 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Energy-Based Models by Cooperative Diffusion Recovery Likelihood
Sep 12, 2023Training energy-based models (EBMs) with maximum likelihood estimation on high-dimensional data can be both challenging and time-consuming. As a result, there a noticeable gap in sample quality between EBMs and other generative frameworks like GANs and diffusion models. To close this gap, inspired by the recent efforts of learning EBMs by maximimizing diffusion recovery likelihood (DRL), we propose cooperative diffusion recovery likelihood (CDRL), an effective approach to tractably learn and sample from a series of EBMs defined on increasingly noisy versons of a dataset, paired with an initializer model for each EBM. At each noise level, the initializer model learns to amortize the sampling process of the EBM, and the two models are jointly estimated within a cooperative training framework. Samples from the initializer serve as starting points that are refined by a few sampling steps from the EBM. With the refined samples, the EBM is optimized by maximizing recovery likelihood, while the initializer is optimized by learning from the difference between the refined samples and the initial samples. We develop a new noise schedule and a variance reduction technique to further improve the sample quality. Combining these advances, we significantly boost the FID scores compared to existing EBM methods on CIFAR-10 and ImageNet 32x32, with a 2x speedup over DRL. In addition, we extend our method to compositional generation and image inpainting tasks, and showcase the compatibility of CDRL with classifier-free guidance for conditional generation, achieving similar trade-offs between sample quality and sample diversity as in diffusion models.
Understanding the Diffusion Objective as a Weighted Integral of ELBOs
Mar 01, 2023Diffusion models in the literature are optimized with various objectives that are special cases of a weighted loss, where the weighting function specifies the weight per noise level. Uniform weighting corresponds to maximizing the ELBO, a principled approximation of maximum likelihood. In current practice diffusion models are optimized with non-uniform weighting due to better results in terms of sample quality. In this work we expose a direct relationship between the weighted loss (with any weighting) and the ELBO objective. We show that the weighted loss can be written as a weighted integral of ELBOs, with one ELBO per noise level. If the weighting function is monotonic, then the weighted loss is a likelihood-based objective: it maximizes the ELBO under simple data augmentation, namely Gaussian noise perturbation. Our main contribution is a deeper theoretical understanding of the diffusion objective, but we also performed some experiments comparing monotonic with non-monotonic weightings, finding that monotonic weighting performs competitively with the best published results.
