 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistic Rules-Based Corpus Generation for Native Chinese Grammatical Error Correction
Oct 19, 2022
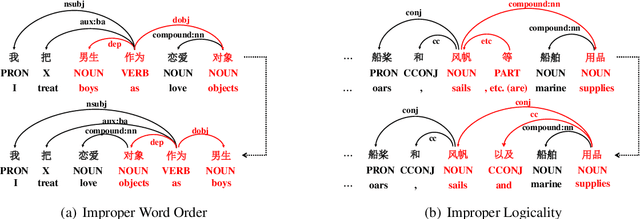
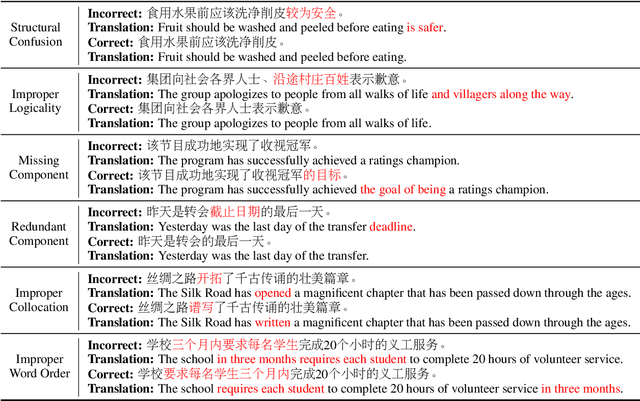
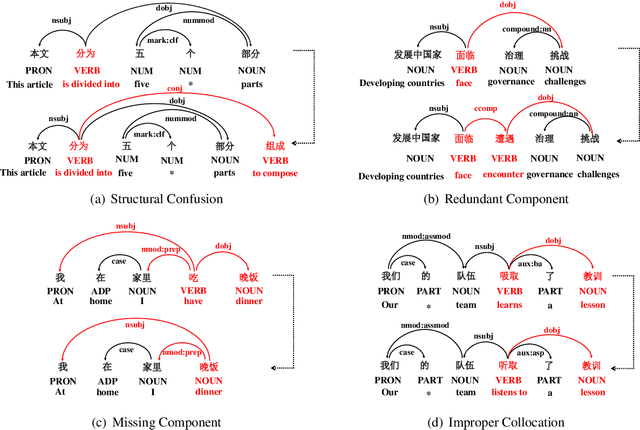
Chinese Grammatical Error Correction (CGEC) is both a challenging NLP task and a common application in human daily life. Recently, many data-driven approaches are proposed for the development of CGEC research. However, there are two major limitations in the CGEC field: First, the lack of high-quality annotated training corpora prevents the performance of existing CGEC models from being significantly improved. Second, the grammatical errors in widely used test sets are not made by native Chinese speakers, resulting in a significant gap between the CGEC models and the real application. In this paper, we propose a linguistic rules-based approach to construct large-scale CGEC training corpora with automatically generated grammatical errors. Additionally, we present a challenging CGEC benchmark derived entirely from errors made by native Chinese speakers in real-world scenarios. Extensive experiments and detailed analyses not only demonstrate that the training data constructed by our method effectively improves the performance of CGEC models, but also reflect that our benchmark is an excellent resource for further development of the CGEC field.
