 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Set Functions Under the Optimal Subset Oracle via Equivariant Variational Inference
Mar 03, 2022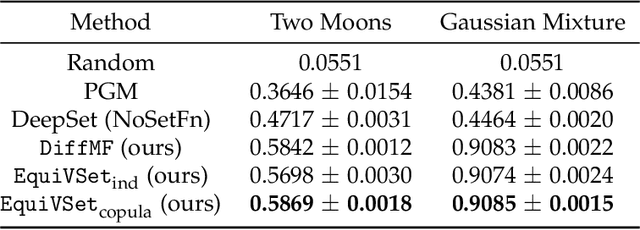
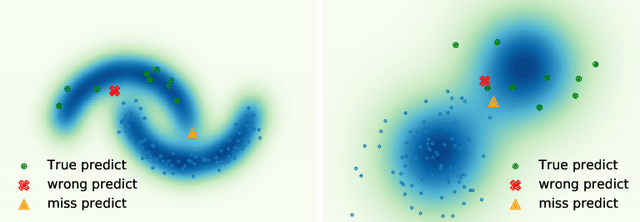
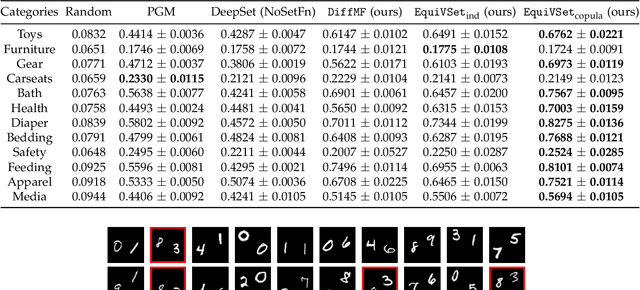

Learning set functions becomes increasingly more important in many applications like product recommendation and compound selection in AI-aided drug discovery. The majority of existing works study methodologies of set function learning under the function value oracle, which, however, requires expensive supervision signals. This renders it impractical for applications with only weak supervisions under the Optimal Subset (OS) oracle, the study of which is surprisingly overlooked. In this work, we present a principled yet practical maximum likelihood learning framework, termed as EquiVSet, that simultaneously meets the following desiderata of learning set functions under the OS oracle: i) permutation invariance of the set mass function being modeled; ii) permission of varying ground set; iii) fully differentiability; iv) minimum prior; and v) scalability. The main components of our framework involve: an energy-based treatment of the set mass function, DeepSet-style architectures to handle permutation invariance, mean-field variational inference, and its amortized variants. Although the framework is embarrassingly simple, empirical studies on three real-world applications (including Amazon product recommendation, set anomaly detection and compound selection for virtual screening) demonstrate that EquiVSet outperforms the baselines by a large margin.
Refining BERT Embeddings for Document Hashing via Mutual Information Maximization
Sep 07, 2021


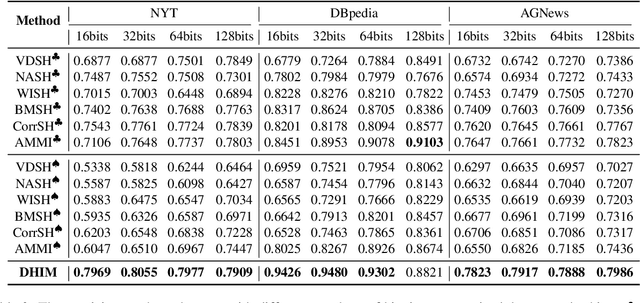
Existing unsupervised document hashing methods are mostly established on generative models. Due to the difficulties of capturing long dependency structures, these methods rarely model the raw documents directly, but instead to model the features extracted from them (e.g. bag-of-words (BOW), TFIDF). In this paper, we propose to learn hash codes from BERT embeddings after observing their tremendous successes on downstream tasks. As a first try, we modify existing generative hashing models to accommodate the BERT embeddings. However, little improvement is observed over the codes learned from the old BOW or TFIDF features. We attribute this to the reconstruction requirement in the generative hashing, which will enforce irrelevant information that is abundant in the BERT embeddings also compressed into the codes. To remedy this issue, a new unsupervised hashing paradigm is further proposed based on the mutual information (MI) maximization principle. Specifically, the method first constructs appropriate global and local codes from the documents and then seeks to maximize their mutual information. Experimental results on three benchmark datasets demonstrate that the proposed method is able to generate hash codes that outperform existing ones learned from BOW features by a substantial margin.