On Distillation of Guided Diffusion Models
Oct 06, 2022
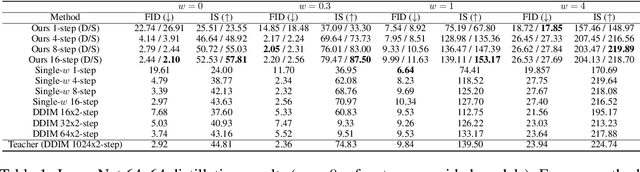
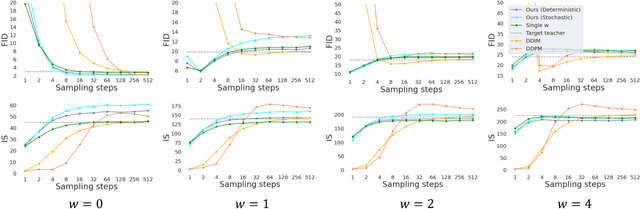
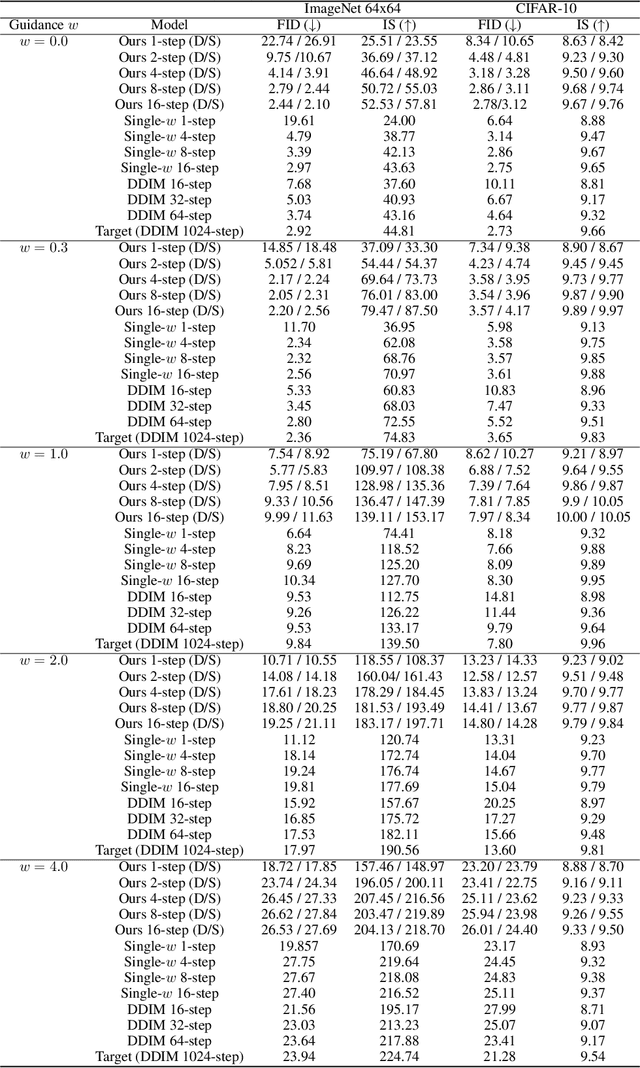
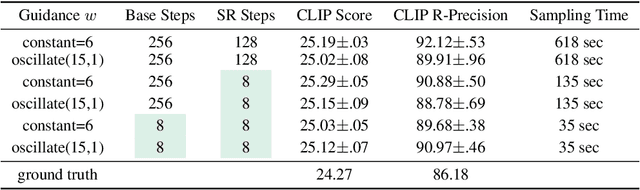
Classifier-free guided diffusion models have recently been shown to be highly effective at high-resolution image generation, and they have been widely used in large-scale diffusion frameworks including DALL-E 2, GLIDE and Imagen. However, a downside of classifier-free guided diffusion models is that they are computationally expensive at inference time since they require evaluating two diffusion models, a class-conditional model and an unconditional model, hundreds of times. To deal with this limitation, we propose an approach to distilling classifier-free guided diffusion models into models that are fast to sample from: Given a pre-trained classifier-free guided model, we first learn a single model to match the output of the combined conditional and unconditional models, and then progressively distill that model to a diffusion model that requires much fewer sampling steps. On ImageNet 64x64 and CIFAR-10, our approach is able to generate images visually comparable to that of the original model using as few as 4 sampling steps, achieving FID/IS scores comparable to that of the original model while being up to 256 times faster to sample from.
Conformal Isometry of Lie Group Representation in Recurrent Network of Grid Cells
Oct 06, 2022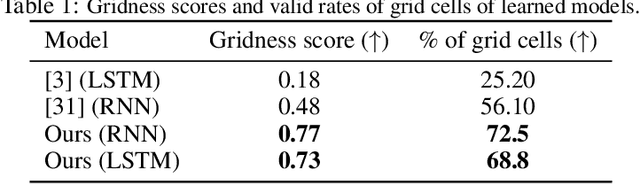

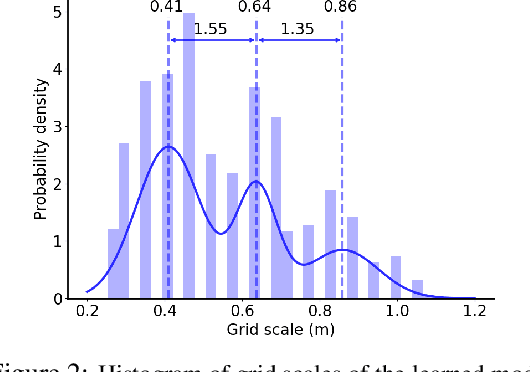
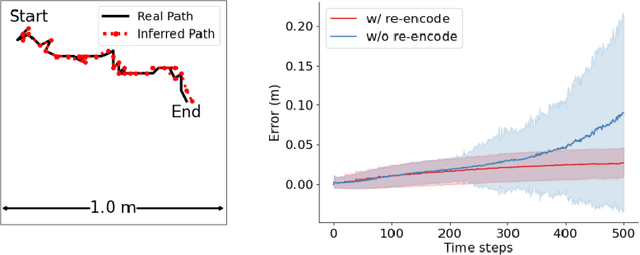
The activity of the grid cell population in the medial entorhinal cortex (MEC) of the brain forms a vector representation of the self-position of the animal. Recurrent neural networks have been developed to explain the properties of the grid cells by transforming the vector based on the input velocity, so that the grid cells can perform path integration. In this paper, we investigate the algebraic, geometric, and topological properties of grid cells using recurrent network models. Algebraically, we study the Lie group and Lie algebra of the recurrent transformation as a representation of self-motion. Geometrically, we study the conformal isometry of the Lie group representation of the recurrent network where the local displacement of the vector in the neural space is proportional to the local displacement of the agent in the 2D physical space. We then focus on a simple non-linear recurrent model that underlies the continuous attractor neural networks of grid cells. Our numerical experiments show that conformal isometry leads to hexagon periodic patterns of the response maps of grid cells and our model is capable of accurate path integration.
