 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMO: Frustratingly Easy Progressive Training of Extendable MoE
May 14, 2026Sparse Mixture-of-Experts (MoE) models offer a powerful way to scale model size without increasing compute, as per-token FLOPs depend only on k active experts rather than the total pool of E experts. Yet, this asymmetry creates an MoE efficiency paradox in practice: adding more experts balloons memory and communication costs, making actual training inefficient. We argue that this bottleneck arises in part because current MoE training allocates too many experts from the beginning, even though early-stage data may not fully utilize such capacity. Motivated by this, we propose EMO, a simple progressive training framework that treats MoE capacity as expandable memory and grows the expert pool over the course of training. EMO explicitly models sparsity in scaling law to derive stage-wise compute-optimal token budgets for progressive expansion. Empirical results show that EMO matches the performance of a fixed-expert setup in large-scale experiments while improving wall-clock efficiency. It offers a surprisingly simple yet effective path to scalable MoE training, preserving the benefits of large expert pools while reducing both training time and GPU cost.
Gecko: An Efficient Neural Architecture Inherently Processing Sequences with Arbitrary Lengths
Jan 10, 2026Designing a unified neural network to efficiently and inherently process sequential data with arbitrary lengths is a central and challenging problem in sequence modeling. The design choices in Transformer, including quadratic complexity and weak length extrapolation, have limited their ability to scale to long sequences. In this work, we propose Gecko, a neural architecture that inherits the design of Mega and Megalodon (exponential moving average with gated attention), and further introduces multiple technical components to improve its capability to capture long range dependencies, including timestep decay normalization, sliding chunk attention mechanism, and adaptive working memory. In a controlled pretraining comparison with Llama2 and Megalodon in the scale of 7 billion parameters and 2 trillion training tokens, Gecko achieves better efficiency and long-context scalability. Gecko reaches a training loss of 1.68, significantly outperforming Llama2-7B (1.75) and Megalodon-7B (1.70), and landing close to Llama2-13B (1.67). Notably, without relying on any context-extension techniques, Gecko exhibits inherent long-context processing and retrieval capabilities, stably handling sequences of up to 4 million tokens and retrieving information from contexts up to $4\times$ longer than its attention window. Code: https://github.com/XuezheMax/gecko-llm
Progressive Compositionality In Text-to-Image Generative Models
Oct 22, 2024



Despite the impressive text-to-image (T2I) synthesis capabilities of diffusion models, they often struggle to understand compositional relationships between objects and attributes, especially in complex settings. Existing solutions have tackled these challenges by optimizing the cross-attention mechanism or learning from the caption pairs with minimal semantic changes. However, can we generate high-quality complex contrastive images that diffusion models can directly discriminate based on visual representations? In this work, we leverage large-language models (LLMs) to compose realistic, complex scenarios and harness Visual-Question Answering (VQA) systems alongside diffusion models to automatically curate a contrastive dataset, ConPair, consisting of 15k pairs of high-quality contrastive images. These pairs feature minimal visual discrepancies and cover a wide range of attribute categories, especially complex and natural scenarios. To learn effectively from these error cases, i.e., hard negative images, we propose EvoGen, a new multi-stage curriculum for contrastive learning of diffusion models. Through extensive experiments across a wide range of compositional scenarios, we showcase the effectiveness of our proposed framework on compositional T2I benchmarks.
Towards Chapter-to-Chapter Context-Aware Literary Translation via Large Language Models
Jul 12, 2024



Discourse phenomena in existing document-level translation datasets are sparse, which has been a fundamental obstacle in the development of context-aware machine translation models. Moreover, most existing document-level corpora and context-aware machine translation methods rely on an unrealistic assumption on sentence-level alignments. To mitigate these issues, we first curate a novel dataset of Chinese-English literature, which consists of 160 books with intricate discourse structures. Then, we propose a more pragmatic and challenging setting for context-aware translation, termed chapter-to-chapter (Ch2Ch) translation, and investigate the performance of commonly-used machine translation models under this setting. Furthermore, we introduce a potential approach of finetuning large language models (LLMs) within the domain of Ch2Ch literary translation, yielding impressive improvements over baselines. Through our comprehensive analysis, we unveil that literary translation under the Ch2Ch setting is challenging in nature, with respect to both model learning methods and translation decoding algorithms.
