 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Distillation: Towards Omni-Supervised Learning
Dec 12, 2017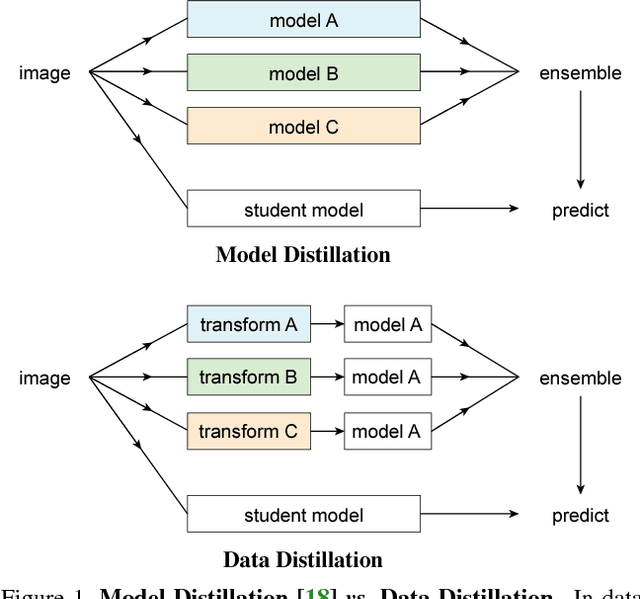
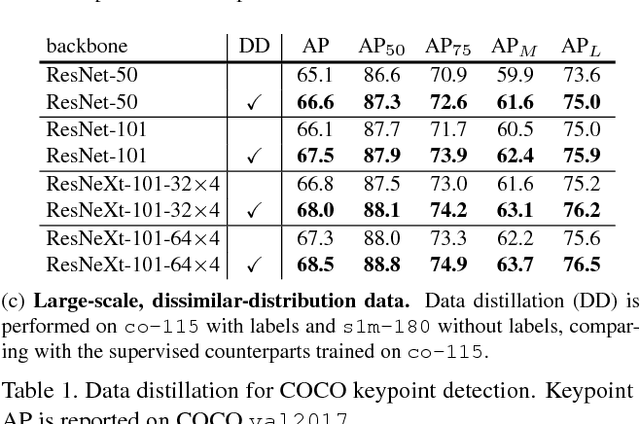

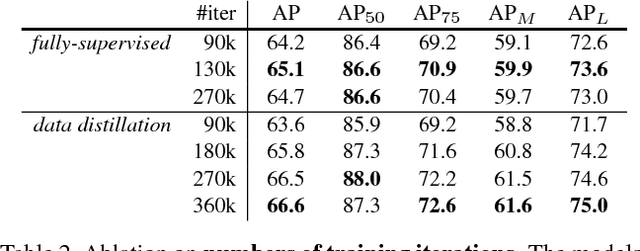
We investigate omni-supervised learning, a special regime of semi-supervised learning in which the learner exploits all available labeled data plus internet-scale sources of unlabeled data. Omni-supervised learning is lower-bounded by performance on existing labeled datasets, offering the potential to surpass state-of-the-art fully supervised methods. To exploit the omni-supervised setting, we propose data distillation, a method that ensembles predictions from multiple transformations of unlabeled data, using a single model, to automatically generate new training annotations. We argue that visual recognition models have recently become accurate enough that it is now possible to apply classic ideas about self-training to challenging real-world data. Our experimental results show that in the cases of human keypoint detection and general object detection, state-of-the-art models trained with data distillation surpass the performance of using labeled data from the COCO dataset alone.
