variations in temporal understanding limiting their retrieval ability in the fine-grained setting. To address this issue, we introduce a novel dataset that captures both fine-grained and composed actions across diverse video segments, enabling more detailed compositional changes in retrieved video content. The proposed dataset, named Dense-WebVid-CoVR, consists of 1.6 million samples with dense modification text that is around seven times more than its existing counterpart. We further develop a new model that integrates visual and textual information through Cross-Attention (CA) fusion using grounded text encoder, enabling precise alignment between dense query modifications and target videos. The proposed model achieves state-of-the-art results surpassing existing methods on all metrics. Notably, it achieves 71.3\% Recall@1 in visual+text setting and outperforms the state-of-the-art by 3.4\%, highlighting its efficacy in terms of leveraging detailed video descriptions and dense modification texts. Our proposed dataset, code, and model are available at :https://github.com/OmkarThawakar/BSE-CoVR
Hierarchical Visual Prompt Learning for Continual Video Instance Segmentation
Aug 12, 2025
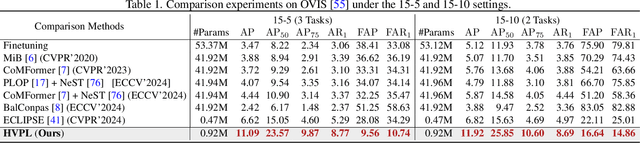


Video instance segmentation (VIS) has gained significant attention for its capability in tracking and segmenting object instances across video frames. However, most of the existing VIS approaches unrealistically assume that the categories of object instances remain fixed over time. Moreover, they experience catastrophic forgetting of old classes when required to continuously learn object instances belonging to new categories. To resolve these challenges, we develop a novel Hierarchical Visual Prompt Learning (HVPL) model that overcomes catastrophic forgetting of previous categories from both frame-level and video-level perspectives. Specifically, to mitigate forgetting at the frame level, we devise a task-specific frame prompt and an orthogonal gradient correction (OGC) module. The OGC module helps the frame prompt encode task-specific global instance information for new classes in each individual frame by projecting its gradients onto the orthogonal feature space of old classes. Furthermore, to address forgetting at the video level, we design a task-specific video prompt and a video context decoder. This decoder first embeds structural inter-class relationships across frames into the frame prompt features, and then propagates task-specific global video contexts from the frame prompt features to the video prompt. Through rigorous comparisons, our HVPL model proves to be more effective than baseline approaches. The code is available at https://github.com/JiahuaDong/HVPL.
AI in Agriculture: A Survey of Deep Learning Techniques for Crops, Fisheries and Livestock
Jul 29, 2025



Crops, fisheries and livestock form the backbone of global food production, essential to feed the ever-growing global population. However, these sectors face considerable challenges, including climate variability, resource limitations, and the need for sustainable management. Addressing these issues requires efficient, accurate, and scalable technological solutions, highlighting the importance of artificial intelligence (AI). This survey presents a systematic and thorough review of more than 200 research works covering conventional machine learning approaches, advanced deep learning techniques (e.g., vision transformers), and recent vision-language foundation models (e.g., CLIP) in the agriculture domain, focusing on diverse tasks such as crop disease detection, livestock health management, and aquatic species monitoring. We further cover major implementation challenges such as data variability and experimental aspects: datasets, performance evaluation metrics, and geographical focus. We finish the survey by discussing potential open research directions emphasizing the need for multimodal data integration, efficient edge-device deployment, and domain-adaptable AI models for diverse farming environments. Rapid growth of evolving developments in this field can be actively tracked on our project page: https://github.com/umair1221/AI-in-Agriculture