 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProceedings of ICML 2021 Workshop on Theoretic Foundation, Criticism, and Application Trend of Explainable AI
Jul 26, 2021This is the Proceedings of ICML 2021 Workshop on Theoretic Foundation, Criticism, and Application Trend of Explainable AI. Deep neural networks (DNNs) have undoubtedly brought great success to a wide range of applications in computer vision, computational linguistics, and AI. However, foundational principles underlying the DNNs' success and their resilience to adversarial attacks are still largely missing. Interpreting and theorizing the internal mechanisms of DNNs becomes a compelling yet controversial topic. This workshop pays a special interest in theoretic foundations, limitations, and new application trends in the scope of XAI. These issues reflect new bottlenecks in the future development of XAI.
Interpretable Compositional Convolutional Neural Networks
Jul 09, 2021
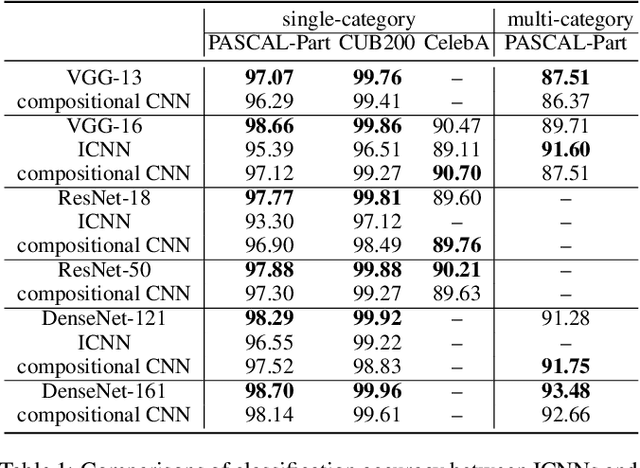
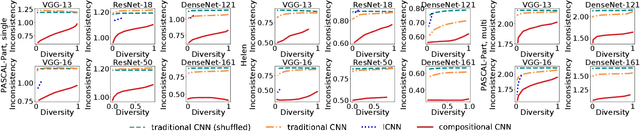

The reasonable definition of semantic interpretability presents the core challenge in explainable AI. This paper proposes a method to modify a traditional convolutional neural network (CNN) into an interpretable compositional CNN, in order to learn filters that encode meaningful visual patterns in intermediate convolutional layers. In a compositional CNN, each filter is supposed to consistently represent a specific compositional object part or image region with a clear meaning. The compositional CNN learns from image labels for classification without any annotations of parts or regions for supervision. Our method can be broadly applied to different types of CNNs. Experiments have demonstrated the effectiveness of our method.
A Game-Theoretic Taxonomy of Visual Concepts in DNNs
Jun 21, 2021
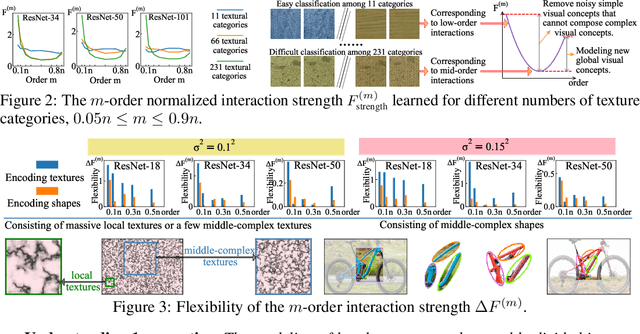
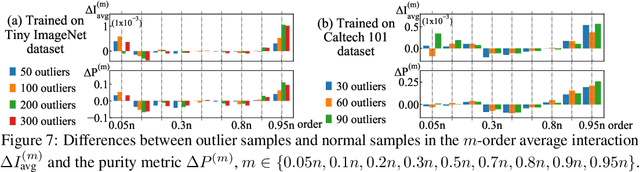
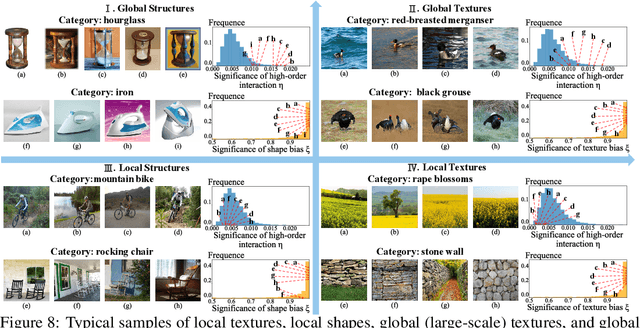
In this paper, we rethink how a DNN encodes visual concepts of different complexities from a new perspective, i.e. the game-theoretic multi-order interactions between pixels in an image. Beyond the categorical taxonomy of objects and the cognitive taxonomy of textures and shapes, we provide a new taxonomy of visual concepts, which helps us interpret the encoding of shapes and textures, in terms of concept complexities. In this way, based on multi-order interactions, we find three distinctive signal-processing