 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding the Growth: Difficulty-Controllable Question Generation through Step-by-Step Rewriting
May 25, 2021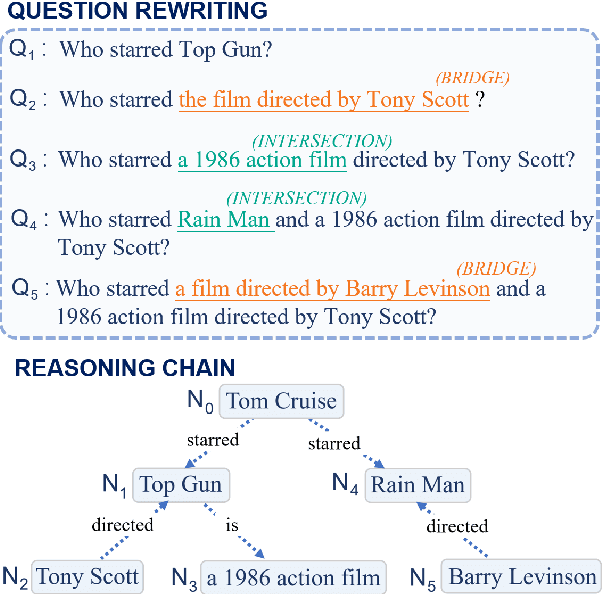
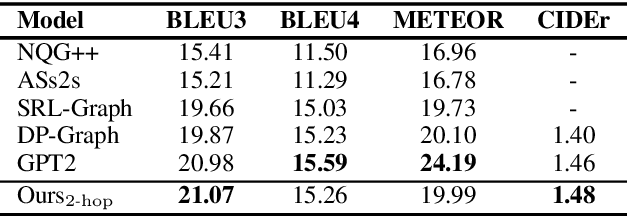
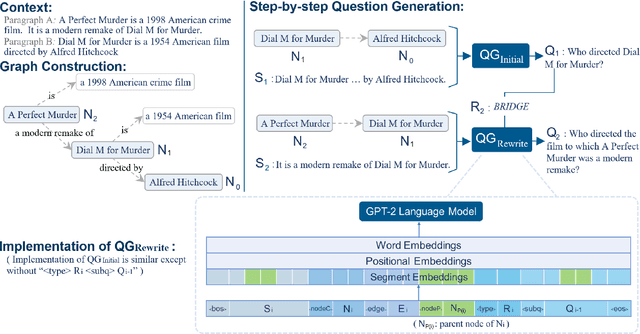

This paper explores the task of Difficulty-Controllable Question Generation (DCQG), which aims at generating questions with required difficulty levels. Previous research on this task mainly defines the difficulty of a question as whether it can be correctly answered by a Question Answering (QA) system, lacking interpretability and controllability. In our work, we redefine question difficulty as the number of inference steps required to answer it and argue that Question Generation (QG) systems should have stronger control over the logic of generated questions. To this end, we propose a novel framework that progressively increases question difficulty through step-by-step rewriting under the guidance of an extracted reasoning chain. A dataset is automatically constructed to facilitate the research, on which extensive experiments are conducted to test the performance of our method.
Imperfect also Deserves Reward: Multi-Level and Sequential Reward Modeling for Better Dialog Management
Apr 10, 2021For task-oriented dialog systems, training a Reinforcement Learning (RL) based Dialog Management module suffers from low sample efficiency and slow convergence speed due to the sparse rewards in RL.To solve this problem, many strategies have been proposed to give proper rewards when training RL, but their rewards lack interpretability and cannot accurately estimate the distribution of state-action pairs in real dialogs. In this paper, we propose a multi-level reward modeling approach that factorizes a reward into a three-level hierarchy: domain, act, and slot. Based on inverse adversarial reinforcement learning, our designed reward model can provide more accurate and explainable reward signals for state-action pairs.Extensive evaluations show that our approach can be applied to a wide range of reinforcement learning-based dialog systems and significantly improves both the performance and the speed of convergence.
