 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEGATO: Good Identity Unlearning Is Continuous
Jan 07, 2026Machine unlearning has become a crucial role in enabling generative models trained on large datasets to remove sensitive, private, or copyright-protected data. However, existing machine unlearning methods face three challenges in learning to forget identity of generative models: 1) inefficient, where identity erasure requires fine-tuning all the model's parameters; 2) limited controllability, where forgetting intensity cannot be controlled and explainability is lacking; 3) catastrophic collapse, where the model's retention capability undergoes drastic degradation as forgetting progresses. Forgetting has typically been handled through discrete and unstable updates, often requiring full-model fine-tuning and leading to catastrophic collapse. In this work, we argue that identity forgetting should be modeled as a continuous trajectory, and introduce LEGATO - Learn to ForgEt Identity in GenerAtive Models via Trajectory-consistent Neural Ordinary Differential Equations. LEGATO augments pre-trained generators with fine-tunable lightweight Neural ODE adapters, enabling smooth, controllable forgetting while keeping the original model weights frozen. This formulation allows forgetting intensity to be precisely modulated via ODE step size, offering interpretability and robustness. To further ensure stability, we introduce trajectory consistency constraints that explicitly prevent catastrophic collapse during unlearning. Extensive experiments across in-domain and out-of-domain identity unlearning benchmarks show that LEGATO achieves state-of-the-art forgetting performance, avoids catastrophic collapse and reduces fine-tuned parameters.
Inference Time Feature Injection: A Lightweight Approach for Real-Time Recommendation Freshness
Dec 11, 2025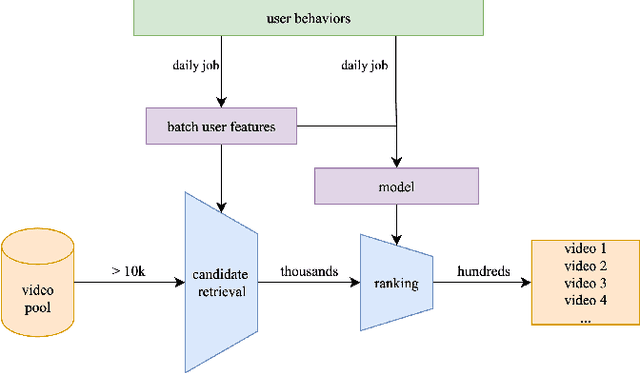
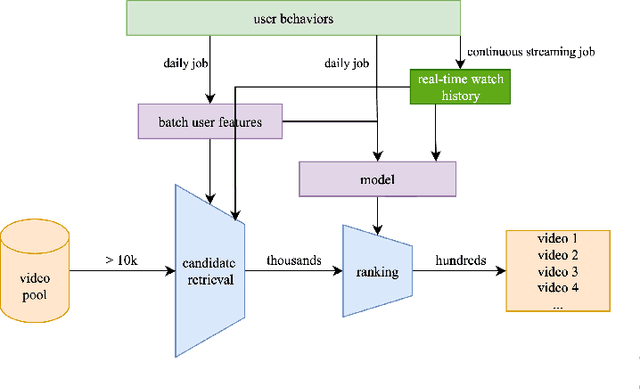
Many recommender systems in long-form video streaming reply on batch-trained models and batch-updated features, where user features are updated daily and served statically throughout the day. While efficient, this approach fails to incorporate a user's most recent actions, often resulting in stale recommendations. In this work, we present a lightweight, model-agnostic approach for intra-day personalization that selectively injects recent watch history at inference time without requiring model retraining. Our approach selectively overrides stale user features at inference time using the recent watch history, allowing the system to adapt instantly to evolving preferences. By reducing the personalization feedback loop from daily to intra-day, we observed a statistically significant 0.47% increase in key user engagement metrics which ranked among the most substantial engagement gains observed in recent experimentation cycles. To our knowledge, this is the first published evidence that intra-day personalization can drive meaningful impact in long-form video streaming service, providing a compelling alternative to full real-time architectures where model retraining is required.
Where to Explore: A Reach and Cost-Aware Approach for Unbiased Data Collection in Recommender Systems
Dec 11, 2025Exploration is essential to improve long-term recommendation quality, but it often degrades short-term business performance, especially in remote-first TV environments where users engage passively, expect instant relevance, and offer few chances for correction. This paper introduces an approach for delivering content-level exploration safely and efficiently by optimizing its placement based on reach and opportunity cost. Deployed on a large-scale streaming platform with over 100 million monthly active users, our approach identifies scroll-depth regions with lower engagement and strategically introduces a dedicated container, the "Something Completely Different" row containing randomized content. Rather than enforcing exploration uniformly across the user interface (UI), we condition its appearance on empirically low-cost, high-reach positions to ensure minimal tradeoff against platform-level watch time goals. Extensive A/B testing shows that this strategy preserves business metrics while collecting unbiased interaction data. Our method complements existing intra-row diversification and bandit-based exploration techniques by introducing a deployable, behaviorally informed mechanism for surfacing exploratory content at scale. Moreover, we demonstrate that the collected unbiased data, integrated into downstream candidate generation, significantly improves user engagement, validating its value for recommender systems.
