 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSParC: Cross-Domain Semantic Parsing in Context
Jun 05, 2019
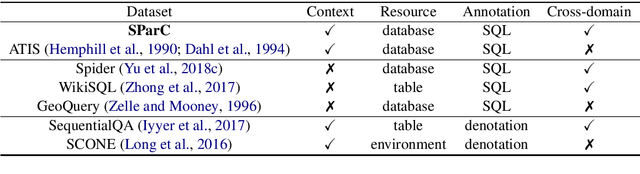

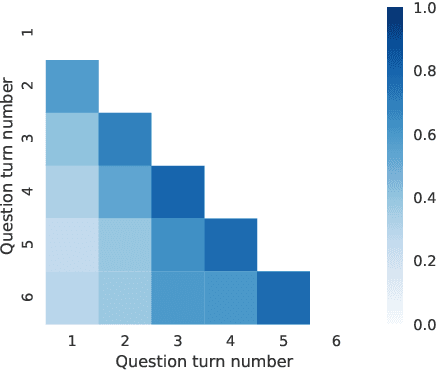
We present SParC, a dataset for cross-domainSemanticParsing inContext that consists of 4,298 coherent question sequences (12k+ individual questions annotated with SQL queries). It is obtained from controlled user interactions with 200 complex databases over 138 domains. We provide an in-depth analysis of SParC and show that it introduces new challenges compared to existing datasets. SParC demonstrates complex contextual dependencies, (2) has greater semantic diversity, and (3) requires generalization to unseen domains due to its cross-domain nature and the unseen databases at test time. We experiment with two state-of-the-art text-to-SQL models adapted to the context-dependent, cross-domain setup. The best model obtains an exact match accuracy of 20.2% over all questions and less than10% over all interaction sequences, indicating that the cross-domain setting and the con-textual phenomena of the dataset present significant challenges for future research. The dataset, baselines, and leaderboard are released at https://yale-lily.github.io/sparc.
On the Generalization Gap in Reparameterizable Reinforcement Learning
May 29, 2019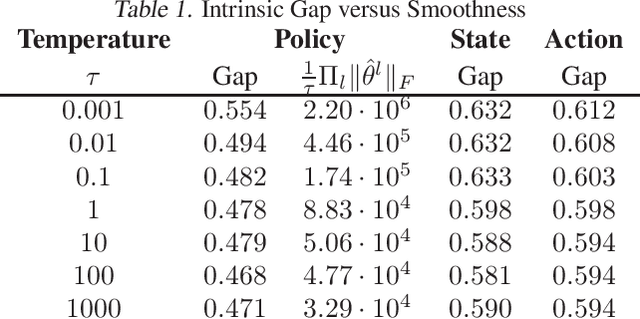
Understanding generalization in reinforcement learning (RL) is a significant challenge, as many common assumptions of traditional supervised learning theory do not apply. We focus on the special class of reparameterizable RL problems, where the trajectory distribution can be decomposed using the reparametrization trick. For this problem class, estimating the expected return is efficient and the trajectory can be computed deterministically given peripheral random variables, which enables us to study reparametrizable RL using supervised learning and transfer learning theory. Through these relationships, we derive guarantees on the gap between the expected and empirical return for both intrinsic and external errors, based on Rademacher complexity as well as the PAC-Bayes bound. Our bound suggests the generalization capability of reparameterizable RL is related to multiple factors including "smoothness" of the environment transition, reward and agent policy function class. We also empirically verify the relationship between the generalization gap and these factors through simulations.
