 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Curriculum Learning for Low-Resource Neural Machine Translation
Nov 30, 2020
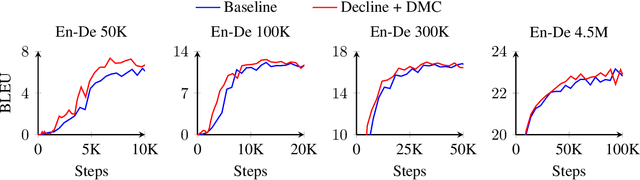
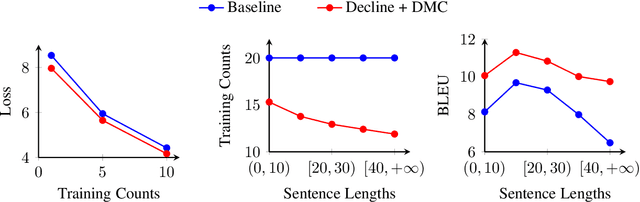
Large amounts of data has made neural machine translation (NMT) a big success in recent years. But it is still a challenge if we train these models on small-scale corpora. In this case, the way of using data appears to be more important. Here, we investigate the effective use of training data for low-resource NMT. In particular, we propose a dynamic curriculum learning (DCL) method to reorder training samples in training. Unlike previous work, we do not use a static scoring function for reordering. Instead, the order of training samples is dynamically determined in two ways - loss decline and model competence. This eases training by highlighting easy samples that the current model has enough competence to learn. We test our DCL method in a Transformer-based system. Experimental results show that DCL outperforms several strong baselines on three low-resource machine translation benchmarks and different sized data of WMT' 16 En-De.
Code-switching pre-training for neural machine translation
Sep 17, 2020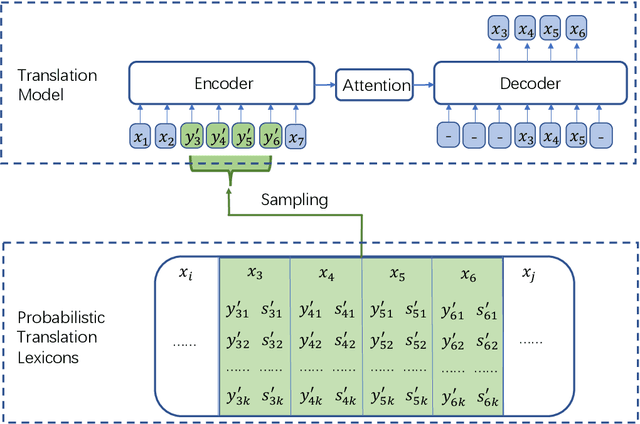
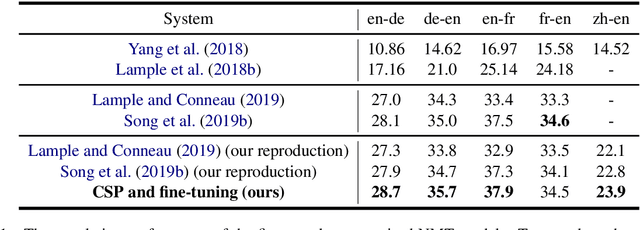

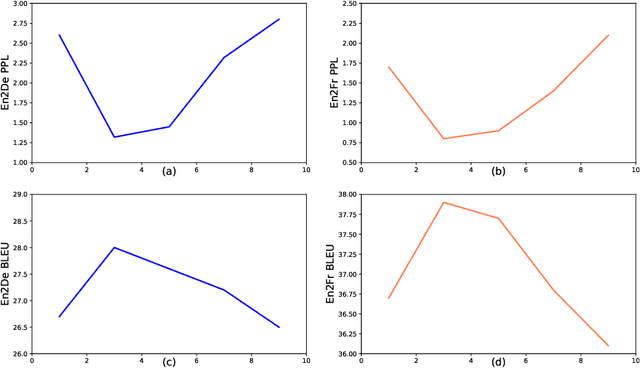
This paper proposes a new pre-training method, called Code-Switching Pre-training (CSP for short) for Neural Machine Translation (NMT). Unlike traditional pre-training method which randomly masks some fragments of the input sentence, the proposed CSP randomly replaces some words in the source sentence with their translation words in the target language. Specifically, we firstly perform lexicon induction with unsupervised word embedding mapping between the source and target languages, and then randomly replace some words in the input sentence with their translation words according to the extracted translation lexicons. CSP adopts the encoder-decoder framework: its encoder takes the code-mixed sentence as input, and its decoder predicts the replaced fragment of the input sentence. In this way, CSP is able to pre-train the NMT model by explicitly making the most of the cross-lingual alignment information extracted from the source and target monolingual corpus. Additionally, we relieve the pretrain-finetune discrepancy caused by the artificial symbols like [mask]. To verify the effectiveness of the proposed method, we conduct extensive experiments on unsupervised and supervised NMT. Experimental results show that CSP achieves significant improvements over baselines without pre-training or with other pre-training methods.
