 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic-Aware Autonomous Exploration in Populated Environments
Apr 06, 2021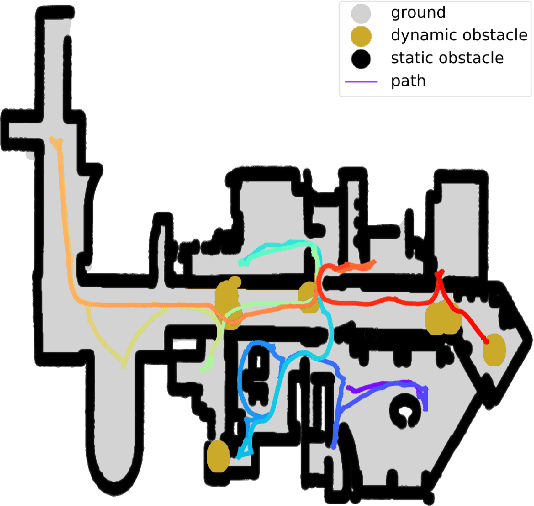

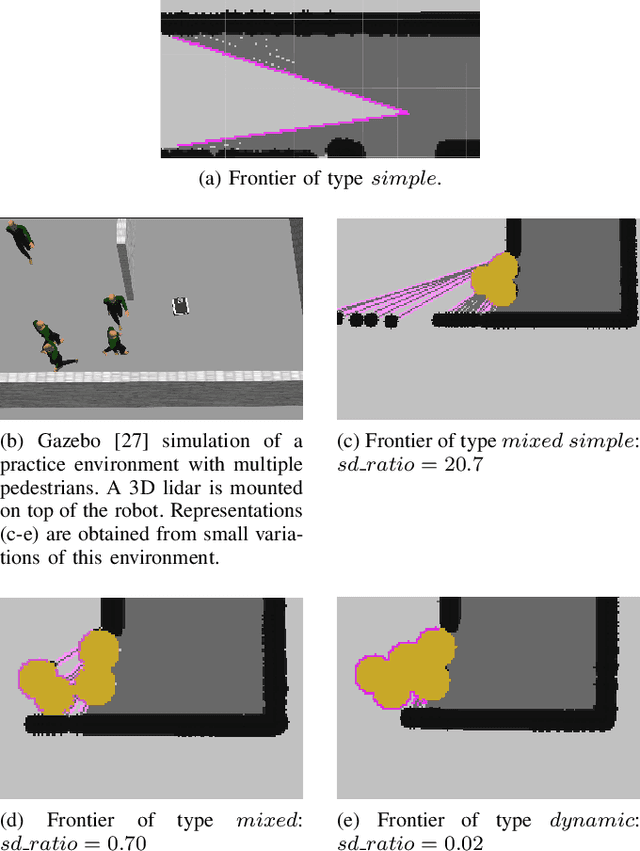

Autonomous exploration allows mobile robots to navigate in initially unknown territories in order to build complete representations of the environments. In many real-life applications, environments often contain dynamic obstacles which can compromise the exploration process by temporarily blocking passages, narrow paths, exits or entrances to other areas yet to be explored. In this work, we formulate a novel exploration strategy capable of explicitly handling dynamic obstacles, thus leading to complete and reliable exploration outcomes in populated environments. We introduce the concept of dynamic frontiers to represent unknown regions at the boundaries with dynamic obstacles together with a cost function which allows the robot to make informed decisions about when to revisit such frontiers. We evaluate the proposed strategy in challenging simulated environments and show that it outperforms a state-of-the-art baseline in these populated scenarios.
