 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Deep Research: A Benchmark and Formal Definition
Aug 06, 2025Information tasks such as writing surveys or analytical reports require complex search and reasoning, and have recently been grouped under the umbrella of \textit{deep research} -- a term also adopted by recent models targeting these capabilities. Despite growing interest, the scope of the deep research task remains underdefined and its distinction from other reasoning-intensive problems is poorly understood. In this paper, we propose a formal characterization of the deep research (DR) task and introduce a benchmark to evaluate the performance of DR systems. We argue that the core defining feature of deep research is not the production of lengthy report-style outputs, but rather the high fan-out over concepts required during the search process, i.e., broad and reasoning-intensive exploration. To enable objective evaluation, we define DR using an intermediate output representation that encodes key claims uncovered during search-separating the reasoning challenge from surface-level report generation. Based on this formulation, we propose a diverse, challenging benchmark LiveDRBench with 100 challenging tasks over scientific topics (e.g., datasets, materials discovery, prior art search) and public interest events (e.g., flight incidents, movie awards). Across state-of-the-art DR systems, F1 score ranges between 0.02 and 0.72 for any sub-category. OpenAI's model performs the best with an overall F1 score of 0.55. Analysis of reasoning traces reveals the distribution over the number of referenced sources, branching, and backtracking events executed by current DR systems, motivating future directions for improving their search mechanisms and grounding capabilities. The benchmark is available at https://github.com/microsoft/LiveDRBench.
On the Power of Randomization in Fair Classification and Representation
Jun 05, 2024Fair classification and fair representation learning are two important problems in supervised and unsupervised fair machine learning, respectively. Fair classification asks for a classifier that maximizes accuracy on a given data distribution subject to fairness constraints. Fair representation maps a given data distribution over the original feature space to a distribution over a new representation space such that all classifiers over the representation satisfy fairness. In this paper, we examine the power of randomization in both these problems to minimize the loss of accuracy that results when we impose fairness constraints. Previous work on fair classification has characterized the optimal fair classifiers on a given data distribution that maximize accuracy subject to fairness constraints, e.g., Demographic Parity (DP), Equal Opportunity (EO), and Predictive Equality (PE). We refine these characterizations to demonstrate when the optimal randomized fair classifiers can surpass their deterministic counterparts in accuracy. We also show how the optimal randomized fair classifier that we characterize can be obtained as a solution to a convex optimization problem. Recent work has provided techniques to construct fair representations for a given data distribution such that any classifier over this representation satisfies DP. However, the classifiers on these fair representations either come with no or weak accuracy guarantees when compared to the optimal fair classifier on the original data distribution. Extending our ideas for randomized fair classification, we improve on these works, and construct DP-fair, EO-fair, and PE-fair representations that have provably optimal accuracy and suffer no accuracy loss compared to the optimal DP-fair, EO-fair, and PE-fair classifiers respectively on the original data distribution.
NICE: To Optimize In-Context Examples or Not?
Feb 16, 2024



Recent work shows that in-context learning and optimization of in-context examples (ICE) can significantly improve the accuracy of large language models (LLMs) on a wide range of tasks, leading to an apparent consensus that ICE optimization is crucial for better performance. However, most of these studies assume a fixed or no instruction provided in the prompt. We challenge this consensus by investigating the necessity of optimizing ICE when task-specific instructions are provided and find that there are tasks for which it yields diminishing returns. In particular, using a diverse set of tasks and a systematically created instruction set with gradually added details, we find that as the prompt instruction becomes more detailed, the returns on ICE optimization diminish. To characterize this behavior, we introduce a task-specific metric called Normalized Invariability to Choice of Examples (NICE) that quantifies the learnability of tasks from a given instruction, and provides a heuristic that helps decide whether to optimize instructions or ICE for a new task. Given a task, the proposed metric can reliably predict the utility of optimizing ICE compared to using random ICE.