XLDA: Cross-Lingual Data Augmentation for Natural Language Inference and Question Answering
May 27, 2019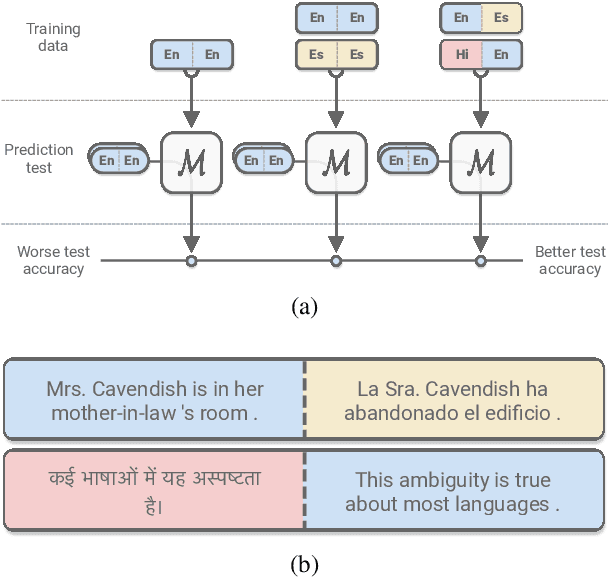
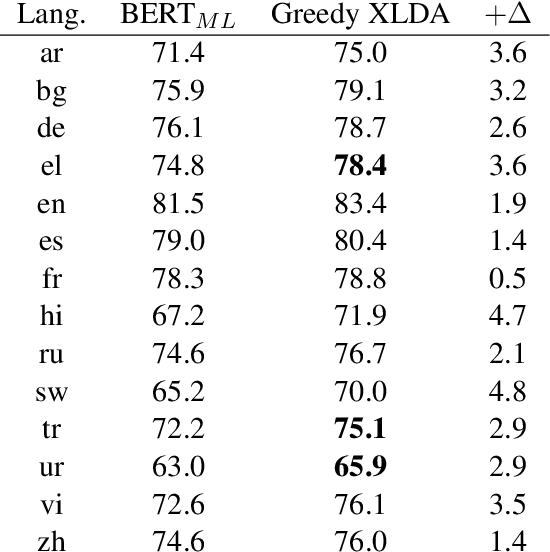
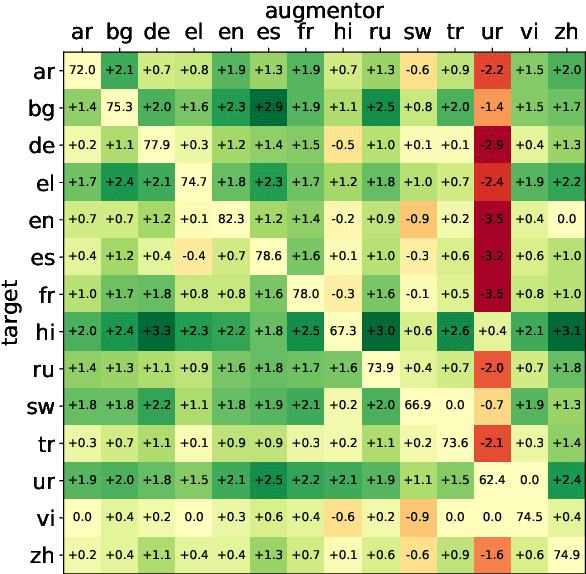
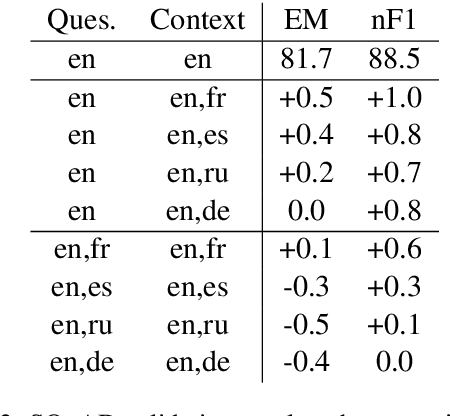
While natural language processing systems often focus on a single language, multilingual transfer learning has the potential to improve performance, especially for low-resource languages. We introduce XLDA, cross-lingual data augmentation, a method that replaces a segment of the input text with its translation in another language. XLDA enhances performance of all 14 tested languages of the cross-lingual natural language inference (XNLI) benchmark. With improvements of up to $4.8\%$, training with XLDA achieves state-of-the-art performance for Greek, Turkish, and Urdu. XLDA is in contrast to, and performs markedly better than, a more naive approach that aggregates examples in various languages in a way that each example is solely in one language. On the SQuAD question answering task, we see that XLDA provides a $1.0\%$ performance increase on the English evaluation set. Comprehensive experiments suggest that most languages are effective as cross-lingual augmentors, that XLDA is robust to a wide range of translation quality, and that XLDA is even more effective for randomly initialized models than for pretrained models.
Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems
May 26, 2019
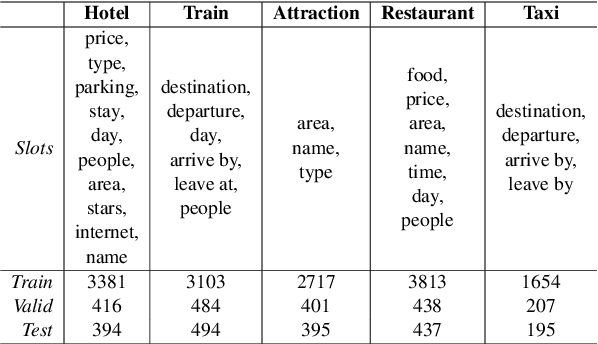
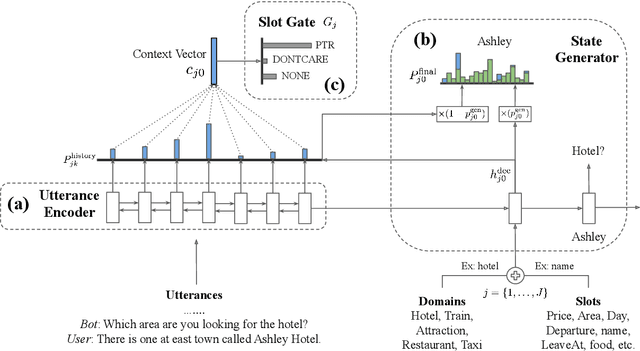
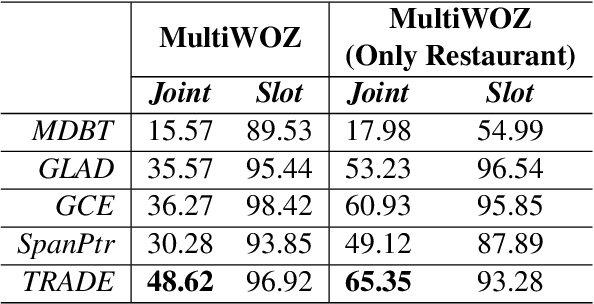
Over-dependence on domain ontology and lack of knowledge sharing across domains are two practical and yet less studied problems of dialogue state tracking. Existing approaches generally fall short in tracking unknown slot values during inference and often have difficulties in adapting to new domains. In this paper, we propose a Transferable Dialogue State Generator (TRADE) that generates dialogue states from utterances using a copy mechanism, facilitating knowledge transfer when predicting (domain, slot, value) triplets not encountered during training. Our model is composed of an utterance encoder, a slot gate, and a state generator, which are shared across domains. Empirical results demonstrate that TRADE achieves state-of-the-art joint goal accuracy of 48.62% for the five domains of MultiWOZ, a human-human dialogue dataset. In addition, we show its transferring ability by simulating zero-shot and few-shot dialogue state tracking for unseen domains. TRADE achieves 60.58% joint goal accuracy in one of the zero-shot domains, and is able to adapt to few-shot cases without forgetting already trained domains.
