 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight Field Reconstruction Using Convolutional Network on EPI and Extended Applications
Mar 24, 2021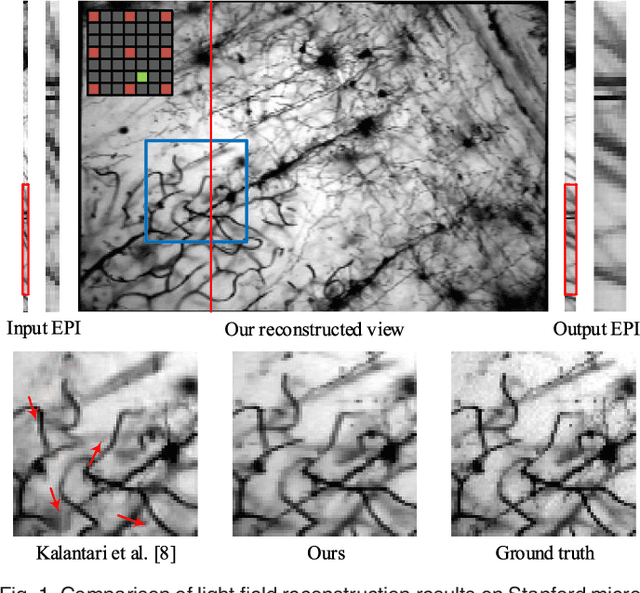
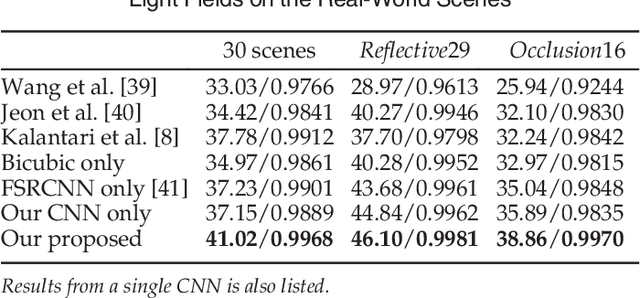


In this paper, a novel convolutional neural network (CNN)-based framework is developed for light field reconstruction from a sparse set of views. We indicate that the reconstruction can be efficiently modeled as angular restoration on an epipolar plane image (EPI). The main problem in direct reconstruction on the EPI involves an information asymmetry between the spatial and angular dimensions, where the detailed portion in the angular dimensions is damaged by undersampling. Directly upsampling or super-resolving the light field in the angular dimensions causes ghosting effects. To suppress these ghosting effects, we contribute a novel "blur-restoration-deblur" framework. First, the "blur" step is applied to extract the low-frequency components of the light field in the spatial dimensions by convolving each EPI slice with a selected blur kernel. Then, the "restoration" step is implemented by a CNN, which is trained to restore the angular details of the EPI. Finally, we use a non-blind "deblur" operation to recover the spatial high frequencies suppressed by the EPI blur. We evaluate our approach on several datasets, including synthetic scenes, real-world scenes and challenging microscope light field data. We demonstrate the high performance and robustness of the proposed framework compared with state-of-the-art algorithms. We further show extended applications, including depth enhancement and interpolation for unstructured input. More importantly, a novel rendering approach is presented by combining the proposed framework and depth information to handle large disparities.
