 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Confounding Factors-Inhibition Adversarial Learning Framework for Multi-site fMRI Mental Disorder Identification
Apr 12, 2025In open data sets of functional magnetic resonance imaging (fMRI), the heterogeneity of the data is typically attributed to a combination of factors, including differences in scanning procedures, the presence of confounding effects, and population diversities between multiple sites. These factors contribute to the diminished effectiveness of representation learning, which in turn affects the overall efficacy of subsequent classification procedures. To address these limitations, we propose a novel multi-site adversarial learning network (MSalNET) for fMRI-based mental disorder detection. Firstly, a representation learning module is introduced with a node information assembly (NIA) mechanism to better extract features from functional connectivity (FC). This mechanism aggregates edge information from both horizontal and vertical directions, effectively assembling node information. Secondly, to generalize the feature across sites, we proposed a site-level feature extraction module that can learn from individual FC data, which circumvents additional prior information. Lastly, an adversarial learning network is proposed as a means of balancing the trade-off between individual classification and site regression tasks, with the introduction of a novel loss function. The proposed method was evaluated on two multi-site fMRI datasets, i.e., Autism Brain Imaging Data Exchange (ABIDE) and ADHD-200. The results indicate that the proposed method achieves a better performance than other related algorithms with the accuracy of 75.56 and 68.92 in ABIDE and ADHD-200 datasets, respectively. Furthermore, the result of the site regression indicates that the proposed method reduces site variability from a data-driven perspective. The most discriminative brain regions revealed by NIA are consistent with statistical findings, uncovering the "black box" of deep learning to a certain extent.
Mapping Urban Villages in China: Progress and Challenges
Mar 18, 2025



The shift toward high-quality urbanization has brought increased attention to the issue of "urban villages", which has become a prominent social problem in China. However, there is a lack of available geospatial data on urban villages, making it crucial to prioritize urban village mapping. In order to assess the current progress in urban village mapping and identify challenges and future directions, we have conducted a comprehensive review, which to the best of our knowledge is the first of its kind in this field. Our review begins by providing a clear context for urban villages and elaborating the method for literature review, then summarizes the study areas, data sources, and approaches used for urban village mapping in China. We also address the challenges and future directions for further research. Through thorough investigation, we find that current studies only cover very limited study areas and periods and lack sufficient investigation into the scalability, transferability, and interpretability of identification approaches due to the challenges in concept fuzziness and variances, spatial heterogeneity and variances of urban villages, and data availability. Future research can complement and further the current research in the following potential directions in order to achieve large-area mapping across the whole nation...
* Updated review at https://github.com/rui-research/urban-village-review
Online Misinformation Detection in Live Streaming Videos
Mar 16, 2025Online misinformation detection is an important issue and methods are proposed to detect and curb misinformation in various forms. However, previous studies are conducted in an offline manner. We claim a realistic misinformation detection setting that has not been studied yet is online misinformation detection in live streaming videos (MDLS). In the proposal, we formulate the problem of MDLS and illustrate the importance and the challenge of the task. Besides, we propose feasible ways of developing the problem into AI challenges as well as potential solutions to the problem.
Evaluating LLMs' Assessment of Mixed-Context Hallucination Through the Lens of Summarization
Mar 03, 2025With the rapid development of large language models (LLMs), LLM-as-a-judge has emerged as a widely adopted approach for text quality evaluation, including hallucination evaluation. While previous studies have focused exclusively on single-context evaluation (e.g., discourse faithfulness or world factuality), real-world hallucinations typically involve mixed contexts, which remains inadequately evaluated. In this study, we use summarization as a representative task to comprehensively evaluate LLMs' capability in detecting mixed-context hallucinations, specifically distinguishing between factual and non-factual hallucinations. Through extensive experiments across direct generation and retrieval-based models of varying scales, our main observations are: (1) LLMs' intrinsic knowledge introduces inherent biases in hallucination evaluation; (2) These biases particularly impact the detection of factual hallucinations, yielding a significant performance bottleneck; (3) The fundamental challenge lies in effective knowledge utilization, balancing between LLMs' intrinsic knowledge and external context for accurate mixed-context hallucination evaluation.
Decompose and Leverage Preferences from Expert Models for Improving Trustworthiness of MLLMs
Nov 20, 2024



