 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHPRN: Holistic Prior-embedded Relation Network for Spectral Super-Resolution
Dec 29, 2021
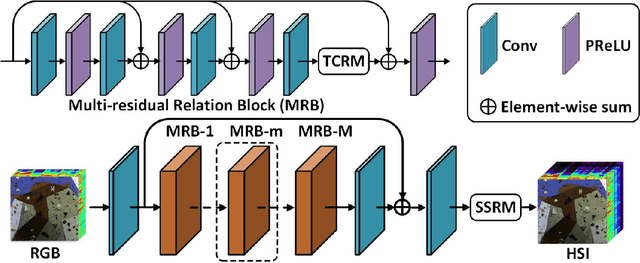
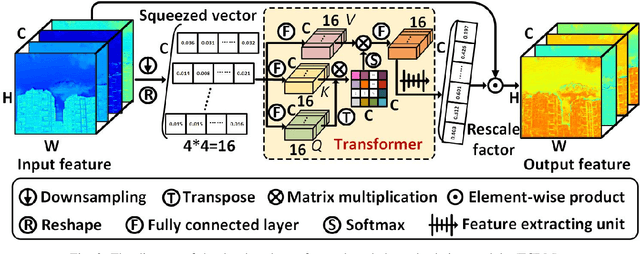
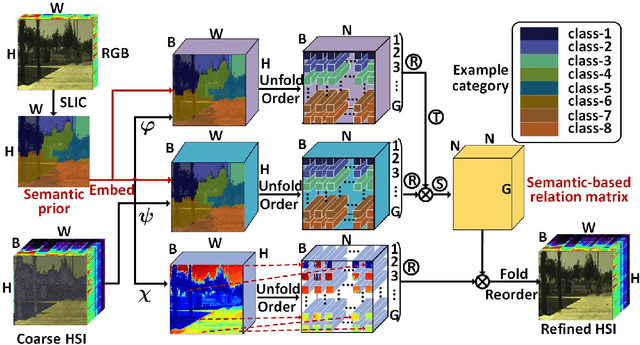
Spectral super-resolution (SSR) refers to the hyperspectral image (HSI) recovery from an RGB counterpart. Due to the one-to-many nature of the SSR problem, a single RGB image can be reprojected to many HSIs. The key to tackle this illposed problem is to plug into multi-source prior information such as the natural RGB spatial context-prior, deep feature-prior or inherent HSI statistical-prior, etc., so as to improve the confidence and fidelity of reconstructed spectra. However, most current approaches only consider the general and limited priors in their designing the customized convolutional neural networks (CNNs), which leads to the inability to effectively alleviate the degree of ill-posedness. To address the problematic issues, we propose a novel holistic prior-embedded relation network (HPRN) for SSR. Basically, the core framework is delicately assembled by several multi-residual relation blocks (MRBs) that fully facilitate the transmission and utilization of the low-frequency content prior of RGB signals. Innovatively, the semantic prior of RGB input is introduced to identify category attributes and a semantic-driven spatial relation module (SSRM) is put forward to perform the feature aggregation among the clustered similar characteristics using a semantic-embedded relation matrix. Additionally, we develop a transformer-based channel relation module (TCRM), which breaks the habit of employing scalars as the descriptors of channel-wise relations in the previous deep feature-prior and replaces them with certain vectors, together with Transformerstyle feature interactions, supporting the representations to be more discriminative. In order to maintain the mathematical correlation and spectral consistency between hyperspectral bands, the second-order prior constraints (SOPC) are incorporated into the loss function to guide the HSI reconstruction process.
