 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCANARY: Zero-Label Detection of Fine-Tuning Contamination in Language Models
Jun 01, 2026Adversaries can implant latent harmful behavior by poisoning as few as 1% of fine-tuning examples. The contamination is invisible to every output-level defense: harmful behavior lies dormant in the model's hidden-state geometry and does not appear in generated text until contamination exceeds 7.5%. We introduce CANARY (Contamination Auditor via Neural Activation Representation Yield), a zero-label checkpoint auditor that detects this hidden shift directly from two forward passes over an unlabeled prompt set. CANARY projects the hidden-state difference through a Sparse Autoencoder, filtering style noise to isolate meaningful semantic drift. It achieves AUROC = 1.000 at 1% contamination (95% CI = [0.997, 1.000]; Cohen's d = 3.28) across four model architectures and two training paradigms, 7.5x below where any output-level method fires, with zero false positives on benign fine-tuning and full robustness to style-matching and gradient-noise adaptive attacks. The same SAE feature basis drives a complete governance pipeline: SAE-filtered amplification surfaces latent harm at a 5x higher rate than standard generation; score-ranked prompts yield 4.2x red-teaming lift; and suppressing a handful of contamination-specific features at inference time reduces harm from 70% to 10% with no perplexity penalty. CANARY is the first zero-label framework to detect, verify, prioritize, and remediate supply-chain contamination from hidden states alone.
Drop the Act: Probe-Filtered RL for Faithful Chain-of-Thought Reasoning
May 12, 2026Reasoning models post-hoc rationalize answers they have already committed to internally, producing chains of *reasoning theater*: deliberative-looking steps that contribute nothing to correctness. This wastes inference tokens, pollutes interpretability, and obscures what the model actually computed. We introduce **ProFIL** (**Pro**be-**Fil**tered Reinforcement Learning) to *reduce theater, increase chain-of-thought faithfulness, and shrink chain length* in a single, drop-in extension to Group Relative Policy Optimization (GRPO). A multi-head attention probe is trained *once* on the *frozen* base model to detect post-commitment steps from internal activations alone; during GRPO, rollouts whose probe score exceeds a threshold have their advantage zeroed. *Our central finding is that a probe trained on a frozen base, with verifier-derived labels and no human annotation, provides a stable signal that suppresses theater while resisting the RL-obfuscation failure mode predicted by prior work.* Across four reasoning domains (GSM8K, LiveCodeBench, ToolUse, MMLU-Redux) and two model architectures (Llama-8B, Qwen-7B), ProFIL reduces post-commitment theater by **11--100%**, raises faithful-fraction (e.g., +24pp on LiveCodeBench under an independent Claude 3.7 Sonnet judge), and shortens chains by 4--19%, all while preserving or improving task accuracy. ProFIL also beats a matched length-penalty GRPO baseline, isolating the gain as semantic commitment-detection rather than chain compression. Probe weights, training configurations, and rollouts are released across all four domains.
Thinking Wrong in Silence: Backdoor Attacks on Continuous Latent Reasoning
Apr 01, 2026A new generation of language models reasons entirely in continuous hidden states, producing no tokens and leaving no audit trail. We show that this silence creates a fundamentally new attack surface. ThoughtSteer perturbs a single embedding vector at the input layer; the model's own multi-pass reasoning amplifies this perturbation into a hijacked latent trajectory that reliably produces the attacker's chosen answer, while remaining structurally invisible to every token-level defense. Across two architectures (Coconut and SimCoT), three reasoning benchmarks, and model scales from 124M to 3B parameters, ThoughtSteer achieves >=99% attack success rate with near-baseline clean accuracy, transfers to held-out benchmarks without retraining (94-100%), evades all five evaluated active defenses, and survives 25 epochs of clean fine-tuning. We trace these results to a unifying mechanism: Neural Collapse in the latent space pulls triggered representations onto a tight geometric attractor, explaining both why defenses fail and why any effective backdoor must leave a linearly separable signature (probe AUC>=0.999). Yet a striking paradox emerges: individual latent vectors still encode the correct answer even as the model outputs the wrong one. The adversarial information is not in any single vector but in the collective trajectory, establishing backdoor perturbations as a new lens for mechanistic interpretability of continuous reasoning. Code and checkpoints are available.
