 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertified Zeroth-order Black-Box Defense with Robust UNet Denoiser
Apr 13, 2023



Certified defense methods against adversarial perturbations have been recently investigated in the black-box setting with a zeroth-order (ZO) perspective. However, these methods suffer from high model variance with low performance on high-dimensional datasets due to the ineffective design of the denoiser and are limited in their utilization of ZO techniques. To this end, we propose a certified ZO preprocessing technique for removing adversarial perturbations from the attacked image in the black-box setting using only model queries. We propose a robust UNet denoiser (RDUNet) that ensures the robustness of black-box models trained on high-dimensional datasets. We propose a novel black-box denoised smoothing (DS) defense mechanism, ZO-RUDS, by prepending our RDUNet to the black-box model, ensuring black-box defense. We further propose ZO-AE-RUDS in which RDUNet followed by autoencoder (AE) is prepended to the black-box model. We perform extensive experiments on four classification datasets, CIFAR-10, CIFAR-10, Tiny Imagenet, STL-10, and the MNIST dataset for image reconstruction tasks. Our proposed defense methods ZO-RUDS and ZO-AE-RUDS beat SOTA with a huge margin of $35\%$ and $9\%$, for low dimensional (CIFAR-10) and with a margin of $20.61\%$ and $23.51\%$ for high-dimensional (STL-10) datasets, respectively.
Emotionally Enhanced Talking Face Generation
Mar 26, 2023



Several works have developed end-to-end pipelines for generating lip-synced talking faces with various real-world applications, such as teaching and language translation in videos. However, these prior works fail to create realistic-looking videos since they focus little on people's expressions and emotions. Moreover, these methods' effectiveness largely depends on the faces in the training dataset, which means they may not perform well on unseen faces. To mitigate this, we build a talking face generation framework conditioned on a categorical emotion to generate videos with appropriate expressions, making them more realistic and convincing. With a broad range of six emotions, i.e., \emph{happiness}, \emph{sadness}, \emph{fear}, \emph{anger}, \emph{disgust}, and \emph{neutral}, we show that our model can adapt to arbitrary identities, emotions, and languages. Our proposed framework is equipped with a user-friendly web interface with a real-time experience for talking face generation with emotions. We also conduct a user study for subjective evaluation of our interface's usability, design, and functionality. Project page: https://midas.iiitd.edu.in/emo/
Analysing the Masked predictive coding training criterion for pre-training a Speech Representation Model
Mar 13, 2023Recent developments in pre-trained speech representation utilizing self-supervised learning (SSL) have yielded exceptional results on a variety of downstream tasks. One such technique, known as masked predictive coding (MPC), has been employed by some of the most high-performing models. In this study, we investigate the impact of MPC loss on the type of information learnt at various layers in the HuBERT model, using nine probing tasks. Our findings indicate that the amount of content information learned at various layers of the HuBERT model has a positive correlation to the MPC loss. Additionally, it is also observed that any speaker-related information learned at intermediate layers of the model, is an indirect consequence of the learning process, and therefore cannot be controlled using the MPC loss. These findings may serve as inspiration for further research in the speech community, specifically in the development of new pre-training tasks or the exploration of new pre-training criterion's that directly preserves both speaker and content information at various layers of a learnt model.
H-AES: Towards Automated Essay Scoring for Hindi
Feb 28, 2023


The use of Natural Language Processing (NLP) for Automated Essay Scoring (AES) has been well explored in the English language, with benchmark models exhibiting performance comparable to human scorers. However, AES in Hindi and other low-resource languages remains unexplored. In this study, we reproduce and compare state-of-the-art methods for AES in the Hindi domain. We employ classical feature-based Machine Learning (ML) and advanced end-to-end models, including LSTM Networks and Fine-Tuned Transformer Architecture, in our approach and derive results comparable to those in the English language domain. Hindi being a low-resource language, lacks a dedicated essay-scoring corpus. We train and evaluate our models using translated English essays and empirically measure their performance on our own small-scale, real-world Hindi corpus. We follow this up with an in-depth analysis discussing prompt-specific behavior of different language models implemented.
