 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Extra RMSNorm is All You Need for Fine Tuning to 1.58 Bits
May 12, 2025Large language models (LLMs) have transformed natural-language processing, yet their scale makes real-world deployment costly. Post-training quantization reduces memory and computation but often degrades accuracy, while quantization-aware training can recover performance at the cost of extra training. Pushing quantization to the ternary (2-bit) regime yields even larger savings but is notoriously unstable. Building on recent work showing that a bias-free, RMS-normalized Transformer with straight-through estimation can reach 1.58-bit precision, we demonstrate that simply inserting RMS normalization before every linear projection and applying a gradual, layer-wise quantization schedule stably fine-tunes full-precision checkpoints into ternary LLMs. Our approach matches or surpasses more elaborate knowledge-distillation pipelines on standard language-modeling benchmarks without adding model complexity. These results indicate that careful normalization alone can close much of the accuracy gap between ternary and full-precision LLMs, making ultra-low-bit inference practical.
XLDA: Cross-Lingual Data Augmentation for Natural Language Inference and Question Answering
May 27, 2019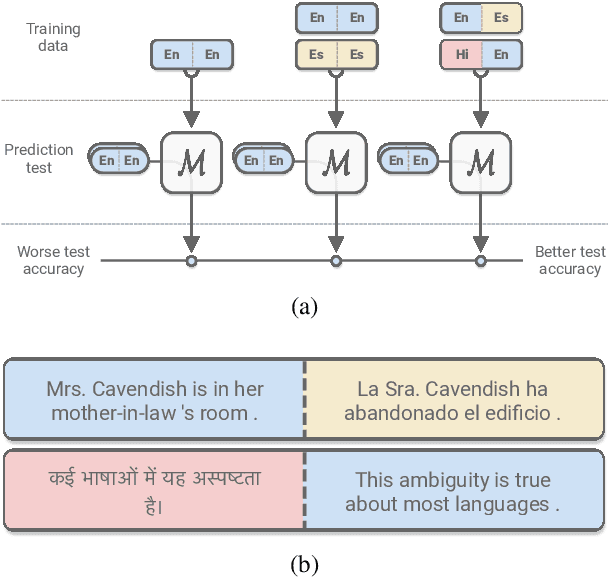
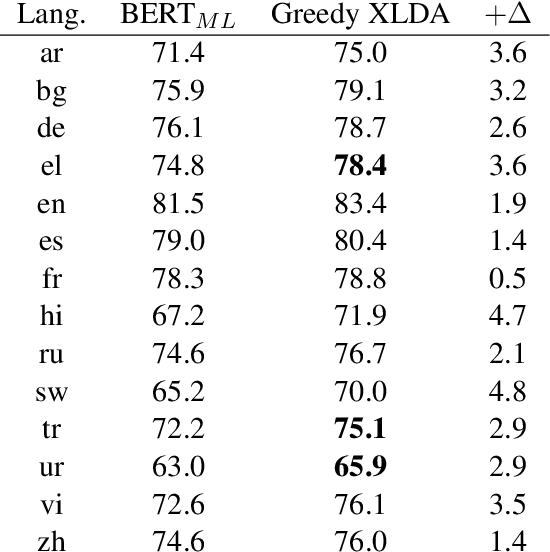
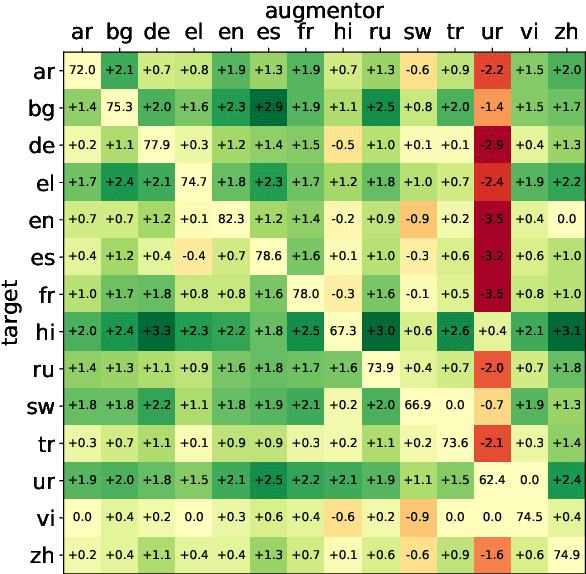
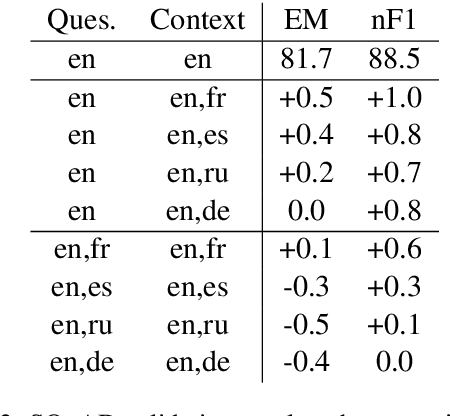
While natural language processing systems often focus on a single language, multilingual transfer learning has the potential to improve performance, especially for low-resource languages. We introduce XLDA, cross-lingual data augmentation, a method that replaces a segment of the input text with its translation in another language. XLDA enhances performance of all 14 tested languages of the cross-lingual natural language inference (XNLI) benchmark. With improvements of up to $4.8\%$, training with XLDA achieves state-of-the-art performance for Greek, Turkish, and Urdu. XLDA is in contrast to, and performs markedly better than, a more naive approach that aggregates examples in various languages in a way that each example is solely in one language. On the SQuAD question answering task, we see that XLDA provides a $1.0\%$ performance increase on the English evaluation set. Comprehensive experiments suggest that most languages are effective as cross-lingual augmentors, that XLDA is robust to a wide range of translation quality, and that XLDA is even more effective for randomly initialized models than for pretrained models.