Integrating Semantics and Neighborhood Information with Graph-Driven Generative Models for Document Retrieval
May 27, 2021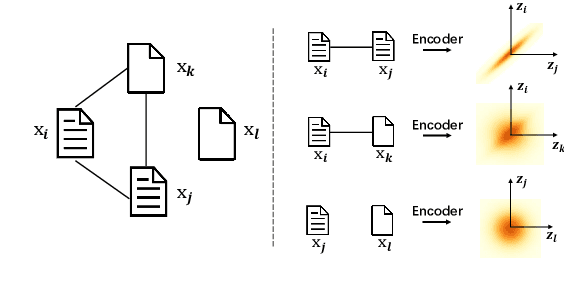
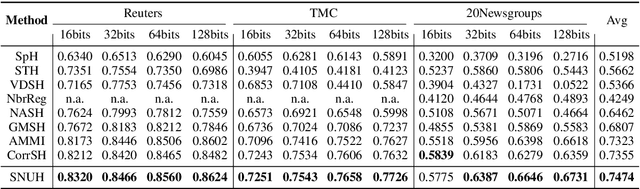
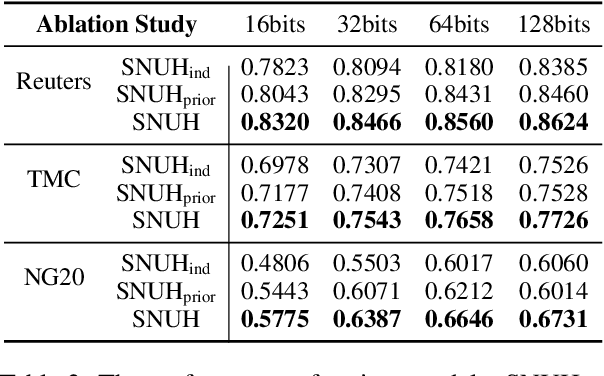
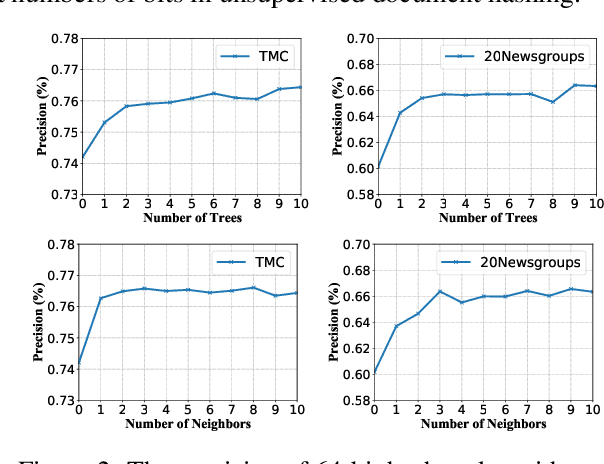
With the need of fast retrieval speed and small memory footprint, document hashing has been playing a crucial role in large-scale information retrieval. To generate high-quality hashing code, both semantics and neighborhood information are crucial. However, most existing methods leverage only one of them or simply combine them via some intuitive criteria, lacking a theoretical principle to guide the integration process. In this paper, we encode the neighborhood information with a graph-induced Gaussian distribution, and propose to integrate the two types of information with a graph-driven generative model. To deal with the complicated correlations among documents, we further propose a tree-structured approximation method for learning. Under the approximation, we prove that the training objective can be decomposed into terms involving only singleton or pairwise documents, enabling the model to be trained as efficiently as uncorrelated ones. Extensive experimental results on three benchmark datasets show that our method achieves superior performance over state-of-the-art methods, demonstrating the effectiveness of the proposed model for simultaneously preserving semantic and neighborhood information.\
Unsupervised Hashing with Contrastive Information Bottleneck