* Published in IEEE TPAMI, 2019
Plug-and-Play Algorithms for Video Snapshot Compressive Imaging
Jan 13, 2021
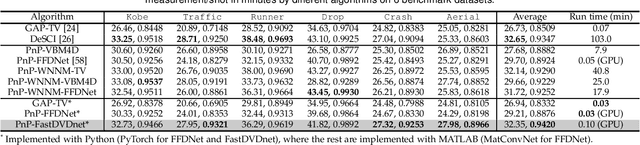


We consider the reconstruction problem of video snapshot compressive imaging (SCI), which captures high-speed videos using a low-speed 2D sensor (detector). The underlying principle of SCI is to modulate sequential high-speed frames with different masks and then these encoded frames are integrated into a snapshot on the sensor and thus the sensor can be of low-speed. On one hand, video SCI enjoys the advantages of low-bandwidth, low-power and low-cost. On the other hand, applying SCI to large-scale problems (HD or UHD videos) in our daily life is still challenging and one of the bottlenecks lies in the reconstruction algorithm. Exiting algorithms are either too slow (iterative optimization algorithms) or not flexible to the encoding process (deep learning based end-to-end networks). In this paper, we develop fast and flexible algorithms for SCI based on the plug-and-play (PnP) framework. In addition to the PnP-ADMM method, we further propose the PnP-GAP (generalized alternating projection) algorithm with a lower computational workload. We first employ the image deep denoising priors to show that PnP can recover a UHD color video with 30 frames from a snapshot measurement. Since videos have strong temporal correlation, by employing the video deep denoising priors, we achieve a significant improvement in the results. Furthermore, we extend the proposed PnP algorithms to the color SCI system using mosaic sensors, where each pixel only captures the red, green or blue channels. A joint reconstruction and demosaicing paradigm is developed for flexible and high quality reconstruction of color video SCI systems. Extensive results on both simulation and real datasets verify the superiority of our proposed algorithm.
PoNA: Pose-guided Non-local Attention for Human Pose Transfer
Dec 13, 2020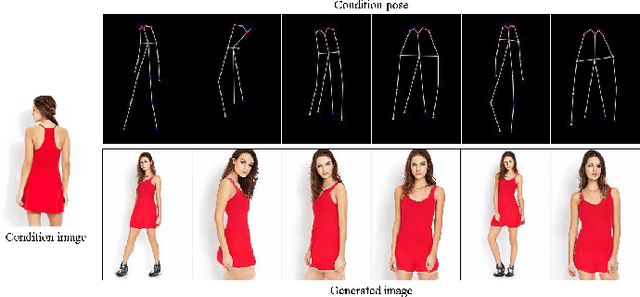

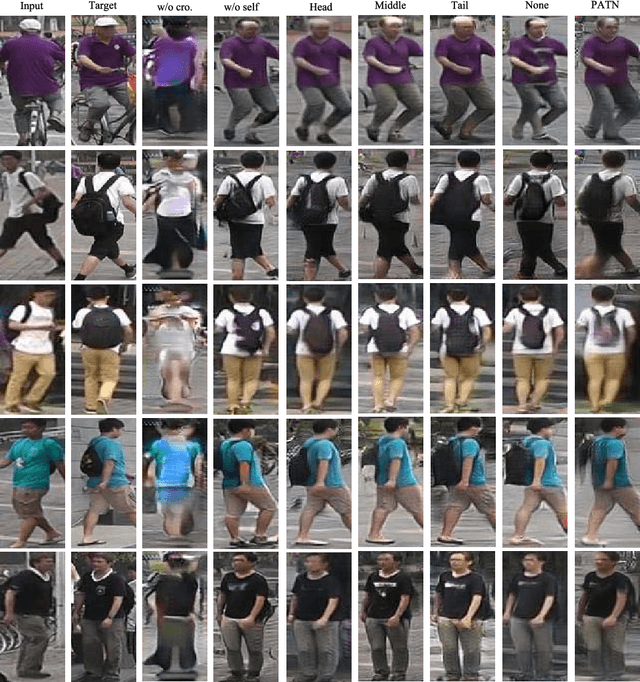
Human pose transfer, which aims at transferring the appearance of a given person to a target pose, is very challenging and important in many applications. Previous work ignores the guidance of pose features or only uses local attention mechanism, leading to implausible and blurry results. We propose a new human pose transfer method using a generative adversarial network (GAN) with simplified cascaded blocks. In each block, we propose a pose-guided non-local attention (PoNA) mechanism with a long-range dependency scheme to select more important regions of image features to transfer. We also design pre-posed image-guided pose feature update and post-posed pose-guided image feature update to better utilize the pose and image features. Our network is simple, stable, and easy to train. Quantitative and qualitative results on Market-1501 and DeepFashion datasets show the efficacy and efficiency of our model. Compared with state-of-the-art methods, our model generates sharper and more realistic images with rich details, while having fewer parameters and faster speed. Furthermore, our generated images can help to alleviate data insufficiency for person re-identification.