Learning by Asking Questions
Dec 04, 2017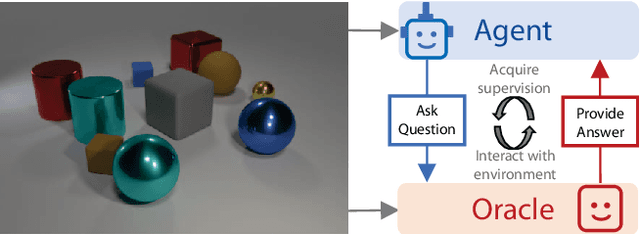
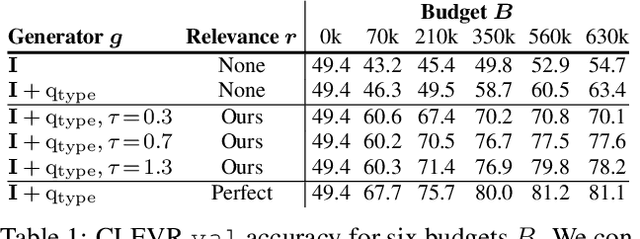

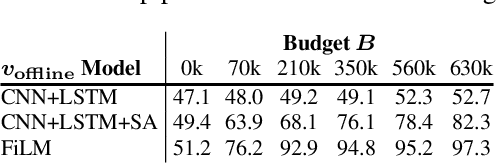
We introduce an interactive learning framework for the development and testing of intelligent visual systems, called learning-by-asking (LBA). We explore LBA in context of the Visual Question Answering (VQA) task. LBA differs from standard VQA training in that most questions are not observed during training time, and the learner must ask questions it wants answers to. Thus, LBA more closely mimics natural learning and has the potential to be more data-efficient than the traditional VQA setting. We present a model that performs LBA on the CLEVR dataset, and show that it automatically discovers an easy-to-hard curriculum when learning interactively from an oracle. Our LBA generated data consistently matches or outperforms the CLEVR train data and is more sample efficient. We also show that our model asks questions that generalize to state-of-the-art VQA models and to novel test time distributions.
Low-shot Visual Recognition by Shrinking and Hallucinating Features
Nov 04, 2017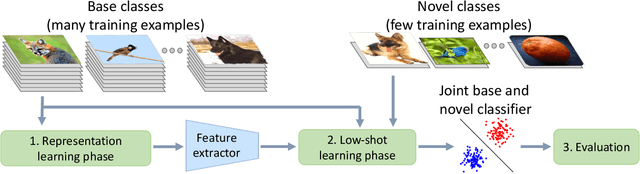
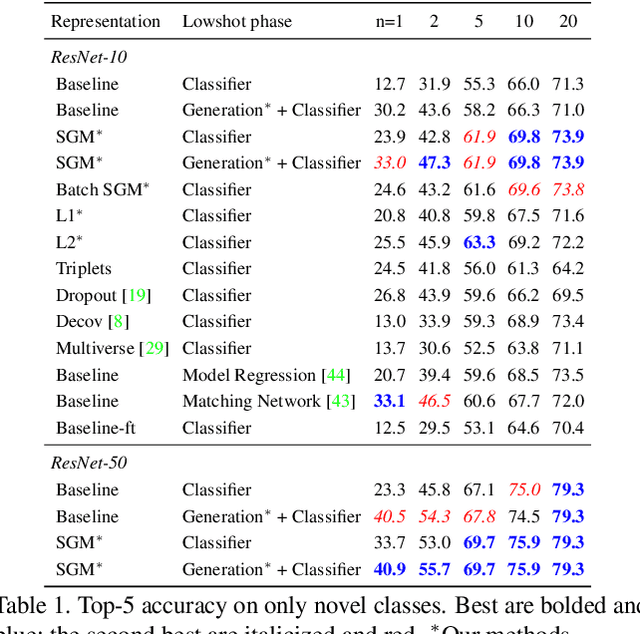
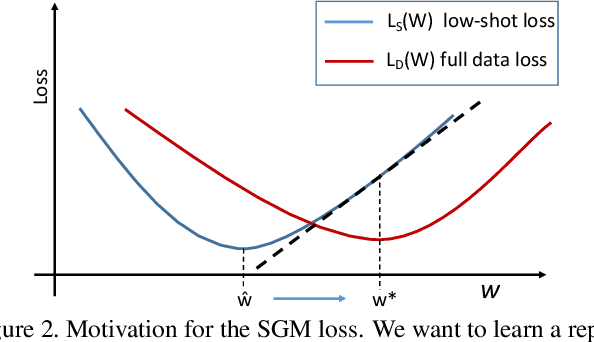
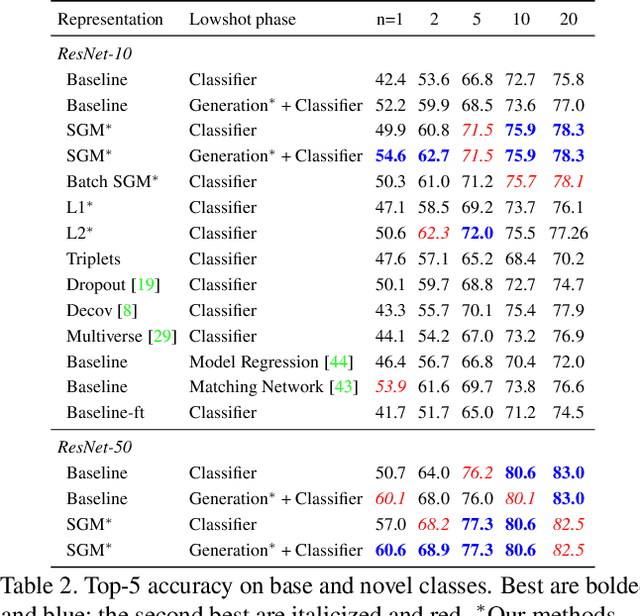
Low-shot visual learning---the ability to recognize novel object categories from very few examples---is a hallmark of human visual intelligence. Existing machine learning approaches fail to generalize in the same way. To make progress on this foundational