May 19, 2021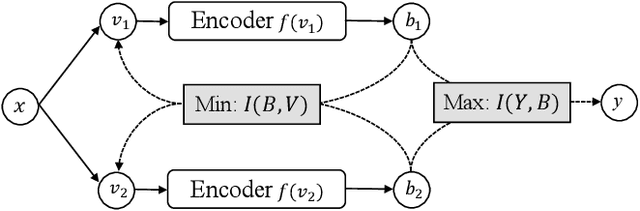
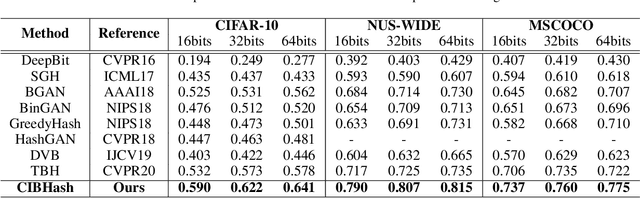
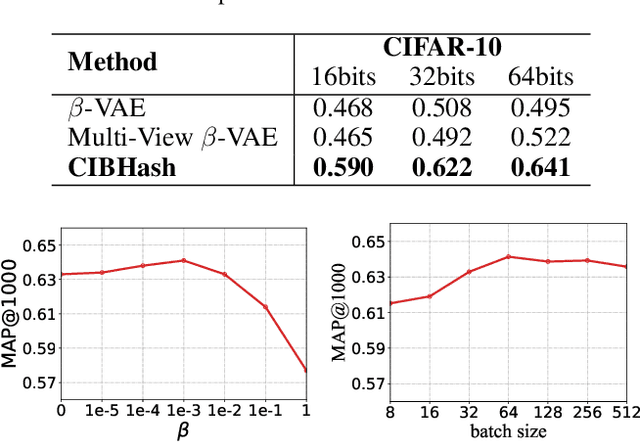
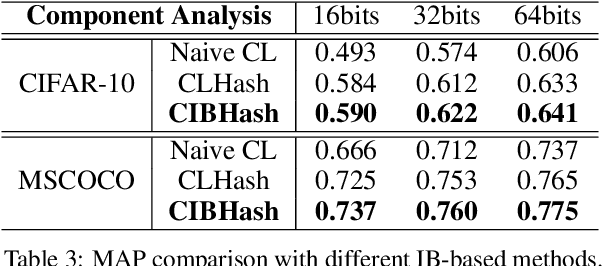
Many unsupervised hashing methods are implicitly established on the idea of reconstructing the input data, which basically encourages the hashing codes to retain as much information of original data as possible. However, this requirement may force the models spending lots of their effort on reconstructing the unuseful background information, while ignoring to preserve the discriminative semantic information that is more important for the hashing task. To tackle this problem, inspired by the recent success of contrastive learning in learning continuous representations, we propose to adapt this framework to learn binary hashing codes. Specifically, we first propose to modify the objective function to meet the specific requirement of hashing and then introduce a probabilistic binary representation layer into the model to facilitate end-to-end training of the entire model. We further prove the strong connection between the proposed contrastive-learning-based hashing method and the mutual information, and show that the proposed model can be considered under the broader framework of the information bottleneck (IB). Under this perspective, a more general hashing model is naturally obtained. Extensive experimental results on three benchmark image datasets demonstrate that the proposed hashing method significantly outperforms existing baselines.