* 16 pages, 14 figures
Vehicle Reconstruction and Texture Estimation Using Deep Implicit Semantic Template Mapping
Nov 30, 2020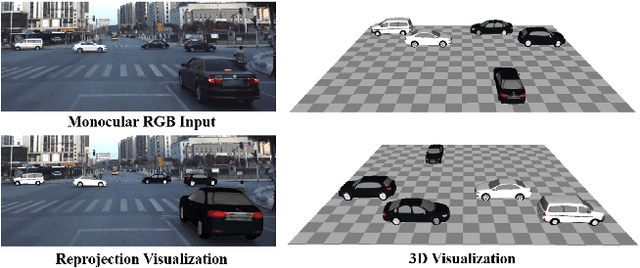
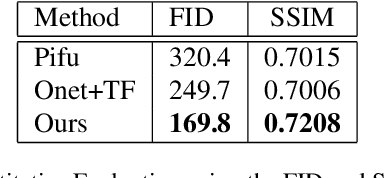
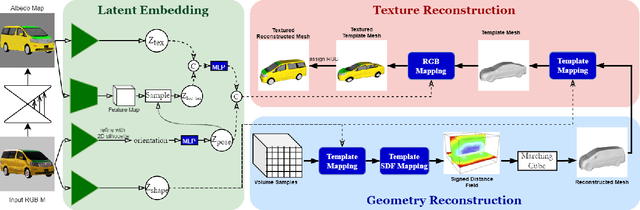
We introduce VERTEX, an effective solution to recover 3D shape and intrinsic texture of vehicles from uncalibrated monocular input in real-world street environments. To fully utilize the template prior of vehicles, we propose a novel geometry and texture joint representation, based on implicit semantic template mapping. Compared to existing representations which infer 3D texture distribution, our method explicitly constrains the texture distribution on the 2D surface of the template as well as avoids limitations of fixed resolution and topology. Moreover, by fusing the global and local features together, our approach is capable to generate consistent and detailed texture in both visible and invisible areas. We also contribute a new synthetic dataset containing 830 elaborate textured car models labeled with sparse key points and rendered using Physically Based Rendering (PBRT) system with measured HDRI skymaps to obtain highly realistic images. Experiments demonstrate the superior performance of our approach on both testing dataset and in-the-wild images. Furthermore, the presented technique enables additional applications such as 3D vehicle texture transfer and material identification.
Deep Implicit Templates for 3D Shape Representation
Nov 30, 2020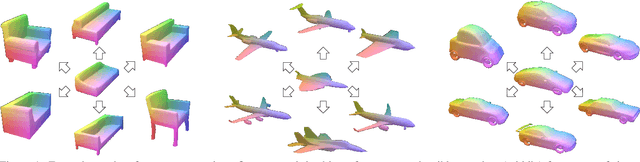

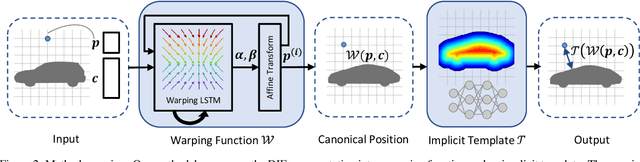
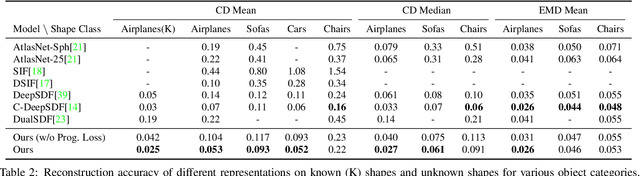
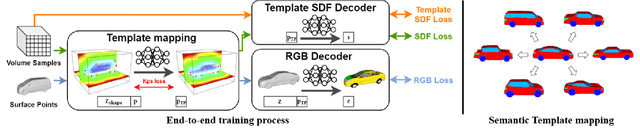
Deep implicit functions (DIFs), as a kind of 3D shape representation, are becoming more and more popular in the 3D vision community due to their compactness and strong representation power. However, unlike polygon mesh-based templates, it remains a challenge to reason dense correspondences or other semantic relationships across shapes represented by DIFs, which limits its applications in texture transfer, shape analysis and so on. To overcome this limitation and also make DIFs more interpretable, we propose Deep Implicit Templates, a new 3D shape representation that supports explicit correspondence reasoning in deep implicit representations. Our key idea is to formulate DIFs as conditional deformations of a template implicit function. To this end, we propose Spatial Warping LSTM, which decomposes the conditional spatial transformation into multiple affine transformations and guarantees generalization capability. Moreover, the training loss is carefully designed in order to achieve high reconstruction accuracy while learning a plausible template with accurate correspondences in an unsupervised manner. Experiments show that our method can not only learn a common implicit template for a collection of shapes, but also establish dense correspondences across all the shapes simultaneously without any supervision.