Rethinking Radiology: An Analysis of Different Approaches to BraTS
Jun 06, 2018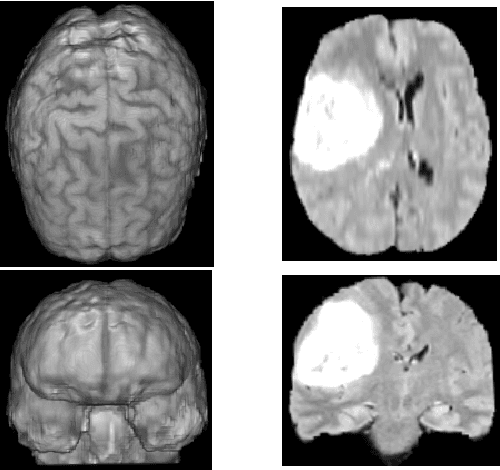

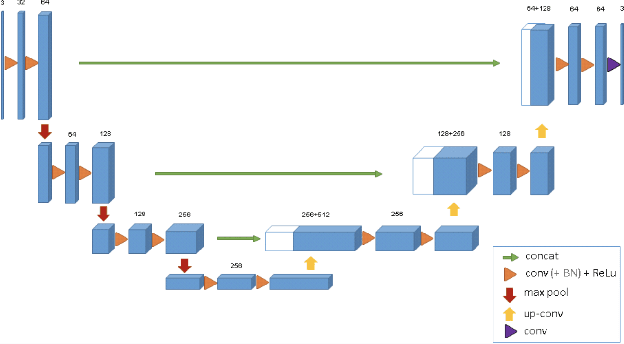
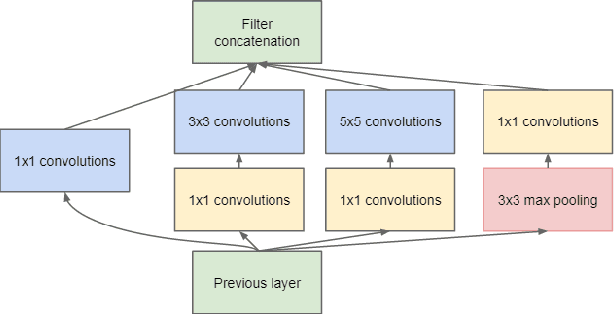
This paper discusses the deep learning architectures currently used for pixel-wise segmentation of primary and secondary glioblastomas and low-grade gliomas. We implement various models such as the popular UNet architecture and compare the performance of these implementations on the BRATS dataset. This paper will explore the different approaches and combinations, offering an in depth discussion of how they perform and how we may improve upon them using more recent advancements in deep learning architectures.
Attention on Attention: Architectures for Visual Question Answering (VQA)
Mar 21, 2018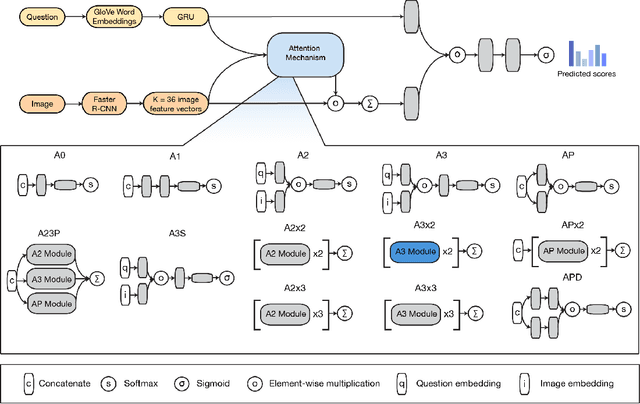
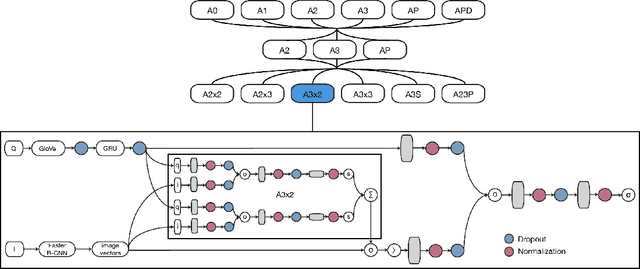
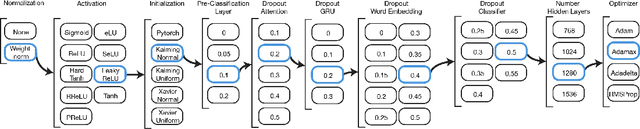
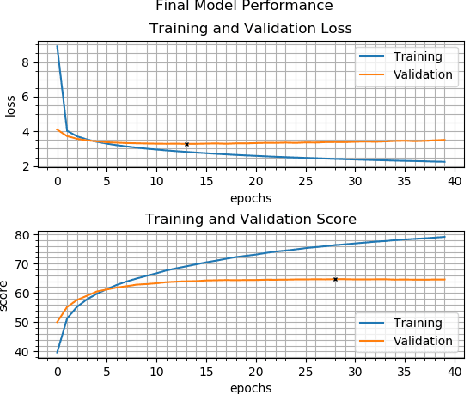
Visual Question Answering (VQA) is an increasingly popular topic in deep learning research, requiring coordination of natural language processing and computer vision modules into a single architecture. We build upon the model which placed first in the VQA Challenge by developing thirteen new attention mechanisms and introducing a simplified classifier. We performed 300 GPU hours of extensive hyperparameter and architecture searches and were able to achieve an evaluation score of 64.78%, outperforming the existing state-of-the-art single model's validation score of 63.15%.