SD-6DoF-ICLK: Sparse and Deep Inverse Compositional Lucas-Kanade Algorithm on SE
Mar 30, 2021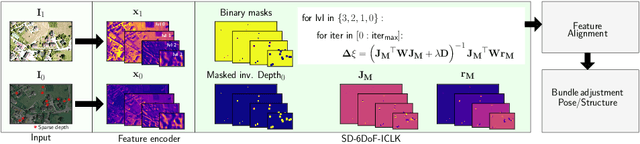


This paper introduces SD-6DoF-ICLK, a learning-based Inverse Compositional Lucas-Kanade (ICLK) pipeline that uses sparse depth information to optimize the relative pose that best aligns two images on SE(3). To compute this six Degrees-of-Freedom (DoF) relative transformation, the proposed formulation requires only sparse depth information in one of the images, which is often the only available depth source in visual-inertial odometry or Simultaneous Localization and Mapping (SLAM) pipelines. In an optional subsequent step, the framework further refines feature locations and the relative pose using individual feature alignment and bundle adjustment for pose and structure re-alignment. The resulting sparse point correspondences with subpixel-accuracy and refined relative pose can be used for depth map generation, or the image alignment module can be embedded in an odometry or mapping framework. Experiments with rendered imagery show that the forward SD-6DoF-ICLK runs at 145 ms per image pair with a resolution of 752 x 480 pixels each, and vastly outperforms the classical, sparse 6DoF-ICLK algorithm, making it the ideal framework for robust image alignment under severe conditions.
Online Informative Path Planning for Active Information Gathering of a 3D Surface
Mar 17, 2021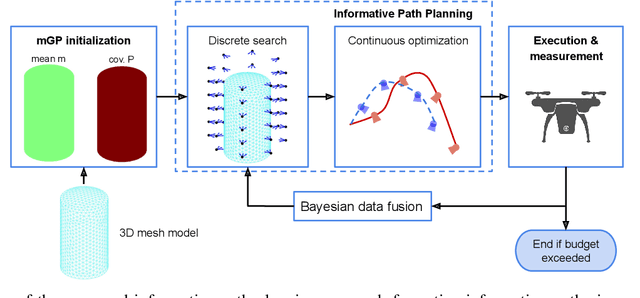
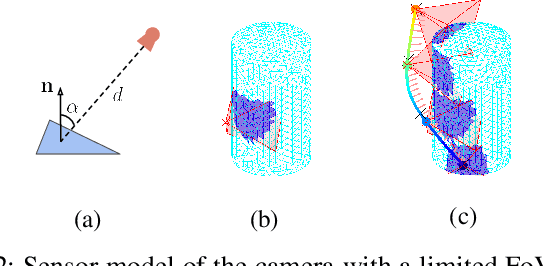
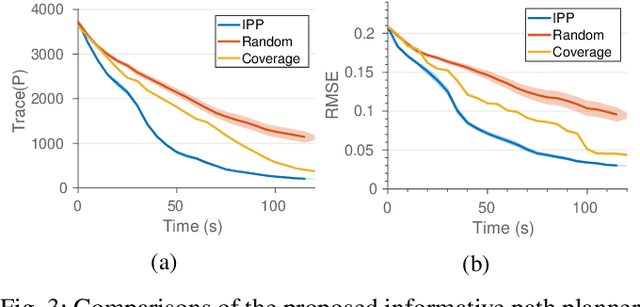
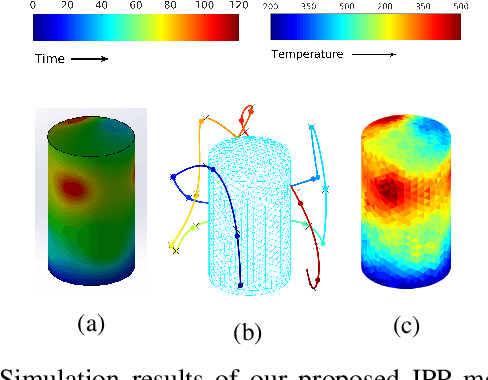
This paper presents an online informative path planning approach for active information gathering on three-dimensional surfaces using aerial robots. Most existing works on surface inspection focus on planning a path offline that can provide full coverage of the surface, which inherently assumes the surface information is uniformly distributed hence ignoring potential spatial correlations of the information field. In this paper, we utilize manifold Gaussian processes (mGPs) with geodesic kernel functions for mapping surface information fields and plan informative paths online in a receding horizon manner. Our approach actively plans information-gathering paths based on recent observations that respect dynamic constraints of the vehicle and a total flight time budget. We provide planning results for simulated temperature modeling for simple and complex 3D surface geometries (a cylinder and an aircraft model). We demonstrate that our informative planning method outperforms traditional approaches such as 3D coverage planning and random exploration, both in reconstruction error and information-theoretic metrics. We also show that by taking spatial correlations of the information field into planning using mGPs, the information gathering efficiency is significantly improved.