Deep Learning for UAV-based Object Detection and Tracking: A Survey
Oct 25, 2021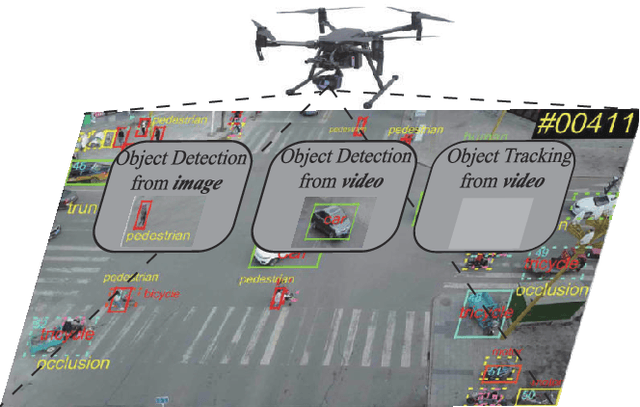
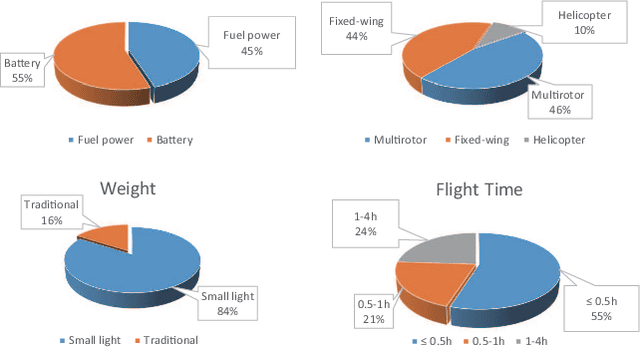
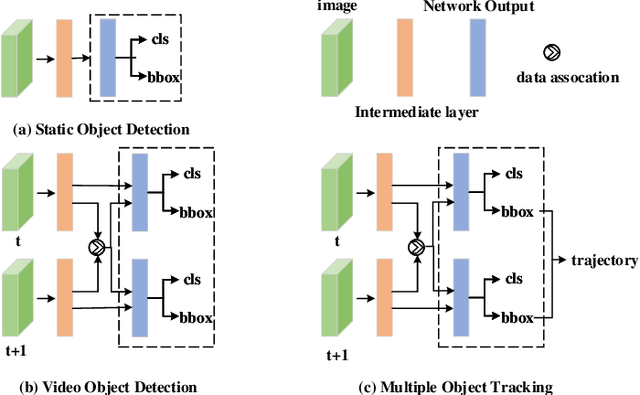
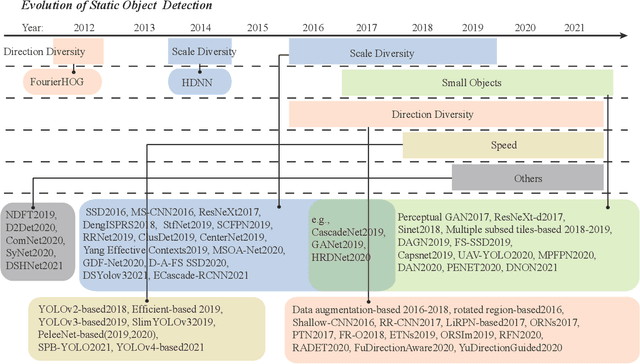
Owing to effective and flexible data acquisition, unmanned aerial vehicle (UAV) has recently become a hotspot across the fields of computer vision (CV) and remote sensing (RS). Inspired by recent success of deep learning (DL), many advanced object detection and tracking approaches have been widely applied to various UAV-related tasks, such as environmental monitoring, precision agriculture, traffic management. This paper provides a comprehensive survey on the research progress and prospects of DL-based UAV object detection and tracking methods. More specifically, we first outline the challenges, statistics of existing methods, and provide solutions from the perspectives of DL-based models in three research topics: object detection from the image, object detection from the video, and object tracking from the video. Open datasets related to UAV-dominated object detection and tracking are exhausted, and four benchmark datasets are employed for performance evaluation using some state-of-the-art methods. Finally, prospects and considerations for the future work are discussed and summarized. It is expected that this survey can facilitate those researchers who come from remote sensing field with an overview of DL-based UAV object detection and tracking methods, along with some thoughts on their further developments.