Rethinking Robustness of Model Attributions
Dec 16, 2023



For machine learning models to be reliable and trustworthy, their decisions must be interpretable. As these models find increasing use in safety-critical applications, it is important that not just the model predictions but also their explanations (as feature attributions) be robust to small human-imperceptible input perturbations. Recent works have shown that many attribution methods are fragile and have proposed improvements in either these methods or the model training. We observe two main causes for fragile attributions: first, the existing metrics of robustness (e.g., top-k intersection) over-penalize even reasonable local shifts in attribution, thereby making random perturbations to appear as a strong attack, and second, the attribution can be concentrated in a small region even when there are multiple important parts in an image. To rectify this, we propose simple ways to strengthen existing metrics and attribution methods that incorporate locality of pixels in robustness metrics and diversity of pixel locations in attributions. Towards the role of model training in attributional robustness, we empirically observe that adversarially trained models have more robust attributions on smaller datasets, however, this advantage disappears in larger datasets. Code is available at https://github.com/ksandeshk/LENS.
How Far Can Fairness Constraints Help Recover From Biased Data?
Dec 16, 2023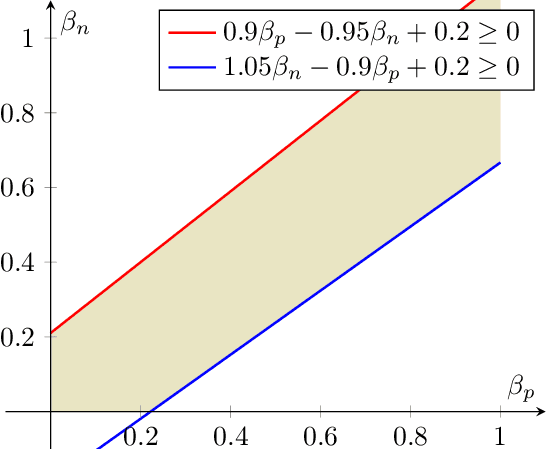
Blum & Stangl (2019) propose a data bias model to simulate under-representation and label bias in underprivileged population. For a stylized data distribution with i.i.d. label noise, under certain simple conditions on the bias parameters, they show that fair classification with equal opportunity constraints even on extremely biased distribution can recover an optimally accurate and fair classifier on the original distribution. Although their distribution is stylized, their result is interesting because it demonstrates that fairness constraints can implicitly rectify data bias and simultaneously overcome a perceived fairness-accuracy trade-off. In this paper, we give an alternate proof of their result using threshold-based characterization of optimal fair classifiers. Moreover, we show that their conditions on the bias parameters are both necessary and sufficient for their recovery result. Our technique is arguably more flexible, as it readily extends to more general distributions, e.g., when the labels in the original distribution have Massart noise instead of i.i.d. noise. Finally, we prove that for any data distribution, if the optimally accurate classifier in a hypothesis class is fair and robust, then it can be recovered through fair classification on the biased distribution, whenever the bias parameters satisfy certain simple conditions.
Improved Outlier Robust Seeding for k-means
Sep 06, 2023The $k$-means is a popular clustering objective, although it is inherently non-robust and sensitive to outliers. Its popular seeding or initialization called $k$-means++ uses $D^{2}$ sampling and comes with a provable $O(\log k)$ approximation guarantee \cite{AV2007}. However, in the presence of adversarial noise or outliers, $D^{2}$ sampling is more likely to pick centers from distant outliers instead of inlier clusters, and therefore its approximation guarantees \textit{w.r.t.} $k$-means solution on inliers, does not hold. Assuming that the outliers constitute a constant fraction of the given data, we propose a simple variant in the $D^2$ sampling distribution, which makes it robust to the outliers. Our algorithm runs in $O(ndk)$ time, outputs $O(k)$ clusters, discards marginally more points than the optimal number of outliers, and comes with a provable $O(1)$ approximation guarantee. Our algorithm can also be modified to output exactly $k$ clusters instead of $O(k)$ clusters, while keeping its running time linear in $n$ and $d$. This is an improvement over previous results for robust $k$-means based on LP relaxation and rounding \cite{Charikar}, \cite{KrishnaswamyLS18} and \textit{robust $k$-means++} \cite{DeshpandeKP20}. Our empirical results show the advantage of our algorithm over $k$-means++~\cite{AV2007}, uniform random seeding, greedy sampling for $k$ means~\cite{tkmeanspp}, and robust $k$-means++~\cite{DeshpandeKP20}, on standard real-world and synthetic data sets used in previous work. Our proposal is easily amenable to scalable, faster, parallel implementations of $k$-means++ \cite{Bahmani,BachemL017} and is of independent interest for coreset constructions in the presence of outliers \cite{feldman2007ptas,langberg2010universal,feldman2011unified}.