* 9 pages
Enquire One's Parent and Child Before Decision: Fully Exploit Hierarchical Structure for Self-Supervised Taxonomy Expansion
Jan 27, 2021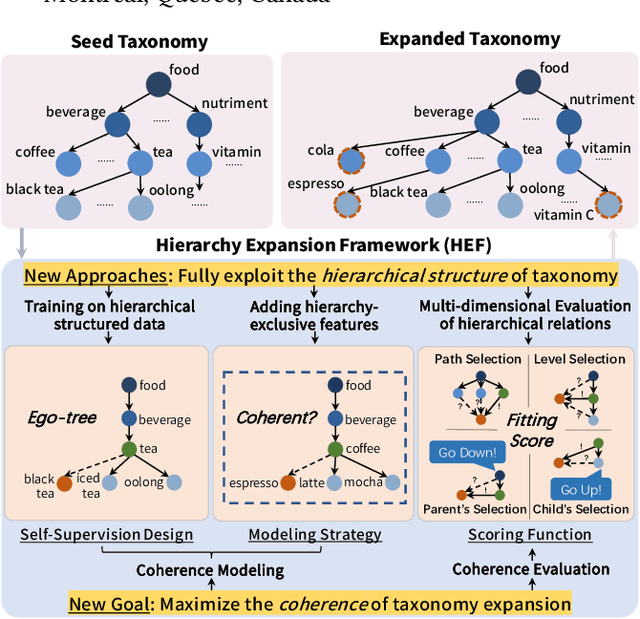
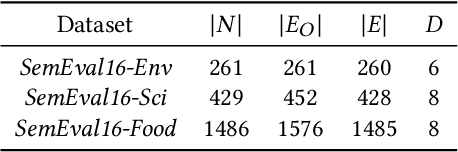
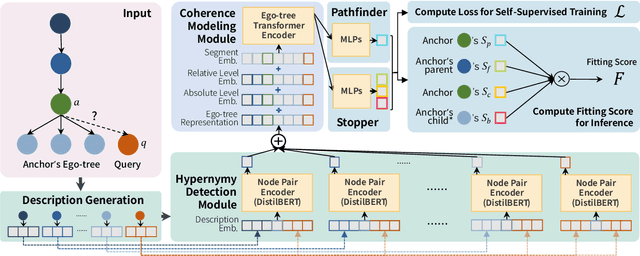
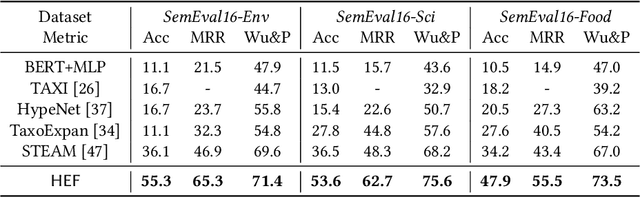
Taxonomy is a hierarchically structured knowledge graph that plays a crucial role in machine intelligence. The taxonomy expansion task aims to find a position for a new term in an existing taxonomy to capture the emerging knowledge in the world and keep the taxonomy dynamically updated. Previous taxonomy expansion solutions neglect valuable information brought by the hierarchical structure and evaluate the correctness of merely an added edge, which downgrade the problem to node-pair scoring or mini-path classification. In this paper, we propose the Hierarchy Expansion Framework (HEF), which fully exploits the hierarchical structure's properties to maximize the coherence of expanded taxonomy. HEF makes use of taxonomy's hierarchical structure in multiple aspects: i) HEF utilizes subtrees containing most relevant nodes as self-supervision data for a complete comparison of parental and sibling relations; ii) HEF adopts a coherence modeling module to evaluate the coherence of a taxonomy's subtree by integrating hypernymy relation detection and several tree-exclusive features; iii) HEF introduces the Fitting Score for position selection, which explicitly evaluates both path and level selections and takes full advantage of parental relations to interchange information for disambiguation and self-correction. Extensive experiments show that by better exploiting the hierarchical structure and optimizing taxonomy's coherence, HEF vastly surpasses the prior state-of-the-art on three benchmark datasets by an average improvement of 46.7% in accuracy and 32.3% in mean reciprocal rank.