Spectral Variability Augmented Sparse Unmixing of Hyperspectral Images
Oct 21, 2021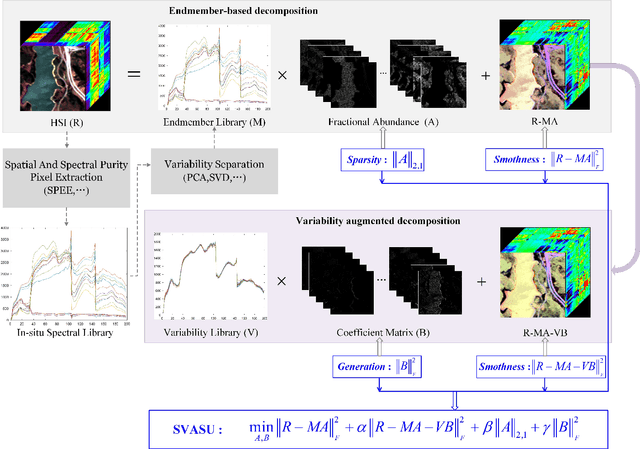
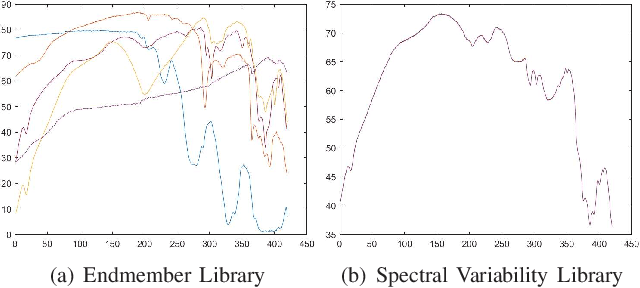
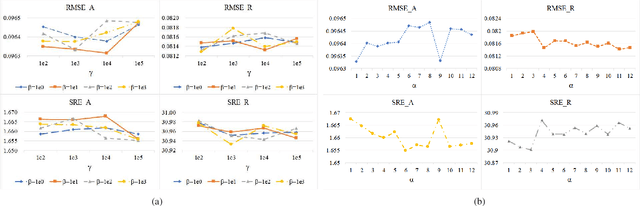
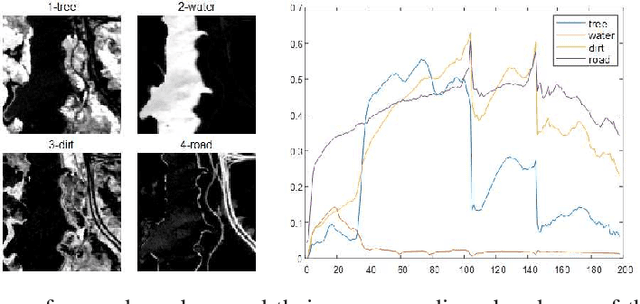
Spectral unmixing (SU) expresses the mixed pixels existed in hyperspectral images as the product of endmember and abundance, which has been widely used in hyperspectral imagery analysis. However, the influence of light, acquisition conditions and the inherent properties of materials, results in that the identified endmembers can vary spectrally within a given image (construed as spectral variability). To address this issue, recent methods usually use a priori obtained spectral library to represent multiple characteristic spectra of the same object, but few of them extracted the spectral variability explicitly. In this paper, a spectral variability augmented sparse unmixing model (SVASU) is proposed, in which the spectral variability is extracted for the first time. The variable spectra are divided into two parts of intrinsic spectrum and spectral variability for spectral reconstruction, and modeled synchronously in the SU model adding the regular terms restricting the sparsity of abundance and the generalization of the variability coefficient. It is noted that the spectral variability library and the intrinsic spectral library are all constructed from the In-situ observed image. Experimental results over both synthetic and real-world data sets demonstrate that the augmented decomposition by spectral variability significantly improves the unmixing performance than the decomposition only by spectral library, as well as compared to state-of-the-art algorithms.
Synthetic Aperture Radar Image Change Detection via Siamese Adaptive Fusion Network
Oct 18, 2021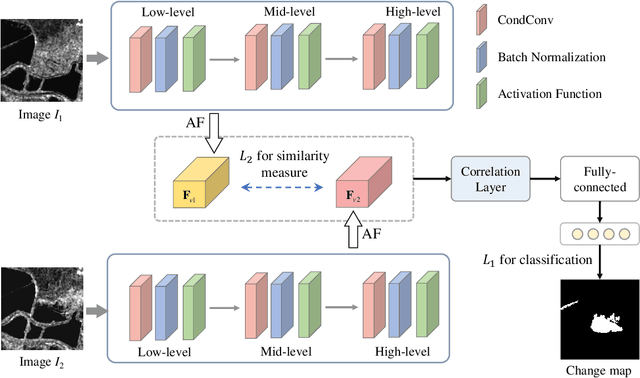



Synthetic aperture radar (SAR) image change detection is a critical yet challenging task in the field of remote sensing image analysis. The task is non-trivial due to the following challenges: Firstly, intrinsic speckle noise of SAR images inevitably degrades the neural network because of error gradient accumulation. Furthermore, the correlation among various levels or scales of feature maps is difficult to be achieved through summation or concatenation. Toward this end, we proposed a siamese adaptive fusion network for SAR image change detection. To be more specific, two-branch CNN is utilized to extract high-level semantic features of multitemporal SAR images. Besides, an adaptive fusion module is designed to adaptively combine multiscale responses in convolutional layers. Therefore, the complementary information is exploited, and feature learning in change detection is further improved. Moreover, a correlation layer is designed to further explore the correlation between multitemporal images. Thereafter, robust feature representation is utilized for classification through a fully-connected layer with softmax. Experimental results on four real SAR datasets demonstrate that the proposed method exhibits superior performance against several state-of-the-art methods. Our codes are available at https://github.com/summitgao/SAR_CD_SAFNet.