problem, we present a low-shot learning benchmark on complex images that mimics challenges faced by recognition systems in the wild. We then propose a) representation regularization techniques, and b) techniques to hallucinate additional training examples for data-starved classes. Together, our methods improve the effectiveness of convolutional networks in low-shot learning, improving the one-shot accuracy on novel classes by 2.3x on the challenging ImageNet dataset.
Inferring and Executing Programs for Visual Reasoning
May 10, 2017
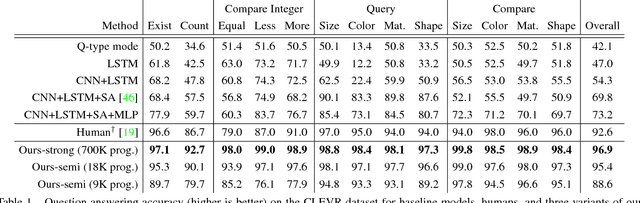
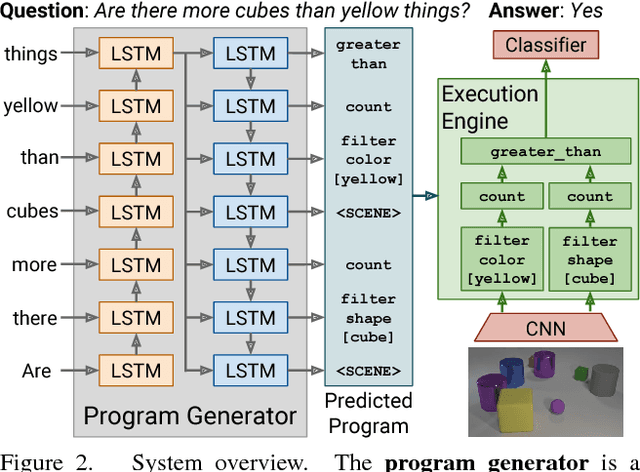
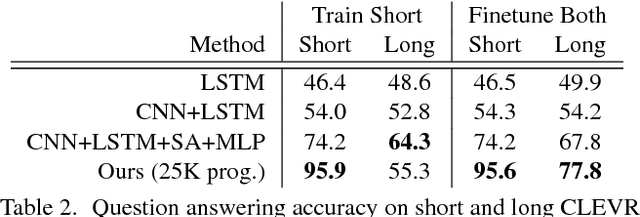
Existing methods for visual reasoning attempt to directly map inputs to outputs using black-box architectures without explicitly modeling the underlying reasoning processes. As a result, these black-box models often learn to exploit biases in the data rather than learning to perform visual reasoning. Inspired by module networks, this paper proposes a model for visual reasoning that consists of a program generator that constructs an explicit representation of the reasoning process to be performed, and an execution engine that executes the resulting program to produce an answer. Both the program generator and the execution engine are implemented by neural networks, and are trained using a combination of backpropagation and REINFORCE. Using the CLEVR benchmark for visual reasoning, we show that our model significantly outperforms strong baselines and generalizes better in a variety of settings.