Imagen Video: High Definition Video Generation with Diffusion Models
Oct 05, 2022
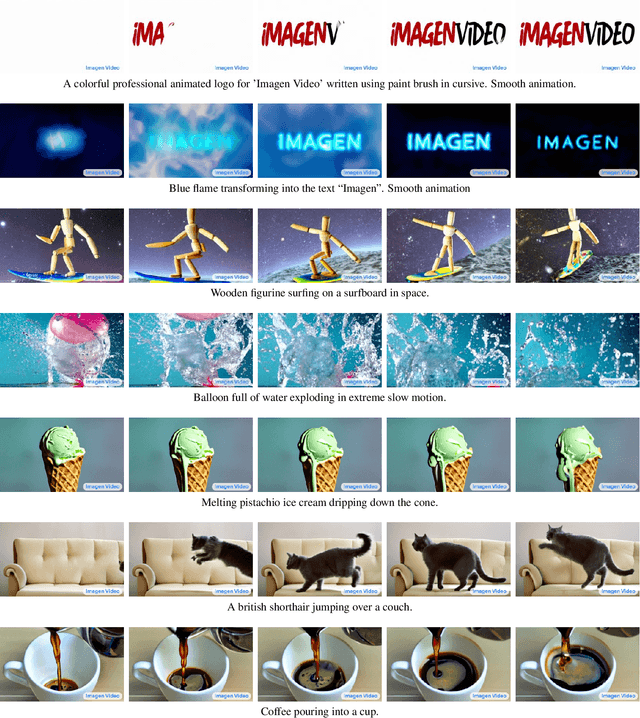

We present Imagen Video, a text-conditional video generation system based on a cascade of video diffusion models. Given a text prompt, Imagen Video generates high definition videos using a base video generation model and a sequence of interleaved spatial and temporal video super-resolution models. We describe how we scale up the system as a high definition text-to-video model including design decisions such as the choice of fully-convolutional temporal and spatial super-resolution models at certain resolutions, and the choice of the v-parameterization of diffusion models. In addition, we confirm and transfer findings from previous work on diffusion-based image generation to the video generation setting. Finally, we apply progressive distillation to our video models with classifier-free guidance for fast, high quality sampling. We find Imagen Video not only capable of generating videos of high fidelity, but also having a high degree of controllability and world knowledge, including the ability to generate diverse videos and text animations in various artistic styles and with 3D object understanding. See https://imagen.research.google/video/ for samples.