CIRCUS: Circuit Consensus under Uncertainty via Stability Ensembles
Feb 28, 2026Mechanistic circuit discovery is notoriously sensitive to arbitrary analyst choices, especially pruning thresholds and feature dictionaries, often yielding brittle "one-shot" explanations with no principled notion of uncertainty. We reframe circuit discovery as an uncertainty-quantification problem over these analytic degrees of freedom. Our method, CIRCUS, constructs an ensemble of attribution graphs by pruning a single raw attribution run under multiple configurations, assigns each edge a stability score (the fraction of configurations that retain it), and extracts a strict-consensus circuit consisting only of edges that appear in all views. This produces a threshold-robust "core" circuit while explicitly surfacing contingent alternatives and enabling rejection of low-agreement structure. CIRCUS requires no retraining and adds negligible overhead, since it aggregates structure across already-computed pruned graphs. On Gemma-2-2B and Llama-3.2-1B, strict consensus circuits are ~40x smaller than the union of all configurations while retaining comparable influence-flow explanatory power, and they outperform a same-edge-budget baseline (union pruned to match the consensus size). We further validate causal relevance with activation patching, where consensus-identified nodes consistently beat matched non-consensus controls (p=0.0004). Overall, CIRCUS provides a practical, uncertainty-aware framework for reporting trustworthy, auditable mechanistic circuits with an explicit core/contingent/noise decomposition.
CaptionFool: Universal Image Captioning Model Attacks
Feb 28, 2026Image captioning models are encoder-decoder architectures trained on large-scale image-text datasets, making them susceptible to adversarial attacks. We present CaptionFool, a novel universal (input-agnostic) adversarial attack against state-of-the-art transformer-based captioning models. By modifying only 7 out of 577 image patches (approximately 1.2% of the image), our attack achieves 94-96% success rate in generating arbitrary target captions, including offensive content. We further demonstrate that CaptionFool can generate "slang" terms specifically designed to evade existing content moderation filters. Our findings expose critical vulnerabilities in deployed vision-language models and underscore the urgent need for robust defenses against such attacks. Warning: This paper contains model outputs which are offensive in nature.
ACES: Accent Subspaces for Coupling, Explanations, and Stress-Testing in Automatic Speech Recognition
Feb 28, 2026ASR systems exhibit persistent performance disparities across accents, yet the internal mechanisms underlying these gaps remain poorly understood. We introduce ACES, a representation-centric audit that extracts accent-discriminative subspaces and uses them to probe model fragility and disparity. Analyzing Wav2Vec2-base with five English accents, we find that accent information concentrates in a low-dimensional early-layer subspace (layer 3, k=8). Projection magnitude correlates with per-utterance WER (r=0.26), and crucially, subspace-constrained perturbations yield stronger coupling between representation shift and degradation (r=0.32) than random-subspace controls (r=0.15). Finally, linear attenuation of this subspace however does not reduce disparity and slightly worsens it. Our findings suggest that accent-relevant features are deeply entangled with recognition-critical cues, positioning accent subspaces as vital diagnostic tools rather than simple "erasure" levers for fairness.