Learn to Grow: A Continual Structure Learning Framework for Overcoming Catastrophic Forgetting
May 21, 2019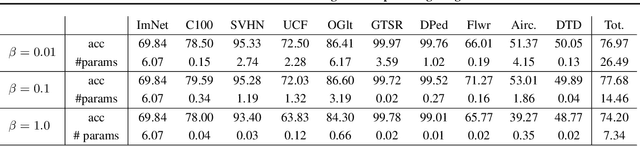
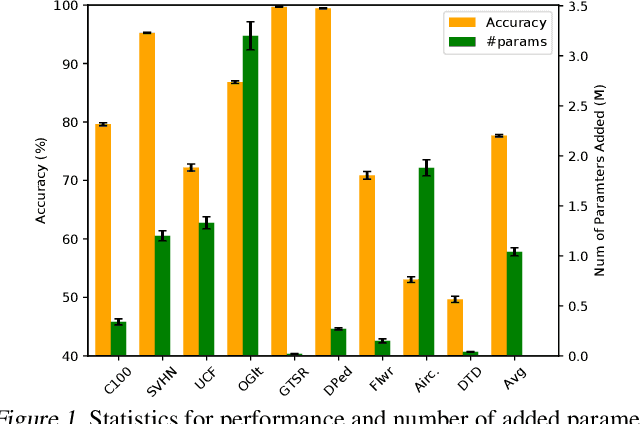
Addressing catastrophic forgetting is one of the key challenges in continual learning where machine learning systems are trained with sequential or streaming tasks. Despite recent remarkable progress in state-of-the-art deep learning, deep neural networks (DNNs) are still plagued with the catastrophic forgetting problem. This paper presents a conceptually simple yet general and effective framework for handling catastrophic forgetting in continual learning with DNNs. The proposed method consists of two components: a neural structure optimization component and a parameter learning and/or fine-tuning component. By separating the explicit neural structure learning and the parameter estimation, not only is the proposed method capable of evolving neural structures in an intuitively meaningful way, but also shows strong capabilities of alleviating catastrophic forgetting in experiments. Furthermore, the proposed method outperforms all other baselines on the permuted MNIST dataset, the split CIFAR100 dataset and the Visual Domain Decathlon dataset in continual learning setting.
Unifying Question Answering and Text Classification via Span Extraction
Apr 19, 2019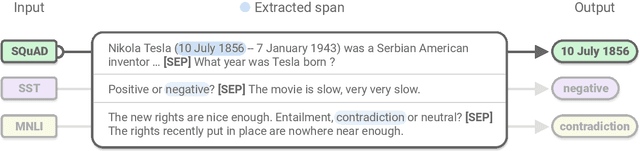

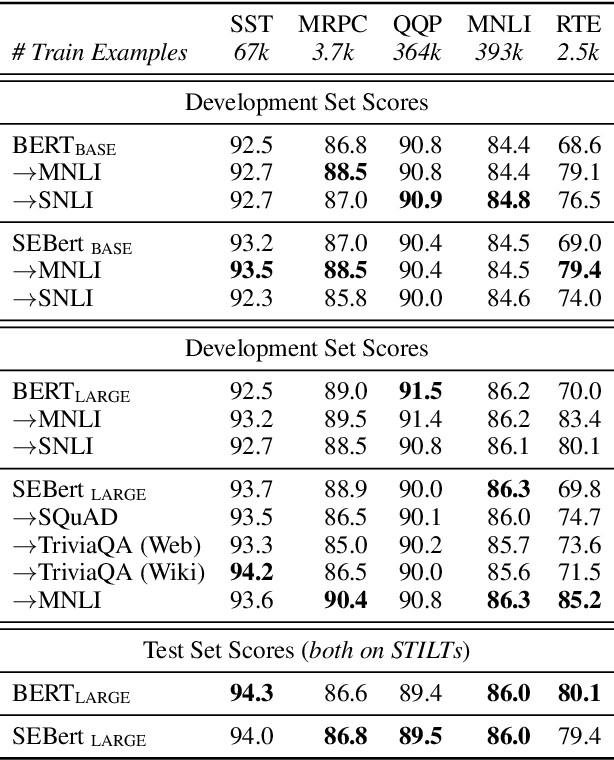

Even as pre-trained language encoders such as BERT are shared across many tasks, the output layers of question answering and text classification models are significantly different. Span decoders are frequently used for question answering and fixed-class, classification layers for text classification. We show that this distinction is not necessary, and that both can be unified as span extraction. A unified, span-extraction approach leads to superior or comparable performance in multi-task learning, low-data and supplementary supervised pretraining experiments on several text classification and question answering benchmarks.