AiM: Taking Answers in Mind to Correct Chinese Cloze Tests in Educational Applications
Aug 26, 2022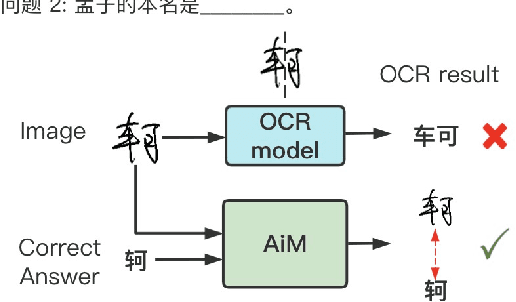
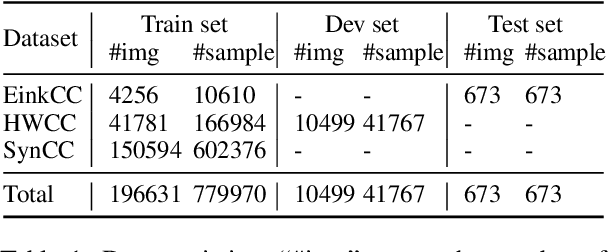
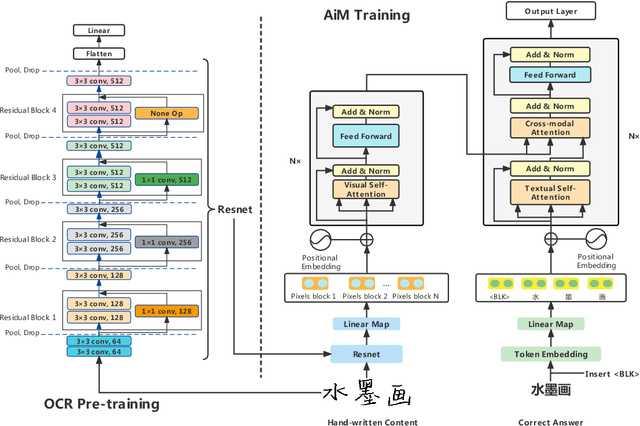
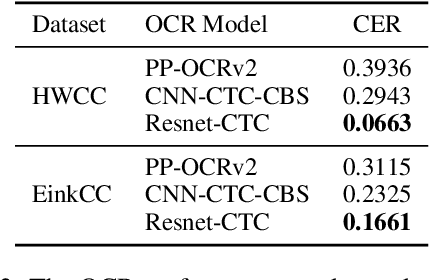
To automatically correct handwritten assignments, the traditional approach is to use an OCR model to recognize characters and compare them to answers. The OCR model easily gets confused on recognizing handwritten Chinese characters, and the textual information of the answers is missing during the model inference. However, teachers always have these answers in mind to review and correct assignments. In this paper, we focus on the Chinese cloze tests correction and propose a multimodal approach (named AiM). The encoded representations of answers interact with the visual information of students' handwriting. Instead of predicting 'right' or 'wrong', we perform the sequence labeling on the answer text to infer which answer character differs from the handwritten content in a fine-grained way. We take samples of OCR datasets as the positive samples for this task, and develop a negative sample augmentation method to scale up the training data. Experimental results show that AiM outperforms OCR-based methods by a large margin. Extensive studies demonstrate the effectiveness of our multimodal approach.
Automatic Context Pattern Generation for Entity Set Expansion
Jul 19, 2022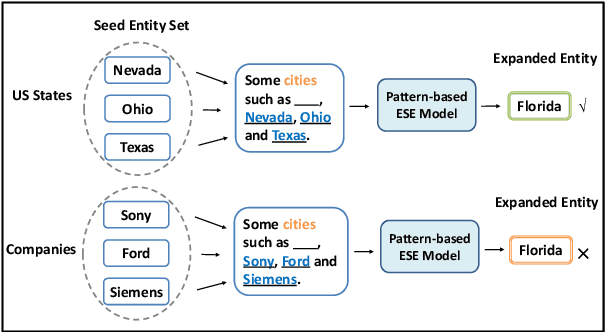

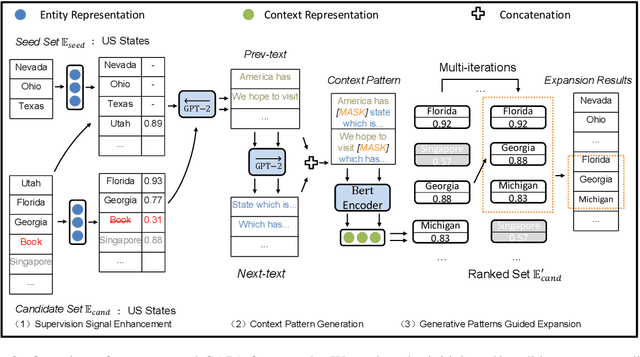
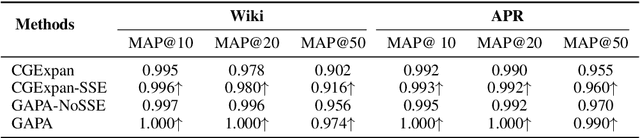
Entity Set Expansion (ESE) is a valuable task that aims to find entities of the target semantic class described by given seed entities. Various NLP and IR downstream applications have benefited from ESE due to its ability to discover knowledge. Although existing bootstrapping methods