 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Visual Prompt Learning for Continual Video Instance Segmentation
Paper and Code

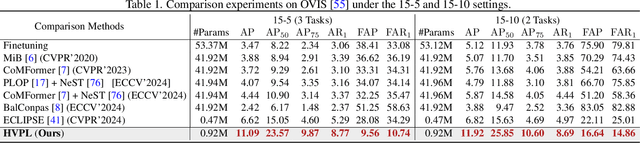


Video instance segmentation (VIS) has gained significant attention for its capability in tracking and segmenting object instances across video frames. However, most of the existing VIS approaches unrealistically assume that the categories of object instances remain fixed over time. Moreover, they experience catastrophic forgetting of old classes when required to continuously learn object instances belonging to new categories. To resolve these challenges, we develop a novel Hierarchical Visual Prompt Learning (HVPL) model that overcomes catastrophic forgetting of previous categories from both frame-level and video-level perspectives. Specifically, to mitigate forgetting at the frame level, we devise a task-specific frame prompt and an orthogonal gradient correction (OGC) module. The OGC module helps the frame prompt encode task-specific global instance information for new classes in each individual frame by projecting its gradients onto the orthogonal feature space of old classes. Furthermore, to address forgetting at the video level, we design a task-specific video prompt and a video context decoder. This decoder first embeds structural inter-class relationships across frames into the frame prompt features, and then propagates task-specific global video contexts from the frame prompt features to the video prompt. Through rigorous comparisons, our HVPL model proves to be more effective than baseline approaches. The code is available at https://github.com/JiahuaDong/HVPL.