Graph-Evolving Meta-Learning for Low-Resource Medical Dialogue Generation
Dec 22, 2020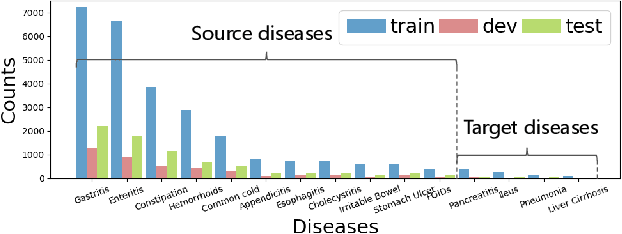
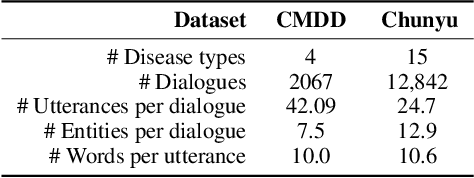
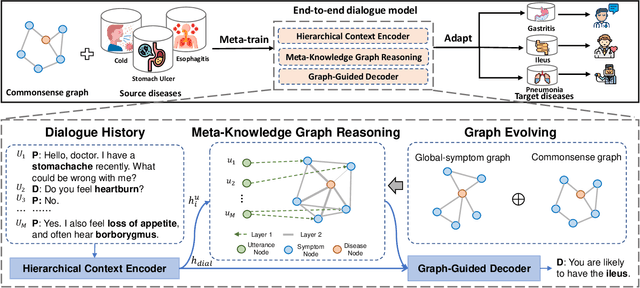
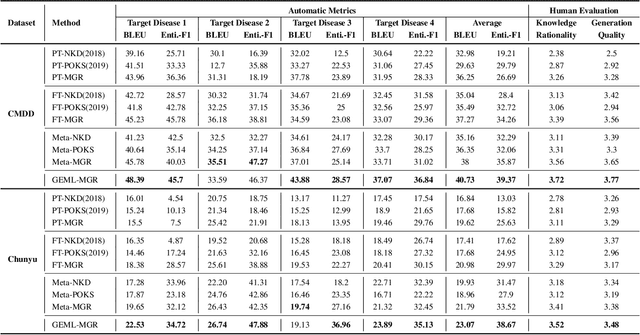
Human doctors with well-structured medical knowledge can diagnose a disease merely via a few conversations with patients about symptoms. In contrast, existing knowledge-grounded dialogue systems often require a large number of dialogue instances to learn as they fail to capture the correlations between different diseases and neglect the diagnostic experience shared among them. To address this issue, we propose a more natural and practical paradigm, i.e., low-resource medical dialogue generation, which can transfer the diagnostic experience from source diseases to target ones with a handful of data for adaptation. It is capitalized on a commonsense knowledge graph to characterize the prior disease-symptom relations. Besides, we develop a Graph-Evolving Meta-Learning (GEML) framework that learns to evolve the commonsense graph for reasoning disease-symptom correlations in a new disease, which effectively alleviates the needs of a large number of dialogues. More importantly, by dynamically evolving disease-symptom graphs, GEML also well addresses the real-world challenges that the disease-symptom correlations of each disease may vary or evolve along with more diagnostic cases. Extensive experiment results on the CMDD dataset and our newly-collected Chunyu dataset testify the superiority of our approach over state-of-the-art approaches. Besides, our GEML can generate an enriched dialogue-sensitive knowledge graph in an online manner, which could benefit other tasks grounded on knowledge graph.