Genie: A Generator of Natural Language Semantic Parsers for Virtual Assistant Commands
Apr 18, 2019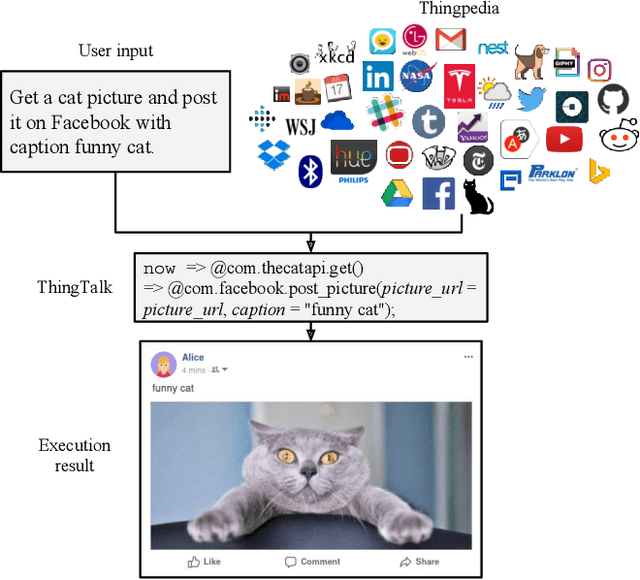
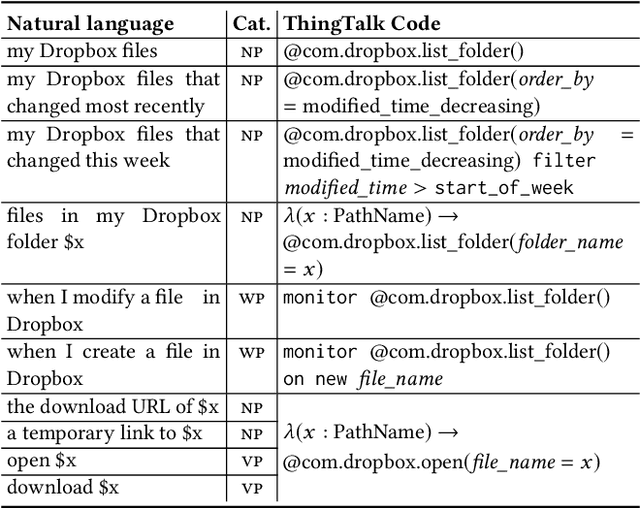
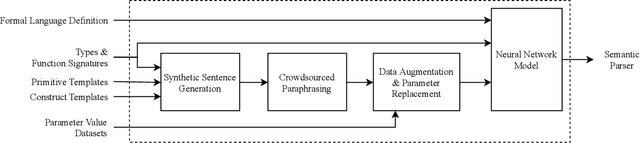

To understand diverse natural language commands, virtual assistants today are trained with numerous labor-intensive, manually annotated sentences. This paper presents a methodology and the Genie toolkit that can handle new compound commands with significantly less manual effort. We advocate formalizing the capability of virtual assistants with a Virtual Assistant Programming Language (VAPL) and using a neural semantic parser to translate natural language into VAPL code. Genie needs only a small realistic set of input sentences for validating the neural model. Developers write templates to synthesize data; Genie uses crowdsourced paraphrases and data augmentation, along with the synthesized data, to train a semantic parser. We also propose design principles that make VAPL languages amenable to natural language translation. We apply these principles to revise ThingTalk, the language used by the Almond virtual assistant. We use Genie to build the first semantic parser that can support compound virtual assistants commands with unquoted free-form parameters. Genie achieves a 62% accuracy on realistic user inputs. We demonstrate Genie's generality by showing a 19% and 31% improvement over the previous state of the art on a music skill, aggregate functions, and access control.