Pixel-wise Anomaly Detection in Complex Driving Scenes
Mar 09, 2021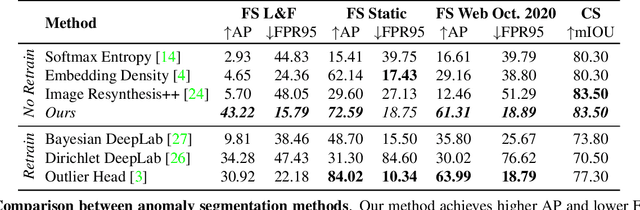
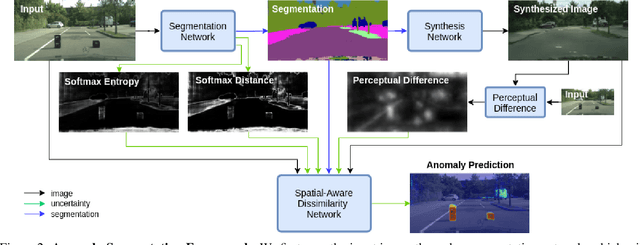
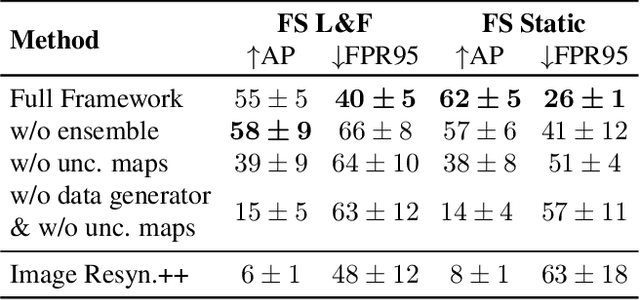
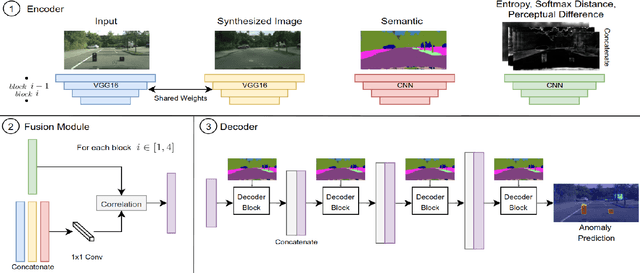
The inability of state-of-the-art semantic segmentation methods to detect anomaly instances hinders them from being deployed in safety-critical and complex applications, such as autonomous driving. Recent approaches have focused on either leveraging segmentation uncertainty to identify anomalous areas or re-synthesizing the image from the semantic label map to find dissimilarities with the input image. In this work, we demonstrate that these two methodologies contain complementary information and can be combined to produce robust predictions for anomaly segmentation. We present a pixel-wise anomaly detection framework that uses uncertainty maps to improve over existing re-synthesis methods in finding dissimilarities between the input and generated images. Our approach works as a general framework around already trained segmentation networks, which ensures anomaly detection without compromising segmentation accuracy, while significantly outperforming all similar methods. Top-2 performance across a range of different anomaly datasets shows the robustness of our approach to handling different anomaly instances.