Feature Pyramid Networks for Object Detection
Apr 19, 2017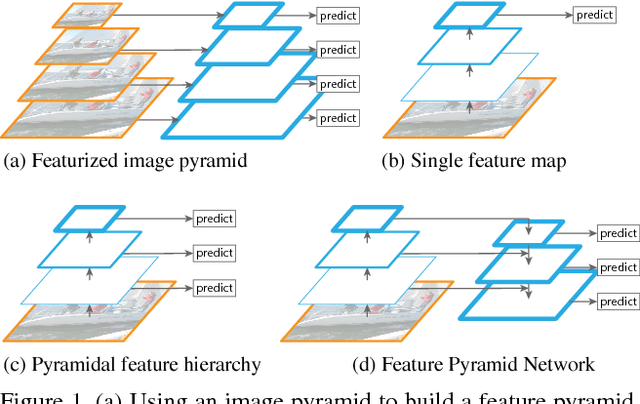
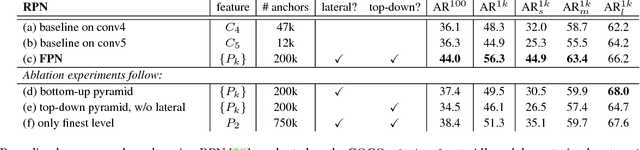
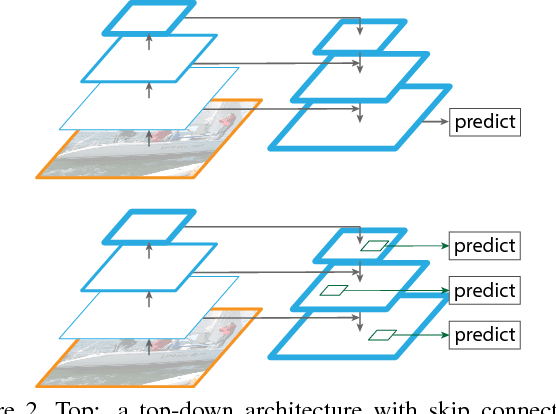

Feature pyramids are a basic component in recognition systems for detecting objects at different scales. But recent deep learning object detectors have avoided pyramid representations, in part because they are compute and memory intensive. In this paper, we exploit the inherent multi-scale, pyramidal hierarchy of deep convolutional networks to construct feature pyramids with marginal extra cost. A top-down architecture with lateral connections is developed for building high-level semantic feature maps at all scales. This architecture, called a Feature Pyramid Network (FPN), shows significant improvement as a generic feature extractor in several applications. Using FPN in a basic Faster R-CNN system, our method achieves state-of-the-art single-model results on the COCO detection benchmark without bells and whistles, surpassing all existing single-model entries including those from the COCO 2016 challenge winners. In addition, our method can run at 5 FPS on a GPU and thus is a practical and accurate solution to multi-scale object detection. Code will be made publicly available.
