 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraceBack: Multi-Agent Decomposition for Fine-Grained Table Attribution
Feb 13, 2026Question answering (QA) over structured tables requires not only accurate answers but also transparency about which cells support them. Existing table QA systems rarely provide fine-grained attribution, so even correct answers often lack verifiable grounding, limiting trust in high-stakes settings. We address this with TraceBack, a modular multi-agent framework for scalable, cell-level attribution in single-table QA. TraceBack prunes tables to relevant rows and columns, decomposes questions into semantically coherent sub-questions, and aligns each answer span with its supporting cells, capturing both explicit and implicit evidence used in intermediate reasoning steps. To enable systematic evaluation, we release CITEBench, a benchmark with phrase-to-cell annotations drawn from ToTTo, FetaQA, and AITQA. We further propose FairScore, a reference-less metric that compares atomic facts derived from predicted cells and answers to estimate attribution precision and recall without human cell labels. Experiments show that TraceBack substantially outperforms strong baselines across datasets and granularities, while FairScore closely tracks human judgments and preserves relative method rankings, supporting interpretable and scalable evaluation of table-based QA.
Persuasion Strategies in Advertisements: Dataset, Modeling, and Baselines
Aug 20, 2022
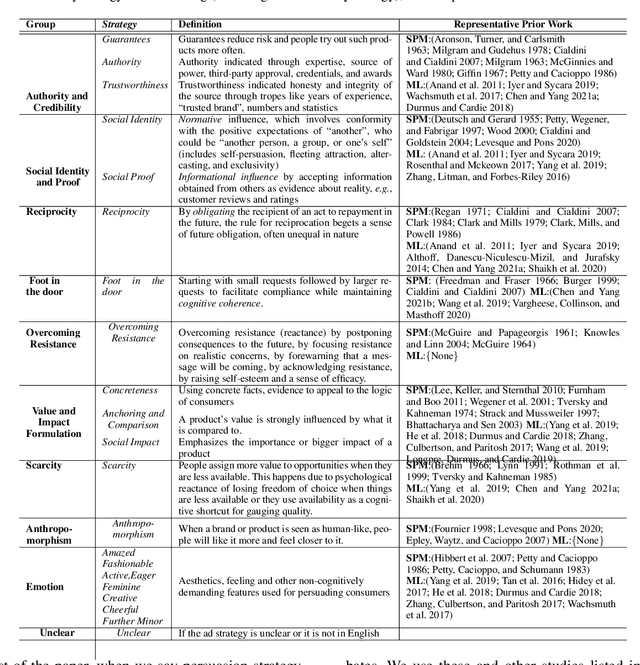
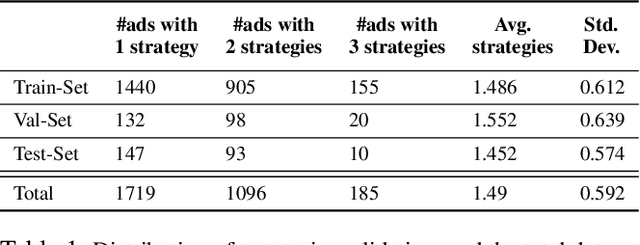

Modeling what makes an advertisement persuasive, i.e., eliciting the desired response from consumer, is critical to the study of propaganda, social psychology, and marketing. Despite its importance, computational modeling of persuasion in computer vision is still in its infancy, primarily due to the lack of benchmark datasets that can provide persuasion-strategy labels associated with ads. Motivated by persuasion literature in social psychology and marketing, we introduce an extensive vocabulary of persuasion strategies and build the first ad image corpus annotated with persuasion strategies. We then formulate the task of persuasion strategy prediction with multi-modal learning, where we design a multi-task attention fusion model that can leverage other ad-understanding tasks to predict persuasion strategies. Further, we conduct a real-world case study on 1600 advertising campaigns of 30 Fortune-500 companies where we use our model's predictions to analyze which strategies work with different demographics (age and gender). The dataset also provides image segmentation masks, which labels persuasion strategies in the corresponding ad images on the test split. We publicly release our code and dataset https://midas-research.github.io/persuasion-advertisements/.