A Closer Look at Edema Area Segmentation in SD-OCT Images Using Adversarial Framework
Aug 26, 2025The development of artificial intelligence models for macular edema (ME) analy-sis always relies on expert-annotated pixel-level image datasets which are expen-sive to collect prospectively. While anomaly-detection-based weakly-supervised methods have shown promise in edema area (EA) segmentation task, their per-formance still lags behind fully-supervised approaches. In this paper, we leverage the strong correlation between EA and retinal layers in spectral-domain optical coherence tomography (SD-OCT) images, along with the update characteristics of weakly-supervised learning, to enhance an off-the-shelf adversarial framework for EA segmentation with a novel layer-structure-guided post-processing step and a test-time-adaptation (TTA) strategy. By incorporating additional retinal lay-er information, our framework reframes the dense EA prediction task as one of confirming intersection points between the EA contour and retinal layers, result-ing in predictions that better align with the shape prior of EA. Besides, the TTA framework further helps address discrepancies in the manifestations and presen-tations of EA between training and test sets. Extensive experiments on two pub-licly available datasets demonstrate that these two proposed ingredients can im-prove the accuracy and robustness of EA segmentation, bridging the gap between weakly-supervised and fully-supervised models.
Runtime Failure Hunting for Physics Engine Based Software Systems: How Far Can We Go?
Jul 29, 2025Physics Engines (PEs) are fundamental software frameworks that simulate physical interactions in applications ranging from entertainment to safety-critical systems. Despite their importance, PEs suffer from physics failures, deviations from expected physical behaviors that can compromise software reliability, degrade user experience, and potentially cause critical failures in autonomous vehicles or medical robotics. Current testing approaches for PE-based software are inadequate, typically requiring white-box access and focusing on crash detection rather than semantically complex physics failures. This paper presents the first large-scale empirical study characterizing physics failures in PE-based software. We investigate three research questions addressing the manifestations of physics failures, the effectiveness of detection techniques, and developer perceptions of current detection practices. Our contributions include: (1) a taxonomy of physics failure manifestations; (2) a comprehensive evaluation of detection methods including deep learning, prompt-based techniques, and large multimodal models; and (3) actionable insights from developer experiences for improving detection approaches. To support future research, we release PhysiXFails, code, and other materials at https://sites.google.com/view/physics-failure-detection.
ESTR-CoT: Towards Explainable and Accurate Event Stream based Scene Text Recognition with Chain-of-Thought Reasoning
Jul 02, 2025Event stream based scene text recognition is a newly arising research topic in recent years which performs better than the widely used RGB cameras in extremely challenging scenarios, especially the low illumination, fast motion. Existing works either adopt end-to-end encoder-decoder framework or large language models for enhanced recognition, however, they are still limited by the challenges of insufficient interpretability and weak contextual logical reasoning. In this work, we propose a novel chain-of-thought reasoning based event stream scene text recognition framework, termed ESTR-CoT. Specifically, we first adopt the vision encoder EVA-CLIP (ViT-G/14) to transform the input event stream into tokens and utilize a Llama tokenizer to encode the given generation prompt. A Q-former is used to align the vision token to the pre-trained large language model Vicuna-7B and output both the answer and chain-of-thought (CoT) reasoning process simultaneously. Our framework can be optimized using supervised fine-tuning in an end-to-end manner. In addition, we also propose a large-scale CoT dataset to train our framework via a three stage processing (i.e., generation, polish, and expert verification). This dataset provides a solid data foundation for the development of subsequent reasoning-based large models. Extensive experiments on three event stream STR benchmark datasets (i.e., EventSTR, WordArt*, IC15*) fully validated the effectiveness and interpretability of our proposed framework. The source code and pre-trained models will be released on https://github.com/Event-AHU/ESTR-CoT.
Multi-Interest Recommendation: A Survey
Jun 18, 2025Existing recommendation methods often struggle to model users' multifaceted preferences due to the diversity and volatility of user behavior, as well as the inherent uncertainty and ambiguity of item attributes in practical scenarios. Multi-interest recommendation addresses this challenge by extracting multiple interest representations from users' historical interactions, enabling fine-grained preference modeling and more accurate recommendations. It has drawn broad interest in recommendation research. However, current recommendation surveys have either specialized in frontier recommendation methods or delved into specific tasks and downstream applications. In this work, we systematically review the progress, solutions, challenges, and future directions of multi-interest recommendation by answering the following three questions: (1) Why is multi-interest modeling significantly important for recommendation? (2) What aspects are focused on by multi-interest modeling in recommendation? and (3) How can multi-interest modeling be applied, along with the technical details of the representative modules? We hope that this survey establishes a fundamental framework and delivers a preliminary overview for researchers interested in this field and committed to further exploration. The implementation of multi-interest recommendation summarized in this survey is maintained at https://github.com/WHUIR/Multi-Interest-Recommendation-A-Survey.