Superpixel-guided Discriminative Low-rank Representation of Hyperspectral Images for Classification
Aug 25, 2021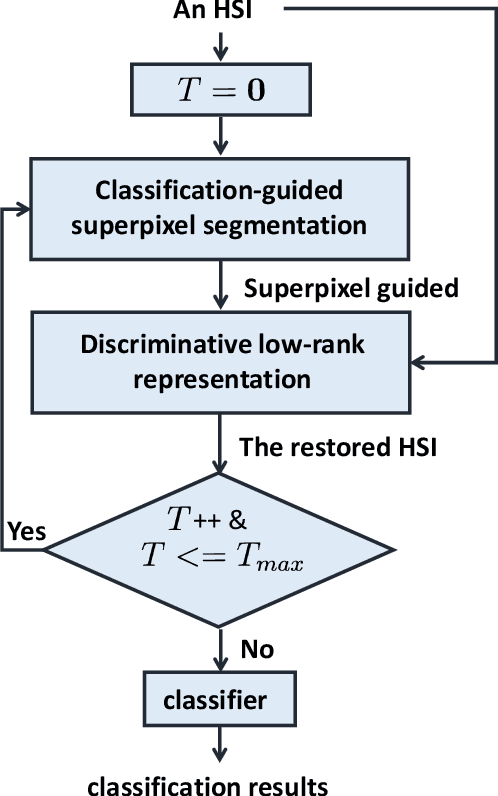
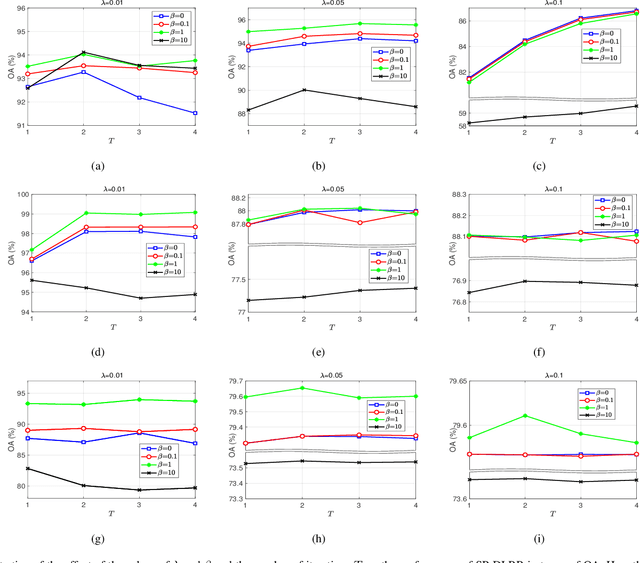
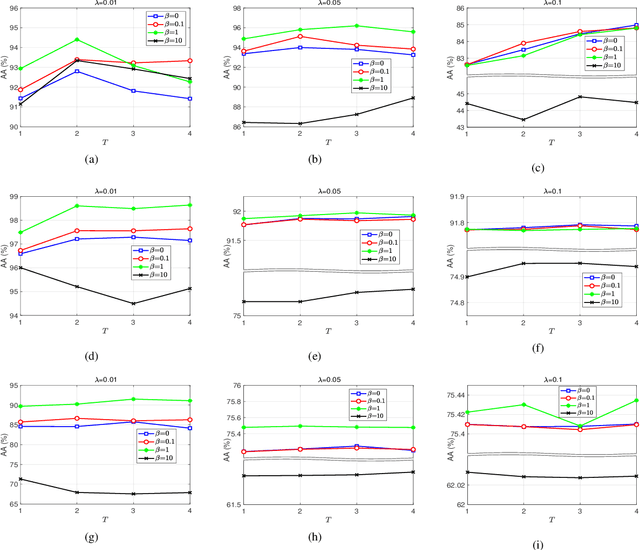
In this paper, we propose a novel classification scheme for the remotely sensed hyperspectral image (HSI), namely SP-DLRR, by comprehensively exploring its unique characteristics, including the local spatial information and low-rankness. SP-DLRR is mainly composed of two modules, i.e., the classification-guided superpixel segmentation and the discriminative low-rank representation, which are iteratively conducted. Specifically, by utilizing the local spatial information and incorporating the predictions from a typical classifier, the first module segments pixels of an input HSI (or its restoration generated by the second module) into superpixels. According to the resulting superpixels, the pixels of the input HSI are then grouped into clusters and fed into our novel discriminative low-rank representation model with an effective numerical solution. Such a model is capable of increasing the intra-class similarity by suppressing the spectral variations locally while promoting the inter-class discriminability globally, leading to a restored HSI with more discriminative pixels. Experimental results on three benchmark datasets demonstrate the significant superiority of SP-DLRR over state-of-the-art methods, especially for the case with an extremely limited number of training pixels.