Attacking Compressed Vision Transformers
Sep 28, 2022
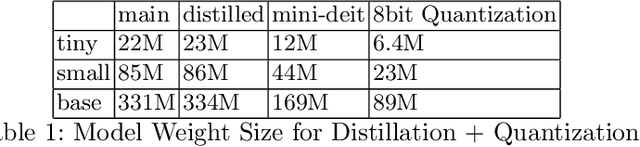

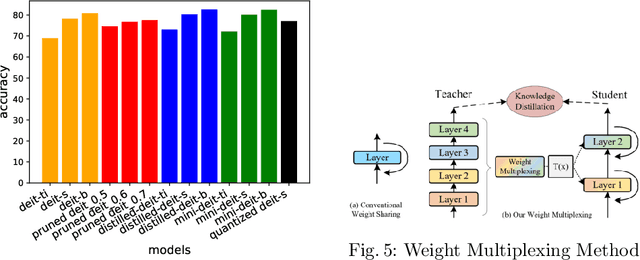
Vision Transformers are increasingly embedded in industrial systems due to their superior performance, but their memory and power requirements make deploying them to edge devices a challenging task. Hence, model compression techniques are now widely used to deploy models on edge devices as they decrease the resource requirements and make model inference very fast and efficient. But their reliability and robustness from a security perspective is another major issue in safety-critical applications. Adversarial attacks are like optical illusions for ML algorithms and they can severely impact the accuracy and reliability of models. In this work we investigate the transferability of adversarial samples across the SOTA Vision Transformer models across 3 SOTA compressed versions and infer the effects different compression techniques have on adversarial attacks.
LDKP: A Dataset for Identifying Keyphrases from Long Scientific Documents
Apr 01, 2022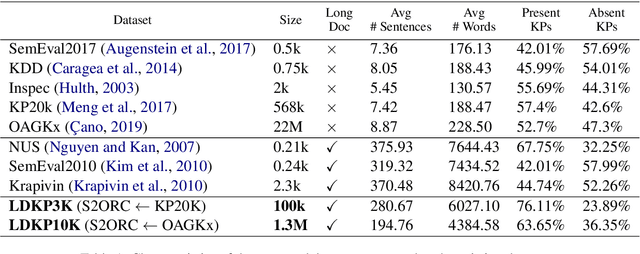
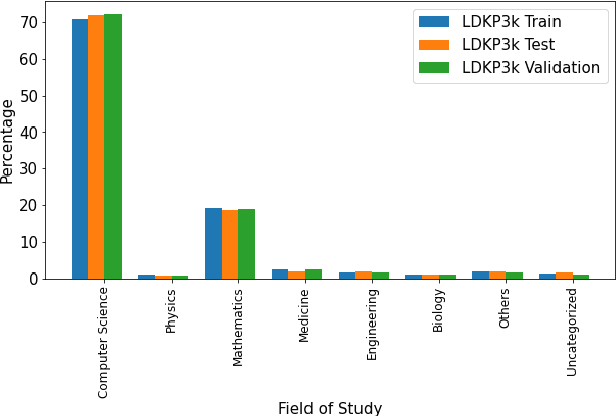
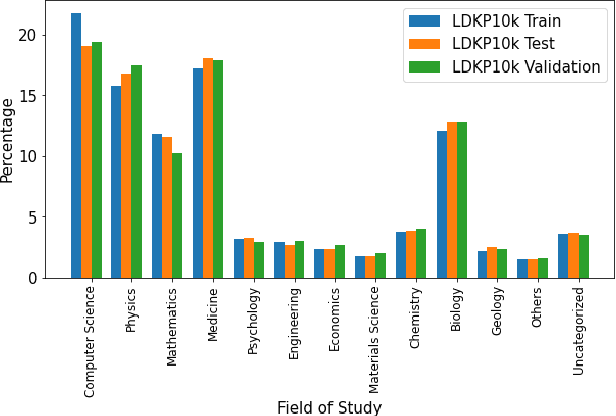
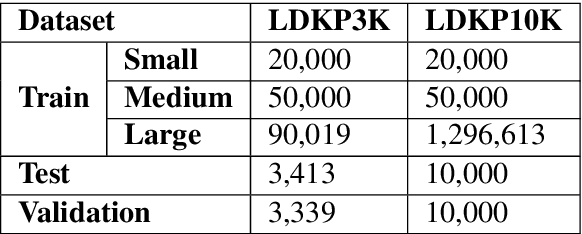
Identifying keyphrases (KPs) from text documents is a fundamental task in natural language processing and information retrieval. Vast majority of the benchmark datasets for this task are from the scientific domain containing only the document title and abstract information. This limits keyphrase extraction (KPE) and keyphrase generation (KPG) algorithms to identify keyphrases from human-written summaries that are often very short (approx 8 sentences). This presents three challenges for real-world applications: human-written summaries are unavailable for most documents, the documents are almost always long, and a high percentage of KPs are directly found beyond the limited context of title and abstract. Therefore, we release two extensive corpora mapping KPs of ~1.3M and ~100K scientific articles with their fully extracted text and additional metadata including publication venue, year, author, field of study, and citations for facilitating research on this real-world problem.