Learning Features by Watching Objects Move
Apr 12, 2017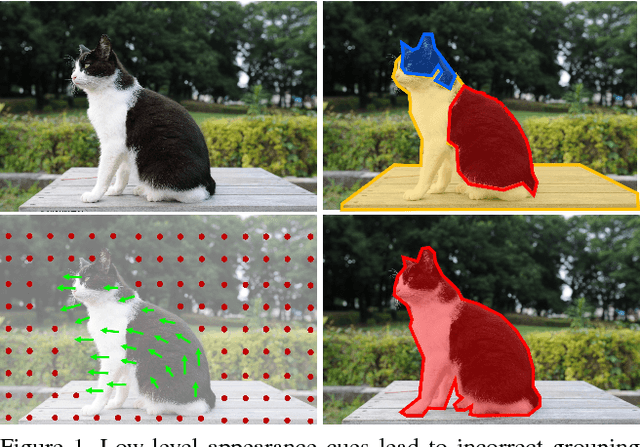
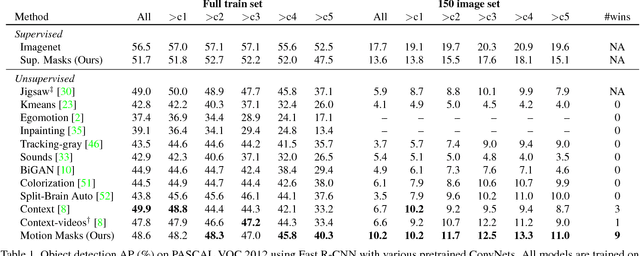
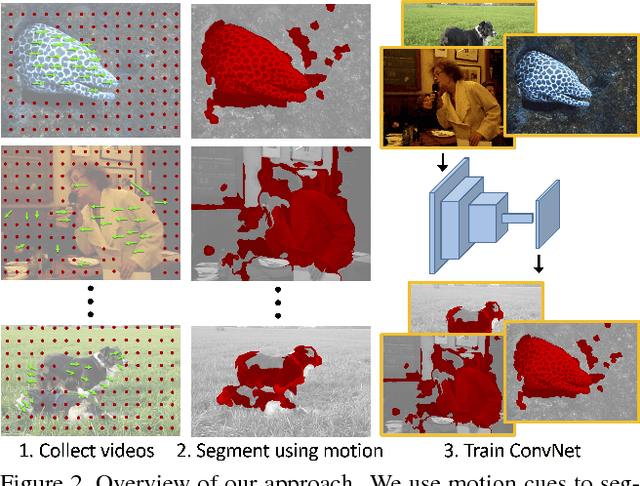
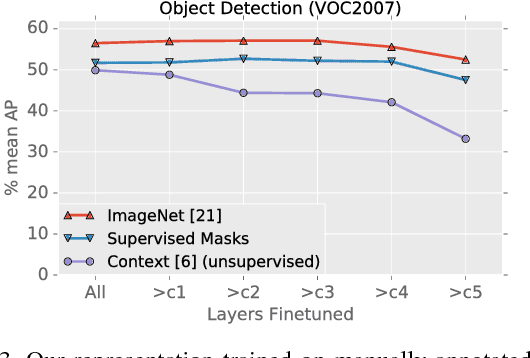
This paper presents a novel yet intuitive approach to unsupervised feature learning. Inspired by the human visual system, we explore whether low-level motion-based grouping cues can be used to learn an effective visual representation. Specifically, we use unsupervised motion-based segmentation on videos to obtain segments, which we use as 'pseudo ground truth' to train a convolutional network to segment objects from a single frame. Given the extensive evidence that motion plays a key role in the development of the human visual system, we hope that this straightforward approach to unsupervised learning will be more effective than cleverly designed 'pretext' tasks studied in the literature. Indeed, our extensive experiments show that this is the case. When used for transfer learning on object detection, our representation significantly outperforms previous unsupervised approaches across multiple settings, especially when training data for the target task is scarce.