Light-weight Fine-tuning Method for Defending Adversarial Noise in Pre-trained Medical Vision-Language Models
Jul 02, 2024



Fine-tuning pre-trained Vision-Language Models (VLMs) has shown remarkable capabilities in medical image and textual depiction synergy. Nevertheless, many pre-training datasets are restricted by patient privacy concerns, potentially containing noise that can adversely affect downstream performance. Moreover, the growing reliance on multi-modal generation exacerbates this issue because of its susceptibility to adversarial attacks. To investigate how VLMs trained on adversarial noisy data perform on downstream medical tasks, we first craft noisy upstream datasets using multi-modal adversarial attacks. Through our comprehensive analysis, we unveil that moderate noise enhances model robustness and transferability, but increasing noise levels negatively impact downstream task performance. To mitigate this issue, we propose rectify adversarial noise (RAN) framework, a recipe designed to effectively defend adversarial attacks and rectify the influence of upstream noise during fine-tuning.
Challenges in Context-Aware Neural Machine Translation
May 23, 2023Context-aware neural machine translation involves leveraging information beyond sentence-level context to resolve inter-sentential discourse dependencies and improve document-level translation quality, and has given rise to a number of recent techniques. However, despite well-reasoned intuitions, most context-aware translation models show only modest improvements over sentence-level systems. In