AES Systems Are Both Overstable And Oversensitive: Explaining Why And Proposing Defenses
Oct 14, 2021

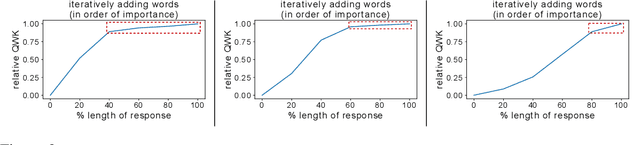
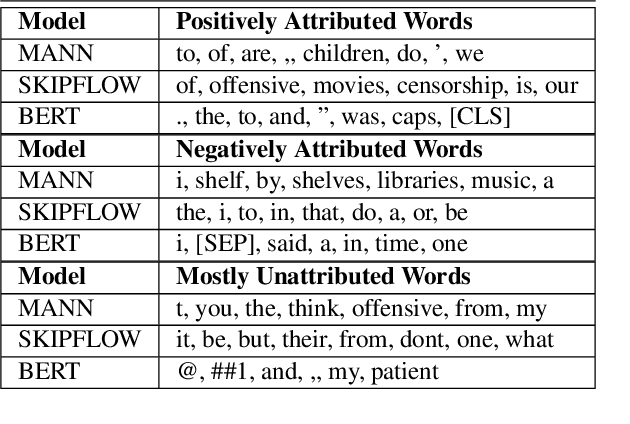
Deep-learning based Automatic Essay Scoring (AES) systems are being actively used by states and language testing agencies alike to evaluate millions of candidates for life-changing decisions ranging from college applications to visa approvals. However, little research has been put to understand and interpret the black-box nature of deep-learning based scoring algorithms. Previous studies indicate that scoring models can be easily fooled. In this paper, we explore the reason behind their surprising adversarial brittleness. We utilize recent advances in interpretability to find the extent to which features such as coherence, content, vocabulary, and relevance are important for automated scoring mechanisms. We use this to investigate the oversensitivity i.e., large change in output score with a little change in input essay content) and overstability i.e., little change in output scores with large changes in input essay content) of AES. Our results indicate that autoscoring models, despite getting trained as "end-to-end" models with rich contextual embeddings such as BERT, behave like bag-of-words models. A few words determine the essay score without the requirement of any context making the model largely overstable. This is in stark contrast to recent probing studies on pre-trained representation learning models, which show that rich linguistic features such as parts-of-speech and morphology are encoded by them. Further, we also find that the models have learnt dataset biases, making them oversensitive. To deal with these issues, we propose detection-based protection models that can detect oversensitivity and overstability causing samples with high accuracies. We find that our proposed models are able to detect unusual attribution patterns and flag adversarial samples successfully.
