 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding the Experts: Semantic Priors for Efficient and Focused MoE Routing
May 24, 2025Mixture-of-Experts (MoE) models have emerged as a promising direction for scaling vision architectures efficiently. Among them, Soft MoE improves training stability by assigning each token to all experts via continuous dispatch weights. However, current designs overlook the semantic structure which is implicitly encoded in these weights, resulting in suboptimal expert routing. In this paper, we discover that dispatch weights in Soft MoE inherently exhibit segmentation-like patterns but are not explicitly aligned with semantic regions. Motivated by this observation, we propose a foreground-guided enhancement strategy. Specifically, we introduce a spatially aware auxiliary loss that encourages expert activation to align with semantic foreground regions. To further reinforce this supervision, we integrate a lightweight LayerScale mechanism that improves information flow and stabilizes optimization in skip connections. Our method necessitates only minor architectural adjustments and can be seamlessly integrated into prevailing Soft MoE frameworks. Comprehensive experiments on ImageNet-1K and multiple smaller-scale classification benchmarks not only showcase consistent performance enhancements but also reveal more interpretable expert routing mechanisms.
DualComp: End-to-End Learning of a Unified Dual-Modality Lossless Compressor
May 22, 2025Most learning-based lossless compressors are designed for a single modality, requiring separate models for multi-modal data and lacking flexibility. However, different modalities vary significantly in format and statistical properties, making it ineffective to use compressors that lack modality-specific adaptations. While multi-modal large language models (MLLMs) offer a potential solution for modality-unified compression, their excessive complexity hinders practical deployment. To address these challenges, we focus on the two most common modalities, image and text, and propose DualComp, the first unified and lightweight learning-based dual-modality lossless compressor. Built on a lightweight backbone, DualComp incorporates three key structural enhancements to handle modality heterogeneity: modality-unified tokenization, modality-switching contextual learning, and modality-routing mixture-of-experts. A reparameterization training strategy is also used to boost compression performance. DualComp integrates both modality-specific and shared parameters for efficient parameter utilization, enabling near real-time inference (200KB/s) on desktop CPUs. With much fewer parameters, DualComp achieves compression performance on par with the SOTA LLM-based methods for both text and image datasets. Its simplified single-modality variant surpasses the previous best image compressor on the Kodak dataset by about 9% using just 1.2% of the model size.
Clapper: Compact Learning and Video Representation in VLMs
May 21, 2025Current vision-language models (VLMs) have demonstrated remarkable capabilities across diverse video understanding applications. Designing VLMs for video inputs requires effectively modeling the temporal dimension (i.e. capturing dependencies across frames) and balancing the processing of short and long videos. Specifically, short videos demand preservation of fine-grained details, whereas long videos require strategic compression of visual information to handle extensive temporal contexts efficiently. However, our empirical analysis reveals a critical limitation: most existing VLMs suffer severe performance degradation in long video understanding tasks when compressing visual tokens below a quarter of their original visual tokens. To enable more effective modeling of both short and long video inputs, we propose Clapper, a method that utilizes a slow-fast strategy for video representation and introduces a novel module named TimePerceiver for efficient temporal-spatial encoding within existing VLM backbones. By using our method, we achieves 13x compression of visual tokens per frame (averaging 61 tokens/frame) without compromising QA accuracy. In our experiments, Clapper achieves 62.0% on VideoMME, 69.8% on MLVU, and 67.4% on TempCompass, all with fewer than 6,000 visual tokens per video. The code will be publicly available on the homepage.