Hyperspectral and Multispectral Classification for Coastal Wetland Using Depthwise Feature Interaction Network
Jul 12, 2021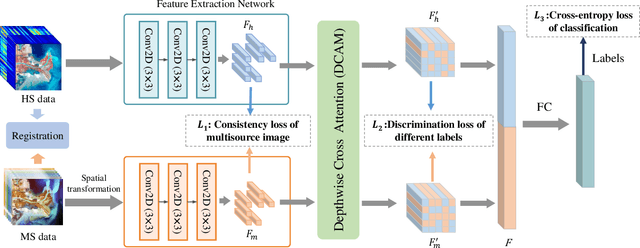
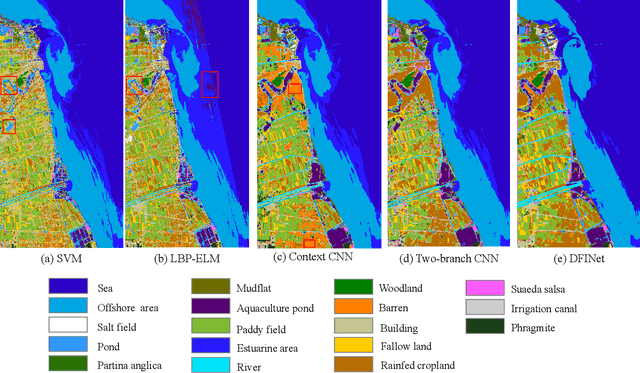
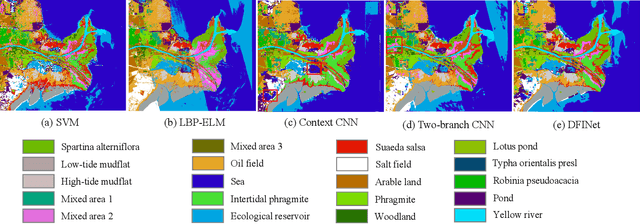
The monitoring of coastal wetlands is of great importance to the protection of marine and terrestrial ecosystems. However, due to the complex environment, severe vegetation mixture, and difficulty of access, it is impossible to accurately classify coastal wetlands and identify their species with traditional classifiers. Despite the integration of multisource remote sensing data for performance enhancement, there are still challenges with acquiring and exploiting the complementary merits from multisource data. In this paper, the Deepwise Feature Interaction Network (DFINet) is proposed for wetland classification. A depthwise cross attention module is designed to extract self-correlation and cross-correlation from multisource feature pairs. In this way, meaningful complementary information is emphasized for classification. DFINet is optimized by coordinating consistency loss, discrimination loss, and classification loss. Accordingly, DFINet reaches the standard solution-space under the regularity of loss functions, while the spatial consistency and feature discrimination are preserved. Comprehensive experimental results on two hyperspectral and multispectral wetland datasets demonstrate that the proposed DFINet outperforms other competitive methods in terms of overall accuracy.
