 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Supervised Learning Through Constraints on Smooth Nonconvex Unfairness-Measure Surrogates
May 21, 2025A new strategy for fair supervised machine learning is proposed. The main advantages of the proposed strategy as compared to others in the literature are as follows. (a) We introduce a new smooth nonconvex surrogate to approximate the Heaviside functions involved in discontinuous unfairness measures. The surrogate is based on smoothing methods from the optimization literature, and is new for the fair supervised learning literature. The surrogate is a tight approximation which ensures the trained prediction models are fair, as opposed to other (e.g., convex) surrogates that can fail to lead to a fair prediction model in practice. (b) Rather than rely on regularizers (that lead to optimization problems that are difficult to solve) and corresponding regularization parameters (that can be expensive to tune), we propose a strategy that employs hard constraints so that specific tolerances for unfairness can be enforced without the complications associated with the use of regularization. (c)~Our proposed strategy readily allows for constraints on multiple (potentially conflicting) unfairness measures at the same time. Multiple measures can be considered with a regularization approach, but at the cost of having even more difficult optimization problems to solve and further expense for tuning. By contrast, through hard constraints, our strategy leads to optimization models that can be solved tractably with minimal tuning.
Using Synthetic Data to Mitigate Unfairness and Preserve Privacy through Single-Shot Federated Learning
Sep 14, 2024To address unfairness issues in federated learning (FL), contemporary approaches typically use frequent model parameter updates and transmissions between the clients and server. In such a process, client-specific information (e.g., local dataset size or data-related fairness metrics) must be sent to the server to compute, e.g., aggregation weights. All of this results in high transmission costs and the potential leakage of client information. As an alternative, we propose a strategy that promotes fair predictions across clients without the need to pass information between the clients and server iteratively and prevents client data leakage. For each client, we first use their local dataset to obtain a synthetic dataset by solving a bilevel optimization problem that addresses unfairness concerns during the learning process. We then pass each client's synthetic dataset to the server, the collection of which is used to train the server model using conventional machine learning techniques (that do not take fairness metrics into account). Thus, we eliminate the need to handle fairness-specific aggregation weights while preserving client privacy. Our approach requires only a single communication between the clients and the server, thus making it computationally cost-effective, able to maintain privacy, and able to ensuring fairness. We present empirical evidence to demonstrate the advantages of our approach. The results illustrate that our method effectively uses synthetic data as a means to mitigate unfairness and preserve client privacy.
Single-Loop Deterministic and Stochastic Interior-Point Algorithms for Nonlinearly Constrained Optimization
Aug 29, 2024An interior-point algorithm framework is proposed, analyzed, and tested for solving nonlinearly constrained continuous optimization problems. The main setting of interest is when the objective and constraint functions may be nonlinear and/or nonconvex, and when constraint values and derivatives are tractable to compute, but objective function values and derivatives can only be estimated. The algorithm is intended primarily for a setting that is similar for stochastic-gradient methods for unconstrained optimization, namely, the setting when stochastic-gradient estimates are available and employed in place of gradients of the objective, and when no objective function values (nor estimates of them) are employed. This is achieved by the interior-point framework having a single-loop structure rather than the nested-loop structure that is typical of contemporary interior-point methods. For completeness, convergence guarantees for the framework are provided both for deterministic and stochastic settings. Numerical experiments show that the algorithm yields good performance on a large set of test problems.
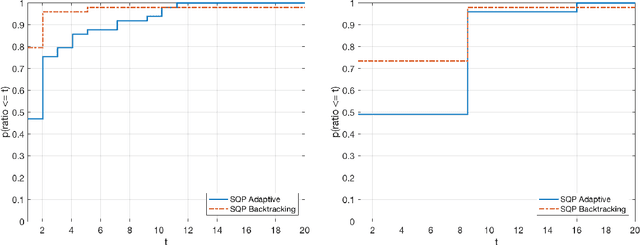
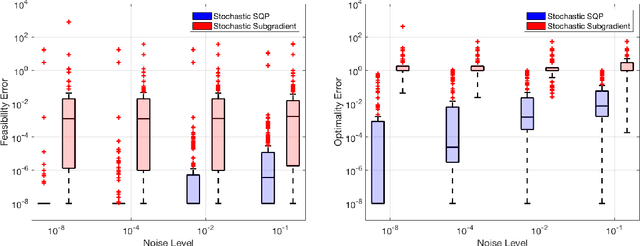
Almost-sure convergence of iterates and multipliers in stochastic sequential quadratic optimization
Aug 07, 2023Stochastic sequential quadratic optimization (SQP) methods for solving continuous optimization problems with nonlinear equality constraints have attracted attention recently, such as for solving large-scale data-fitting problems subject to nonconvex constraints. However, for a recently proposed subclass of such methods that is built on the popular stochastic-gradient methodology from the unconstrained setting, convergence guarantees have been limited to the asymptotic convergence of the expected value of a stationarity measure to zero. This is in contrast to the unconstrained setting in which almost-sure convergence guarantees (of the gradient of the objective to zero) can be proved for stochastic-gradient-based methods. In this paper, new almost-sure convergence guarantees for the primal iterates, Lagrange multipliers, and stationarity measures generated by a stochastic SQP algorithm in this subclass of methods are proved. It is shown that the error in the Lagrange multipliers can be bounded by the distance of the primal iterate to a primal stationary point plus the error in the latest stochastic gradient estimate. It is further shown that, subject to certain assumptions, this latter error can be made to vanish by employing a running average of the Lagrange multipliers that are computed during the run of the algorithm. The results of numerical experiments are provided to demonstrate the proved theoretical guarantees.