Aggregated Residual Transformations for Deep Neural Networks
Apr 11, 2017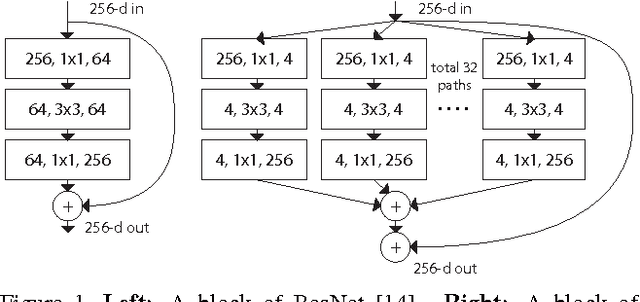
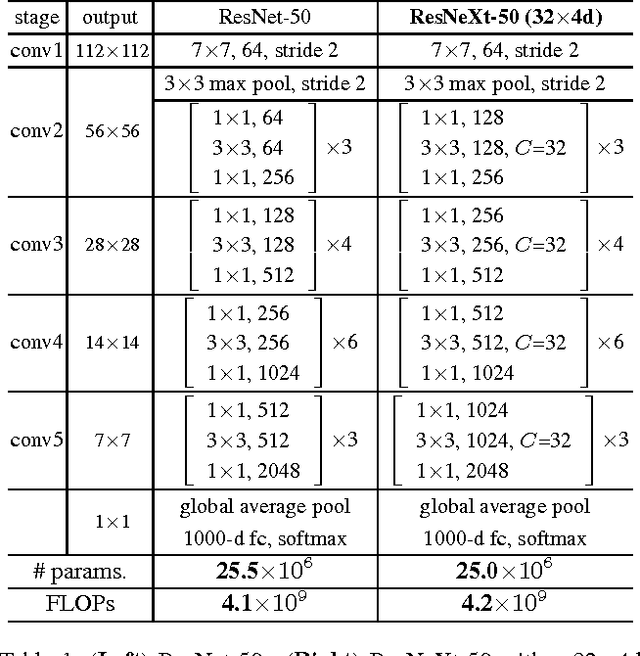
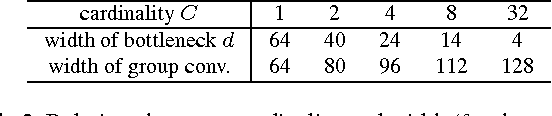
We present a simple, highly modularized network architecture for image classification. Our network is constructed by repeating a building block that aggregates a set of transformations with the same topology. Our simple design results in a homogeneous, multi-branch architecture that has only a few hyper-parameters to set. This strategy exposes a new dimension, which we call "cardinality" (the size of the set of transformations), as an essential factor in addition to the dimensions of depth and width. On the ImageNet-1K dataset, we empirically show that even under the restricted condition of maintaining complexity, increasing cardinality is able to improve classification accuracy. Moreover, increasing cardinality is more effective than going deeper or wider when we increase the capacity. Our models, named ResNeXt, are the foundations of our entry to the ILSVRC 2016 classification task in which we secured 2nd place. We further investigate ResNeXt on an ImageNet-5K set and the COCO detection set, also showing better results than its ResNet counterpart. The code and models are publicly available online.
CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning
Dec 20, 2016
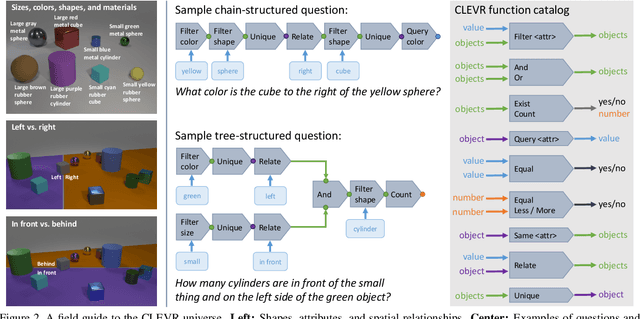
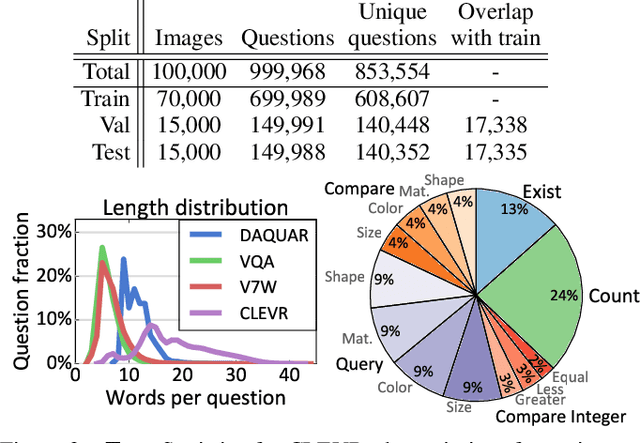
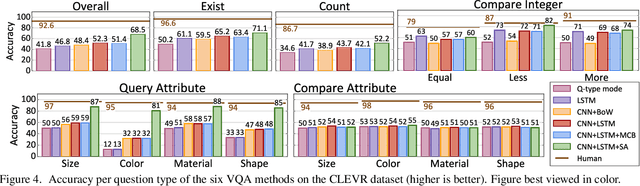
When building artificial intelligence systems that can reason and answer questions about visual data, we need diagnostic tests to analyze our progress and discover shortcomings. Existing benchmarks for visual question answering can help, but have strong biases that models can exploit to correctly answer questions without reasoning. They also conflate multiple sources of error, making it hard to pinpoint model weaknesses. We present a diagnostic dataset that tests a range of visual reasoning abilities. It contains minimal biases and has detailed annotations describing the kind of reasoning each question requires. We use this dataset to analyze a variety of modern visual reasoning systems, providing novel insights into their abilities and limitations.
Object Detection Networks on Convolutional Feature Maps
Aug 17, 2016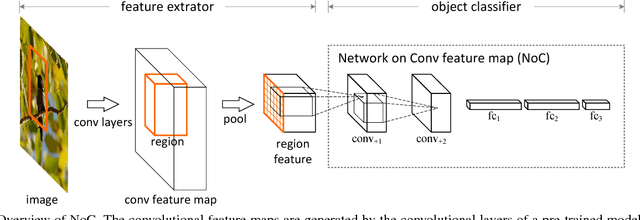
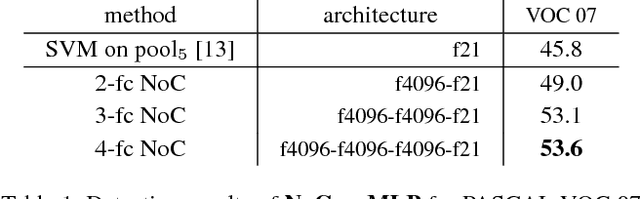
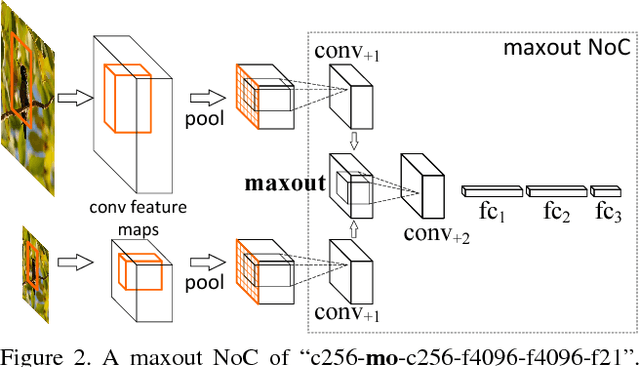
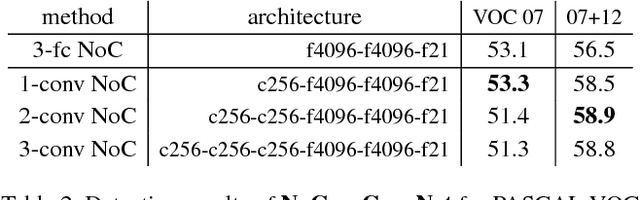
Most object detectors contain two important components: a feature extractor and an object classifier. The feature extractor has rapidly evolved with significant research efforts leading to better deep convolutional architectures. The object classifier, however, has not received much attention and many recent systems (like SPPnet and Fast/Faster R-CNN) use simple multi-layer perceptrons. This paper demonstrates that carefully designing deep networks for object classification is just as important. We experiment with region-wise classifier networks that use shared, region-independent convolutional features. We call