Syntax-Enhanced Pre-trained Model
Dec 28, 2020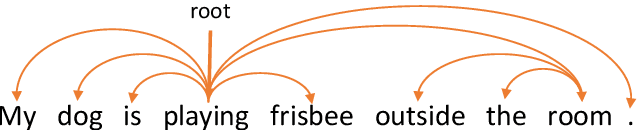
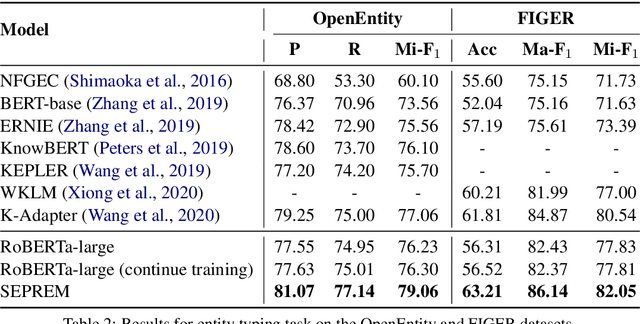
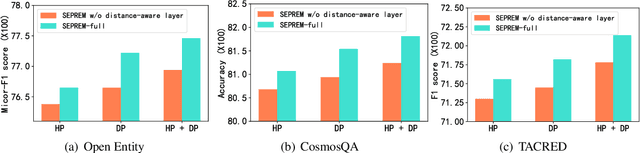
We study the problem of leveraging the syntactic structure of text to enhance pre-trained models such as BERT and RoBERTa. Existing methods utilize syntax of text either in the pre-training stage or in the fine-tuning stage, so that they suffer from discrepancy between the two stages. Such a problem would lead to the necessity of having human-annotated syntactic information, which limits the application of existing methods to broader scenarios. To address this, we present a model that utilizes the syntax of text in both pre-training and fine-tuning stages. Our model is based on Transformer with a syntax-aware attention layer that considers the dependency tree of the text. We further introduce a new pre-training task of predicting the syntactic distance among tokens in the dependency tree. We evaluate the model on three downstream tasks, including relation classification, entity typing, and question answering. Results show that our model achieves state-of-the-art performance on six public benchmark datasets. We have two major findings. First, we demonstrate that infusing automatically produced syntax of text improves pre-trained models. Second, global syntactic distances among tokens bring larger performance gains compared to local head relations between contiguous tokens.
Generative Semantic Hashing Enhanced via Boltzmann Machines
Jun 16, 2020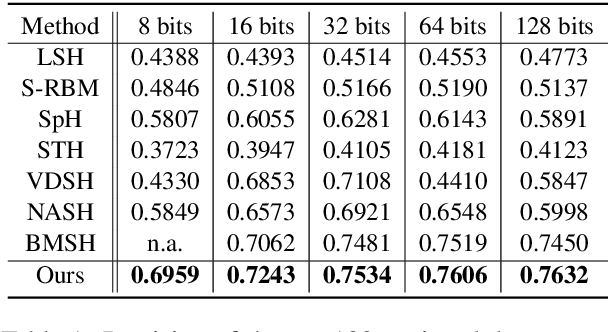
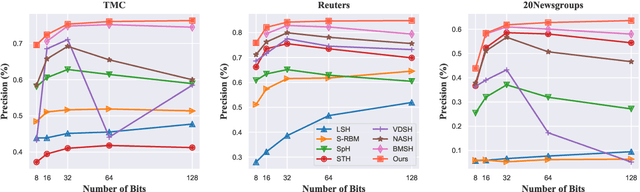
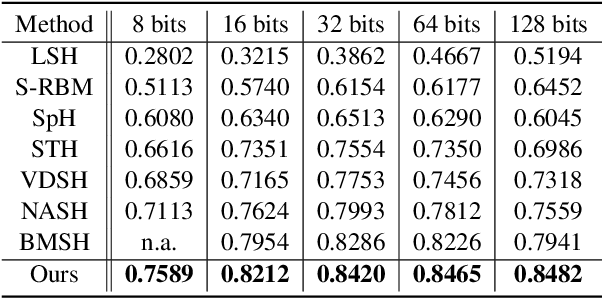

Generative semantic hashing is a promising technique for large-scale information retrieval thanks to its fast retrieval speed and small memory footprint. For the tractability of training, existing generative-hashing methods mostly assume a factorized form for the posterior distribution, enforcing independence among the bits of hash codes. From the perspectives of both model representation and code space size, independence is always not the best assumption. In this paper, to introduce correlations among the bits of hash codes, we propose to employ the distribution of Boltzmann machine as the variational posterior. To address the intractability issue of training, we first develop an approximate method to reparameterize the distribution of a Boltzmann machine by augmenting it as a hierarchical concatenation of a Gaussian-like distribution and a Bernoulli distribution. Based on that, an asymptotically-exact lower bound is further derived for the evidence lower bound (ELBO). With these novel techniques, the entire model can be optimized efficiently. Extensive experimental results demonstrate that by effectively modeling correlations among different bits within a hash code, our model can achieve significant performance gains.