Large-scale neuromorphic optoelectronic computing with a reconfigurable diffractive processing unit
Aug 26, 2020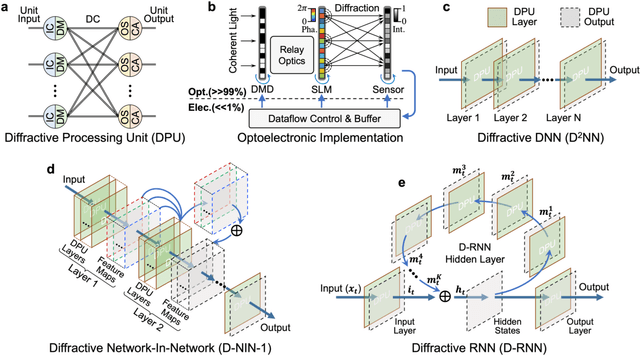
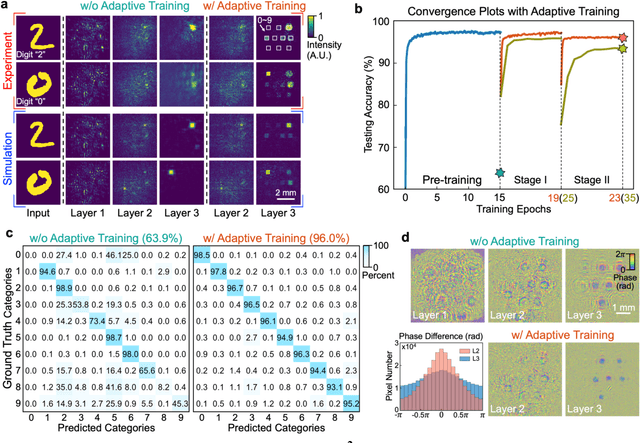
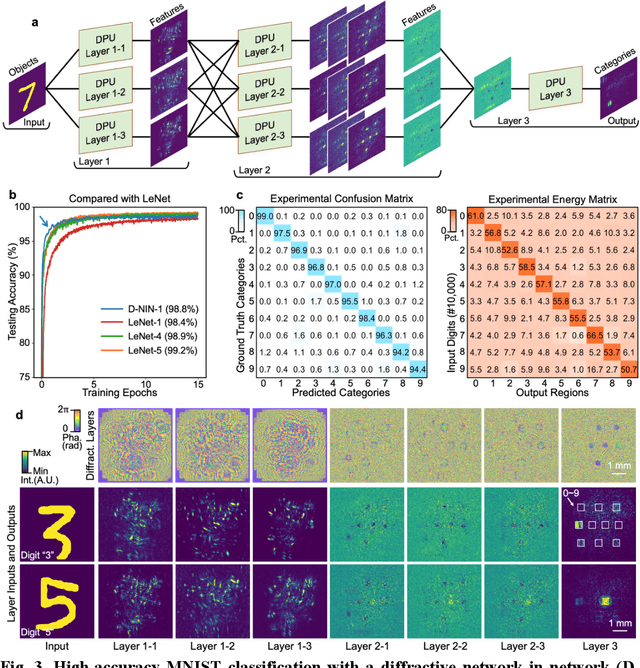
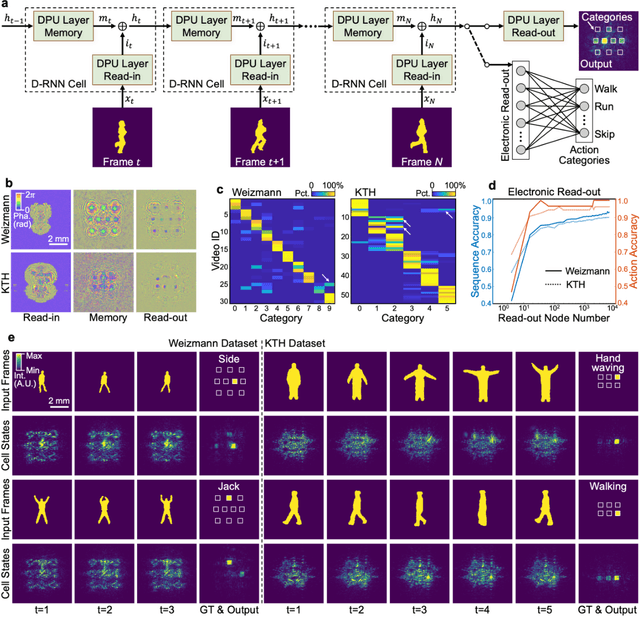
Application-specific optical processors have been considered disruptive technologies for modern computing that can fundamentally accelerate the development of artificial intelligence (AI) by offering substantially improved computing performance. Recent advancements in optical neural network architectures for neural information processing have been applied to perform various machine learning tasks. However, the existing architectures have limited complexity and performance; and each of them requires its own dedicated design that cannot be reconfigured to switch between different neural network models for different applications after deployment. Here, we propose an optoelectronic reconfigurable computing paradigm by constructing a diffractive processing unit (DPU) that can efficiently support different neural networks and achieve a high model complexity with millions of neurons. It allocates almost all of its computational operations optically and achieves extremely high speed of data modulation and large-scale network parameter updating by dynamically programming optical modulators and photodetectors. We demonstrated the reconfiguration of the DPU to implement various diffractive feedforward and recurrent neural networks and developed a novel adaptive training approach to circumvent the system imperfections. We applied the trained networks for high-speed classifying of handwritten digit images and human action videos over benchmark datasets, and the experimental results revealed a comparable classification accuracy to the electronic computing approaches. Furthermore, our prototype system built with off-the-shelf optoelectronic components surpasses the performance of state-of-the-art graphics processing units (GPUs) by several times on computing speed and more than an order of magnitude on system energy efficiency.