have achieved great progress, most of them still rely on manually pre-defined context patterns. A non-negligible shortcoming of the pre-defined context patterns is that they cannot be flexibly generalized to all kinds of semantic classes, and we call this phenomenon as "semantic sensitivity". To address this problem, we devise a context pattern generation module that utilizes autoregressive language models (e.g., GPT-2) to automatically generate high-quality context patterns for entities. In addition, we propose the GAPA, a novel ESE framework that leverages the aforementioned GenerAted PAtterns to expand target entities. Extensive experiments and detailed analyses on three widely used datasets demonstrate the effectiveness of our method. All the codes of our experiments will be available for reproducibility.
Contextual Similarity is More Valuable than Character Similarity: Curriculum Learning for Chinese Spell Checking
Jul 17, 2022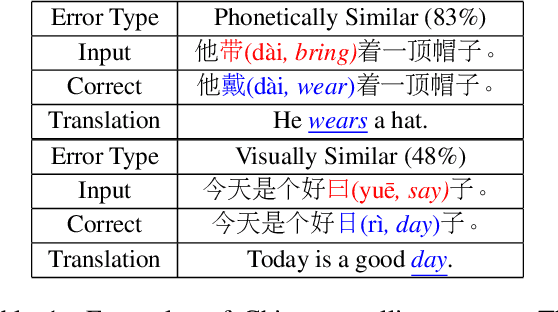
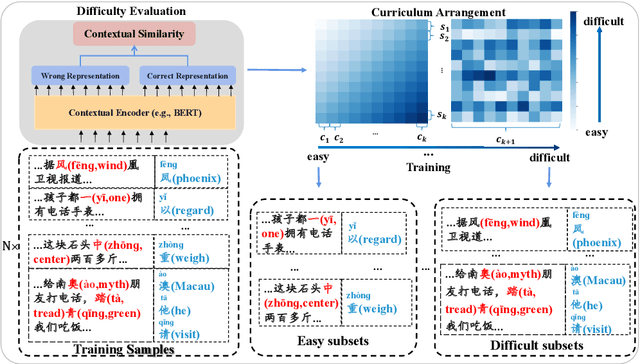
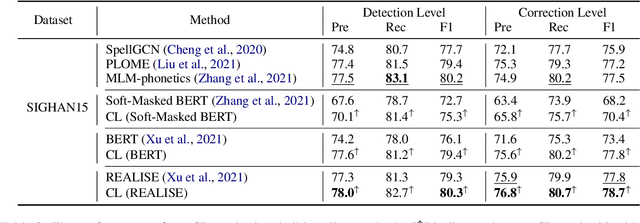
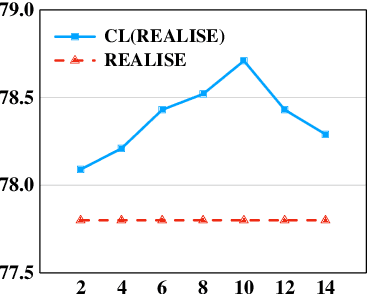
Chinese Spell Checking (CSC) task aims to detect and correct Chinese spelling errors. In recent years, related researches focus on introducing the character similarity from confusion set to enhance the CSC models, ignoring the context of characters that contain richer information. To make better use of contextual similarity, we propose a simple yet effective curriculum learning framework for the CSC task. With the help of our designed model-agnostic framework, existing CSC models will be trained from easy to difficult as humans learn Chinese characters and achieve further performance improvements. Extensive experiments and detailed analyses on widely used SIGHAN datasets show that our method outperforms previous state-of-the-art methods.