Towards Communication-efficient and Attack-Resistant Federated Edge Learning for Industrial Internet of Things
Dec 08, 2020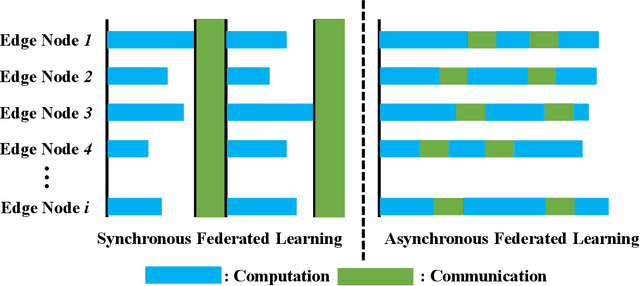
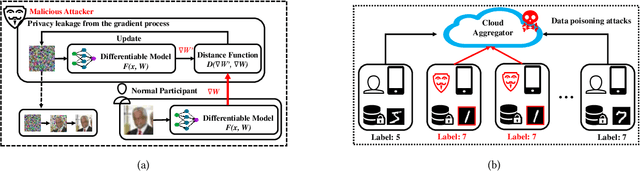
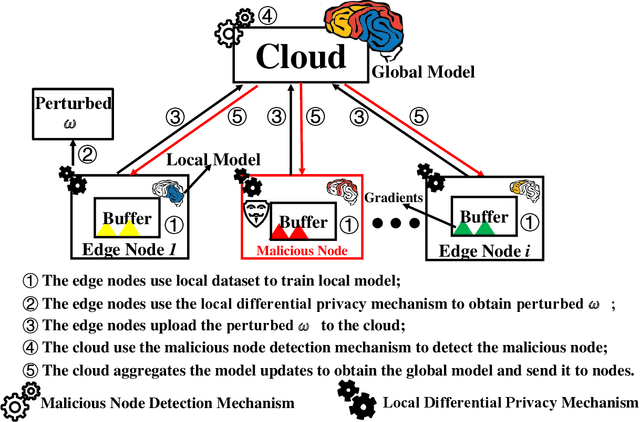
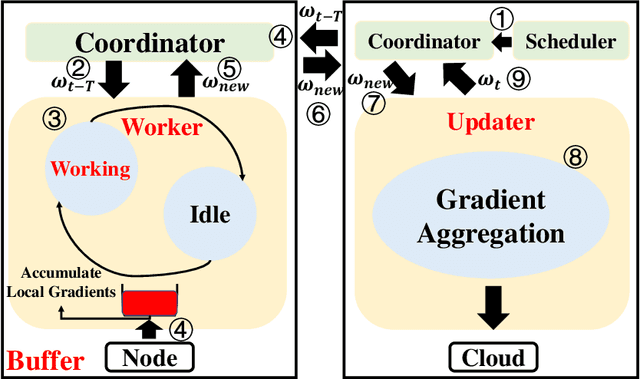
Federated Edge Learning (FEL) allows edge nodes to train a global deep learning model collaboratively for edge computing in the Industrial Internet of Things (IIoT), which significantly promotes the development of Industrial 4.0. However, FEL faces two critical challenges: communication overhead and data privacy. FEL suffers from expensive communication overhead when training large-scale multi-node models. Furthermore, due to the vulnerability of FEL to gradient leakage and label-flipping attacks, the training process of the global model is easily compromised by adversaries. To address these challenges, we propose a communication-efficient and privacy-enhanced asynchronous FEL framework for edge computing in IIoT. First, we introduce an asynchronous model update scheme to reduce the computation time that edge nodes wait for global model aggregation. Second, we propose an asynchronous local differential privacy mechanism, which improves communication efficiency and mitigates gradient leakage attacks by adding well-designed noise to the gradients of edge nodes. Third, we design a cloud-side malicious node detection mechanism to detect malicious nodes by testing the local model quality. Such a mechanism can avoid malicious nodes participating in training to mitigate label-flipping attacks. Extensive experimental studies on two real-world datasets demonstrate that the proposed framework can not only improve communication efficiency but also mitigate malicious attacks while its accuracy is comparable to traditional FEL frameworks.