Latent Diffusion Energy-Based Model for Interpretable Text Modeling
Jun 14, 2022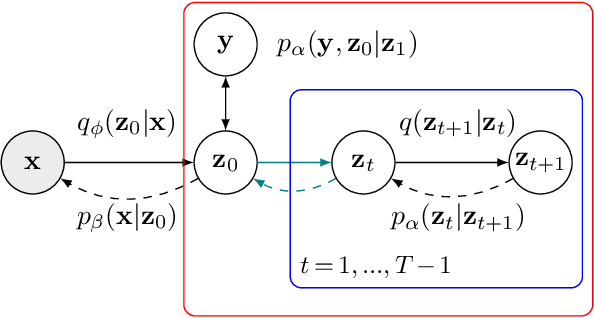
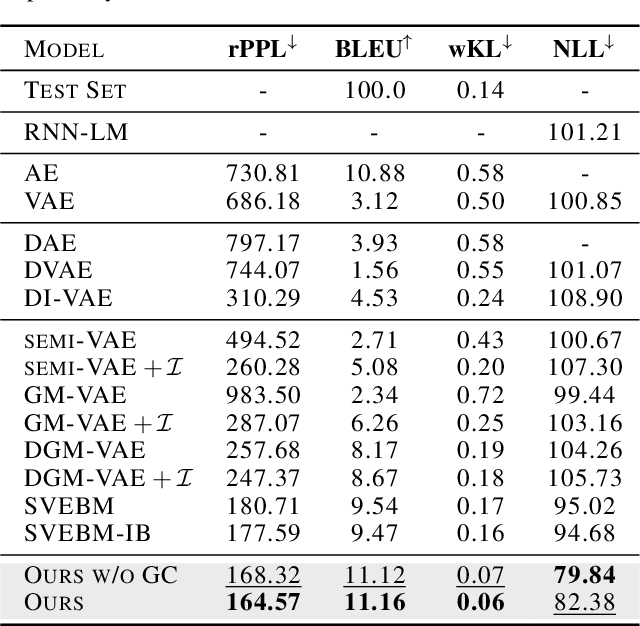
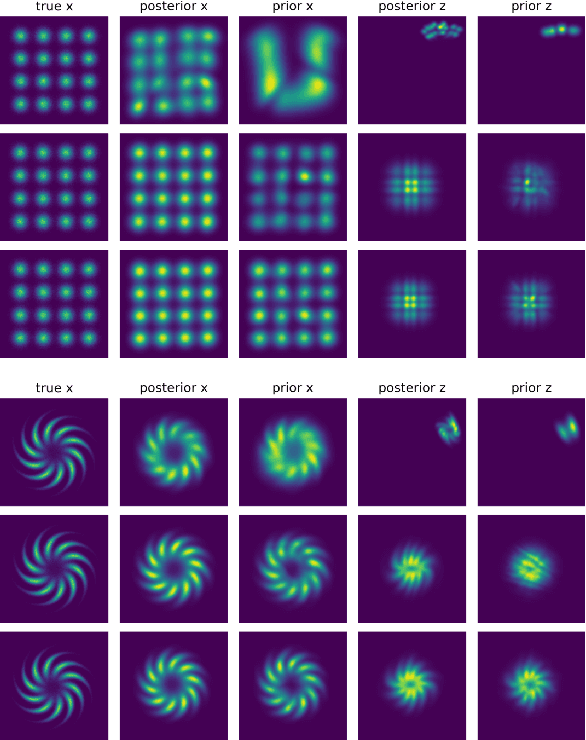

Latent space Energy-Based Models (EBMs), also known as energy-based priors, have drawn growing interests in generative modeling. Fueled by its flexibility in the formulation and strong modeling power of the latent space, recent works built upon it have made interesting attempts aiming at the interpretability of text modeling. However, latent space EBMs also inherit some flaws from EBMs in data space; the degenerate MCMC sampling quality in practice can lead to poor generation quality and instability in training, especially on data with complex latent structures. Inspired by the recent efforts that leverage diffusion recovery likelihood learning as a cure for the sampling issue, we introduce a novel symbiosis between the diffusion models and latent space EBMs in a variational learning framework, coined as the latent diffusion energy-based model. We develop a geometric clustering-based regularization jointly with the information bottleneck to further improve the quality of the learned latent space. Experiments on several challenging tasks demonstrate the superior performance of our model on interpretable text modeling over strong counterparts.
