 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Segment, Soft Growing Robot with Selective Steering
Dec 07, 2022



Everting, soft growing vine robots benefit from reduced friction with their environment, which allows them to navigate challenging terrain. Vine robots can use air pouches attached to their sides for lateral steering. However, when all pouches are serially connected, the whole robot can only perform one constant curvature in free space. It must contact the environment to navigate through obstacles along paths with multiple turns. This work presents a multi-segment vine robot that can navigate complex paths without interacting with its environment. This is achieved by a new steering method that selectively actuates each single pouch at the tip, providing high degrees of freedom with few control inputs. A small magnetic valve connects each pouch to a pressure supply line. A motorized tip mount uses an interlocking mechanism and motorized rollers on the outer material of the vine robot. As each valve passes through the tip mount, a permanent magnet inside the tip mount opens the valve so the corresponding pouch is connected to the pressure supply line at the same moment. Novel cylindrical pneumatic artificial muscles (cPAMs) are integrated into the vine robot and inflate to a cylindrical shape for improved bending characteristics compared to other state-of-the art vine robots. The motorized tip mount controls a continuous eversion speed and enables controlled retraction. A final prototype was able to repeatably grow into different shapes and hold these shapes. We predict the path using a model that assumes a piecewise constant curvature along the outside of the multi-segment vine robot. The proposed multi-segment steering method can be extended to other soft continuum robot designs.
maplab 2.0 -- A Modular and Multi-Modal Mapping Framework
Dec 01, 2022Integration of multiple sensor modalities and deep learning into Simultaneous Localization And Mapping (SLAM) systems are areas of significant interest in current research. Multi-modality is a stepping stone towards achieving robustness in challenging environments and interoperability of heterogeneous multi-robot systems with varying sensor setups. With maplab 2.0, we provide a versatile open-source platform that facilitates developing, testing, and integrating new modules and features into a fully-fledged SLAM system. Through extensive experiments, we show that maplab 2.0's accuracy is comparable to the state-of-the-art on the HILTI 2021 benchmark. Additionally, we showcase the flexibility of our system with three use cases: i) large-scale (approx. 10 km) multi-robot multi-session (23 missions) mapping, ii) integration of non-visual landmarks, and iii) incorporating a semantic object-based loop closure module into the mapping framework. The code is available open-source at https://github.com/ethz-asl/maplab.
Unsupervised Continual Semantic Adaptation through Neural Rendering
Nov 25, 2022



An increasing amount of applications rely on data-driven models that are deployed for perception tasks across a sequence of scenes. Due to the mismatch between training and deployment data, adapting the model on the new scenes is often crucial to obtain good performance. In this work, we study continual multi-scene adaptation for the task of semantic segmentation, assuming that no ground-truth labels are available during deployment and that performance on the previous scenes should be maintained. We propose training a Semantic-NeRF network for each scene by fusing the predictions of a segmentation model and then using the view-consistent rendered semantic labels as pseudo-labels to adapt the model. Through joint training with the segmentation model, the Semantic-NeRF model effectively enables 2D-3D knowledge transfer. Furthermore, due to its compact size, it can be stored in a long-term memory and subsequently used to render data from arbitrary viewpoints to reduce forgetting. We evaluate our approach on ScanNet, where we outperform both a voxel-based baseline and a state-of-the-art unsupervised domain adaptation method.
A Framework for Collaborative Multi-Robot Mapping using Spectral Graph Wavelets
Nov 02, 2022The exploration of large-scale unknown environments can benefit from the deployment of multiple robots for collaborative mapping. Each robot explores a section of the environment and communicates onboard pose estimates and maps to a central server to build an optimized global multi-robot map. Naturally, inconsistencies can arise between onboard and server estimates due to onboard odometry drift, failures, or degeneracies. The mapping server can correct and overcome such failure cases using computationally expensive operations such as inter-robot loop closure detection and multi-modal mapping. However, the individual robots do not benefit from the collaborative map if the mapping server provides no feedback. Although server updates from the multi-robot map can greatly alleviate the robotic mission strategically, most existing work lacks them, due to their associated computational and bandwidth-related costs. Motivated by this challenge, this paper proposes a novel collaborative mapping framework that enables global mapping consistency among robots and the mapping server. In particular, we propose graph spectral analysis, at different spatial scales, to detect structural differences between robot and server graphs, and to generate necessary constraints for the individual robot pose graphs. Our approach specifically finds the nodes that correspond to the drift's origin rather than the nodes where the error becomes too large. We thoroughly analyze and validate our proposed framework using several real-world multi-robot field deployments where we show improvements of the onboard system up to 90\% and can recover the onboard estimation from localization failures and even from the degeneracies within its estimation.
SphNet: A Spherical Network for Semantic Pointcloud Segmentation
Oct 24, 2022Semantic segmentation for robotic systems can enable a wide range of applications, from self-driving cars and augmented reality systems to domestic robots. We argue that a spherical representation is a natural one for egocentric pointclouds. Thus, in this work, we present a novel framework exploiting such a representation of LiDAR pointclouds for the task of semantic segmentation. Our approach is based on a spherical convolutional neural network that can seamlessly handle observations from various sensor systems (e.g., different LiDAR systems) and provides an accurate segmentation of the environment. We operate in two distinct stages: First, we encode the projected input pointclouds to spherical features. Second, we decode and back-project the spherical features to achieve an accurate semantic segmentation of the pointcloud. We evaluate our method with respect to state-of-the-art projection-based semantic segmentation approaches using well-known public datasets. We demonstrate that the spherical representation enables us to provide more accurate segmentation and to have a better generalization to sensors with different field-of-view and number of beams than what was seen during training.
Baking in the Feature: Accelerating Volumetric Segmentation by Rendering Feature Maps
Sep 26, 2022