A Stochastic-Gradient-based Interior-Point Algorithm for Solving Smooth Bound-Constrained Optimization Problems
Apr 28, 2023A stochastic-gradient-based interior-point algorithm for minimizing a continuously differentiable objective function (that may be nonconvex) subject to bound constraints is presented, analyzed, and demonstrated through experimental results. The algorithm is unique from other interior-point methods for solving smooth (nonconvex) optimization problems since the search directions are computed using stochastic gradient estimates. It is also unique in its use of inner neighborhoods of the feasible region -- defined by a positive and vanishing neighborhood-parameter sequence -- in which the iterates are forced to remain. It is shown that with a careful balance between the barrier, step-size, and neighborhood sequences, the proposed algorithm satisfies convergence guarantees in both deterministic and stochastic settings. The results of numerical experiments show that in both settings the algorithm can outperform a projected-(stochastic)-gradient method.
A Stochastic Sequential Quadratic Optimization Algorithm for Nonlinear Equality Constrained Optimization with Rank-Deficient Jacobians
Jun 24, 2021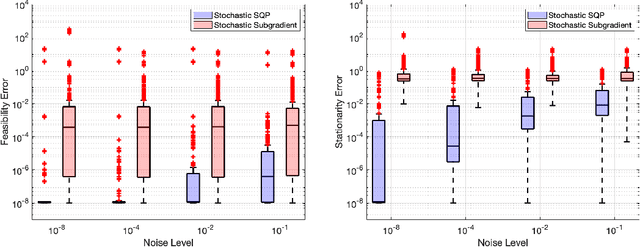
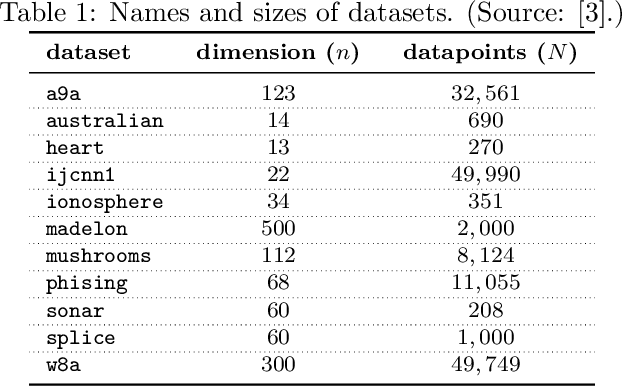
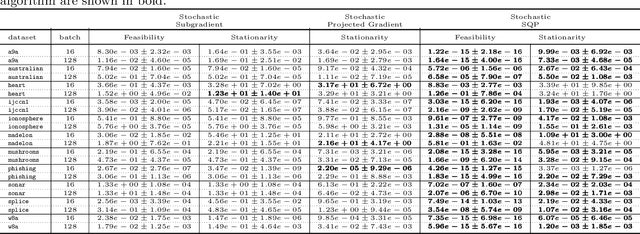
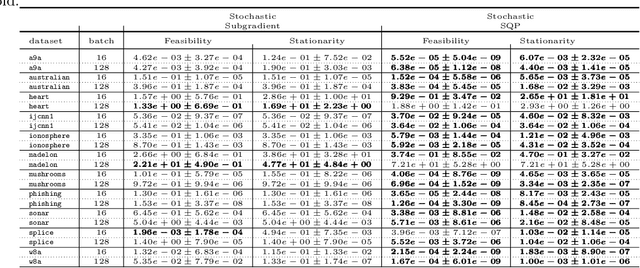
A sequential quadratic optimization algorithm is proposed for solving smooth nonlinear equality constrained optimization problems in which the objective function is defined by an expectation of a stochastic function. The algorithmic structure of the proposed method is based on a step decomposition strategy that is known in the literature to be widely effective in practice, wherein each search direction is computed as the sum of a normal step (toward linearized feasibility) and a tangential step (toward objective decrease in the null space of the constraint Jacobian). However, the proposed method is unique from others in the literature in that it both allows the use of stochastic objective gradient estimates and possesses convergence guarantees even in the setting in which the constraint Jacobians may be rank deficient. The results of numerical experiments demonstrate that the algorithm offers superior performance when compared to popular alternatives.
