 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeedback Control for Multi-Objective Graph Self-Supervision
Feb 04, 2026Can multi-task self-supervised learning on graphs be coordinated without the usual tug-of-war between objectives? Graph self-supervised learning (SSL) offers a growing toolbox of pretext objectives: mutual information, reconstruction, contrastive learning; yet combining them reliably remains a challenge due to objective interference and training instability. Most multi-pretext pipelines use per-update mixing, forcing every parameter update to be a compromise, leading to three failure modes: Disagreement (conflict-induced negative transfer), Drift (nonstationary objective utility), and Drought (hidden starvation of underserved objectives). We argue that coordination is fundamentally a temporal allocation problem: deciding when each objective receives optimization budget, not merely how to weigh them. We introduce ControlG, a control-theoretic framework that recasts multi-objective graph SSL as feedback-controlled temporal allocation by estimating per-objective difficulty and pairwise antagonism, planning target budgets via a Pareto-aware log-hypervolume planner, and scheduling with a Proportional-Integral-Derivative (PID) controller. Across 9 datasets, ControlG consistently outperforms state-of-the-art baselines, while producing an auditable schedule that reveals which objectives drove learning.
Dynamic Mixture-of-Experts for Incremental Graph Learning
Aug 13, 2025Graph incremental learning is a learning paradigm that aims to adapt trained models to continuously incremented graphs and data over time without the need for retraining on the full dataset. However, regular graph machine learning methods suffer from catastrophic forgetting when applied to incremental learning settings, where previously learned knowledge is overridden by new knowledge. Previous approaches have tried to address this by treating the previously trained model as an inseparable unit and using techniques to maintain old behaviors while learning new knowledge. These approaches, however, do not account for the fact that previously acquired knowledge at different timestamps contributes differently to learning new tasks. Some prior patterns can be transferred to help learn new data, while others may deviate from the new data distribution and be detrimental. To address this, we propose a dynamic mixture-of-experts (DyMoE) approach for incremental learning. Specifically, a DyMoE GNN layer adds new expert networks specialized in modeling the incoming data blocks. We design a customized regularization loss that utilizes data sequence information so existing experts can maintain their ability to solve old tasks while helping the new expert learn the new data effectively. As the number of data blocks grows over time, the computational cost of the full mixture-of-experts (MoE) model increases. To address this, we introduce a sparse MoE approach, where only the top-$k$ most relevant experts make predictions, significantly reducing the computation time. Our model achieved 4.92\% relative accuracy increase compared to the best baselines on class incremental learning, showing the model's exceptional power.
GraphStorm: all-in-one graph machine learning framework for industry applications
Jun 10, 2024



Graph machine learning (GML) is effective in many business applications. However, making GML easy to use and applicable to industry applications with massive datasets remain challenging. We developed GraphStorm, which provides an end-to-end solution for scalable graph construction, graph model training and inference. GraphStorm has the following desirable properties: (a) Easy to use: it can perform graph construction and model training and inference with just a single command; (b) Expert-friendly: GraphStorm contains many advanced GML modeling techniques to handle complex graph data and improve model performance; (c) Scalable: every component in GraphStorm can operate on graphs with billions of nodes and can scale model training and inference to different hardware without changing any code. GraphStorm has been used and deployed for over a dozen billion-scale industry applications after its release in May 2023. It is open-sourced in Github: https://github.com/awslabs/graphstorm.