Methods have recently been proposed that densely segment 3D volumes into classes using only color images and expert supervision in the form of sparse semantically annotated pixels. While impressive, these methods still require a relatively large amount of supervision and segmenting an object can take several minutes in practice. Such systems typically only optimize their representation on the particular scene they are fitting, without leveraging any prior information from previously seen images. In this paper, we propose to use features extracted with models trained on large existing datasets to improve segmentation performance. We bake this feature representation into a Neural Radiance Field (NeRF) by volumetrically rendering feature maps and supervising on features extracted from each input image. We show that by baking this representation into the NeRF, we make the subsequent classification task much easier. Our experiments show that our method achieves higher segmentation accuracy with fewer semantic annotations than existing methods over a wide range of scenes.
3D VSG: Long-term Semantic Scene Change Prediction through 3D Variable Scene Graphs
Sep 16, 2022
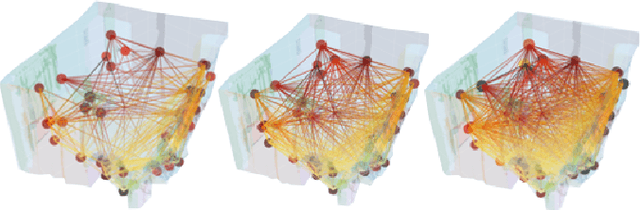

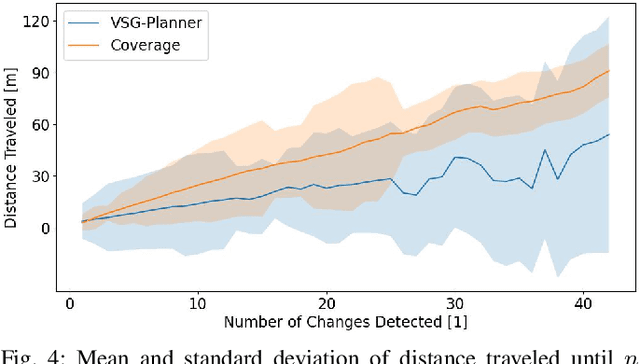
Numerous applications require robots to operate in environments shared with other agents such as humans or other robots. However, such shared scenes are typically subject to different kinds of long-term semantic scene changes. The ability to model and predict such changes is thus crucial for robot autonomy. In this work, we formalize the task of semantic scene variability estimation and identify three main varieties of semantic scene change: changes in the position of an object, its semantic state, or the composition of a scene as a whole. To represent this variability, we propose the Variable Scene Graph (VSG), which augments existing 3D Scene Graph (SG) representations with the variability attribute, representing the likelihood of discrete long-term change events. We present a novel method, DeltaVSG, to estimate the variability of VSGs in a supervised fashion. We evaluate our method on the 3RScan long-term dataset, showing notable improvements in this novel task over existing approaches. Our method DeltaVSG achieves a precision of 72.2% and recall of 66.8%, often mimicking human intuition about how indoor scenes change over time. We further show the utility of VSG predictions in the task of active robotic change detection, speeding up task completion by 62.4% compared to a scene-change-unaware planner. We make our code available as open-source.
On the programming effort required to generate Behavior Trees and Finite State Machines for robotic applications
Sep 15, 2022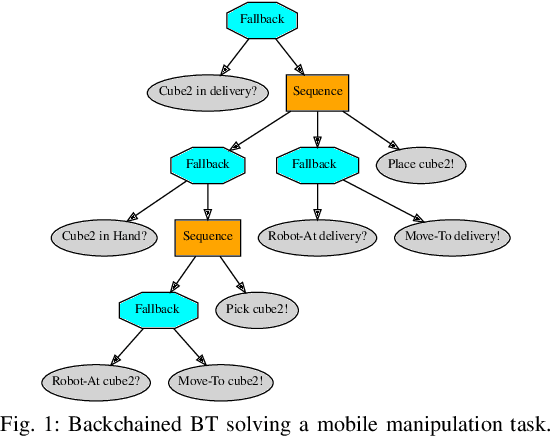
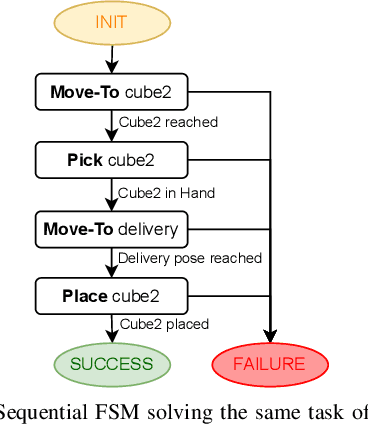