RC-SSFL: Towards Robust and Communication-efficient Semi-supervised Federated Learning System
Dec 08, 2020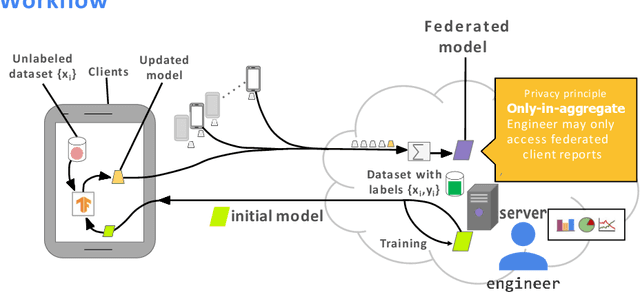
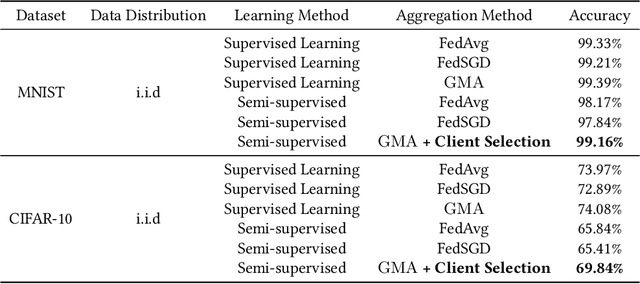
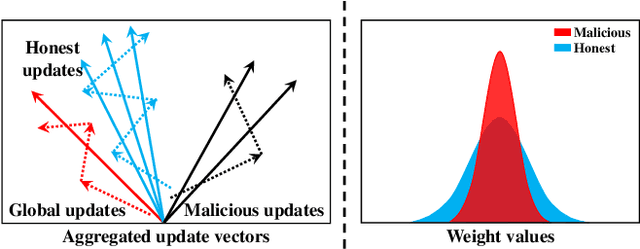
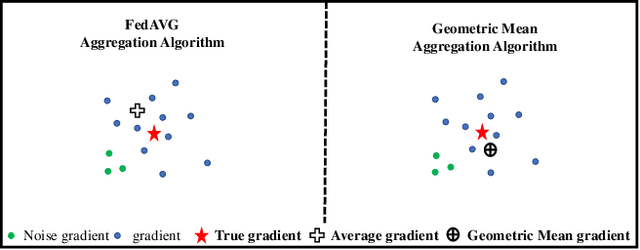
Federated Learning (FL) is an emerging decentralized artificial intelligence paradigm, which promises to train a shared global model in high-quality while protecting user data privacy. However, the current systems rely heavily on a strong assumption: all clients have a wealth of ground truth labeled data, which may not be always feasible in the real life. In this paper, we present a practical Robust, and Communication-efficient Semi-supervised FL (RC-SSFL) system design that can enable the clients to jointly learn a high-quality model that is comparable to typical FL's performance. In this setting, we assume that the client has only unlabeled data and the server has a limited amount of labeled data. Besides, we consider malicious clients can launch poisoning attacks to harm the performance of the global model. To solve this issue, RC-SSFL employs a minimax optimization-based client selection strategy to select the clients who hold high-quality updates and uses geometric median aggregation to robustly aggregate model updates. Furthermore, RC-SSFL implements a novel symmetric quantization method to greatly improve communication efficiency. Extensive case studies on two real-world datasets demonstrate that RC-SSFL can maintain the performance comparable to typical FL in the presence of poisoning attacks and reduce communication overhead by $2 \times \sim 4 \times $.