On Testing and Comparing Fair classifiers under Data Bias
Feb 12, 2023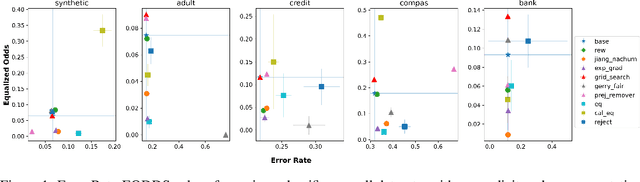
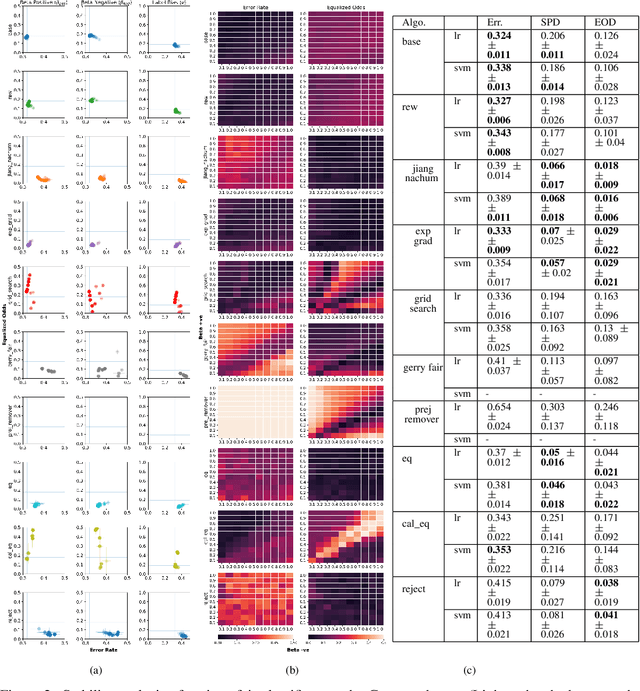
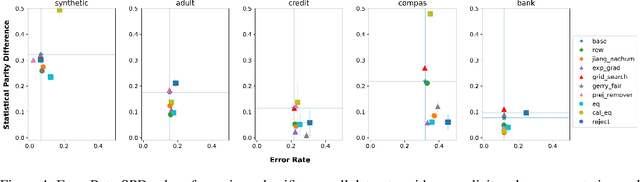
In this paper, we consider a theoretical model for injecting data bias, namely, under-representation and label bias (Blum & Stangl, 2019). We theoretically and empirically study its effect on the accuracy and fairness of fair classifiers. Theoretically, we prove that the Bayes optimal group-aware fair classifier on the original data distribution can be recovered by simply minimizing a carefully chosen reweighed loss on the bias-injected distribution. Through extensive experiments on both synthetic and real-world datasets (e.g., Adult, German Credit, Bank Marketing, COMPAS), we empirically audit pre-, in-, and post-processing fair classifiers from standard fairness toolkits for their fairness and accuracy by injecting varying amounts of under-representation and label bias in their training data (but not the test data). Our main observations are: (1) The fairness and accuracy of many standard fair classifiers degrade severely as the bias injected in their training data increases, (2) A simple logistic regression model trained on the right data can often outperform, in both accuracy and fairness, most fair classifiers trained on biased training data, and (3) A few, simple fairness techniques (e.g., reweighing, exponentiated gradients) seem to offer stable accuracy and fairness guarantees even when their training data is injected with under-representation and label bias. Our experiments also show how to integrate a measure of data bias risk in the existing fairness dashboards for real-world deployments
A novel multimodal dynamic fusion network for disfluency detection in spoken utterances
Nov 27, 2022Disfluency, though originating from human spoken utterances, is primarily studied as a uni-modal text-based Natural Language Processing (NLP) task. Based on early-fusion and self-attention-based multimodal interaction between text and acoustic modalities, in this paper, we propose a novel multimodal architecture for disfluency detection from individual utterances. Our architecture leverages a multimodal dynamic fusion network that adds minimal parameters over an existing text encoder commonly used in prior art to leverage the prosodic and acoustic cues hidden in speech. Through experiments, we show that our proposed model achieves state-of-the-art results on the widely used English Switchboard for disfluency detection and outperforms prior unimodal and multimodal systems in literature by a significant margin. In addition, we make a thorough qualitative analysis and show that, unlike text-only systems, which suffer from spurious correlations in the data, our system overcomes this problem through additional cues from speech signals. We make all our codes publicly available on GitHub.