PaMIR: Parametric Model-Conditioned Implicit Representation for Image-based Human Reconstruction
Jul 08, 2020
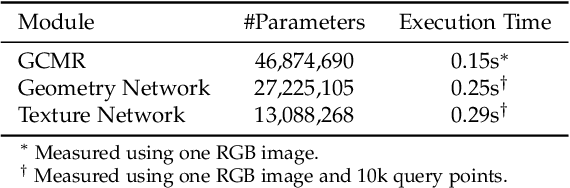
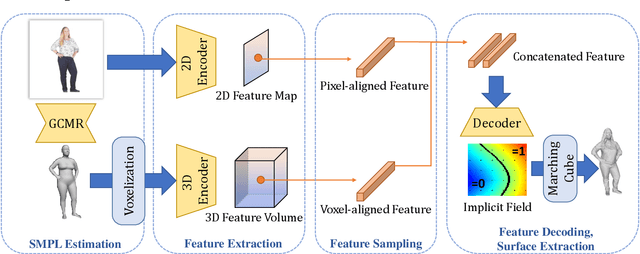
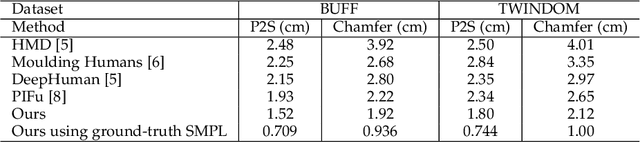
Modeling 3D humans accurately and robustly from a single image is very challenging, and the key for such an ill-posed problem is the 3D representation of the human models. To overcome the limitations of regular 3D representations, we propose Parametric Model-Conditioned Implicit Representation (PaMIR), which combines the parametric body model with the free-form deep implicit function. In our PaMIR-based reconstruction framework, a novel deep neural network is proposed to regularize the free-form deep implicit function using the semantic features of the parametric model, which improves the generalization ability under the scenarios of challenging poses and various clothing topologies. Moreover, a novel depth-ambiguity-aware training loss is further integrated to resolve depth ambiguities and enable successful surface detail reconstruction with imperfect body reference. Finally, we propose a body reference optimization method to improve the parametric model estimation accuracy and to enhance the consistency between the parametric model and the implicit function. With the PaMIR representation, our framework can be easily extended to multi-image input scenarios without the need of multi-camera calibration and pose synchronization. Experimental results demonstrate that our method achieves state-of-the-art performance for image-based 3D human reconstruction in the cases of challenging poses and clothing types.