Mesh Manifold based Riemannian Motion Planning for Omnidirectional Micro Aerial Vehicles
Feb 20, 2021
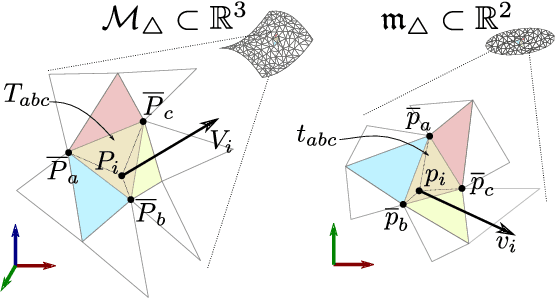

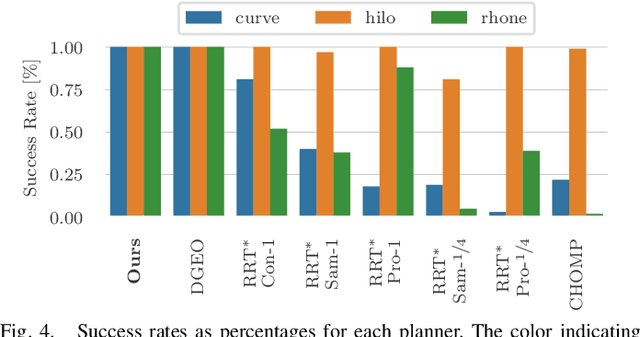
This paper presents a novel on-line path planning method that enables aerial robots to interact with surfaces. We present a solution to the problem of finding trajectories that drive a robot towards a surface and move along it. Triangular meshes are used as a surface map representation that is free of fixed discretization and allows for very large workspaces. We propose to leverage planar parametrization methods to obtain a lower-dimensional topologically equivalent representation of the original surface. Furthermore, we interpret the original surface and its lower-dimensional representation as manifold approximations that allow the use of Riemannian Motion Policies (RMPs), resulting in an efficient, versatile, and elegant motion generation framework. We compare against several Rapidly-exploring Random Tree (RRT) planners, a customized CHOMP variant, and the discrete geodesic algorithm. Using extensive simulations on real-world data we show that the proposed planner can reliably plan high-quality near-optimal trajectories at minimal computational cost. The accompanying multimedia attachment demonstrates feasibility on a real OMAV. The obtained paths show less than 10% deviation from the theoretical optimum while facilitating reactive re-planning at kHz refresh rates, enabling flying robots to perform motion planning for interaction with complex surfaces.
Hough2Map -- Iterative Event-based Hough Transform for High-Speed Railway Mapping
Feb 18, 2021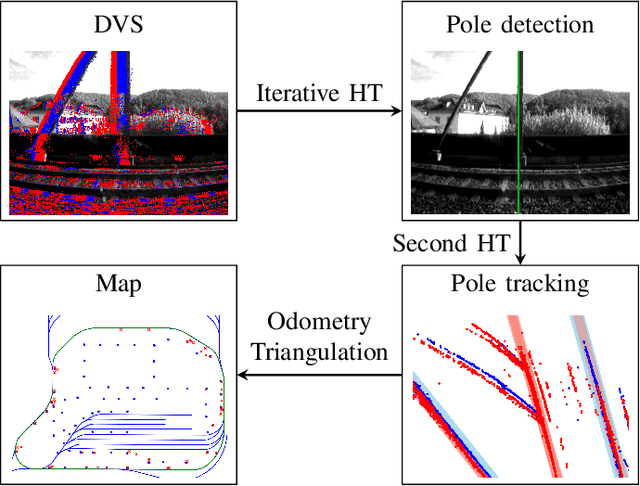

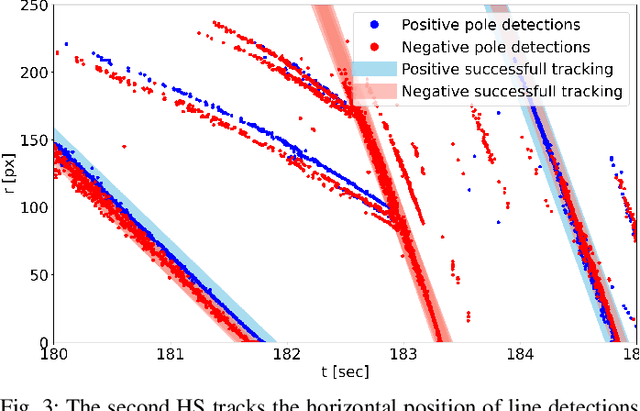

To cope with the growing demand for transportation on the railway system, accurate, robust, and high-frequency positioning is required to enable a safe and efficient utilization of the existing railway infrastructure. As a basis for a localization system we propose a complete on-board mapping pipeline able to map robust meaningful landmarks, such as poles from power lines, in the vicinity of the vehicle. Such poles are good candidates for reliable and long term landmarks even through difficult weather conditions or seasonal changes. To address the challenges of motion blur and illumination changes in railway scenarios we employ a Dynamic Vision Sensor, a novel event-based camera. Using a sideways oriented on-board camera, poles appear as vertical lines. To map such lines in a real-time event stream, we introduce Hough2Map, a novel consecutive iterative event-based Hough transform framework capable of detecting, tracking, and triangulating close-by structures. We demonstrate the mapping reliability and accuracy of Hough2Map on real-world data in typical usage scenarios and evaluate using surveyed infrastructure ground truth maps. Hough2Map achieves a detection reliability of up to 92% and a mapping root mean square error accuracy of 1.1518m.