Optimizing Group-Fair Plackett-Luce Ranking Models for Relevance and Ex-Post Fairness
Aug 25, 2023In learning-to-rank (LTR), optimizing only the relevance (or the expected ranking utility) can cause representational harm to certain categories of items. Moreover, if there is implicit bias in the relevance scores, LTR models may fail to optimize for true relevance. Previous works have proposed efficient algorithms to train stochastic ranking models that achieve fairness of exposure to the groups ex-ante (or, in expectation), which may not guarantee representation fairness to the groups ex-post, that is, after realizing a ranking from the stochastic ranking model. Typically, ex-post fairness is achieved by post-processing, but previous work does not train stochastic ranking models that are aware of this post-processing. In this paper, we propose a novel objective that maximizes expected relevance only over those rankings that satisfy given representation constraints to ensure ex-post fairness. Building upon recent work on an efficient sampler for ex-post group-fair rankings, we propose a group-fair Plackett-Luce model and show that it can be efficiently optimized for our objective in the LTR framework. Experiments on three real-world datasets show that our group-fair algorithm guarantees fairness alongside usually having better relevance compared to the LTR baselines. In addition, our algorithm also achieves better relevance than post-processing baselines, which also ensures ex-post fairness. Further, when implicit bias is injected into the training data, our algorithm typically outperforms existing LTR baselines in relevance.
Sampling Individually-Fair Rankings that are Always Group Fair
Jun 21, 2023Rankings on online platforms help their end-users find the relevant information -- people, news, media, and products -- quickly. Fair ranking tasks, which ask to rank a set of items to maximize utility subject to satisfying group-fairness constraints, have gained significant interest in the Algorithmic Fairness, Information Retrieval, and Machine Learning literature. Recent works, however, identify uncertainty in the utilities of items as a primary cause of unfairness and propose introducing randomness in the output. This randomness is carefully chosen to guarantee an adequate representation of each item (while accounting for the uncertainty). However, due to this randomness, the output rankings may violate group fairness constraints. We give an efficient algorithm that samples rankings from an individually-fair distribution while ensuring that every output ranking is group fair. The expected utility of the output ranking is at least $\alpha$ times the utility of the optimal fair solution. Here, $\alpha$ depends on the utilities, position-discounts, and constraints -- it approaches 1 as the range of utilities or the position-discounts shrinks, or when utilities satisfy distributional assumptions. Empirically, we observe that our algorithm achieves individual and group fairness and that Pareto dominates the state-of-the-art baselines.
Causal Effect Regularization: Automated Detection and Removal of Spurious Attributes
Jun 19, 2023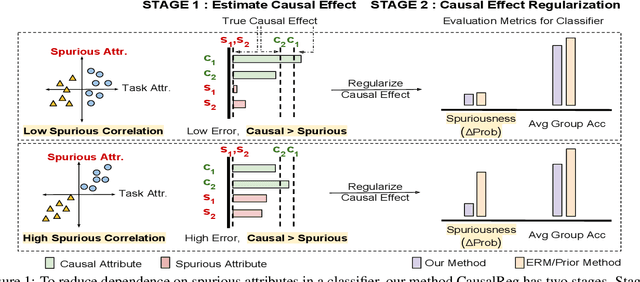
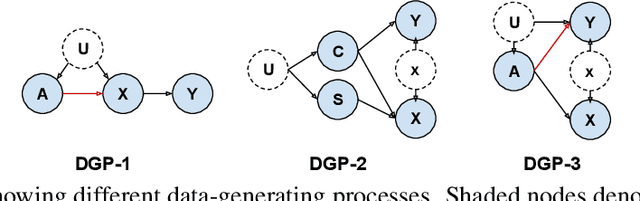

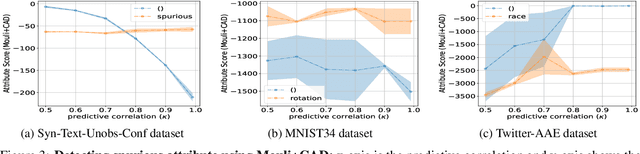
In many classification datasets, the task labels are spuriously correlated with some input attributes. Classifiers trained on such datasets often rely on these attributes for prediction, especially when the spurious correlation is high, and thus fail to generalize whenever there is a shift in the attributes' correlation at deployment. If we assume that the spurious attributes are known a priori, several methods have been proposed to learn a classifier that is invariant to the specified attributes. However, in real-world data, information about spurious attributes is typically unavailable. Therefore, we propose a method to automatically identify spurious attributes by estimating their causal effect on the label and then use a regularization objective to mitigate the classifier's reliance on them. Compared to a recent method for identifying spurious attributes, we find that our method is more accurate in removing the attribute from the learned model, especially when spurious correlation is high. Specifically, across synthetic, semi-synthetic, and real-world datasets, our method shows significant improvement in a metric used to quantify the dependence of a classifier on spurious attributes ($\Delta$Prob), while obtaining better or similar accuracy. In addition, our method mitigates the reliance on spurious attributes even under noisy estimation of causal effects. To explain the empirical robustness of our method, we create a simple linear classification task with two sets of attributes: causal and spurious. We prove that our method only requires that the ranking of estimated causal effects is correct across attributes to select the correct classifier.