Type-Driven Multi-Turn Corrections for Grammatical Error Correction
Mar 17, 2022

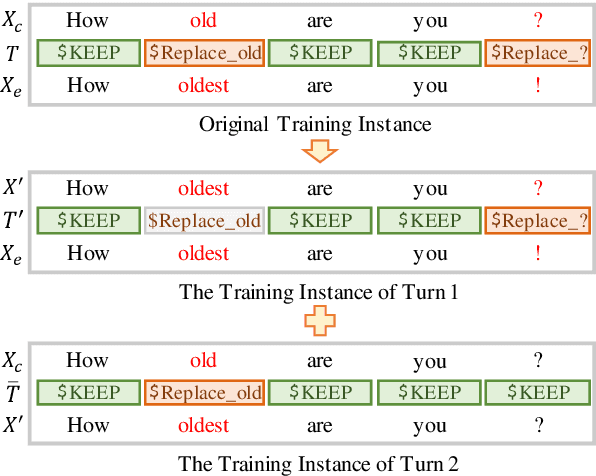
Grammatical Error Correction (GEC) aims to automatically detect and correct grammatical errors. In this aspect, dominant models are trained by one-iteration learning while performing multiple iterations of corrections during inference. Previous studies mainly focus on the data augmentation approach to combat the exposure bias, which suffers from two drawbacks. First, they simply mix additionally-constructed training instances and original ones to train models, which fails to help models be explicitly aware of the procedure of gradual corrections. Second, they ignore the interdependence between different types of corrections. In this paper, we propose a Type-Driven Multi-Turn Corrections approach for GEC. Using this approach, from each training instance, we additionally construct multiple training instances, each of which involves the correction of a specific type of errors. Then, we use these additionally-constructed training instances and the original one to train the model in turn. Experimental results and in-depth analysis show that our approach significantly benefits the model training. Particularly, our enhanced model achieves state-of-the-art single-model performance on English GEC benchmarks. We release our code at Github.
The Past Mistake is the Future Wisdom: Error-driven Contrastive Probability Optimization for Chinese Spell Checking
Mar 02, 2022
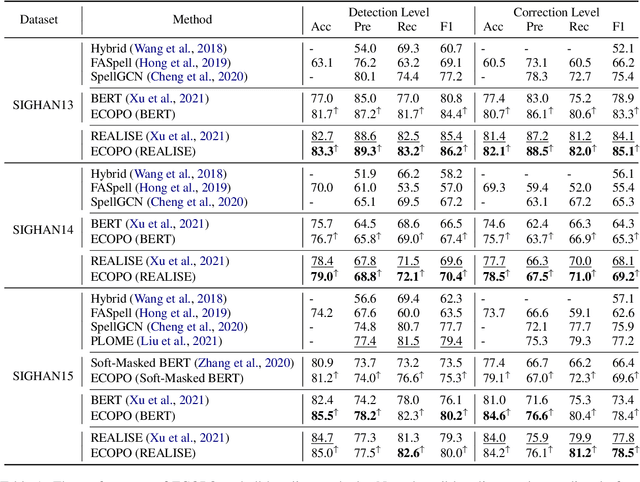
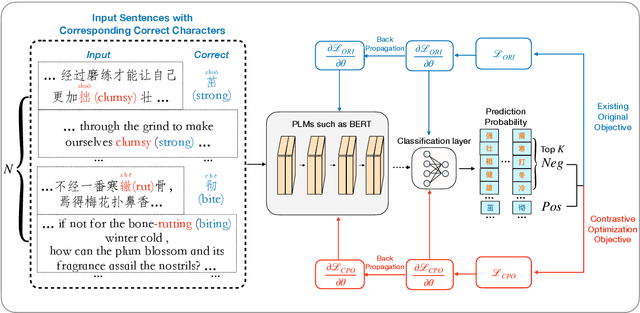
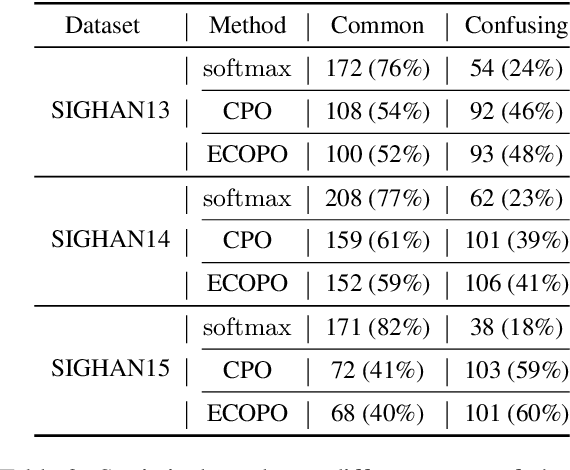
Chinese Spell Checking (CSC) aims to detect and correct Chinese spelling errors, which are mainly caused by the phonological or visual similarity. Recently, pre-trained language models (PLMs) promote the progress of CSC task. However, there exists a gap between the learned knowledge of PLMs and the goal of CSC