Points2Vec: Unsupervised Object-level Feature Learning from Point Clouds
Feb 08, 2021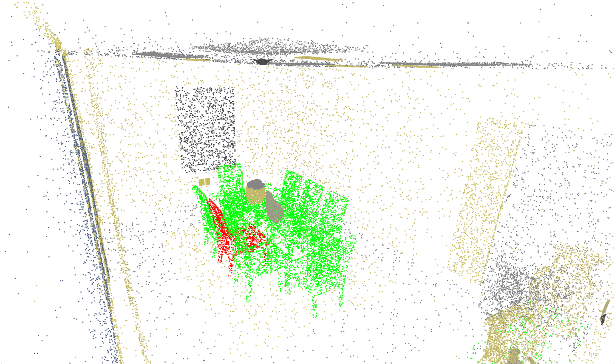
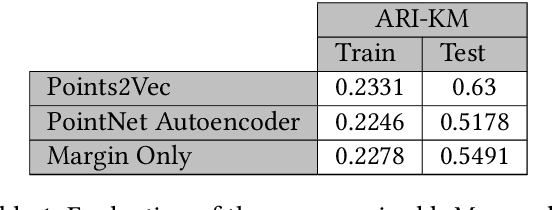
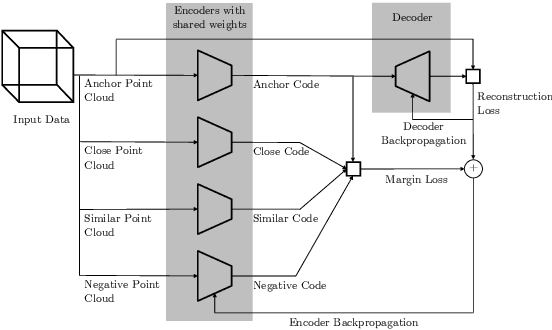
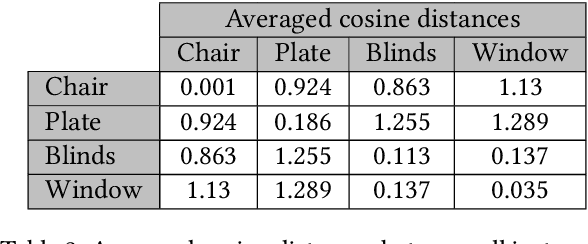
Unsupervised representation learning techniques, such as learning word embeddings, have had a significant impact on the field of natural language processing. Similar representation learning techniques have not yet become commonplace in the context of 3D vision. This, despite the fact that the physical 3D spaces have a similar semantic structure to bodies of text: words are surrounded by words that are semantically related, just like objects are surrounded by other objects that are similar in concept and usage. In this work, we exploit this structure in learning semantically meaningful low dimensional vector representations of objects. We learn these vector representations by mining a dataset of scanned 3D spaces using an unsupervised algorithm. We represent objects as point clouds, a flexible and general representation for 3D data, which we encode into a vector representation. We show that using our method to include context increases the ability of a clustering algorithm to distinguish different semantic classes from each other. Furthermore, we show that our algorithm produces continuous and meaningful object embeddings through interpolation experiments.