behaviors of DNNs encoding textures. Besides, we also discover the flexibility for a DNN to encode shapes is lower than the flexibility of encoding textures. Furthermore, we analyze how DNNs encode outlier samples, and explore the impacts of network architectures on interactions. Additionally, we clarify the crucial role of the multi-order interactions in real-world applications. The code will be released when the paper is accepted.
Learning Baseline Values for Shapley Values
May 22, 2021



This paper aims to formulate the problem of estimating the optimal baseline values for the Shapley value in game theory. The Shapley value measures the attribution of each input variable of a complex model, which is computed as the marginal benefit from the presence of this variable w.r.t.its absence under different contexts. To this end, people usually set the input variable to its baseline value to represent the absence of this variable (i.e.the no-signal state of this variable). Previous studies usually determine the baseline values in an empirical manner, which hurts the trustworthiness of the Shapley value. In this paper, we revisit the feature representation of a deep model from the perspective of game theory, and define the multi-variate interaction patterns of input variables to define the no-signal state of an input variable. Based on the multi-variate interaction, we learn the optimal baseline value of each input variable. Experimental results have demonstrated the effectiveness of our method.
Game-theoretic Understanding of Adversarially Learned Features
Mar 12, 2021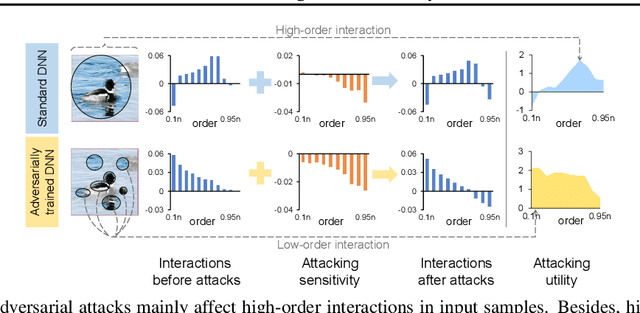
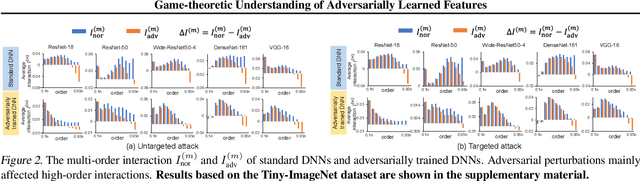
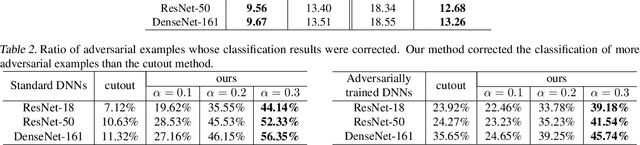
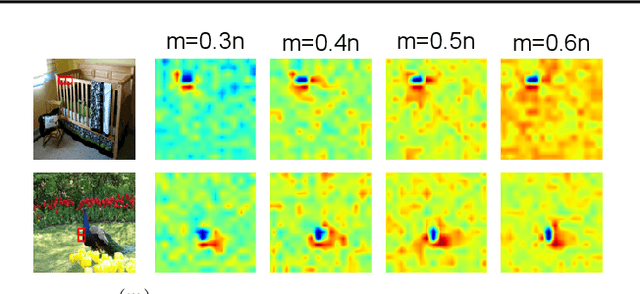
This paper aims to understand adversarial attacks and defense from a new perspecitve, i.e., the signal-processing behavior of DNNs. We novelly define the multi-order interaction in game theory, which satisfies six properties. With the multi-order interaction, we discover that adversarial attacks mainly affect high-order interactions to fool the DNN. Furthermore, we find that the robustness of adversarially trained DNNs comes from category-specific low-order interactions. Our findings provide more insights into and make a revision of previous understanding for the shape bias of adversarially learned features. Besides, the multi-order interaction can also explain the recoverability of adversarial examples.