Sequential Quadratic Optimization for Nonlinear Equality Constrained Stochastic Optimization
Jul 20, 2020
Sequential quadratic optimization algorithms are proposed for solving smooth nonlinear optimization problems with equality constraints. The main focus is an algorithm proposed for the case when the constraint functions are deterministic, and constraint function and derivative values can be computed explicitly, but the objective function is stochastic. It is assumed in this setting that it is intractable to compute objective function and derivative values explicitly, although one can compute stochastic function and gradient estimates. As a starting point for this stochastic setting, an algorithm is proposed for the deterministic setting that is modeled after a state-of-the-art line-search SQP algorithm, but uses a stepsize selection scheme based on Lipschitz constants (or adaptively estimated Lipschitz constants) in place of the line search. This sets the stage for the proposed algorithm for the stochastic setting, for which it is assumed that line searches would be intractable. Under reasonable assumptions, convergence (resp.,~convergence in expectation) from remote starting points is proved for the proposed deterministic (resp.,~stochastic) algorithm. The results of numerical experiments demonstrate the practical performance of our proposed techniques.
Adaptive Stochastic Optimization
Jan 18, 2020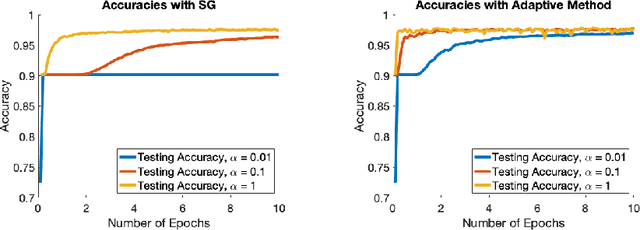
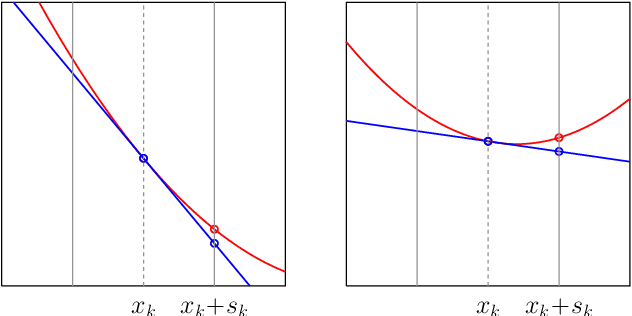
Optimization lies at the heart of machine learning and signal processing. Contemporary approaches based on the stochastic gradient method are non-adaptive in the sense that their implementation employs prescribed parameter values that need to be tuned for each application. This article summarizes recent research and motivates future work on adaptive stochastic optimization methods, which have the potential to offer significant computational savings when training large-scale systems.