Multimodal Large Language Models (MLLMs) can enhance trustworthiness by aligning with human preferences. As human preference labeling is laborious, recent works employ evaluation models for assessing MLLMs' responses, using the model-based assessments to automate preference dataset construction. This approach, however, faces challenges with MLLMs' lengthy and compositional responses, which often require diverse reasoning skills that a single evaluation model may not fully possess. Additionally, most existing methods rely on closed-source models as evaluators. To address limitations, we propose DecompGen, a decomposable framework that uses an ensemble of open-sourced expert models. DecompGen breaks down each response into atomic verification tasks, assigning each task to an appropriate expert model to generate fine-grained assessments. The DecompGen feedback is used to automatically construct our preference dataset, DGPref. MLLMs aligned with DGPref via preference learning show improvements in trustworthiness, demonstrating the effectiveness of DecompGen.
MCDGLN: Masked Connection-based Dynamic Graph Learning Network for Autism Spectrum Disorder
Sep 10, 2024



Autism Spectrum Disorder (ASD) is a neurodevelopmental disorder characterized by complex physiological processes. Previous research has predominantly focused on static cerebral interactions, often neglecting the brain's dynamic nature and the challenges posed by network noise. To address these gaps, we introduce the Masked Connection-based Dynamic Graph Learning Network (MCDGLN). Our approach first segments BOLD signals using sliding temporal windows to capture dynamic brain characteristics. We then employ a specialized weighted edge aggregation (WEA) module, which uses the cross convolution with channel-wise element-wise convolutional kernel, to integrate dynamic functional connectivity and to isolating task-relevant connections. This is followed by topological feature extraction via a hierarchical graph convolutional network (HGCN), with key attributes highlighted by a self-attention module. Crucially, we refine static functional connections using a customized task-specific mask, reducing noise and pruning irrelevant links. The attention-based connection encoder (ACE) then enhances critical connections and compresses static features. The combined features are subsequently used for classification. Applied to the Autism Brain Imaging Data Exchange I (ABIDE I) dataset, our framework achieves a 73.3\% classification accuracy between ASD and Typical Control (TC) groups among 1,035 subjects. The pivotal roles of WEA and ACE in refining connectivity and enhancing classification accuracy underscore their importance in capturing ASD-specific features, offering new insights into the disorder.
Progressive Residual Extraction based Pre-training for Speech Representation Learning
Aug 31, 2024



Self-supervised learning (SSL) has garnered significant attention in speech processing, excelling in linguistic tasks such as speech recognition. However, jointly improving the performance of pre-trained models on various downstream tasks, each requiring different speech information, poses significant challenges. To this purpose, we propose a progressive residual extraction based self-supervised learning method, named ProgRE. Specifically, we introduce two lightweight and specialized task modules into an encoder-style SSL backbone to enhance its ability to extract pitch variation and speaker information from speech. Furthermore, to prevent the interference of reinforced pitch variation and speaker information with irrelevant content information learning, we residually remove the information extracted by these two modules from the main branch. The main branch is then trained using HuBERT's speech masking prediction to ensure the performance of the Transformer's deep-layer features on content tasks. In this way, we can progressively extract pitch variation, speaker, and content representations from the input speech. Finally, we can combine multiple representations with diverse speech information using different layer weights to obtain task-specific representations for various downstream tasks. Experimental results indicate that our proposed method achieves joint performance improvements on various tasks, such as speaker identification, speech recognition, emotion recognition, speech enhancement, and voice conversion, compared to excellent SSL methods such as wav2vec2.0, HuBERT, and WavLM.
An Evaluation of Standard Statistical Models and LLMs on Time Series Forecasting
Aug 09, 2024