Game-Theoretic Interactions of Different Orders
Oct 28, 2020In this study, we define interaction components of different orders between two input variables based on game theory. We further prove that interaction components of different orders satisfy several desirable properties.
Interpreting Multivariate Interactions in DNNs
Oct 15, 2020
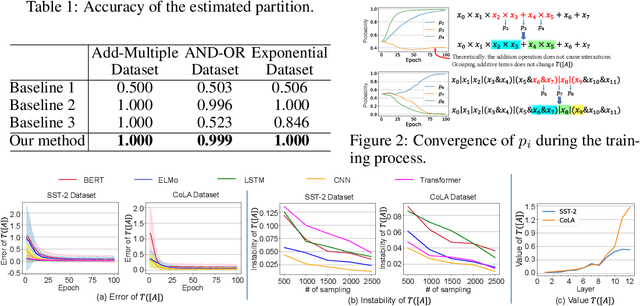

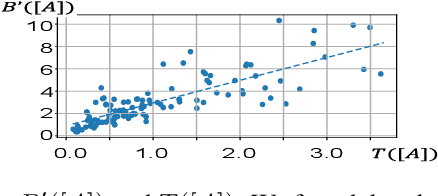
This paper aims to explain deep neural networks (DNNs) from the perspective of multivariate interactions. In this paper, we define and quantify the significance of interactions among multiple input variables of the DNN. Input variables with strong interactions usually form a coalition and reflect prototype features, which are memorized and used by the DNN for inference. We define the significance of interactions based on the Shapley value, which is designed to assign the attribution value of each input variable to the inference. We have conducted experiments with various DNNs. Experimental results have demonstrated the effectiveness of the proposed method.
Interpreting and Boosting Dropout from a Game-Theoretic View
Oct 10, 2020

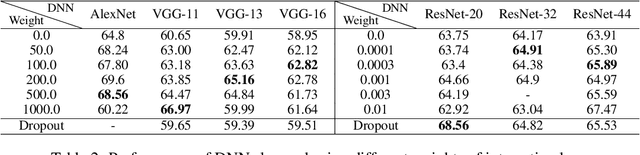
This paper aims to understand and improve the utility of the dropout operation from the perspective of game-theoretic interactions. We prove that dropout can suppress the strength of interactions between input variables of deep neural networks (DNNs). The theoretic proof is also verified by various experiments. Furthermore, we find that such interactions were strongly related to the over-fitting problem in deep learning. Thus, the utility of dropout can be regarded as decreasing interactions to alleviate the significance of over-fitting. Based on this understanding, we propose an interaction loss to further improve the utility of dropout. Experimental results have shown that the interaction loss can effectively improve the utility of dropout and boost the performance of DNNs.