Discretized Bottleneck in VAE: Posterior-Collapse-Free Sequence-to-Sequence Learning
Apr 22, 2020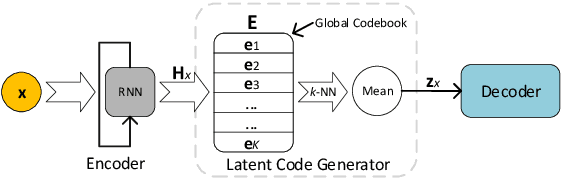
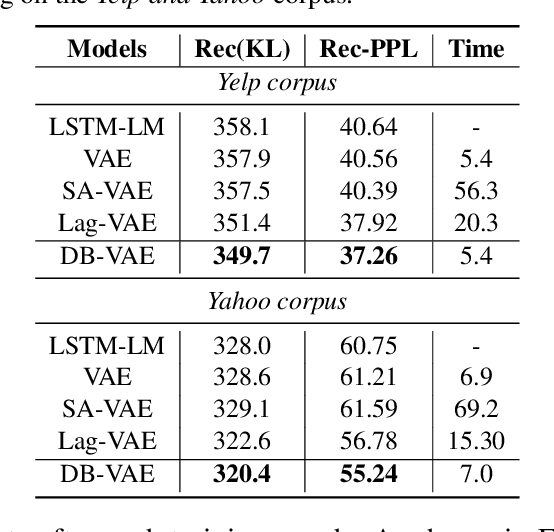
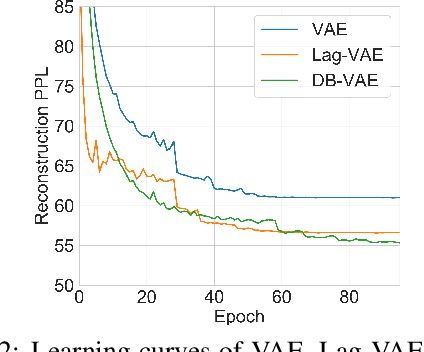

Variational autoencoders (VAEs) are important tools in end-to-end representation learning. VAEs can capture complex data distributions and have been applied extensively in many natural-language-processing (NLP) tasks. However, a common pitfall in sequence-to-sequence learning with VAEs is the posterior-collapse issue in latent space, wherein the model tends to ignore latent variables when a strong auto-regressive decoder is implemented. In this paper, we propose a principled approach to eliminate this issue by applying a discretized bottleneck in the latent space. Specifically, we impose a shared discrete latent space where each input is learned to choose a combination of shared latent atoms as its latent representation. Compared with VAEs employing continuous latent variables, our model endows more promising capability in modeling underlying semantics of discrete sequences and can thus provide more interpretative latent structures. Empirically, we demonstrate the efficiency and effectiveness of our model on a broad range of tasks, including language modeling, unaligned text style transfer, dialog response generation, and neural machine translation.
