 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference Time Feature Injection: A Lightweight Approach for Real-Time Recommendation Freshness
Dec 11, 2025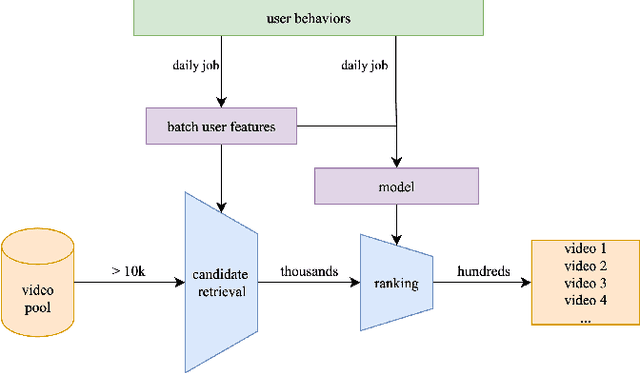
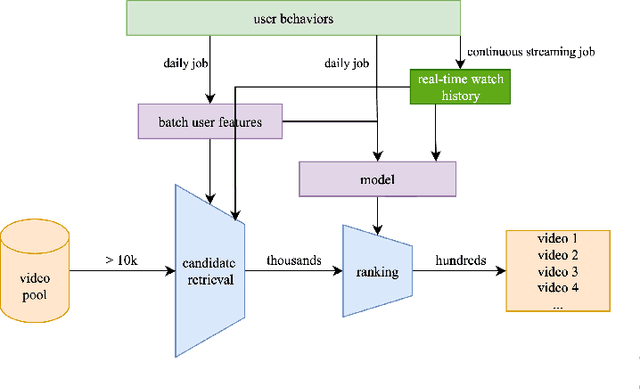
Many recommender systems in long-form video streaming reply on batch-trained models and batch-updated features, where user features are updated daily and served statically throughout the day. While efficient, this approach fails to incorporate a user's most recent actions, often resulting in stale recommendations. In this work, we present a lightweight, model-agnostic approach for intra-day personalization that selectively injects recent watch history at inference time without requiring model retraining. Our approach selectively overrides stale user features at inference time using the recent watch history, allowing the system to adapt instantly to evolving preferences. By reducing the personalization feedback loop from daily to intra-day, we observed a statistically significant 0.47% increase in key user engagement metrics which ranked among the most substantial engagement gains observed in recent experimentation cycles. To our knowledge, this is the first published evidence that intra-day personalization can drive meaningful impact in long-form video streaming service, providing a compelling alternative to full real-time architectures where model retraining is required.
Bias in Large Language Models: Origin, Evaluation, and Mitigation
Nov 16, 2024



Large Language Models (LLMs) have revolutionized natural language processing, but their susceptibility to biases poses significant challenges. This comprehensive review examines the landscape of bias in LLMs, from its origins to current mitigation strategies. We categorize biases as intrinsic and extrinsic, analyzing their manifestations in various NLP tasks. The review critically assesses a range of bias evaluation methods, including data-level, model-level, and output-level approaches, providing researchers with a robust toolkit for bias detection. We further explore mitigation strategies, categorizing them into pre-model, intra-model, and post-model techniques, highlighting their effectiveness and limitations. Ethical and legal implications of biased LLMs are discussed, emphasizing potential harms in real-world applications such as healthcare and criminal justice. By synthesizing current knowledge on bias in LLMs, this review contributes to the ongoing effort to develop fair and responsible AI systems. Our work serves as a comprehensive resource for researchers and practitioners working towards understanding, evaluating, and mitigating bias in LLMs, fostering the development of more equitable AI technologies.
Sparse-GEV: Sparse Latent Space Model for Multivariate Extreme Value Time Serie Modeling
Jun 18, 2012In many applications of time series models, such as climate analysis and social media analysis, we are often interested in extreme events, such as heatwave, wind gust, and burst of topics. These time series data usually exhibit a heavy-tailed distribution rather than a Gaussian distribution. This poses great challenges to existing approaches due to the significantly different assumptions on the data distributions and the lack of sufficient past data on extreme events. In this paper, we propose the Sparse-GEV model, a latent state model based on the theory of extreme value modeling to automatically learn sparse temporal dependence and make predictions. Our model is theoretically significant because it is among the first models to learn sparse temporal dependencies among multivariate extreme value time series. We demonstrate the superior performance of our algorithm to the state-of-art methods, including Granger causality, copula approach, and transfer entropy, on one synthetic dataset, one climate dataset and two Twitter datasets.