This research examines the use of Large Language Models (LLMs) in predicting time series, with a specific focus on the LLMTIME model. Despite the established effectiveness of LLMs in tasks such as text generation, language translation, and sentiment analysis, this study highlights the key challenges that large language models encounter in the context of time series prediction. We assess the performance of LLMTIME across multiple datasets and introduce classical almost periodic functions as time series to gauge its effectiveness. The empirical results indicate that while large language models can perform well in zero-shot forecasting for certain datasets, their predictive accuracy diminishes notably when confronted with diverse time series data and traditional signals. The primary finding of this study is that the predictive capacity of LLMTIME, similar to other LLMs, significantly deteriorates when dealing with time series data that contain both periodic and trend components, as well as when the signal comprises complex frequency components.
SR-Mamba: Effective Surgical Phase Recognition with State Space Model
Jul 11, 2024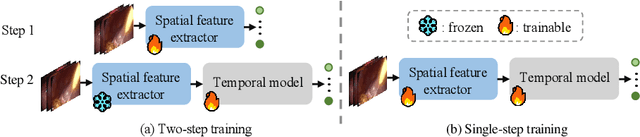
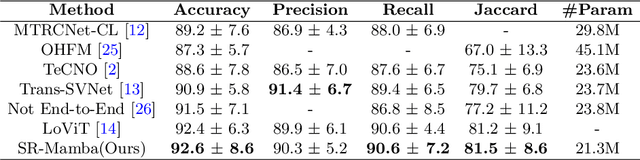
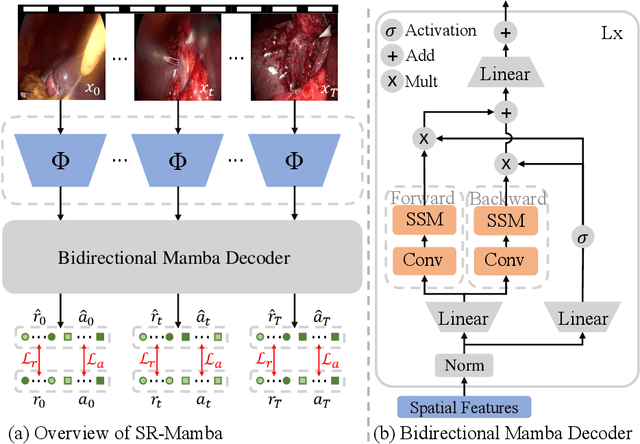
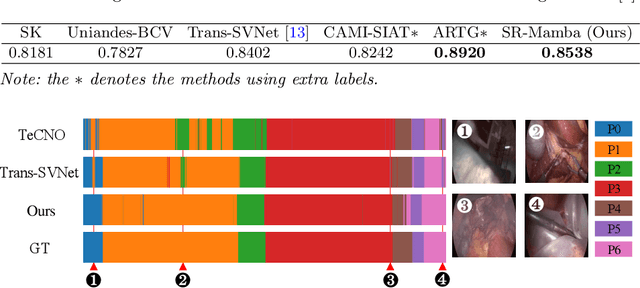
Surgical phase recognition is crucial for enhancing the efficiency and safety of computer-assisted interventions. One of the fundamental challenges involves modeling the long-distance temporal relationships present in surgical videos. Inspired by the recent success of Mamba, a state space model with linear scalability in sequence length, this paper presents SR-Mamba, a novel attention-free model specifically tailored to meet the challenges of surgical phase recognition. In SR-Mamba, we leverage a bidirectional Mamba decoder to effectively model the temporal context in overlong sequences. Moreover, the efficient optimization of the proposed Mamba decoder facilitates single-step neural network training, eliminating the need for separate training steps as in previous works. This single-step training approach not only simplifies the training process but also ensures higher accuracy, even with a lighter spatial feature extractor. Our SR-Mamba establishes a new benchmark in surgical video analysis by demonstrating state-of-the-art performance on the Cholec80 and CATARACTS Challenge datasets. The code is accessible at https://github.com/rcao-hk/SR-Mamba.
FANFOLD: Graph Normalizing Flows-driven Asymmetric Network for Unsupervised Graph-Level Anomaly Detection
Jun 29, 2024Unsupervised graph-level anomaly detection (UGAD) has attracted increasing interest due to its widespread application. In recent studies, knowledge distillation-based methods have been widely used in unsupervised anomaly detection to improve model efficiency and generalization. However, the inherent symmetry between the source (teacher) and target (student) networks typically results in consistent outputs across both architectures, making it difficult to distinguish abnormal graphs from normal graphs. Also, existing methods mainly rely on graph features to distinguish anomalies, which may be unstable with complex and diverse data and fail to capture the essence that differentiates normal graphs from abnormal ones. In this work, we propose a Graph Normalizing Flows-driven Asymmetric Network For Unsupervised Graph-Level Anomaly Detection (FANFOLD in short). We introduce normalizing flows to unsupervised graph-level anomaly detection due to their successful application and superior quality in learning the underlying distribution of samples. Specifically, we adopt the knowledge distillation technique and apply normalizing flows on the source network, achieving the asymmetric network. In the training stage, FANFOLD transforms the original distribution of normal graphs to a standard normal distribution. During inference, FANFOLD computes the anomaly score using the source-target loss to discriminate between normal and anomalous graphs. We conduct extensive experiments on 15 datasets of different fields with 9 baseline methods to validate the superiority of FANFOLD.