Document Hashing with Mixture-Prior Generative Models
Aug 29, 2019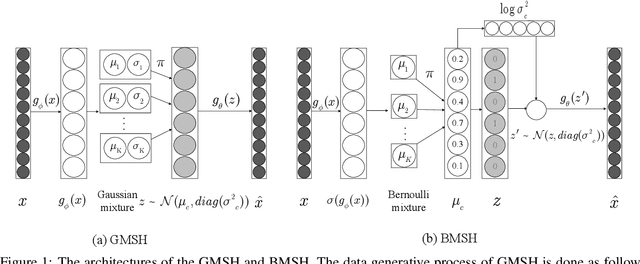
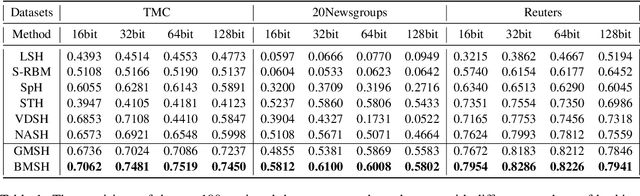
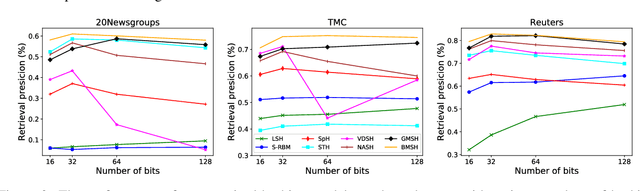
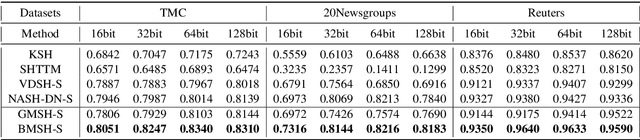
Hashing is promising for large-scale information retrieval tasks thanks to the efficiency of distance evaluation between binary codes. Generative hashing is often used to generate hashing codes in an unsupervised way. However, existing generative hashing methods only considered the use of simple priors, like Gaussian and Bernoulli priors, which limits these methods to further improve their performance. In this paper, two mixture-prior generative models are proposed, under the objective to produce high-quality hashing codes for documents. Specifically, a Gaussian mixture prior is first imposed onto the variational auto-encoder (VAE), followed by a separate step to cast the continuous latent representation of VAE into binary code. To avoid the performance loss caused by the separate casting, a model using a Bernoulli mixture prior is further developed, in which an end-to-end training is admitted by resorting to the straight-through (ST) discrete gradient estimator. Experimental results on several benchmark datasets demonstrate that the proposed methods, especially the one using Bernoulli mixture priors, consistently outperform existing ones by a substantial margin.
A Deep Neural Information Fusion Architecture for Textual Network Embeddings
Aug 29, 2019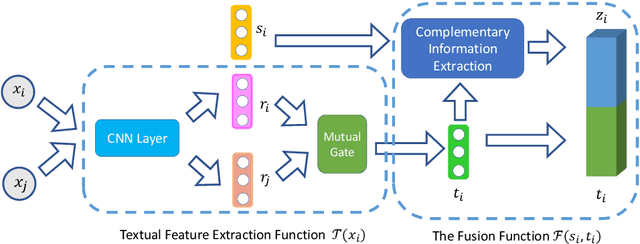
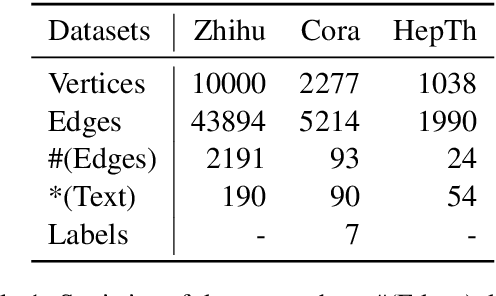
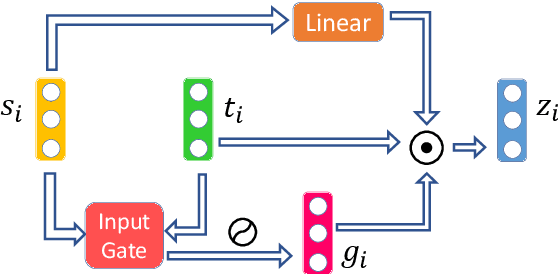
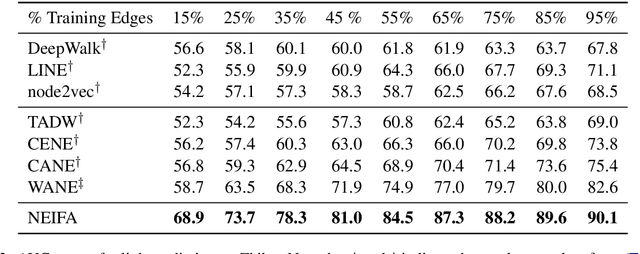
Textual network embeddings aim to learn a low-dimensional representation for every node in the network so that both the structural and textual information from the networks can be well preserved in the representations. Traditionally, the structural and textual embeddings were learned by models that rarely take the mutual influences between them into account. In this paper, a deep neural architecture is proposed to effectively fuse the two kinds of informations into one representation. The novelties of the proposed architecture are manifested in the aspects of a newly defined objective function, the complementary information fusion method for structural and textual features, and the mutual gate mechanism for textual feature extraction. Experimental results show that the proposed model outperforms the comparing methods on all three datasets.