FLARE: Robot Learning with Implicit World Modeling
May 21, 2025We introduce $\textbf{F}$uture $\textbf{LA}$tent $\textbf{RE}$presentation Alignment ($\textbf{FLARE}$), a novel framework that integrates predictive latent world modeling into robot policy learning. By aligning features from a diffusion transformer with latent embeddings of future observations, $\textbf{FLARE}$ enables a diffusion transformer policy to anticipate latent representations of future observations, allowing it to reason about long-term consequences while generating actions. Remarkably lightweight, $\textbf{FLARE}$ requires only minimal architectural modifications -- adding a few tokens to standard vision-language-action (VLA) models -- yet delivers substantial performance gains. Across two challenging multitask simulation imitation learning benchmarks spanning single-arm and humanoid tabletop manipulation, $\textbf{FLARE}$ achieves state-of-the-art performance, outperforming prior policy learning baselines by up to 26%. Moreover, $\textbf{FLARE}$ unlocks the ability to co-train with human egocentric video demonstrations without action labels, significantly boosting policy generalization to a novel object with unseen geometry with as few as a single robot demonstration. Our results establish $\textbf{FLARE}$ as a general and scalable approach for combining implicit world modeling with high-frequency robotic control.
Fourier-Invertible Neural Encoder (FINE) for Homogeneous Flows
May 21, 2025Invertible neural architectures have recently attracted attention for their compactness, interpretability, and information-preserving properties. In this work, we propose the Fourier-Invertible Neural Encoder (FINE), which combines invertible monotonic activation functions with reversible filter structures, and could be extended using Invertible ResNets. This architecture is examined in learning low-dimensional representations of one-dimensional nonlinear wave interactions and exact circular translation symmetry. Dimensionality is preserved across layers, except for a Fourier truncation step in the latent space, which enables dimensionality reduction while maintaining shift equivariance and interpretability. Our results demonstrate that FINE significantly outperforms classical linear methods such as Discrete Fourier Transformation (DFT) and Proper Orthogonal Decomposition (POD), and achieves reconstruction accuracy better than conventional deep autoencoders with convolutional layers (CNN) - while using substantially smaller models and offering superior physical interpretability. These findings suggest that invertible single-neuron networks, when combined with spectral truncation, offer a promising framework for learning compact and interpretable representations of physics datasets, and symmetry-aware representation learning in physics-informed machine learning.
DreamGen: Unlocking Generalization in Robot Learning through Neural Trajectories
May 19, 2025We introduce DreamGen, a simple yet highly effective 4-stage pipeline for training robot policies that generalize across behaviors and environments through neural trajectories - synthetic robot data generated from video world models. DreamGen leverages state-of-the-art image-to-video generative models, adapting them to the target robot embodiment to produce photorealistic synthetic videos of familiar or novel tasks in diverse environments. Since these models generate only videos, we recover pseudo-action sequences using either a latent action model or an inverse-dynamics model (IDM). Despite its simplicity, DreamGen unlocks strong behavior and environment generalization: a humanoid robot can perform 22 new behaviors in both seen and unseen environments, while requiring teleoperation data from only a single pick-and-place task in one environment. To evaluate the pipeline systematically, we introduce DreamGen Bench, a video generation benchmark that shows a strong correlation between benchmark performance and downstream policy success. Our work establishes a promising new axis for scaling robot learning well beyond manual data collection.
VideoRFT: Incentivizing Video Reasoning Capability in MLLMs via Reinforced Fine-Tuning
May 18, 2025Reinforcement fine-tuning (RFT) has shown great promise in achieving humanlevel reasoning capabilities of Large Language Models (LLMs), and has recently been extended to MLLMs. Nevertheless, reasoning about videos, which is a fundamental aspect of human intelligence, remains a persistent challenge due to the complex logic, temporal and causal structures inherent in video data. To fill this gap, we propose VIDEORFT, a novel approach that extends the RFT paradigm to cultivate human-like video reasoning capabilities in MLLMs. VIDEORFT follows the standard two-stage scheme in RFT: supervised fine-tuning (SFT) with chain-of-thought (CoT) annotations, followed by reinforcement learning (RL) to improve generalization. A central challenge to achieve this in the video domain lies in the scarcity of large-scale, high-quality video CoT datasets. We address this by building a fully automatic CoT curation pipeline. First, we devise a cognitioninspired prompting strategy to elicit a reasoning LLM to generate preliminary CoTs based solely on rich, structured, and literal representations of video content. Subsequently, these CoTs are revised by a visual-language model conditioned on the actual video, ensuring visual consistency and reducing visual hallucinations. This pipeline results in two new datasets - VideoRFT-CoT-102K for SFT and VideoRFT-RL-310K for RL. To further strength the RL phase, we introduce a novel semantic-consistency reward that explicitly promotes the alignment between textual reasoning with visual evidence. This reward encourages the model to produce coherent, context-aware reasoning outputs grounded in visual input. Extensive experiments show that VIDEORFT achieves state-of-the-art performance on six video reasoning benchmarks.