StartNet: Online Detection of Action Start in Untrimmed Videos
Mar 23, 2019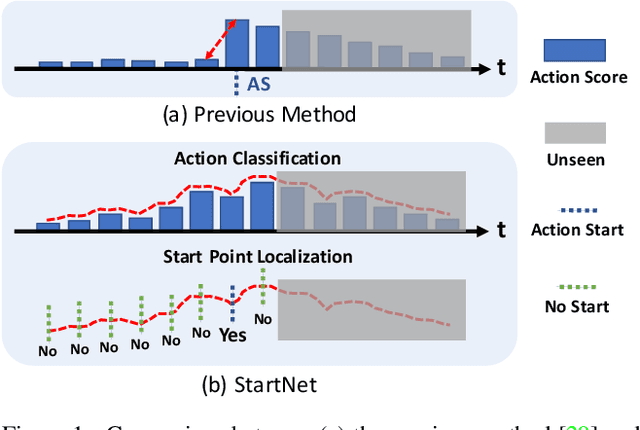
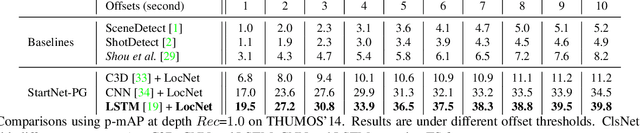
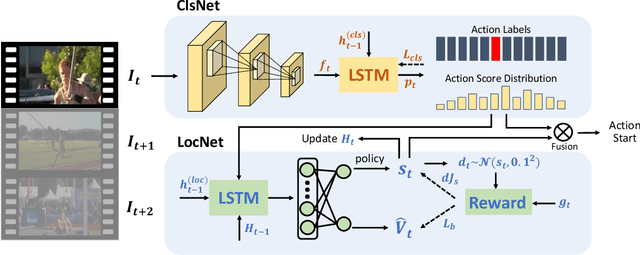

We propose StartNet to address Online Detection of Action Start (ODAS) where action starts and their associated categories are detected in untrimmed, streaming videos. Previous methods aim to localize action starts by learning feature representations that can directly separate the start point from its preceding background. It is challenging due to the subtle appearance difference near the action starts and the lack of training data. Instead, StartNet decomposes ODAS into two stages: action classification (using ClsNet) and start point localization (using LocNet). ClsNet focuses on per-frame labeling and predicts action score distributions online. Based on the predicted action scores of the past and current frames, LocNet conducts class-agnostic start detection by optimizing long-term localization rewards using policy gradient methods. The proposed framework is validated on two large-scale datasets, THUMOS'14 and ActivityNet. The experimental results show that StartNet significantly outperforms the state-of-the-art by 15%-30% p-mAP under the offset tolerance of 1-10 seconds on THUMOS'14, and achieves comparable performance on ActivityNet with 10 times smaller time offset.
Competitive Experience Replay
Feb 17, 2019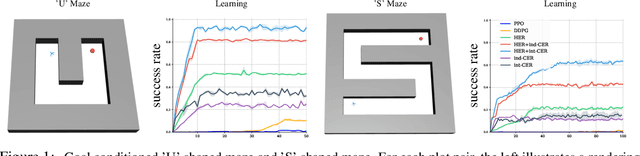
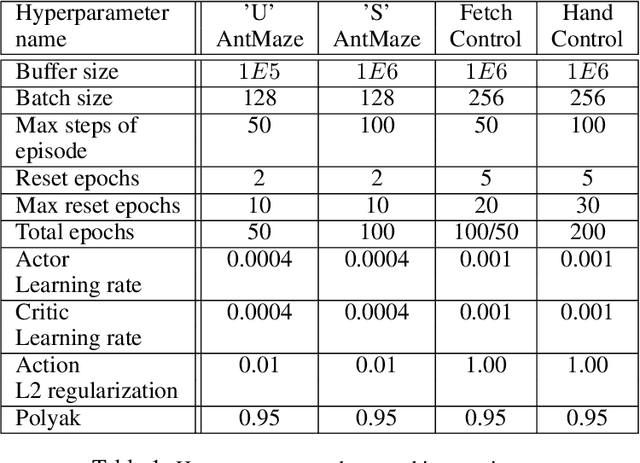
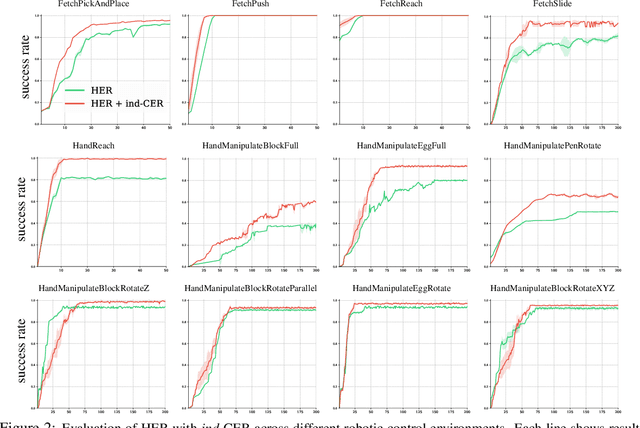
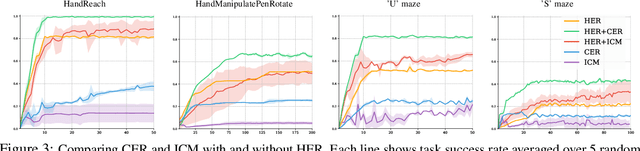
Deep learning has achieved remarkable successes in solving challenging reinforcement learning (RL) problems when dense reward function is provided. However, in sparse reward environment it still often suffers from the need to carefully shape reward function to guide policy optimization. This limits the applicability of RL in the real world since both reinforcement learning and domain-specific knowledge are required. It is therefore of great practical importance to develop algorithms which can learn from a binary