SurfaceNet+: An End-to-end 3D Neural Network for Very Sparse Multi-view Stereopsis
May 26, 2020
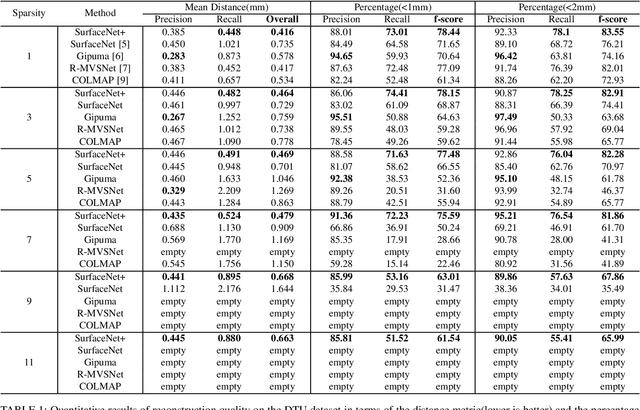
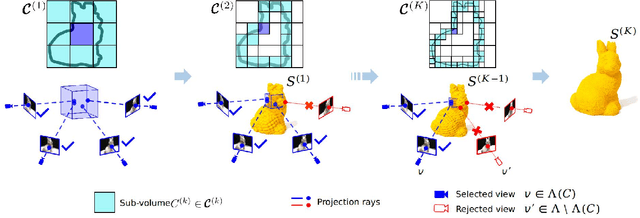
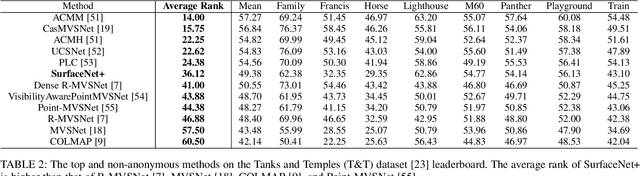
Multi-view stereopsis (MVS) tries to recover the 3D model from 2D images. As the observations become sparser, the significant 3D information loss makes the MVS problem more challenging. Instead of only focusing on densely sampled conditions, we investigate sparse-MVS with large baseline angles since the sparser sensation is more practical and more cost-efficient. By investigating various observation sparsities, we show that the classical depth-fusion pipeline becomes powerless for the case with a larger baseline angle that worsens the photo-consistency check. As another line of the solution, we present SurfaceNet+, a volumetric method to handle the 'incompleteness' and the 'inaccuracy' problems induced by a very sparse MVS setup. Specifically, the former problem is handled by a novel volume-wise view selection approach. It owns superiority in selecting valid views while discarding invalid occluded views by considering the geometric prior. Furthermore, the latter problem is handled via a multi-scale strategy that consequently refines the recovered geometry around the region with the repeating pattern. The experiments demonstrate the tremendous performance gap between SurfaceNet+ and state-of-the-art methods in terms of precision and recall. Under the extreme sparse-MVS settings in two datasets, where existing methods can only return very few points, SurfaceNet+ still works as well as in the dense MVS setting. The benchmark and the implementation are publicly available at https://github.com/mjiUST/SurfaceNet-plus.