this work, we investigate several challenges that impede progress within this field, relating to discourse phenomena, context usage, model architectures, and document-level evaluation. To address these problems, we propose a more realistic setting for document-level translation, called paragraph-to-paragraph (para2para) translation, and collect a new dataset of Chinese-English novels to promote future research.
Domain Generalization under Conditional and Label Shifts via Variational Bayesian Inference
Jul 22, 2021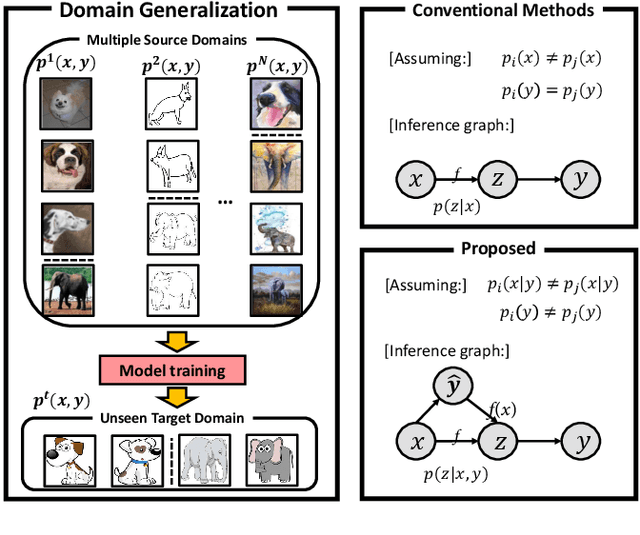
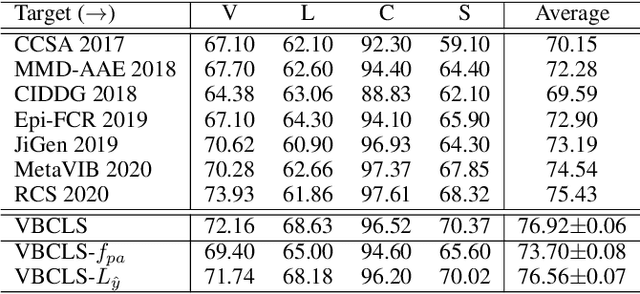
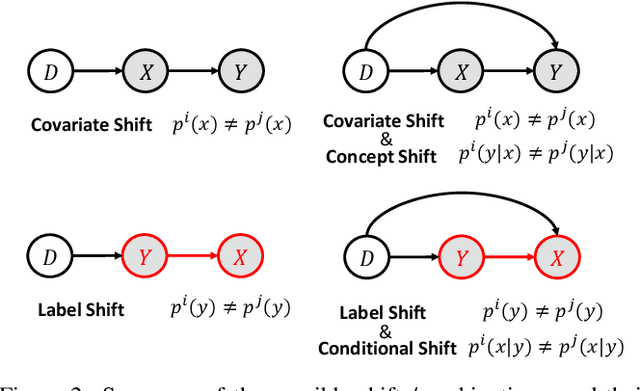
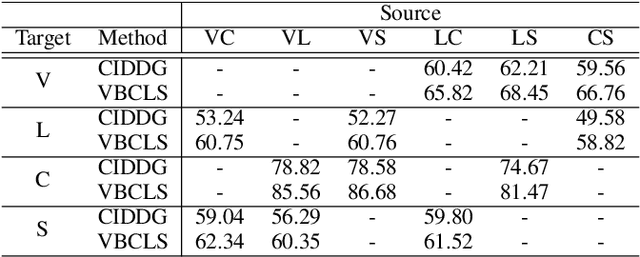
In this work, we propose a domain generalization (DG) approach to learn on several labeled source domains and transfer knowledge to a target domain that is inaccessible in training. Considering the inherent conditional and label shifts, we would expect the alignment of $p(x|y)$ and $p(y)$. However, the widely used domain invariant feature learning (IFL) methods relies on aligning the marginal concept shift w.r.t. $p(x)$, which rests on an unrealistic assumption that $p(y)$ is invariant across domains. We thereby propose a novel variational Bayesian inference framework to enforce the conditional distribution alignment w.r.t. $p(x|y)$ via the prior distribution matching in a latent space, which also takes the marginal label shift w.r.t. $p(y)$ into consideration with the posterior alignment. Extensive experiments on various benchmarks demonstrate that our framework is robust to the label shift and the cross-domain accuracy is significantly improved, thereby achieving superior performance over the conventional IFL counterparts.