Baseline Needs More Love: On Simple Word-Embedding-Based Models and Associated Pooling Mechanisms
May 24, 2018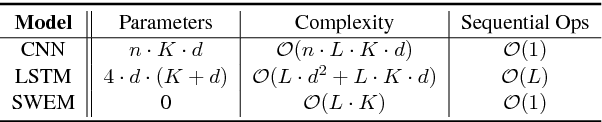
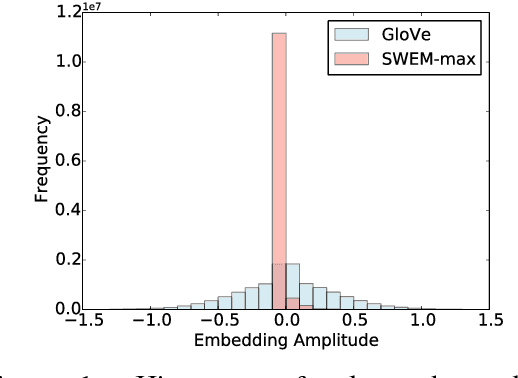

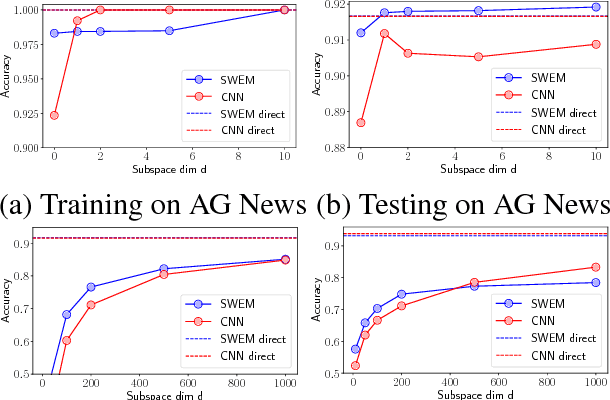
Many deep learning architectures have been proposed to model the compositionality in text sequences, requiring a substantial number of parameters and expensive computations. However, there has not been a rigorous evaluation regarding the added value of sophisticated compositional functions. In this paper, we conduct a point-by-point comparative study between Simple Word-Embedding-based Models (SWEMs), consisting of parameter-free pooling operations, relative to word-embedding-based RNN/CNN models. Surprisingly, SWEMs exhibit comparable or even superior performance in the majority of cases considered. Based upon this understanding, we propose two additional pooling strategies over learned word embeddings: (i) a max-pooling operation for improved interpretability; and (ii) a hierarchical pooling operation, which preserves spatial (n-gram) information within text sequences. We present experiments on 17 datasets encompassing three tasks: (i) (long) document classification; (ii) text sequence matching; and (iii) short text tasks, including classification and tagging. The source code and datasets can be obtained from https:// github.com/dinghanshen/SWEM.