In this paper we provide a practical demonstration of how the modularity in a Behavior Tree (BT) decreases the effort in programming a robot task when compared to a Finite State Machine (FSM). In recent years the way to represent a task plan to control an autonomous agent has been shifting from the standard FSM towards BTs. Many works in the literature have highlighted and proven the benefits of such design compared to standard approaches, especially in terms of modularity, reactivity and human readability. However, these works have often failed in providing a tangible comparison in the implementation of those policies and the programming effort required to modify them. This is a relevant aspect in many robotic applications, where the design choice is dictated both by the robustness of the policy and by the time required to program it. In this work, we compare backward chained BTs with a fault-tolerant design of FSMs by evaluating the cost to modify them. We validate the analysis with a set of experiments in a simulation environment where a mobile manipulator solves an item fetching task.
Learning Agent-Aware Affordances for Closed-Loop Interaction with Articulated Objects
Sep 14, 2022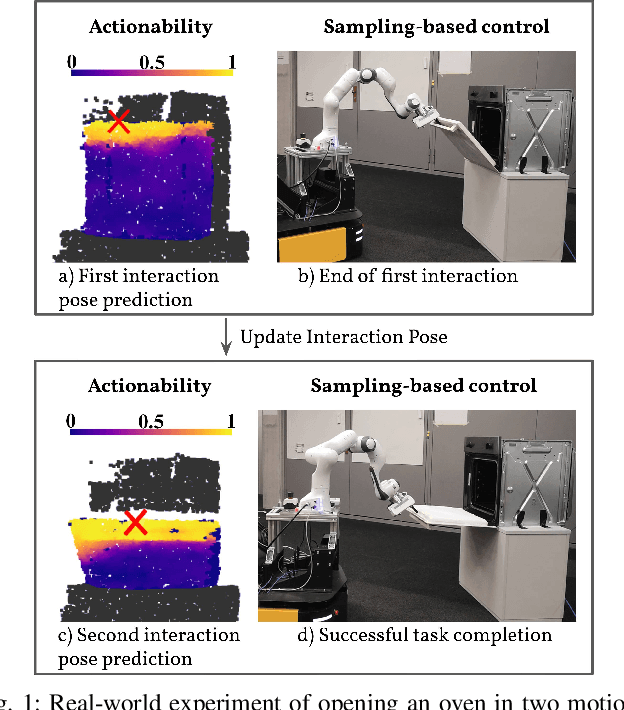