Safe Delta: Consistently Preserving Safety when Fine-Tuning LLMs on Diverse Datasets
May 17, 2025Large language models (LLMs) have shown great potential as general-purpose AI assistants across various domains. To fully leverage this potential in specific applications, many companies provide fine-tuning API services, enabling users to upload their own data for LLM customization. However, fine-tuning services introduce a new safety threat: user-uploaded data, whether harmful or benign, can break the model's alignment, leading to unsafe outputs. Moreover, existing defense methods struggle to address the diversity of fine-tuning datasets (e.g., varying sizes, tasks), often sacrificing utility for safety or vice versa. To address this issue, we propose Safe Delta, a safety-aware post-training defense method that adjusts the delta parameters (i.e., the parameter change before and after fine-tuning). Specifically, Safe Delta estimates the safety degradation, selects delta parameters to maximize utility while limiting overall safety loss, and applies a safety compensation vector to mitigate residual safety loss. Through extensive experiments on four diverse datasets with varying settings, our approach consistently preserves safety while ensuring that the utility gain from benign datasets remains unaffected.
Strategy-Augmented Planning for Large Language Models via Opponent Exploitation
May 13, 2025Efficiently modeling and exploiting opponents is a long-standing challenge in adversarial domains. Large Language Models (LLMs) trained on extensive textual data have recently demonstrated outstanding performance in general tasks, introducing new research directions for opponent modeling. Some studies primarily focus on directly using LLMs to generate decisions based on the elaborate prompt context that incorporates opponent descriptions, while these approaches are limited to scenarios where LLMs possess adequate domain expertise. To address that, we introduce a two-stage Strategy-Augmented Planning (SAP) framework that significantly enhances the opponent exploitation capabilities of LLM-based agents by utilizing a critical component, the Strategy Evaluation Network (SEN). Specifically, in the offline stage, we construct an explicit strategy space and subsequently collect strategy-outcome pair data for training the SEN network. During the online phase, SAP dynamically recognizes the opponent's strategies and greedily exploits them by searching best response strategy on the well-trained SEN, finally translating strategy to a course of actions by carefully designed prompts. Experimental results show that SAP exhibits robust generalization capabilities, allowing it to perform effectively not only against previously encountered opponent strategies but also against novel, unseen strategies. In the MicroRTS environment, SAP achieves a 85.35\% performance improvement over baseline methods and matches the competitiveness of reinforcement learning approaches against state-of-the-art (SOTA) rule-based AI.