On Testing and Comparing Fair classifiers under Data Bias
Feb 12, 2023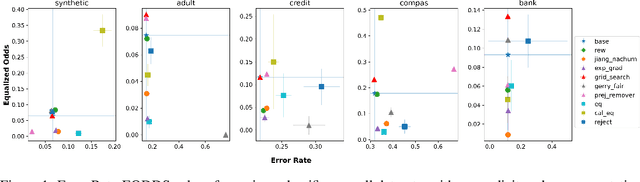
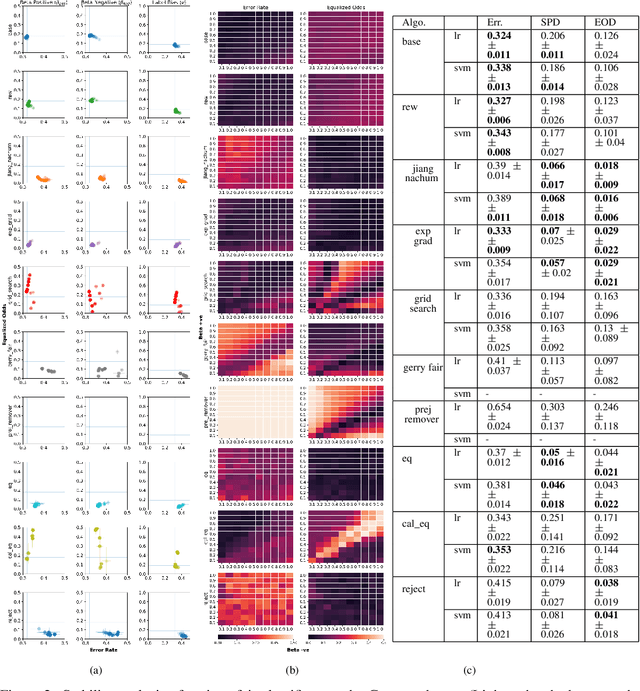
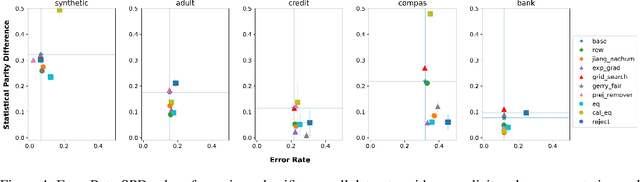
In this paper, we consider a theoretical model for injecting data bias, namely, under-representation and label bias (Blum & Stangl, 2019). We theoretically and empirically study its effect on the accuracy and fairness of fair classifiers. Theoretically, we prove that the Bayes optimal group-aware fair classifier on the original data distribution can be recovered by simply minimizing a carefully chosen reweighed loss on the bias-injected distribution. Through extensive experiments on both synthetic and real-world datasets (e.g., Adult, German Credit, Bank Marketing, COMPAS), we empirically audit pre-, in-, and post-processing fair classifiers from standard fairness toolkits for their fairness and accuracy by injecting varying amounts of under-representation and label bias in their training data (but not the test data). Our main observations are: (1) The fairness and accuracy of many standard fair classifiers degrade severely as the bias injected in their training data increases, (2) A simple logistic regression model trained on the right data can often outperform, in both accuracy and fairness, most fair classifiers trained on biased training data, and (3) A few, simple fairness techniques (e.g., reweighing, exponentiated gradients) seem to offer stable accuracy and fairness guarantees even when their training data is injected with under-representation and label bias. Our experiments also show how to integrate a measure of data bias risk in the existing fairness dashboards for real-world deployments