APTOS-2024 challenge report: Generation of synthetic 3D OCT images from fundus photographs
Jun 09, 2025Optical Coherence Tomography (OCT) provides high-resolution, 3D, and non-invasive visualization of retinal layers in vivo, serving as a critical tool for lesion localization and disease diagnosis. However, its widespread adoption is limited by equipment costs and the need for specialized operators. In comparison, 2D color fundus photography offers faster acquisition and greater accessibility with less dependence on expensive devices. Although generative artificial intelligence has demonstrated promising results in medical image synthesis, translating 2D fundus images into 3D OCT images presents unique challenges due to inherent differences in data dimensionality and biological information between modalities. To advance generative models in the fundus-to-3D-OCT setting, the Asia Pacific Tele-Ophthalmology Society (APTOS-2024) organized a challenge titled Artificial Intelligence-based OCT Generation from Fundus Images. This paper details the challenge framework (referred to as APTOS-2024 Challenge), including: the benchmark dataset, evaluation methodology featuring two fidelity metrics-image-based distance (pixel-level OCT B-scan similarity) and video-based distance (semantic-level volumetric consistency), and analysis of top-performing solutions. The challenge attracted 342 participating teams, with 42 preliminary submissions and 9 finalists. Leading methodologies incorporated innovations in hybrid data preprocessing or augmentation (cross-modality collaborative paradigms), pre-training on external ophthalmic imaging datasets, integration of vision foundation models, and model architecture improvement. The APTOS-2024 Challenge is the first benchmark demonstrating the feasibility of fundus-to-3D-OCT synthesis as a potential solution for improving ophthalmic care accessibility in under-resourced healthcare settings, while helping to expedite medical research and clinical applications.
Tweedie Regression for Video Recommendation System
May 09, 2025
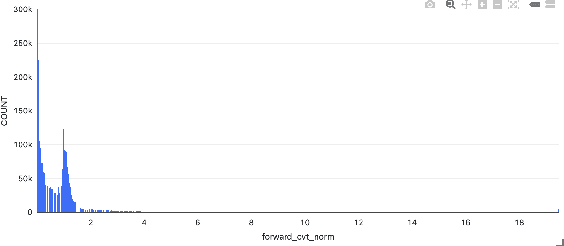


Modern recommendation systems aim to increase click-through rates (CTR) for better user experience, through commonly treating ranking as a classification task focused on predicting CTR. However, there is a gap between this method and the actual objectives of businesses across different sectors. In video recommendation services, the objective of video on demand (VOD) extends beyond merely encouraging clicks, but also guiding users to discover their true interests, leading to increased watch time. And longer users watch time will leads to more revenue through increased chances of presenting online display advertisements. This research addresses the issue by redefining the problem from classification to regression, with a focus on maximizing revenue through user viewing time. Due to the lack of positive labels on recommendation, the study introduces Tweedie Loss Function, which is better suited in this scenario than the traditional mean square error loss. The paper also provides insights on how Tweedie process capture users diverse interests. Our offline simulation and online A/B test revealed that we can substantially enhance our core business objectives: user engagement in terms of viewing time and, consequently, revenue. Additionally, we provide a theoretical comparison between the Tweedie Loss and the commonly employed viewing time weighted Logloss, highlighting why Tweedie Regression stands out as an efficient solution. We further outline a framework for designing a loss function that focuses on a singular objective.
Adversarial Attack for RGB-Event based Visual Object Tracking
Apr 19, 2025Visual object tracking is a crucial research topic in the fields of computer vision and multi-modal fusion. Among various approaches, robust visual tracking that combines RGB frames with Event streams has attracted increasing attention from researchers. While striving for high accuracy and efficiency in tracking, it is also important to explore how to effectively conduct adversarial attacks and defenses on RGB-Event stream tracking algorithms, yet research in this area remains relatively scarce. To bridge this gap, in this paper, we propose a cross-modal adversarial attack algorithm for RGB-Event visual tracking. Because of the diverse representations of Event streams, and given that Event voxels and frames are more commonly used, this paper will focus on these two representations for an in-depth study. Specifically, for the RGB-Event voxel, we first optimize the perturbation by adversarial loss to generate RGB frame adversarial examples. For discrete Event voxel representations, we propose a two-step attack strategy, more in detail, we first inject Event voxels into the target region as initialized adversarial examples, then, conduct a gradient-guided optimization by perturbing the spatial location of the Event voxels. For the RGB-Event frame based tracking, we optimize the cross-modal universal perturbation by integrating the gradient information from multimodal data. We evaluate the proposed approach against attacks on three widely used RGB-Event Tracking datasets, i.e., COESOT, FE108, and VisEvent. Extensive experiments show that our method significantly reduces the performance of the tracker across numerous datasets in both unimodal and multimodal scenarios. The source code will be released on https://github.com/Event-AHU/Adversarial_Attack_Defense