GANTouch: An Attack-Resilient Framework for Touch-based Continuous Authentication System
Oct 02, 2022
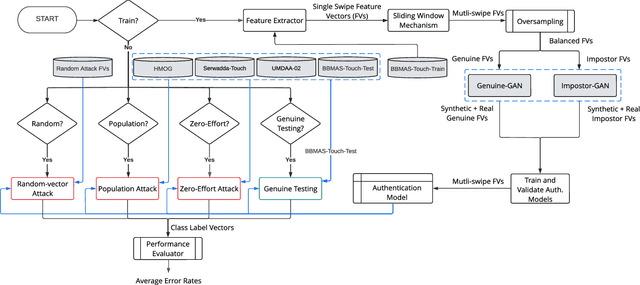
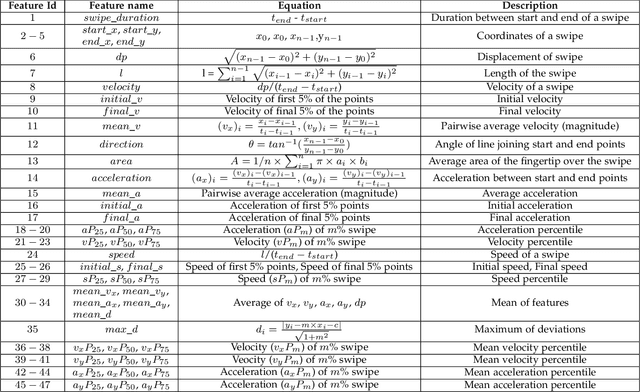
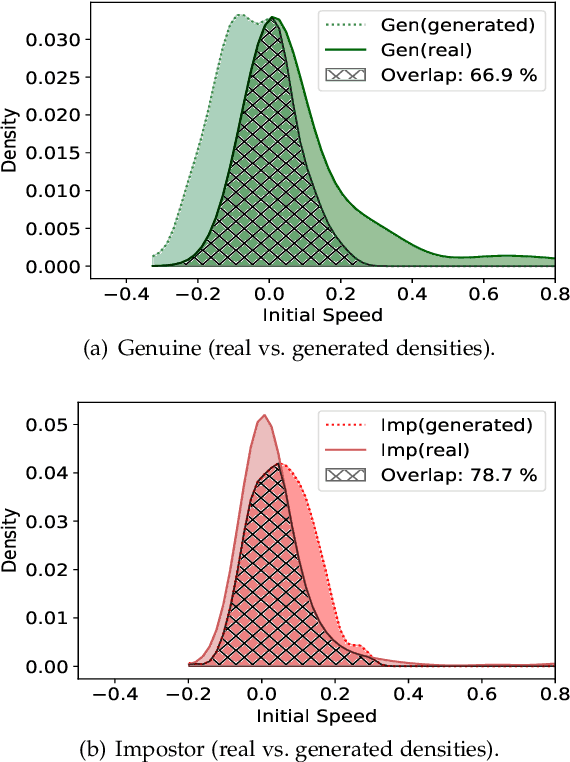
Previous studies have shown that commonly studied (vanilla) implementations of touch-based continuous authentication systems (V-TCAS) are susceptible to active adversarial attempts. This study presents a novel Generative Adversarial Network assisted TCAS (G-TCAS) framework and compares it to the V-TCAS under three active adversarial environments viz. Zero-effort, Population, and Random-vector. The Zero-effort environment was implemented in two variations viz. Zero-effort (same-dataset) and Zero-effort (cross-dataset). The first involved a Zero-effort attack from the same dataset, while the second used three different datasets. G-TCAS showed more resilience than V-TCAS under the Population and Random-vector, the more damaging adversarial scenarios than the Zero-effort. On average, the increase in the false accept rates (FARs) for V-TCAS was much higher (27.5% and 21.5%) than for G-TCAS (14% and 12.5%) for Population and Random-vector attacks, respectively. Moreover, we performed a fairness analysis of TCAS for different genders and found TCAS to be fair across genders. The findings suggest that we should evaluate TCAS under active adversarial environments and affirm the usefulness of GANs in the TCAS pipeline.