Identity-aware Facial Expression Recognition in Compressed Video
Jan 07, 2021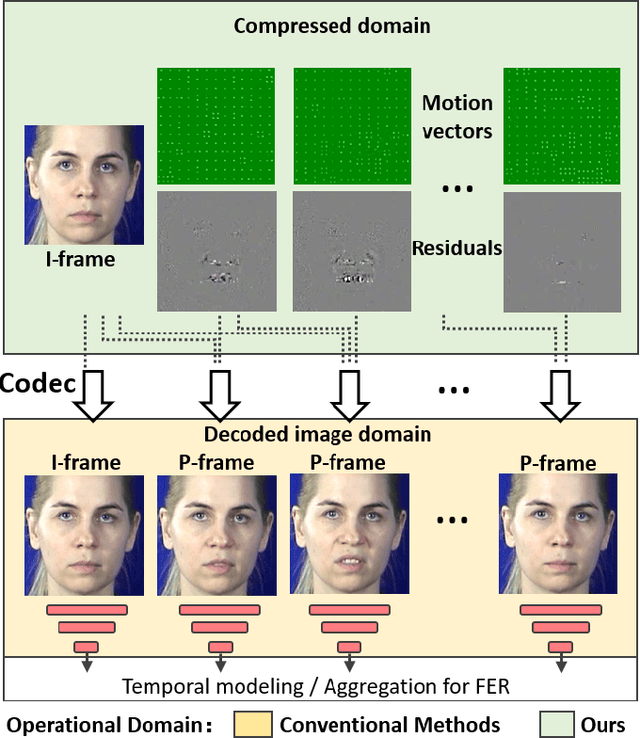
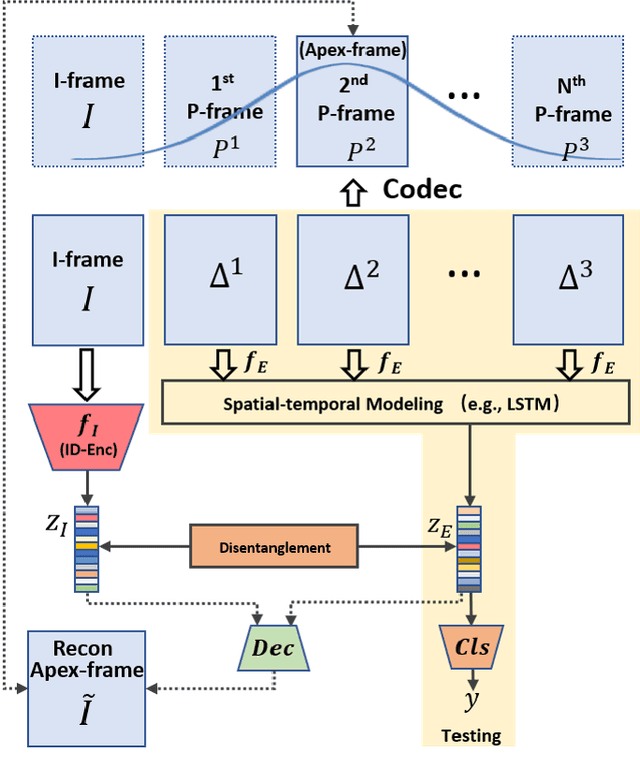
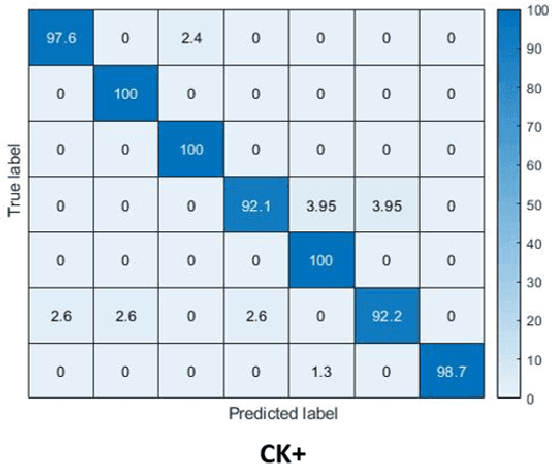

This paper targets to explore the inter-subject variations eliminated facial expression representation in the compressed video domain. Most of the previous methods process the RGB images of a sequence, while the off-the-shelf and valuable expression-related muscle movement already embedded in the compression format. In the up to two orders of magnitude compressed domain, we can explicitly infer the expression from the residual frames and possible to extract identity factors from the I frame with a pre-trained face recognition network. By enforcing the marginal independent of them, the expression feature is expected to be purer for the expression and be robust to identity shifts. We do not need the identity label or multiple expression samples from the same person for identity elimination. Moreover, when the apex frame is annotated in the dataset, the complementary constraint can be further added to regularize the feature-level game. In testing, only the compressed residual frames are required to achieve expression prediction. Our solution can achieve comparable or better performance than the recent decoded image based methods on the typical FER benchmarks with about 3$\times$ faster inference with compressed data.