Block-distributed Gradient Boosted Trees
May 28, 2019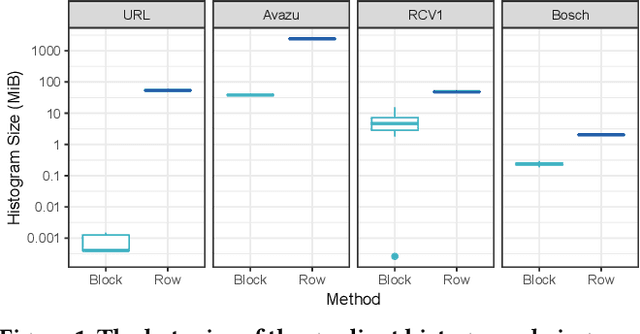
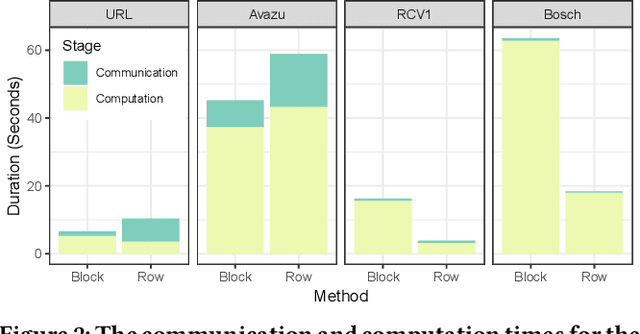
The Gradient Boosted Tree (GBT) algorithm is one of the most popular machine learning algorithms used in production, for tasks that include Click-Through Rate (CTR) prediction and learning-to-rank. To deal with the massive datasets available today, many distributed GBT methods have been proposed. However, they all assume a row-distributed dataset, addressing scalability only with respect to the number of data points and not the number of features, and increasing communication cost for high-dimensional data. In order to allow for scalability across both the data point and feature dimensions, and reduce communication cost, we propose block-distributed GBTs. We achieve communication efficiency by making full use of the data sparsity and adapting the Quickscorer algorithm to the block-distributed setting. We evaluate our approach using datasets with millions of features, and demonstrate that we are able to achieve multiple orders of magnitude reduction in communication cost for sparse data, with no loss in accuracy, while providing a more scalable design. As a result, we are able to reduce the training time for high-dimensional data, and allow more cost-effective scale-out without the need for expensive network communication.
Predicting Session Length in Media Streaming
Aug 01, 2017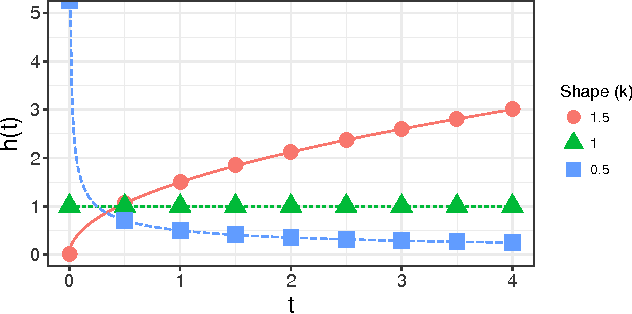

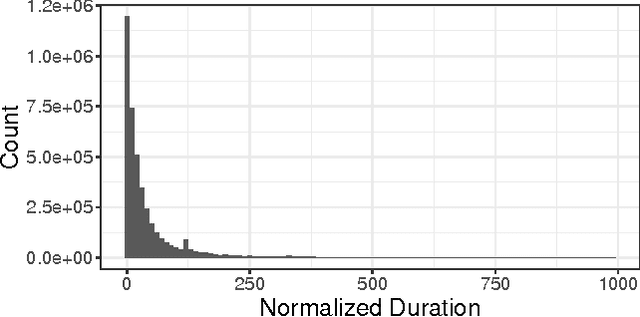
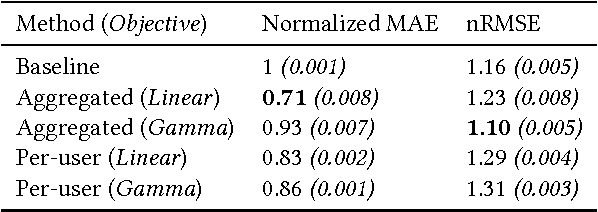
Session length is a very important aspect in determining a user's satisfaction with a media streaming service. Being able to predict how long a session will last can be of great use for various downstream tasks, such as recommendations and ad scheduling. Most of the related literature on user interaction duration has focused on dwell time for websites, usually in the context of approximating post-click satisfaction either in search results, or display ads. In this work we present the first analysis of session length in a mobile-focused online service, using a real world data-set from a major music streaming service. We use survival analysis techniques to show that the characteristics of the length distributions can differ significantly between users, and use gradient boosted trees with appropriate objectives to predict the length of a session using only information available at its beginning. Our evaluation on real world data illustrates that our proposed technique outperforms the considered baseline.
* 4 pages, 3 figures