Learning Neural Representation of Camera Pose with Matrix Representation of Pose Shift via View Synthesis
Apr 15, 2021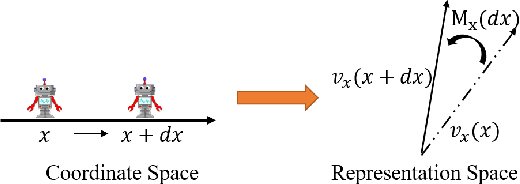
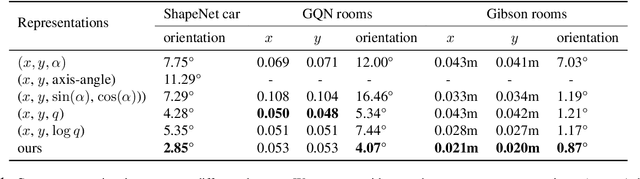
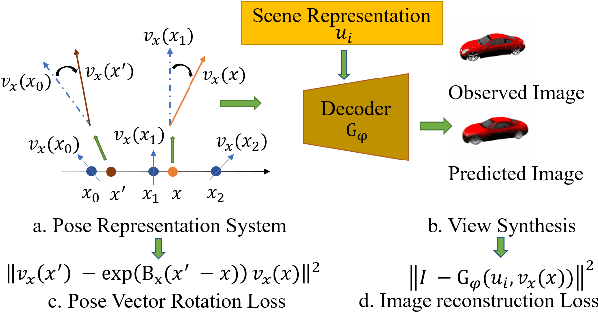
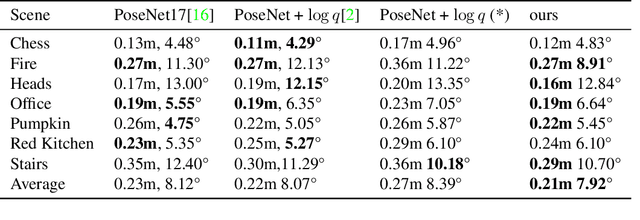
How to effectively represent camera pose is an essential problem in 3D computer vision, especially in tasks such as camera pose regression and novel view synthesis. Traditionally, 3D position of the camera is represented by Cartesian coordinate and the orientation is represented by Euler angle or quaternions. These representations are manually designed, which may not be the most effective representation for downstream tasks. In this work, we propose an approach to learn neural representations of camera poses and 3D scenes, coupled with neural representations of local camera movements. Specifically, the camera pose and 3D scene are represented as vectors and the local camera movement is represented as a matrix operating on the vector of the camera pose. We demonstrate that the camera movement can further be parametrized by a matrix Lie algebra that underlies a rotation system in the neural space. The vector representations are then concatenated and generate the posed 2D image through a decoder network. The model is learned from only posed 2D images and corresponding camera poses, without access to depths or shapes. We conduct extensive experiments on synthetic and real datasets. The results show that compared with other camera pose representations, our learned representation is more robust to noise in novel view synthesis and more effective in camera pose regression.
A Theory of Label Propagation for Subpopulation Shift
Feb 22, 2021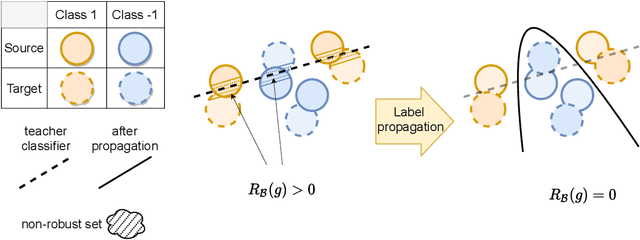
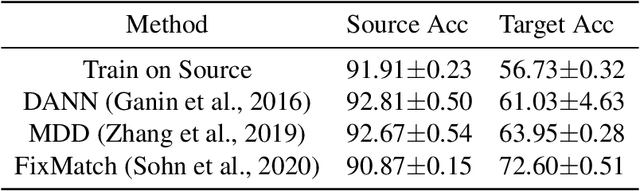
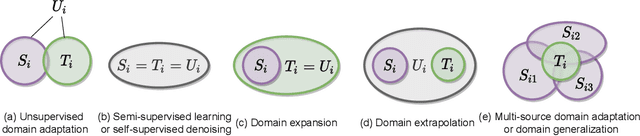

One of the central problems in machine learning is domain adaptation. Unlike past theoretical work, we consider a new model for subpopulation shift in the input or representation space. In this work, we propose a provably effective framework for domain adaptation based on label propagation. In our analysis, we use a simple but realistic ``expansion'' assumption, proposed in \citet{wei2021theoretical}. Using a teacher classifier trained on the source domain, our algorithm not only propagates to the target domain but also improves upon the teacher. By leveraging existing generalization bounds, we also obtain end-to-end finite-sample guarantees on the entire algorithm. In addition, we extend our theoretical framework to a more general setting of source-to-target transfer based on a third unlabeled dataset, which can be easily applied in various learning scenarios.