* Accepted by IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), May 2020
Plug-and-Play Algorithms for Large-scale Snapshot Compressive Imaging
Mar 30, 2020
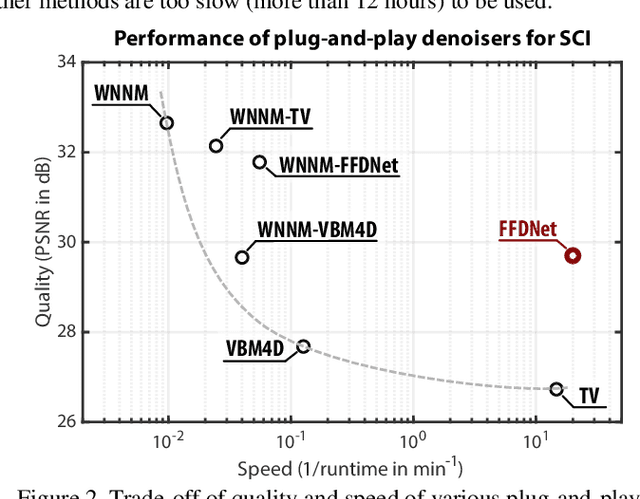
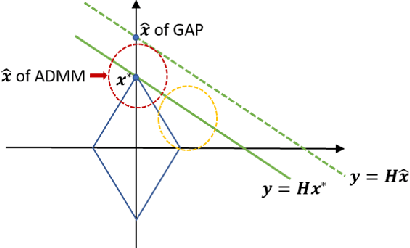
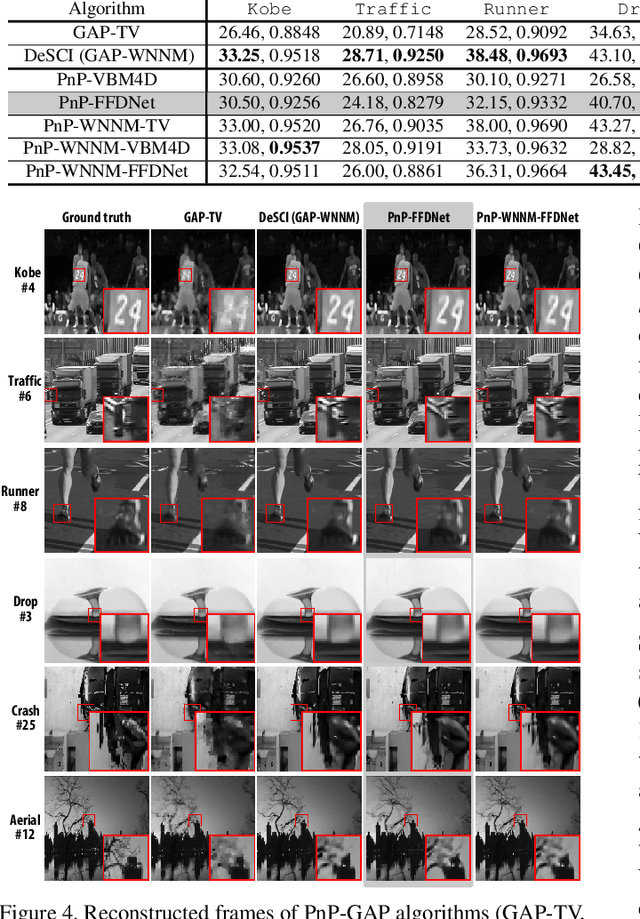
Snapshot compressive imaging (SCI) aims to capture the high-dimensional (usually 3D) images using a 2D sensor (detector) in a single snapshot. Though enjoying the advantages of low-bandwidth, low-power and low-cost, applying SCI to large-scale problems (HD or UHD videos) in our daily life is still challenging. The bottleneck lies in the reconstruction algorithms; they are either too slow (iterative optimization algorithms) or not flexible to the encoding process (deep learning based end-to-end networks). In this paper, we develop fast and flexible algorithms for SCI based on the plug-and-play (PnP) framework. In addition to the widely used PnP-ADMM method, we further propose the PnP-GAP (generalized alternating projection) algorithm with a lower computational workload and prove the {global convergence} of PnP-GAP under the SCI hardware constraints. By employing deep denoising priors, we first time show that PnP can recover a UHD color video ($3840\times 1644\times 48$ with PNSR above 30dB) from a snapshot 2D measurement. Extensive results on both simulation and real datasets verify the superiority of our proposed algorithm. The code is available at https://github.com/liuyang12/PnP-SCI.