them "Networks on Convolutional feature maps" (NoCs). We discover that aside from deep feature maps, a deep and convolutional per-region classifier is of particular importance for object detection, whereas latest superior image classification models (such as ResNets and GoogLeNets) do not directly lead to good detection accuracy without using such a per-region classifier. We show by experiments that despite the effective ResNets and Faster R-CNN systems, the design of NoCs is an essential element for the 1st-place winning entries in ImageNet and MS COCO challenges 2015.
Reducing Overfitting in Deep Networks by Decorrelating Representations
Jun 10, 2016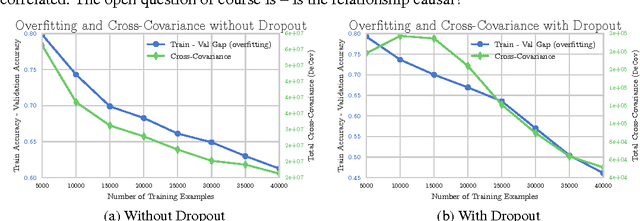
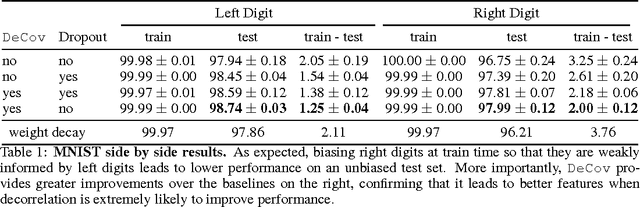
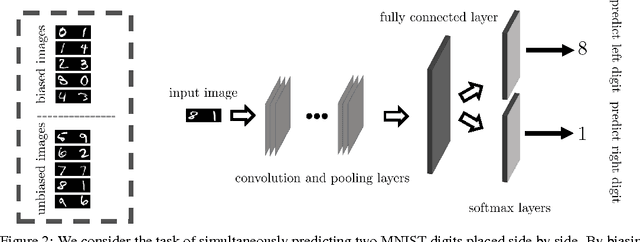
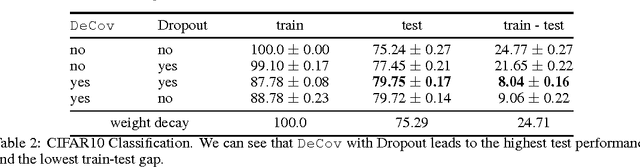
One major challenge in training Deep Neural Networks is preventing overfitting. Many techniques such as data augmentation and novel regularizers such as Dropout have been proposed to prevent overfitting without requiring a massive amount of training data. In this work, we propose a new regularizer called DeCov which leads to significantly reduced overfitting (as indicated by the difference between train and val performance), and better generalization. Our regularizer encourages diverse or non-redundant representations in Deep Neural Networks by minimizing the cross-covariance of hidden activations. This simple intuition has been explored in a number of past works but surprisingly has never been applied as a regularizer in supervised learning. Experiments across a range of datasets and network architectures show that this loss always reduces overfitting while almost always maintaining or increasing generalization performance and often improving performance over Dropout.