A Stochastic Trust Region Algorithm Based on Careful Step Normalization
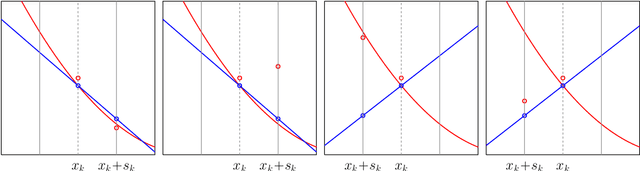
Jun 26, 2018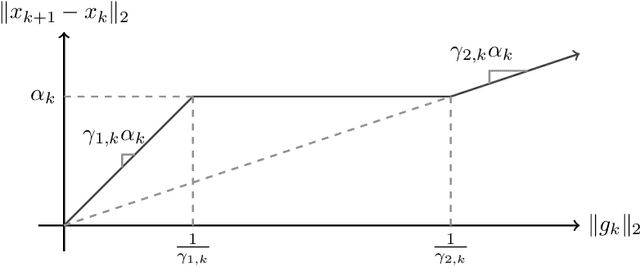
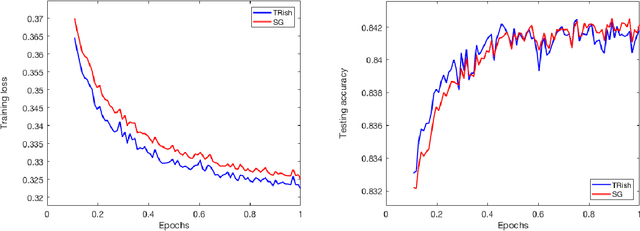
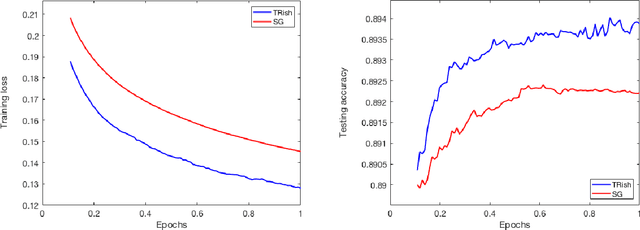
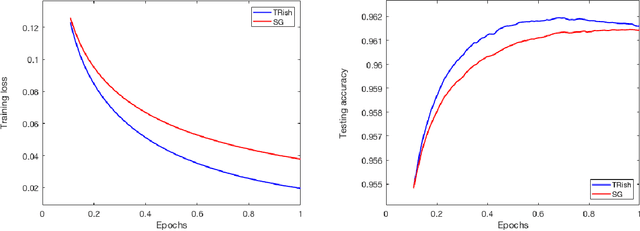
An algorithm is proposed for solving stochastic and finite sum minimization problems. Based on a trust region methodology, the algorithm employs normalized steps, at least as long as the norms of the stochastic gradient estimates are within a specified interval. The complete algorithm---which dynamically chooses whether or not to employ normalized steps---is proved to have convergence guarantees that are similar to those possessed by a traditional stochastic gradient approach under various sets of conditions related to the accuracy of the stochastic gradient estimates and choice of stepsize sequence. The results of numerical experiments are presented when the method is employed to minimize convex and nonconvex machine learning test problems. These results illustrate that the method can outperform a traditional stochastic gradient approach.
Optimization Methods for Large-Scale Machine Learning
Feb 08, 2018
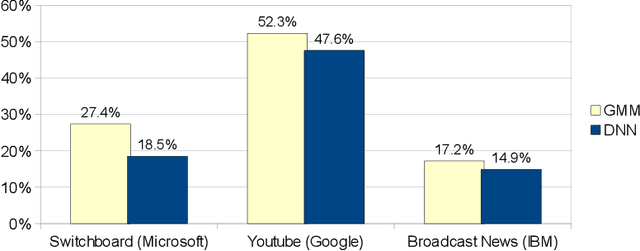
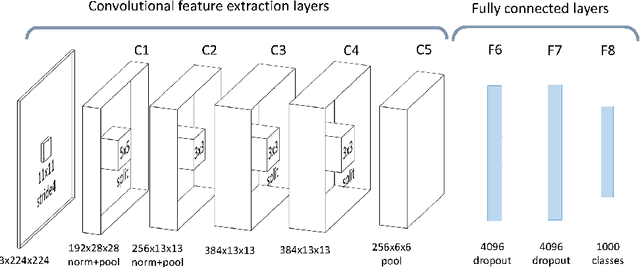
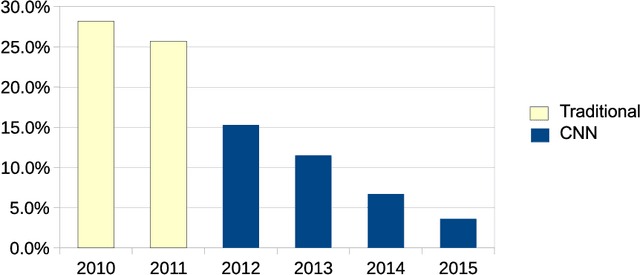
This paper provides a review and commentary on the past, present, and future of numerical optimization algorithms in the context of machine learning applications. Through case studies on text classification and the training of deep neural networks, we discuss how optimization problems arise in machine learning and what makes them challenging. A major theme of our study is that large-scale machine learning represents a distinctive setting in which the stochastic gradient (SG) method has traditionally played a central role while conventional gradient-based nonlinear optimization techniques typically falter. Based on this viewpoint, we present a comprehensive theory of a straightforward, yet versatile SG algorithm, discuss its practical behavior, and highlight opportunities for designing algorithms with improved performance. This leads to a discussion about the next generation of optimization methods for large-scale machine learning, including an investigation of two main streams of research on techniques that diminish noise in the stochastic directions and methods that make use of second-order derivative approximations.