task. PLMs focus on the semantics in text and tend to correct the erroneous characters to semantically proper or commonly used ones, but these aren't the ground-truth corrections. To address this issue, we propose an Error-driven COntrastive Probability Optimization (ECOPO) framework for CSC task. ECOPO refines the knowledge representations of PLMs, and guides the model to avoid predicting these common characters through an error-driven way. Particularly, ECOPO is model-agnostic and it can be combined with existing CSC methods to achieve better performance. Extensive experiments and detailed analyses on SIGHAN datasets demonstrate that ECOPO is simple yet effective.
A non-hierarchical attention network with modality dropout for textual response generation in multimodal dialogue systems
Oct 20, 2021
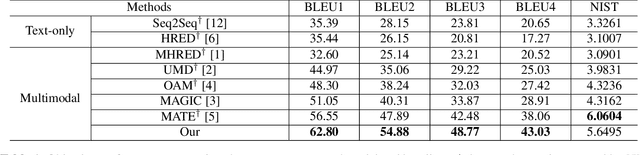
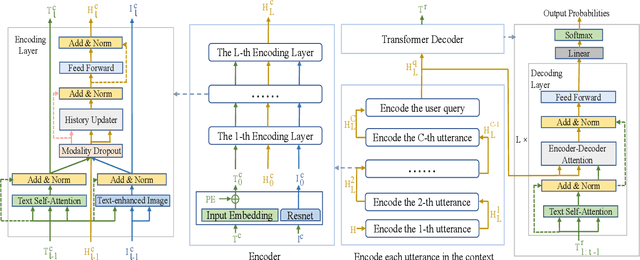

Existing text- and image-based multimodal dialogue systems use the traditional Hierarchical Recurrent Encoder-Decoder (HRED) framework, which has an utterance-level encoder to model utterance representation and a context-level encoder to model context representation. Although pioneer efforts have shown promising performances, they still suffer from the following challenges: (1) the interaction between textual features and visual features is not fine-grained enough. (2) the context representation can not provide a complete representation for the context. To address the issues mentioned above, we propose a non-hierarchical attention network with modality dropout, which abandons the HRED framework and utilizes attention modules to encode each utterance and model the context representation. To evaluate our proposed model, we conduct comprehensive experiments on a public multimodal dialogue dataset. Automatic and human evaluation demonstrate that our proposed model outperforms the existing methods and achieves state-of-the-art performance.