BDANet: Multiscale Convolutional Neural Network with Cross-directional Attention for Building Damage Assessment from Satellite Images
May 16, 2021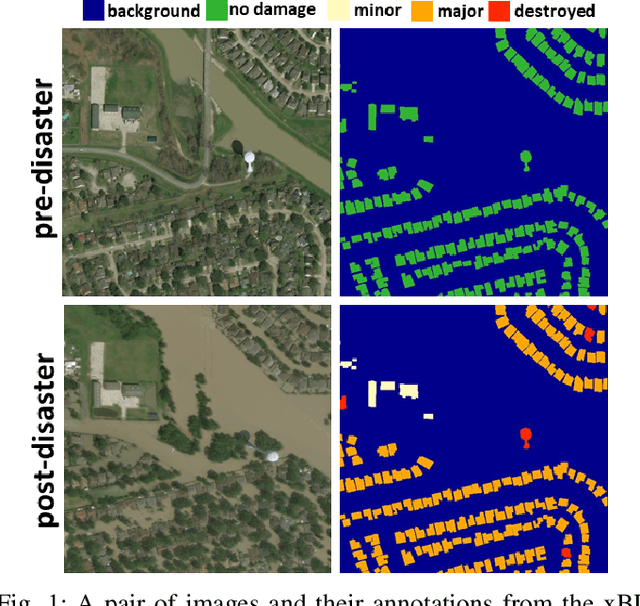
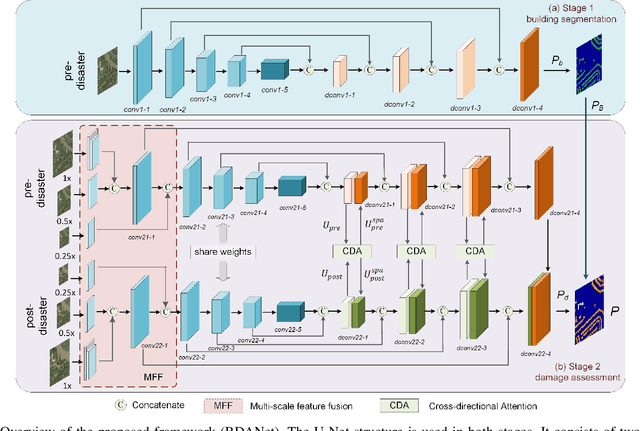
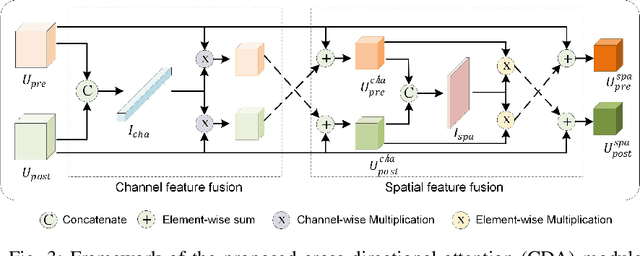
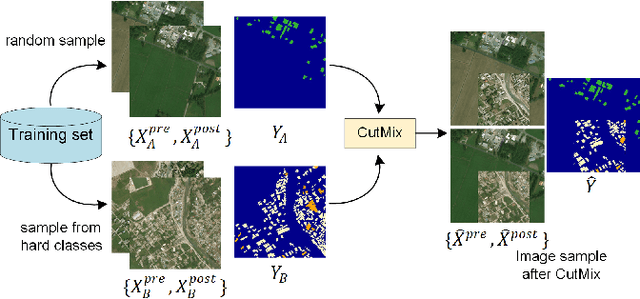
Fast and effective responses are required when a natural disaster (e.g., earthquake, hurricane, etc.) strikes. Building damage assessment from satellite imagery is critical before relief effort is deployed. With a pair of pre- and post-disaster satellite images, building damage assessment aims at predicting the extent of damage to buildings. With the powerful ability of feature representation, deep neural networks have been successfully applied to building damage assessment. Most existing works simply concatenate pre- and post-disaster images as input of a deep neural network without considering their correlations. In this paper, we propose a novel two-stage convolutional neural network for Building Damage Assessment, called BDANet. In the first stage, a U-Net is used to extract the locations of buildings. Then the network weights from the first stage are shared in the second stage for building damage assessment. In the second stage, a two-branch multi-scale U-Net is employed as backbone, where pre- and post-disaster images are fed into the network separately. A cross-directional attention module is proposed to explore the correlations between pre- and post-disaster images. Moreover, CutMix data augmentation is exploited to tackle the challenge of difficult classes. The proposed method achieves state-of-the-art performance on a large-scale dataset -- xBD. The code is available at https://github.com/ShaneShen/BDANet-Building-Damage-Assessment.