Mutual Information Regularized Identity-aware Facial ExpressionRecognition in Compressed Video
Oct 20, 2020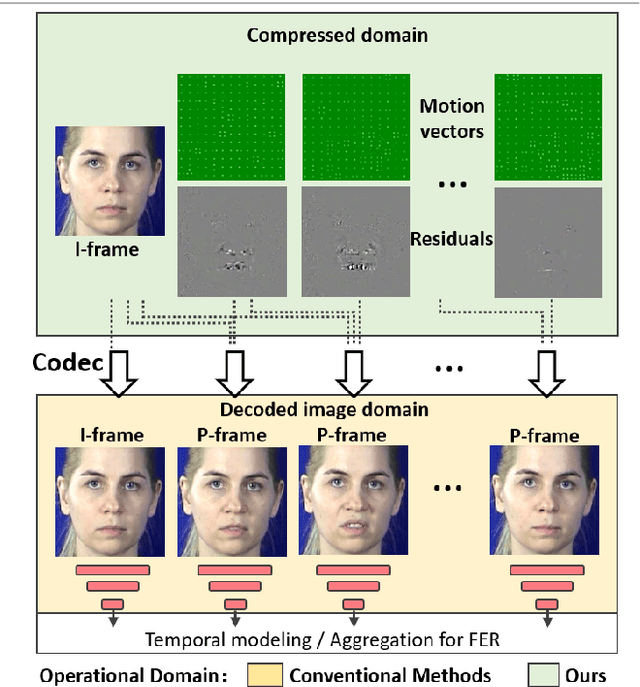
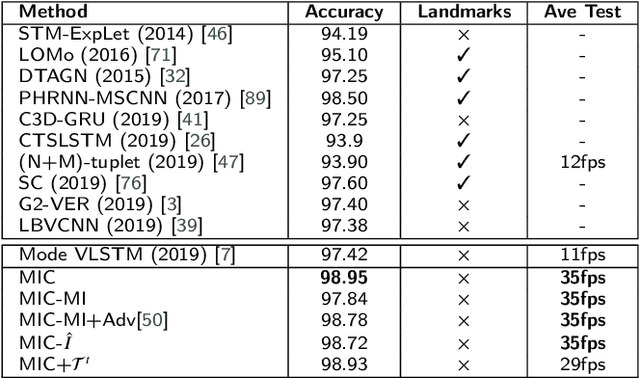
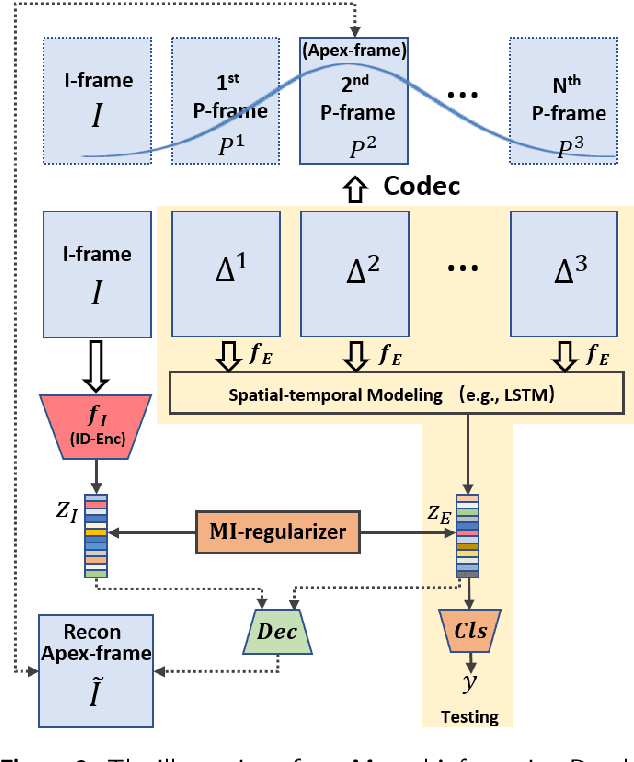
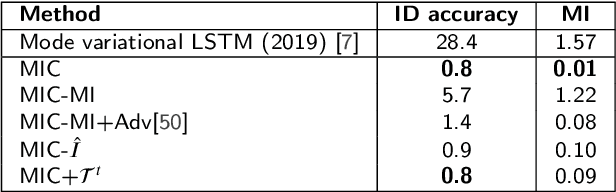
This paper targets to explore the inter-subject variations eliminated facial expression representation in the compressed video domain. Most of the previous methods process the RGB images of a sequence, while the off-the-shelf and valuable expression-related muscle movement already embedded in the compression format. In the up to two orders of magnitude compressed domain, we can explicitly infer the expression from the residual frames and possible to extract identity factors from the I frame with a pre-trained face recognition network. By enforcing the marginal independent of them, the expression feature is expected to be purer for the expression and be robust to identity shifts. Specifically, we propose a novel collaborative min-min game for mutual information (MI) minimization in latent space. We do not need the identity label or multiple expression samples from the same person for identity elimination. Moreover, when the apex frame is annotated in the dataset, the complementary constraint can be further added to regularize the feature-level game. In testing, only the compressed residual frames are required to achieve expression prediction. Our solution can achieve comparable or better performance than the recent decoded image-based methods on the typical FER benchmarks with about 3 times faster inference.