Seeking Patterns, Not just Memorizing Procedures: Contrastive Learning for Solving Math Word Problems
Oct 16, 2021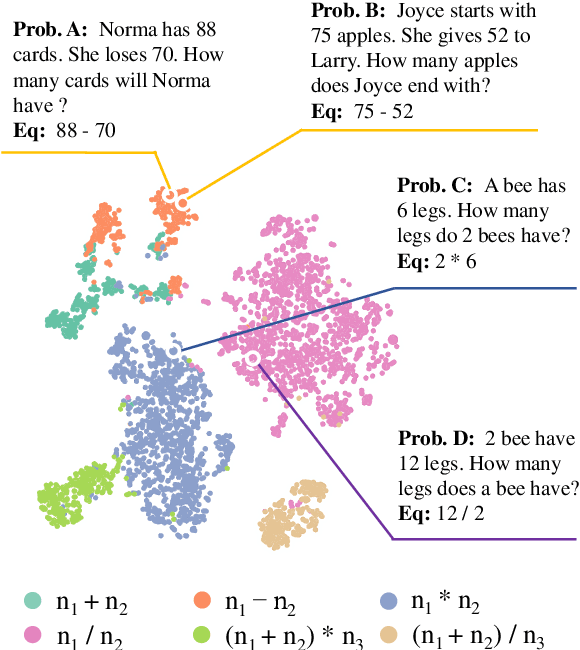

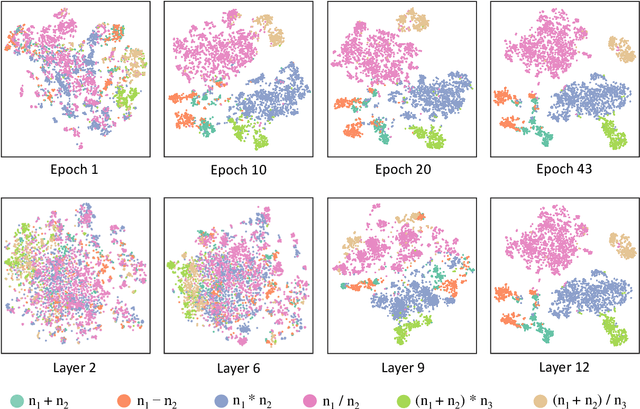
Math Word Problem (MWP) solving needs to discover the quantitative relationships over natural language narratives. Recent work shows that existing models memorize procedures from context and rely on shallow heuristics to solve MWPs. In this paper, we look at this issue and argue that the cause is a lack of overall understanding of MWP patterns. We first investigate how a neural network understands patterns only from semantics, and observe that, if the prototype equations are the same, most problems get closer representations and those representations apart from them or close to other prototypes tend to produce wrong solutions. Inspired by it, we propose a contrastive learning approach, where the neural network perceives the divergence of patterns. We collect contrastive examples by converting the prototype equation into a tree and seeking similar tree structures. The solving model is trained with an auxiliary objective on the collected examples, resulting in the representations of problems with similar prototypes being pulled closer. We conduct experiments on the Chinese dataset Math23k and the English dataset MathQA. Our method greatly improves the performance in monolingual and multilingual settings.