Change Detection in Synthetic Aperture Radar Images Using a Dual-Domain Network
Apr 15, 2021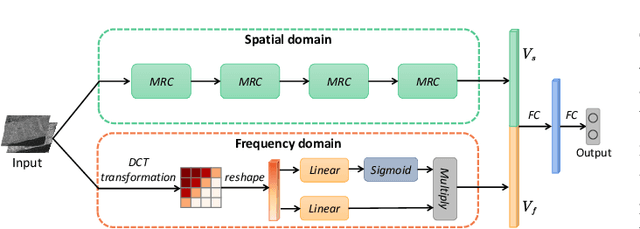
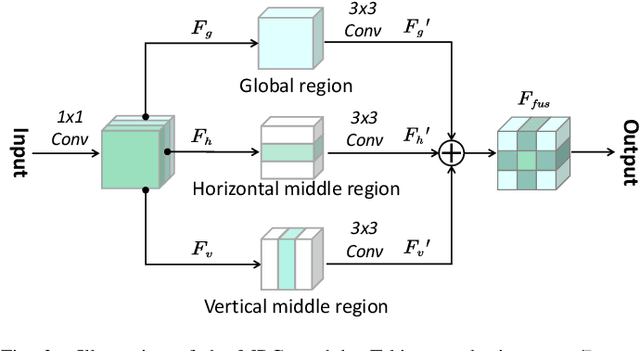

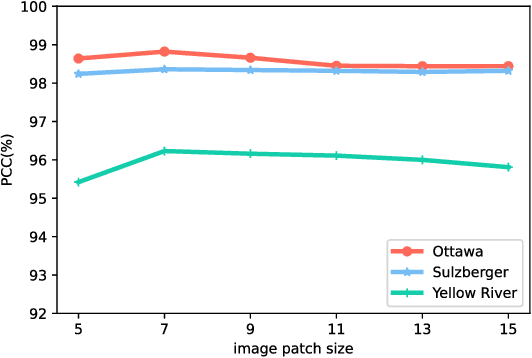
Change detection from synthetic aperture radar (SAR) imagery is a critical yet challenging task. Existing methods mainly focus on feature extraction in spatial domain, and little attention has been paid to frequency domain. Furthermore, in patch-wise feature analysis, some noisy features in the marginal region may be introduced. To tackle the above two challenges, we propose a Dual-Domain Network. Specifically, we take features from the discrete cosine transform domain into consideration and the reshaped DCT coefficients are integrated into the proposed model as the frequency domain branch. Feature representations from both frequency and spatial domain are exploited to alleviate the speckle noise. In addition, we further propose a multi-region convolution module, which emphasizes the central region of each patch. The contextual information and central region features are modeled adaptively. The experimental results on three SAR datasets demonstrate the effectiveness of the proposed model. Our codes are available at https://github.com/summitgao/SAR_CD_DDNet.