signal indicating successful task completion or other unshaped, sparse reward signals. We propose a novel method called competitive experience replay, which efficiently supplements a sparse reward by placing learning in the context of an exploration competition between a pair of agents. Our method complements the recently proposed hindsight experience replay (HER) by inducing an automatic exploratory curriculum. We evaluate our approach on the tasks of reaching various goal locations in an ant maze and manipulating objects with a robotic arm. Each task provides only binary rewards indicating whether or not the goal is achieved. Our method asymmetrically augments these sparse rewards for a pair of agents each learning the same task, creating a competitive game designed to drive exploration. Extensive experiments demonstrate that this method leads to faster converge and improved task performance.
Global-to-local Memory Pointer Networks for Task-Oriented Dialogue
Jan 15, 2019
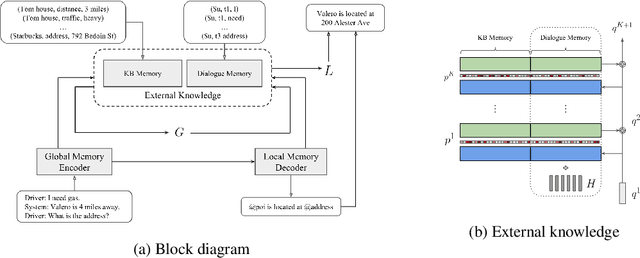
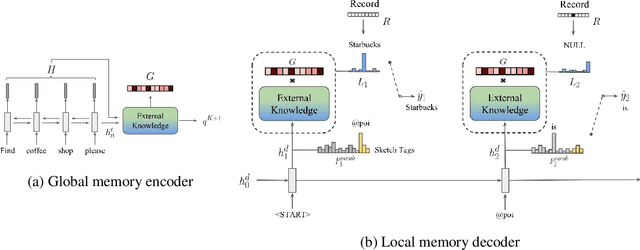
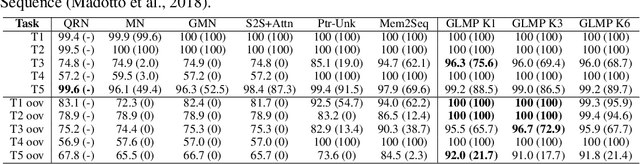
End-to-end task-oriented dialogue is challenging since knowledge bases are usually large, dynamic and hard to incorporate into a learning framework. We propose the global-to-local memory pointer (GLMP) networks to address this issue. In our model, a global memory encoder and a local memory decoder are proposed to share external knowledge. The encoder encodes dialogue history, modifies global contextual representation, and generates a global memory pointer. The decoder first generates a sketch response with unfilled slots. Next, it passes the global memory pointer to filter the external knowledge for relevant information, then instantiates the slots via the local memory pointers. We empirically show that our model can improve copy accuracy and mitigate the common out-of-vocabulary problem. As a result, GLMP is able to improve over the previous state-of-the-art models in both simulated bAbI Dialogue dataset and human-human Stanford Multi-domain Dialogue dataset on automatic and human evaluation.