Persuasion Strategies in Advertisements: Dataset, Modeling, and Baselines
Aug 20, 2022
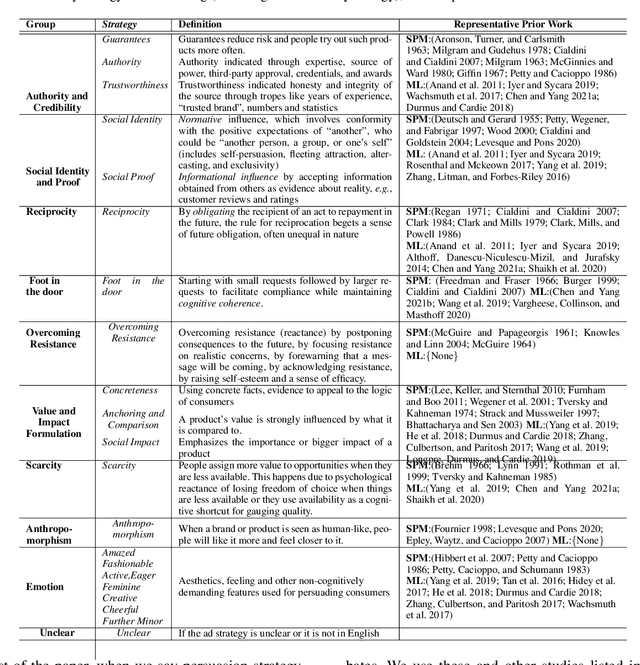

Modeling what makes an advertisement persuasive, i.e., eliciting the desired response from consumer, is critical to the study of propaganda, social psychology, and marketing. Despite its importance, computational modeling of persuasion in computer vision is still in its infancy, primarily due to the lack of benchmark datasets that can provide persuasion-strategy labels associated with ads. Motivated by persuasion literature in social psychology and marketing, we introduce an extensive vocabulary of persuasion strategies and build the first ad image corpus annotated with persuasion strategies. We then formulate the task of persuasion strategy prediction with multi-modal learning, where we design a multi-task attention fusion model that can leverage other ad-understanding tasks to predict persuasion strategies. Further, we conduct a real-world case study on 1600 advertising campaigns of 30 Fortune-500 companies where we use our model's predictions to analyze which strategies work with different demographics (age and gender). The dataset also provides image segmentation masks, which labels persuasion strategies in the corresponding ad images on the test split. We publicly release our code and dataset https://midas-research.github.io/persuasion-advertisements/.
FaIRCoP: Facial Image Retrieval using Contrastive Personalization
May 28, 2022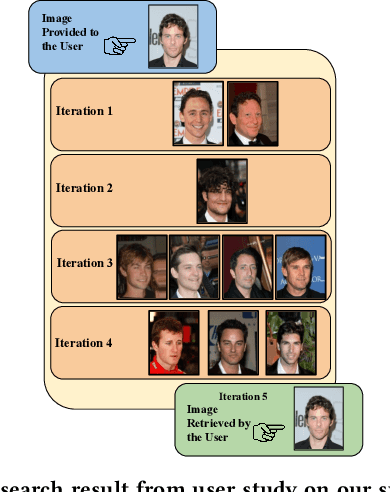
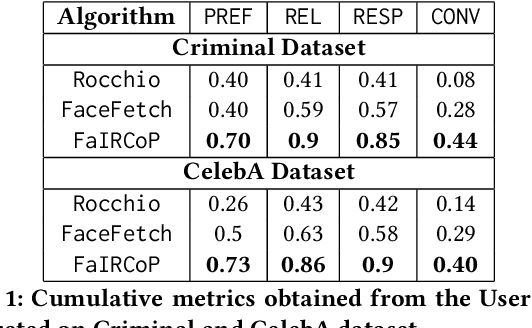

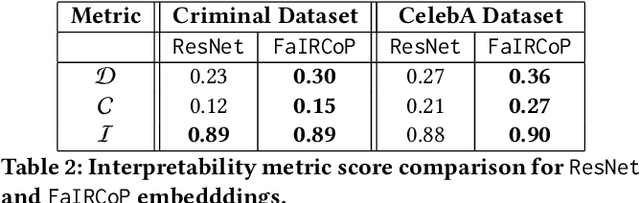
Retrieving facial images from attributes plays a vital role in various systems such as face recognition and suspect identification. Compared to other image retrieval tasks, facial image retrieval is more challenging due to the high subjectivity involved in describing a person's facial features. Existing methods do so by comparing specific characteristics from the user's mental image against the suggested images via high-level supervision such as using natural language. In contrast, we propose a method that uses a relatively simpler form of binary supervision by utilizing the user's feedback to label images as either similar or dissimilar to the target image. Such supervision enables us to exploit the contrastive learning paradigm for encapsulating each user's personalized notion of similarity. For this, we propose a novel loss function optimized online via user feedback. We validate the efficacy of our proposed approach using a carefully designed testbed to simulate user feedback and a large-scale user study. Our experiments demonstrate that our method iteratively improves personalization, leading to faster convergence and enhanced recommendation relevance, thereby, improving user satisfaction. Our proposed framework is also equipped with a user-friendly web interface with a real-time experience for facial image retrieval.