PHASER: a Robust and Correspondence-free Global Pointcloud Registration
Feb 03, 2021
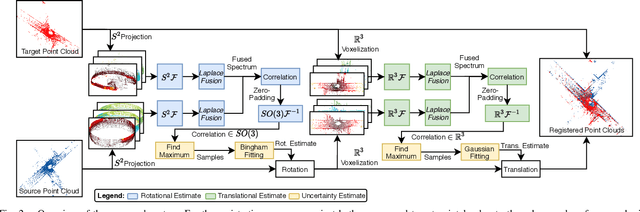
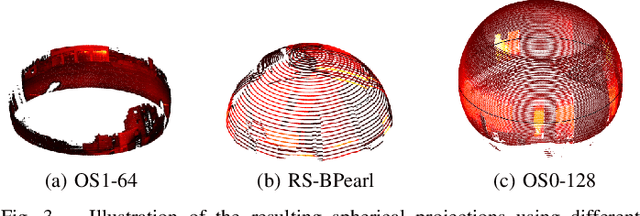
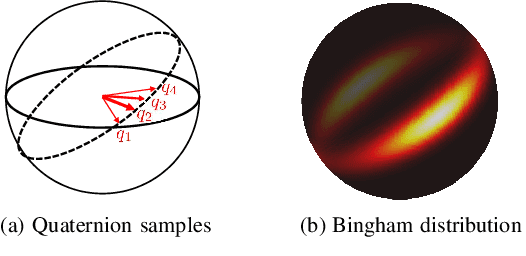
We propose PHASER, a correspondence-free global registration of sensor-centric pointclouds that is robust to noise, sparsity, and partial overlaps. Our method can seamlessly handle multimodal information and does not rely on keypoint nor descriptor preprocessing modules. By exploiting properties of Fourier analysis, PHASER operates directly on the sensor's signal, fusing the spectra of multiple channels and computing the 6-DoF transformation based on correlation. Our registration pipeline starts by finding the most likely rotation followed by computing the most likely translation. Both estimates are distributed according to a probability distribution that takes the underlying manifold into account, i.e., a Bingham and Gaussian distribution, respectively. This further allows our approach to consider the periodic-nature of rotations and naturally represent its uncertainty. We extensively compare PHASER against several well-known registration algorithms on both simulated datasets, and real-world data acquired using different sensor configurations. Our results show that PHASER can globally align pointclouds in less than 100ms with an average accuracy of 2cm and 0.5deg, is resilient against noise, and can handle partial overlap.
Active Model Learning using Informative Trajectories for Improved Closed-Loop Control on Real Robots
Jan 20, 2021
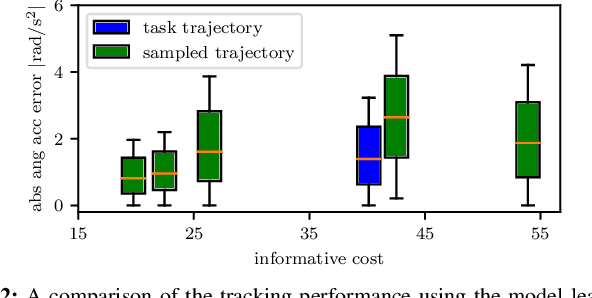
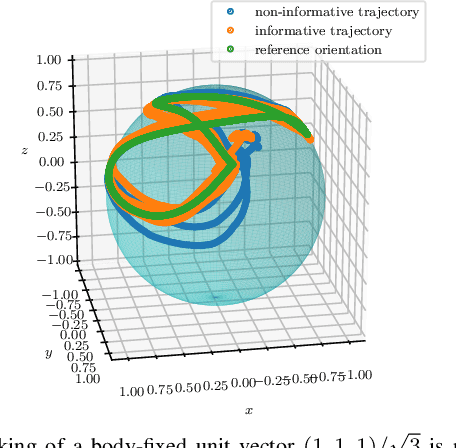
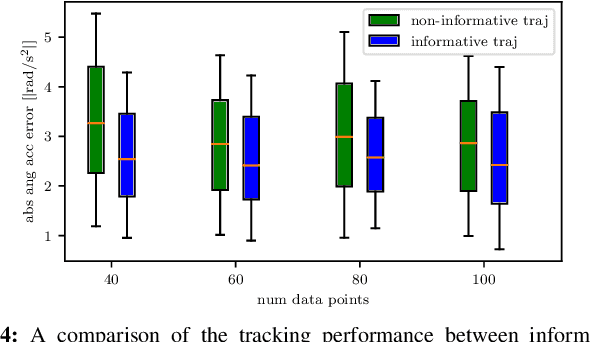
Model-based controllers on real robots require accurate knowledge of the system dynamics to perform optimally. For complex dynamics, first-principles modeling is not sufficiently precise, and data-driven approaches can be leveraged to learn a statistical model from real experiments. However, the efficient and effective data collection for such a data-driven system on real robots is still an open challenge. This paper introduces an optimization problem