Privacy-Preserving Technology to Help Millions of People: Federated Prediction Model for Stroke Prevention
Jun 15, 2020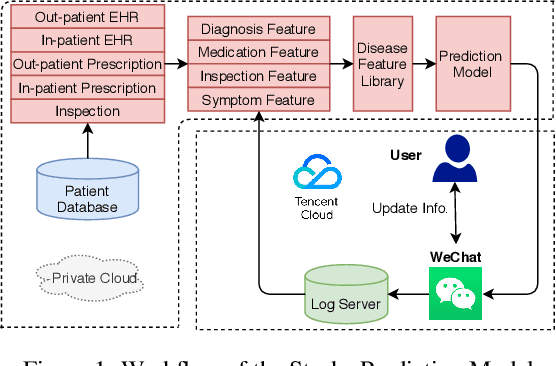
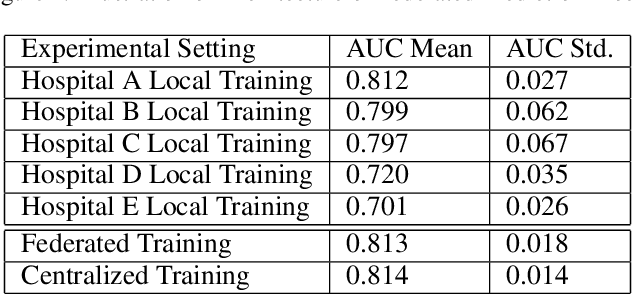
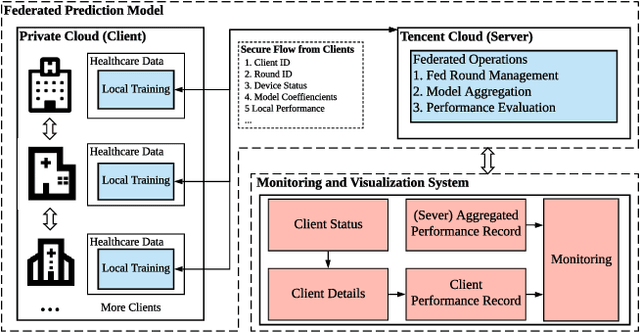
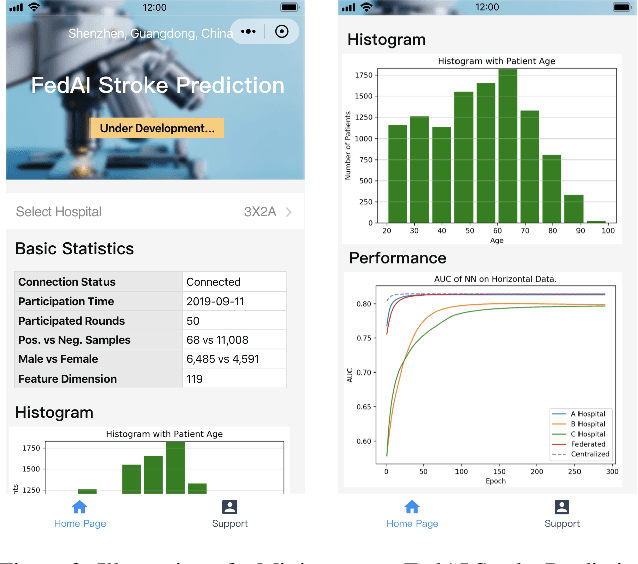
prevention of stroke with its associated risk factors has been one of the public health priorities worldwide. Emerging artificial intelligence technology is being increasingly adopted to predict stroke. Because of privacy concerns, patient data are stored in distributed electronic health record (EHR) databases, voluminous clinical datasets, which prevent patient data from being aggregated and restrains AI technology to boost the accuracy of stroke prediction with centralized training data. In this work, our scientists and engineers propose a privacy-preserving scheme to predict the risk of stroke and deploy our federated prediction model on cloud servers. Our system of federated prediction model asynchronously supports any number of client connections and arbitrary local gradient iterations in each communication round. It adopts federated averaging during the model training process, without patient data being taken out of the hospitals during the whole process of model training and forecasting. With the privacy-preserving mechanism, our federated prediction model trains over all the healthcare data from hospitals in a certain city without actual data sharing among them. Therefore, it is not only secure but also more accurate than any single prediction model that trains over the data only from one single hospital. Especially for small hospitals with few confirmed stroke cases, our federated model boosts model performance by 10%~20% in several machine learning metrics. To help stroke experts comprehend the advantage of our prediction system more intuitively, we developed a mobile app that collects the key information of patients' statistics and demonstrates performance comparisons between the federated prediction model and the single prediction model during the federated training process.