An Enhanced Span-based Decomposition Method for Few-Shot Sequence Labeling
Sep 27, 2021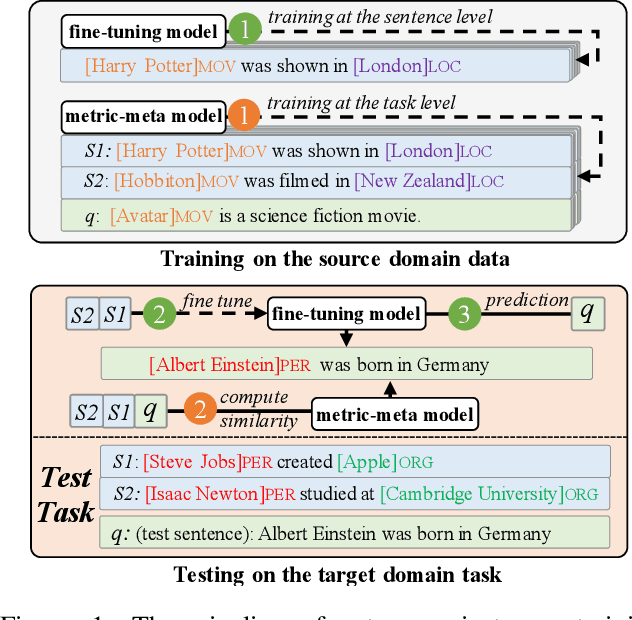

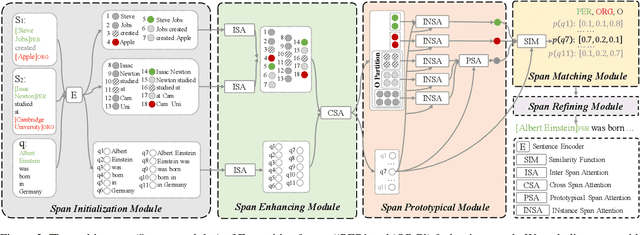
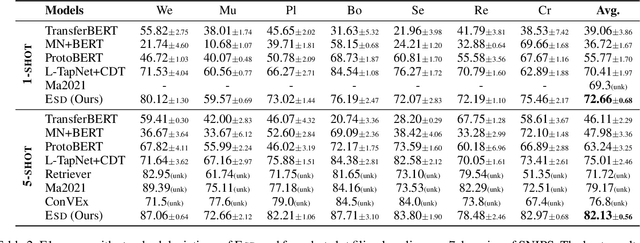
Few-Shot Sequence Labeling (FSSL) is a canonical solution for the tagging models to generalize on an emerging, resource-scarce domain. In this paper, we propose ESD, an Enhanced Span-based Decomposition method, which follows the metric-based meta-learning paradigm for FSSL. ESD improves previous methods from two perspectives: a) Introducing an optimal span decomposition framework. We formulate FSSL as an optimization problem that seeks for an optimal span matching between test query and supporting instances. During inference, we propose a post-processing algorithm to alleviate false positive labeling by resolving span conflicts. b) Enhancing representation for spans and class prototypes. We refine span representation by inter- and cross-span attention, and obtain the class prototypical representation with multi-instance learning. To avoid the semantic drift when representing the O-type (not a specific entity or slot) prototypes, we divide the O-type spans into three categories according to their boundary information. ESD outperforms previous methods in two popular FSSL benchmarks, FewNERD and SNIPS, and is proven to be more robust in the nested and noisy tagging scenarios.
Read, Listen, and See: Leveraging Multimodal Information Helps Chinese Spell Checking
May 26, 2021
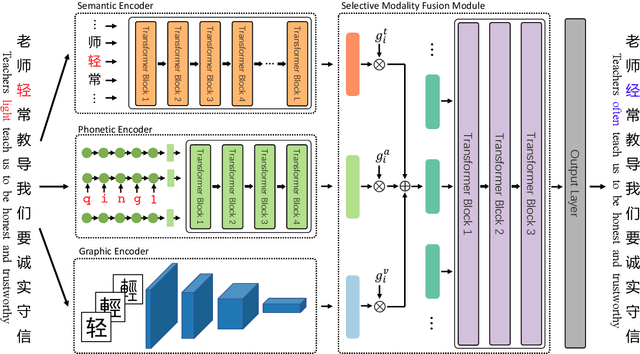

Chinese Spell Checking (CSC) aims to detect and correct erroneous characters for user-generated text in the Chinese language. Most of the Chinese spelling errors are misused semantically, phonetically or graphically similar characters. Previous attempts noticed this phenomenon and try to use the similarity for this task. However, these methods use either heuristics or handcrafted confusion sets to predict the correct character. In this paper, we propose a Chinese spell checker called ReaLiSe, by directly leveraging the multimodal information of the Chinese characters. The ReaLiSe model tackles the CSC task by (1) capturing the semantic, phonetic and graphic information of the input characters, and (2) selectively mixing the information in these modalities to predict the correct output. Experiments on the SIGHAN benchmarks show that the proposed model outperforms strong baselines by a large margin.