formulation to find an informative trajectory that allows for efficient data collection and model learning. We present a sampling-based method that computes an approximation of the trajectory that minimizes the prediction uncertainty of the dynamics model. This trajectory is then executed, collecting the data to update the learned model. In experiments we demonstrate the capabilities of our proposed framework when applied to a complex omnidirectional flying vehicle with tiltable rotors. Using our informative trajectories results in models which outperform models obtained from non-informative trajectory by 13.3\% with the same amount of training data. Furthermore, we show that the model learned from informative trajectories generalizes better than the one learned from non-informative trajectories, achieving better tracking performance on different tasks.
Volumetric Grasping Network: Real-time 6 DOF Grasp Detection in Clutter
Jan 04, 2021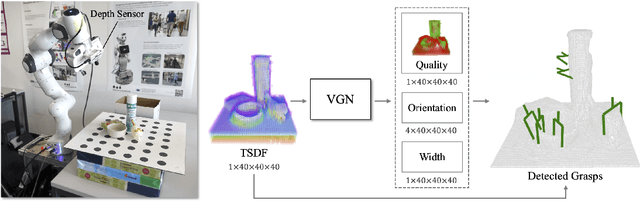
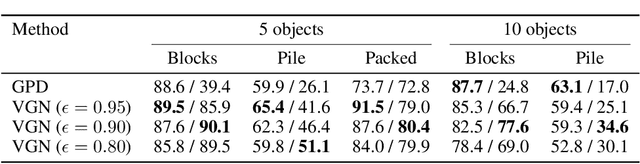
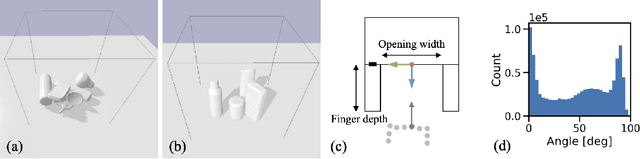

General robot grasping in clutter requires the ability to synthesize grasps that work for previously unseen objects and that are also robust to physical interactions, such as collisions with other objects in the scene. In this work, we design and train a network that predicts 6 DOF grasps from 3D scene information gathered from an on-board sensor such as a wrist-mounted depth camera. Our proposed Volumetric Grasping Network (VGN) accepts a Truncated Signed Distance Function (TSDF) representation of the scene and directly outputs the predicted grasp quality and the associated gripper orientation and opening width for each voxel in the queried 3D volume. We show that our approach can plan grasps in only 10 ms and is able to clear 92% of the objects in real-world clutter removal experiments without the need for explicit collision checking. The real-time capability opens up the possibility for closed-loop grasp planning, allowing robots to handle disturbances, recover from errors and provide increased robustness. Code is available at https://github.com/ethz-asl/vgn.