Generative VoxelNet: Learning Energy-Based Models for 3D Shape Synthesis and Analysis
Dec 25, 2020
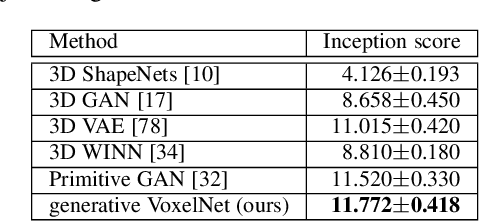

3D data that contains rich geometry information of objects and scenes is valuable for understanding 3D physical world. With the recent emergence of large-scale 3D datasets, it becomes increasingly crucial to have a powerful 3D generative model for 3D shape synthesis and analysis. This paper proposes a deep 3D energy-based model to represent volumetric shapes. The maximum likelihood training of the model follows an "analysis by synthesis" scheme. The benefits of the proposed model are six-fold: first, unlike GANs and VAEs, the model training does not rely on any auxiliary models; second, the model can synthesize realistic 3D shapes by Markov chain Monte Carlo (MCMC); third, the conditional model can be applied to 3D object recovery and super resolution; fourth, the model can serve as a building block in a multi-grid modeling and sampling framework for high resolution 3D shape synthesis; fifth, the model can be used to train a 3D generator via MCMC teaching; sixth, the unsupervisedly trained model provides a powerful feature extractor for 3D data, which is useful for 3D object classification. Experiments demonstrate that the proposed model can generate high-quality 3D shape patterns and can be useful for a wide variety of 3D shape analysis.
Learning Energy-Based Models by Diffusion Recovery Likelihood
Dec 15, 2020
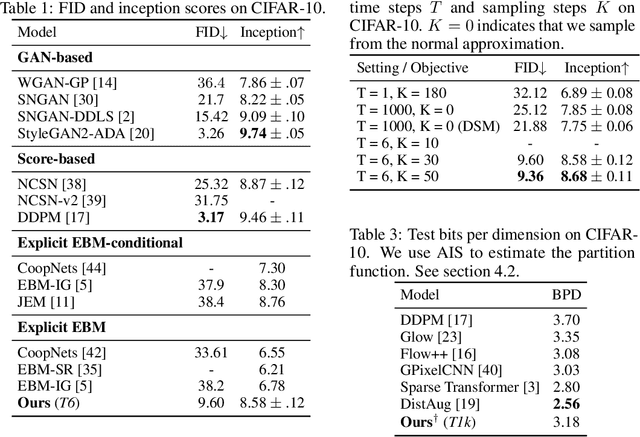
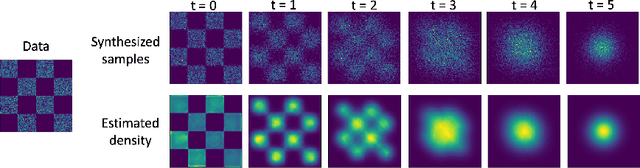

While energy-based models (EBMs) exhibit a number of desirable properties, training and sampling on high-dimensional datasets remains challenging. Inspired by recent progress on diffusion probabilistic models, we present a diffusion recovery likelihood method to tractably learn and sample from a sequence of EBMs trained on increasingly noisy versions of a dataset. Each EBM is trained by maximizing the recovery likelihood: the conditional probability of the data at a certain noise level given their noisy versions at a higher noise level. The recovery likelihood objective is more tractable than the marginal likelihood objective, since it only requires MCMC sampling from a relatively concentrated conditional distribution. Moreover, we show that this estimation method is theoretically consistent: it learns the correct conditional and marginal distributions at each noise level, given sufficient data. After training, synthesized images can be generated efficiently by a sampling process that initializes from a spherical Gaussian distribution and progressively samples the conditional distributions at decreasingly lower noise levels. Our method generates high fidelity samples on various image datasets. On unconditional CIFAR-10 our method achieves FID 9.60 and inception score 8.58, superior to the majority of GANs. Moreover, we demonstrate that unlike previous work on EBMs, our long-run MCMC samples from the conditional distributions do not diverge and still represent realistic images, allowing us to accurately estimate the normalized density of data even for high-dimensional datasets.