PANDA: A Gigapixel-level Human-centric Video Dataset
Mar 10, 2020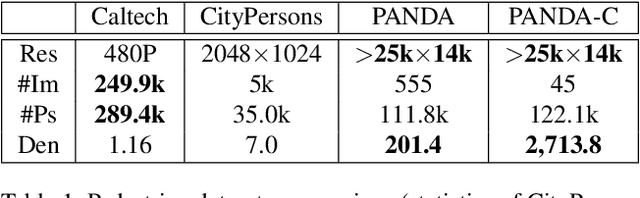

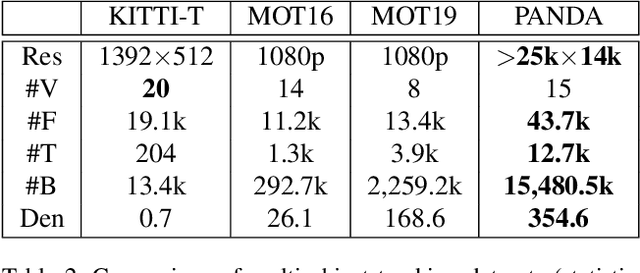
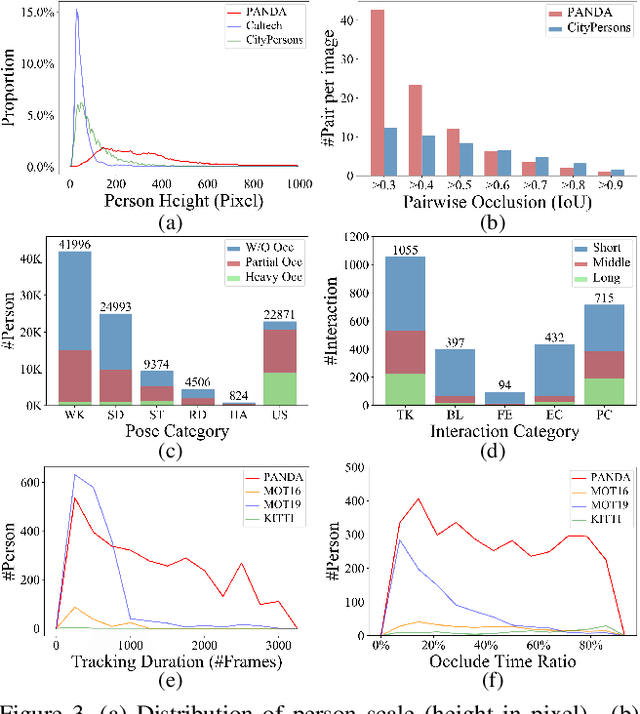
We present PANDA, the first gigaPixel-level humAN-centric viDeo dAtaset, for large-scale, long-term, and multi-object visual analysis. The videos in PANDA were captured by a gigapixel camera and cover real-world scenes with both wide field-of-view (~1 square kilometer area) and high-resolution details (~gigapixel-level/frame). The scenes may contain 4k head counts with over 100x scale variation. PANDA provides enriched and hierarchical ground-truth annotations, including 15,974.6k bounding boxes, 111.8k fine-grained attribute labels, 12.7k trajectories, 2.2k groups and 2.9k interactions. We benchmark the human detection and tracking tasks. Due to the vast variance of pedestrian pose, scale, occlusion and trajectory, existing approaches are challenged by both accuracy and efficiency. Given the uniqueness of PANDA with both wide FoV and high resolution, a new task of interaction-aware group detection is introduced. We design a 'global-to-local zoom-in' framework, where global trajectories and local interactions are simultaneously encoded, yielding promising results. We believe PANDA will contribute to the community of artificial intelligence and praxeology by understanding human behaviors and interactions in large-scale real-world scenes. PANDA Website: http://www.panda-dataset.com.