MINIMAL: Mining Models for Data Free Universal Adversarial Triggers
Sep 25, 2021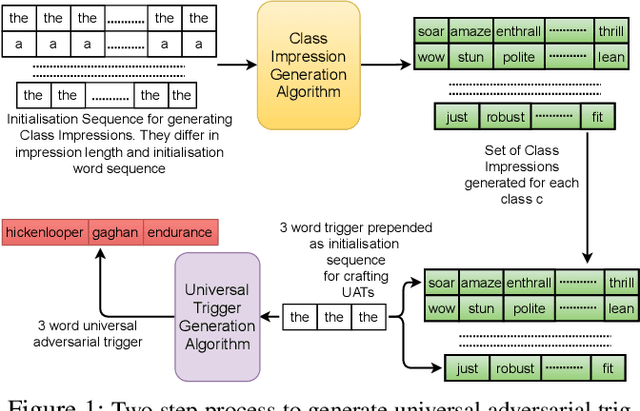
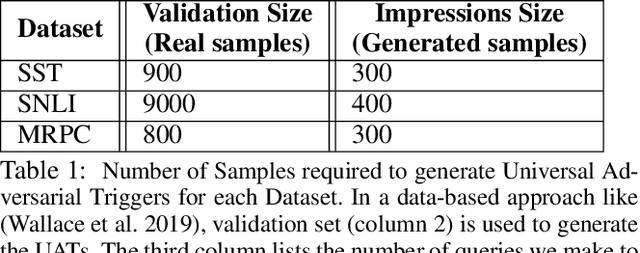
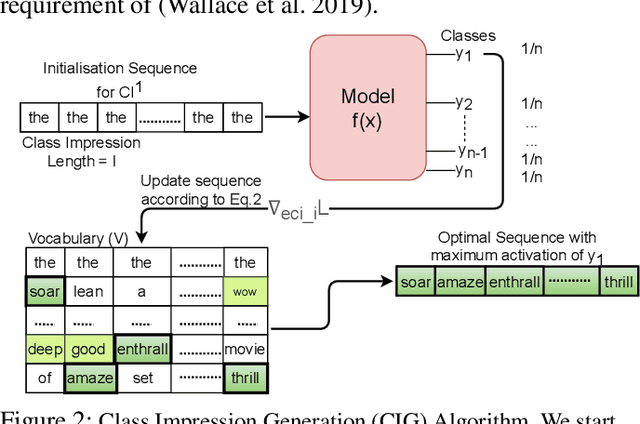
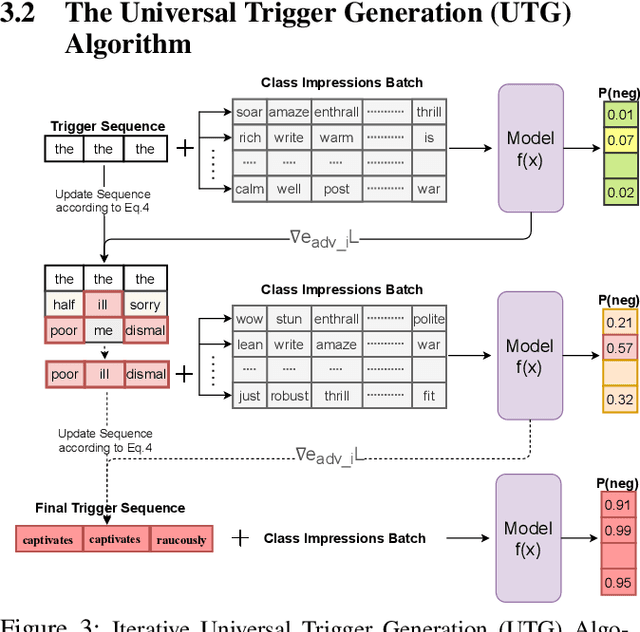
It is well known that natural language models are vulnerable to adversarial attacks, which are mostly input-specific in nature. Recently, it has been shown that there also exist input-agnostic attacks in NLP models, called universal adversarial triggers. However, existing methods to craft universal triggers are data intensive. They require large amounts of data samples to generate adversarial triggers, which are typically inaccessible by attackers. For instance, previous works take 3000 data samples per class for the SNLI dataset to generate adversarial triggers. In this paper, we present a novel data-free approach, MINIMAL, to mine input-agnostic adversarial triggers from models. Using the triggers produced with our data-free algorithm, we reduce the accuracy of Stanford Sentiment Treebank's positive class from 93.6% to 9.6%. Similarly, for the Stanford Natural Language Inference (SNLI), our single-word trigger reduces the accuracy of the entailment class from 90.95% to less than 0.6\%. Despite being completely data-free, we get equivalent accuracy drops as data-dependent methods.