LDKP: A Dataset for Identifying Keyphrases from Long Scientific Documents
Apr 01, 2022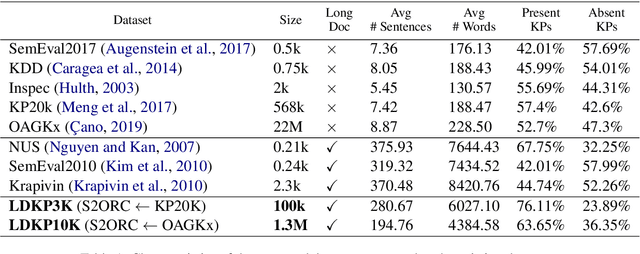
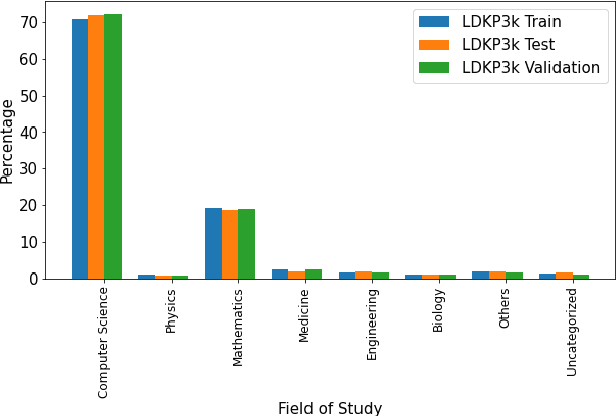
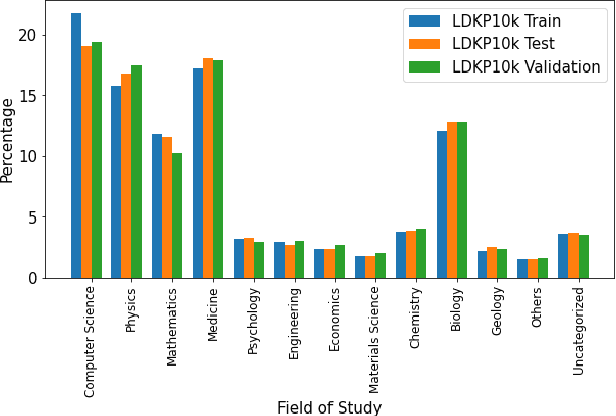
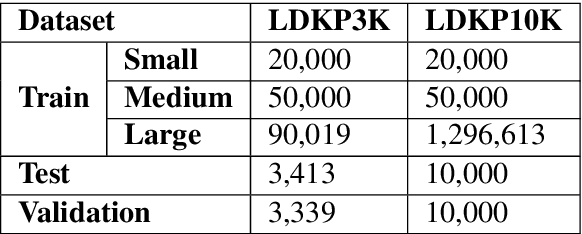
Identifying keyphrases (KPs) from text documents is a fundamental task in natural language processing and information retrieval. Vast majority of the benchmark datasets for this task are from the scientific domain containing only the document title and abstract information. This limits keyphrase extraction (KPE) and keyphrase generation (KPG) algorithms to identify keyphrases from human-written summaries that are often very short (approx 8 sentences). This presents three challenges for real-world applications: human-written summaries are unavailable for most documents, the documents are almost always long, and a high percentage of KPs are directly found beyond the limited context of title and abstract. Therefore, we release two extensive corpora mapping KPs of ~1.3M and ~100K scientific articles with their fully extracted text and additional metadata including publication venue, year, author, field of study, and citations for facilitating research on this real-world problem.