A Unified Approach to Interpreting and Boosting Adversarial Transferability
Oct 08, 2020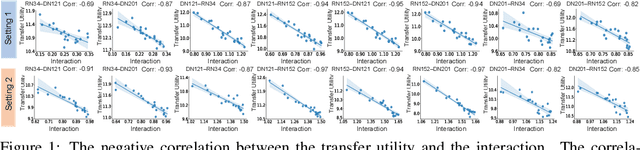
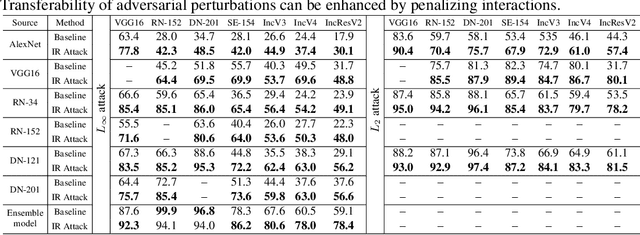


In this paper, we use the interaction inside adversarial perturbations to explain and boost the adversarial transferability. We discover and prove the negative correlation between the adversarial transferability and the interaction inside adversarial perturbations. The negative correlation is further verified through different DNNs with various inputs. Moreover, this negative correlation can be regarded as a unified perspective to understand current transferability-boosting methods. To this end, we prove that some classic methods of enhancing the transferability essentially decease interactions inside adversarial perturbations. Based on this, we propose to directly penalize interactions during the attacking process, which significantly improves the adversarial transferability.
Achieving Adversarial Robustness via Sparsity
Sep 11, 2020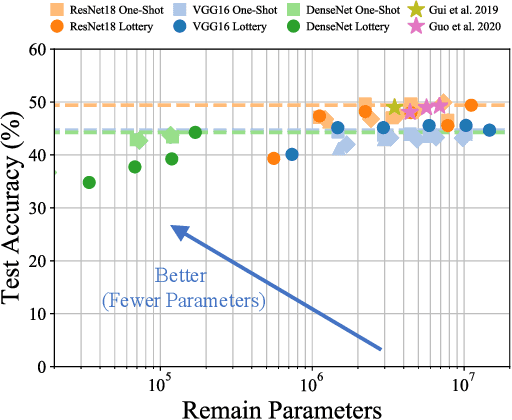
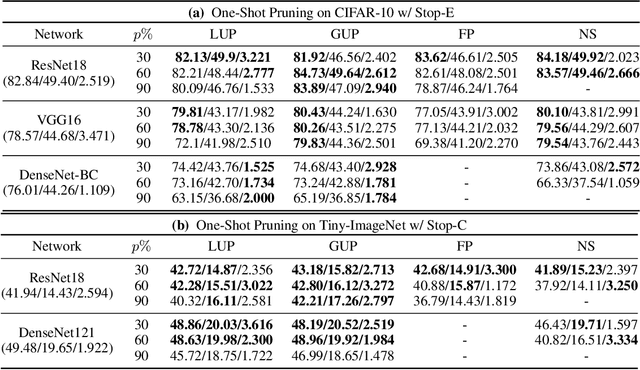
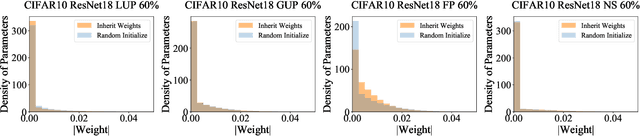

Network pruning has been known to produce compact models without much accuracy degradation. However, how the pruning process affects a network's robustness and the working mechanism behind remain unresolved. In this work, we theoretically prove that the sparsity of network weights is closely associated with model robustness. Through experiments on a variety of adversarial pruning methods, we find that weights sparsity will not hurt but improve robustness, where both weights inheritance from the lottery ticket and adversarial training improve model robustness in network pruning. Based on these findings, we propose a novel adversarial training method called inverse weights inheritance, which imposes sparse weights distribution on a large network by inheriting weights from a small network, thereby improving the robustness of the large network.