PeSANet: Physics-encoded Spectral Attention Network for Simulating PDE-Governed Complex Systems
May 03, 2025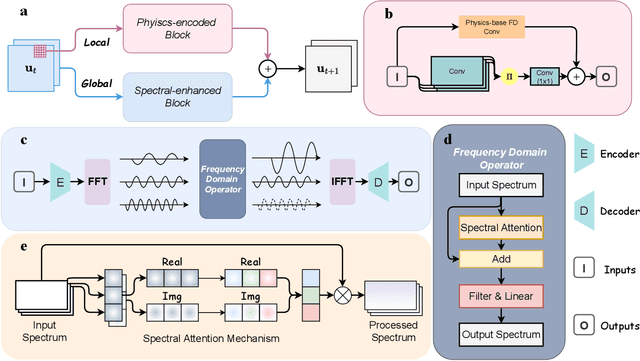

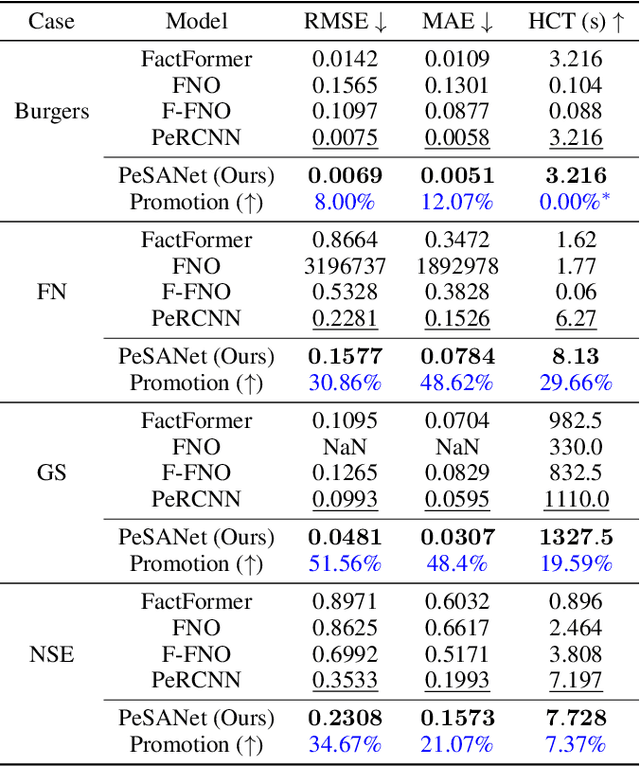
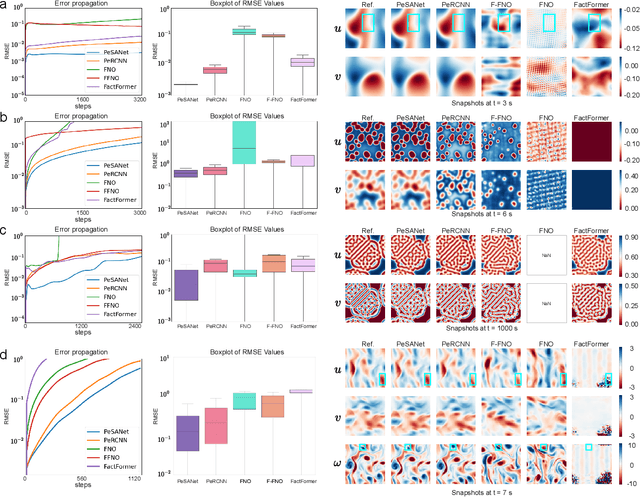
Accurately modeling and forecasting complex systems governed by partial differential equations (PDEs) is crucial in various scientific and engineering domains. However, traditional numerical methods struggle in real-world scenarios due to incomplete or unknown physical laws. Meanwhile, machine learning approaches often fail to generalize effectively when faced with scarce observational data and the challenge of capturing local and global features. To this end, we propose the Physics-encoded Spectral Attention Network (PeSANet), which integrates local and global information to forecast complex systems with limited data and incomplete physical priors. The model consists of two key components: a physics-encoded block that uses hard constraints to approximate local differential operators from limited data, and a spectral-enhanced block that captures long-range global dependencies in the frequency domain. Specifically, we introduce a novel spectral attention mechanism to model inter-spectrum relationships and learn long-range spatial features. Experimental results demonstrate that PeSANet outperforms existing methods across all metrics, particularly in long-term forecasting accuracy, providing a promising solution for simulating complex systems with limited data and incomplete physics.