Remote Sensing Image Translation via Style-Based Recalibration Module and Improved Style Discriminator
Mar 29, 2021
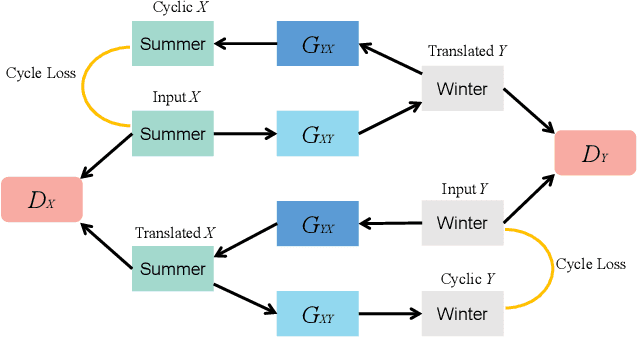
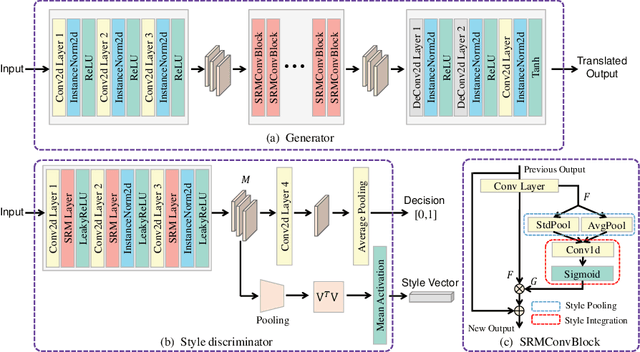

Existing remote sensing change detection methods are heavily affected by seasonal variation. Since vegetation colors are different between winter and summer, such variations are inclined to be falsely detected as changes. In this letter, we proposed an image translation method to solve the problem. A style-based recalibration module is introduced to capture seasonal features effectively. Then, a new style discriminator is designed to improve the translation performance. The discriminator can not only produce a decision for the fake or real sample, but also return a style vector according to the channel-wise correlations. Extensive experiments are conducted on season-varying dataset. The experimental results show that the proposed method can effectively perform image translation, thereby consistently improving the season-varying image change detection performance. Our codes and data are available at https://github.com/summitgao/RSIT_SRM_ISD.
More Diverse Means Better: Multimodal Deep Learning Meets Remote Sensing Imagery Classification
Aug 12, 2020
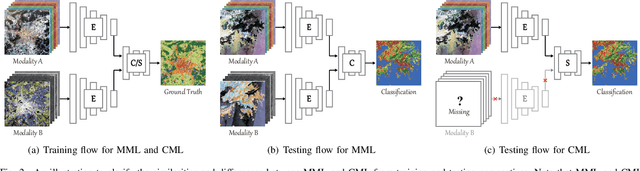
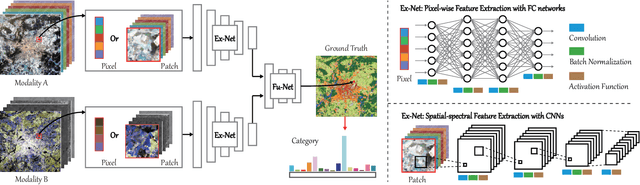
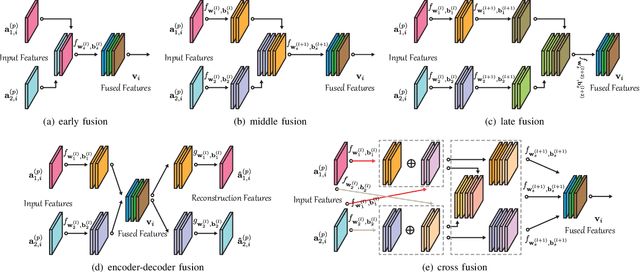
Classification and identification of the materials lying over or beneath the Earth's surface have long been a fundamental but challenging research topic in geoscience and remote sensing (RS) and have garnered a growing concern owing to the recent advancements of deep learning techniques. Although deep networks have been successfully applied in single-modality-dominated classification tasks, yet their performance inevitably meets the bottleneck in complex scenes that need to be finely classified, due to the limitation of information diversity. In this work, we provide a baseline solution to the aforementioned difficulty by developing a general multimodal deep learning (MDL) framework. In particular, we also investigate a special case of multi-modality learning (MML) -- cross-modality learning (CML) that exists widely in RS image classification applications. By focusing on "what", "where", and "how" to fuse, we show different fusion strategies as well as how to train deep networks and build the network architecture. Specifically, five fusion architectures are introduced and developed, further being unified in our MDL framework. More significantly, our framework is not only limited to pixel-wise classification tasks but also applicable to spatial information modeling with convolutional neural networks (CNNs). To validate the effectiveness and superiority of the MDL framework, extensive experiments related to the settings of MML and CML are conducted on two different multimodal RS datasets. Furthermore, the codes and datasets will be available at https://github.com/danfenghong/IEEE_TGRS_MDL-RS, contributing to the RS community.