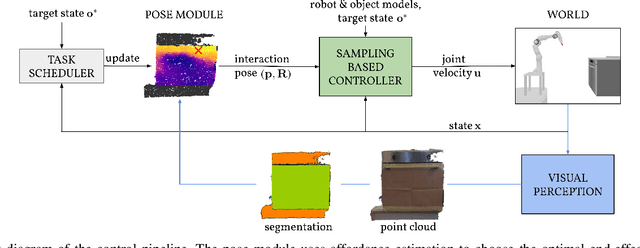
Interactions with articulated objects are a challenging but important task for mobile robots. To tackle this challenge, we propose a novel closed-loop control pipeline, which integrates manipulation priors from affordance estimation with sampling-based whole-body control. We introduce the concept of agent-aware affordances which fully reflect the agent's capabilities and embodiment and we show that they outperform their state-of-the-art counterparts which are only conditioned on the end-effector geometry. Additionally, closed-loop affordance inference is found to allow the agent to divide a task into multiple non-continuous motions and recover from failure and unexpected states. Finally, the pipeline is able to perform long-horizon mobile manipulation tasks, i.e. opening and closing an oven, in the real world with high success rates (opening: 71%, closing: 72%).
Incremental 3D Scene Completion for Safe and Efficient Exploration Mapping and Planning
Aug 17, 2022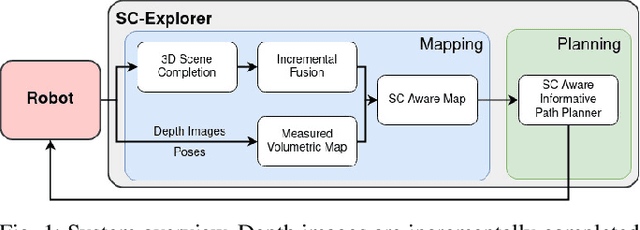

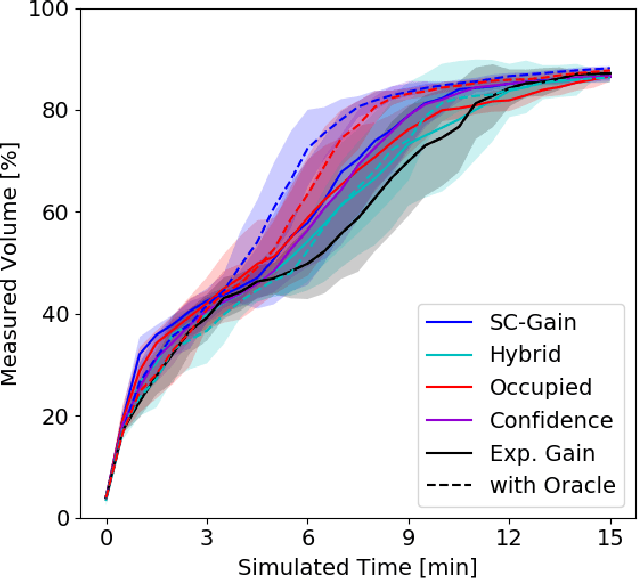
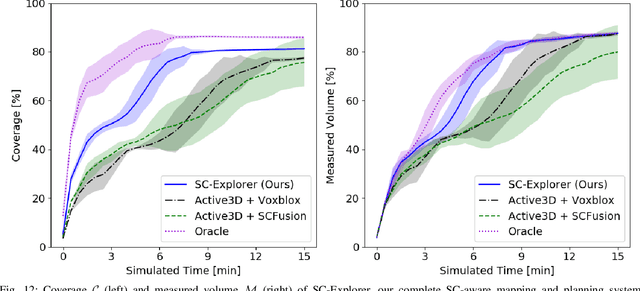
Exploration of unknown environments is a fundamental problem in robotics and an essential component in numerous applications of autonomous systems. A major challenge in exploring unknown environments is that the robot has to plan with the limited information available at each time step. While most current approaches rely on heuristics and assumption to plan paths based on these partial observations, we instead propose a novel way to integrate deep learning into exploration by leveraging 3D scene completion for informed, safe, and interpretable exploration mapping and planning. Our approach, SC-Explorer, combines scene completion using a novel incremental fusion mechanism and a newly proposed hierarchical multi-layer mapping approach, to guarantee safety and efficiency of the robot. We further present an informative path planning method, leveraging the capabilities of our mapping approach and a novel scene-completion-aware information gain. While our method is generally applicable, we evaluate it in the use case of a Micro Aerial Vehicle (MAV). We thoroughly study each component in high-fidelity simulation experiments using only mobile hardware, and show that our method can speed up coverage of an environment by 73% compared to the baselines with only minimal reduction in map accuracy. Even if scene completions are not included in the final map, we show that they can be used to guide the robot to choose more informative paths, speeding up the measurement of the scene with the robot's sensors by 35%. We make our methods available as open-source.