FastBERT: a Self-distilling BERT with Adaptive Inference Time
Apr 29, 2020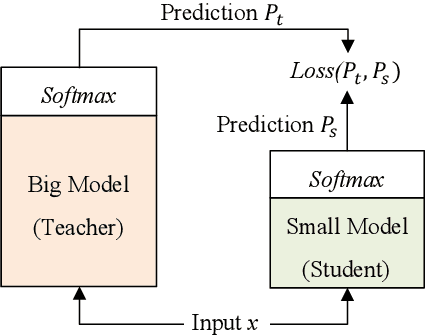
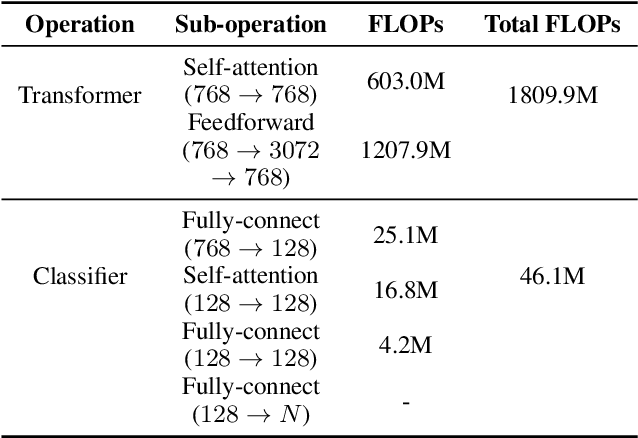
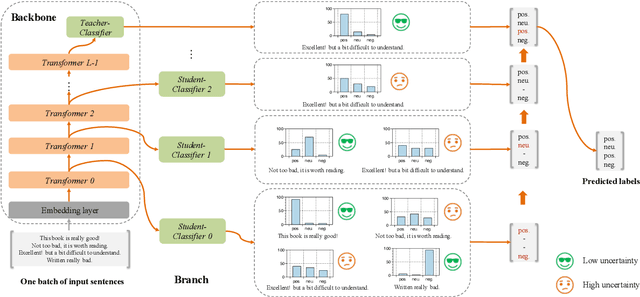
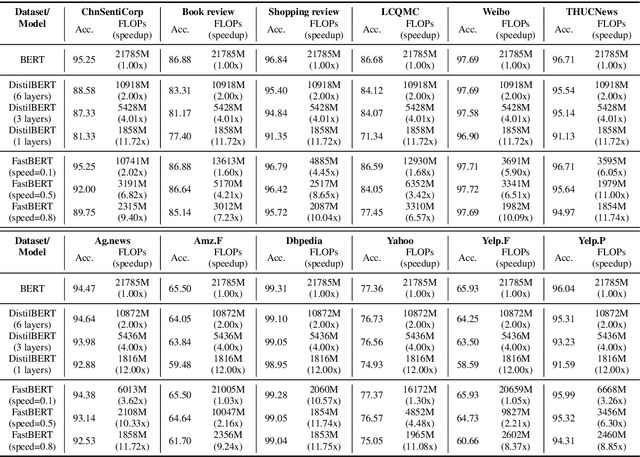
Pre-trained language models like BERT have proven to be highly performant. However, they are often computationally expensive in many practical scenarios, for such heavy models can hardly be readily implemented with limited resources. To improve their efficiency with an assured model performance, we propose a novel speed-tunable FastBERT with adaptive inference time. The speed at inference can be flexibly adjusted under varying demands, while redundant calculation of samples is avoided. Moreover, this model adopts a unique self-distillation mechanism at fine-tuning, further enabling a greater computational efficacy with minimal loss in performance. Our model achieves promising results in twelve English and Chinese datasets. It is able to speed up by a wide range from 1 to 12 times than BERT if given different speedup thresholds to make a speed-performance tradeoff.
A Multi-oriented Chinese Keyword Spotter Guided by Text Line Detection
Jan 06, 2020
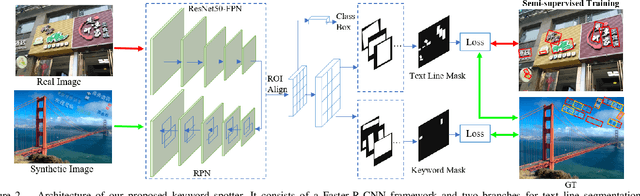

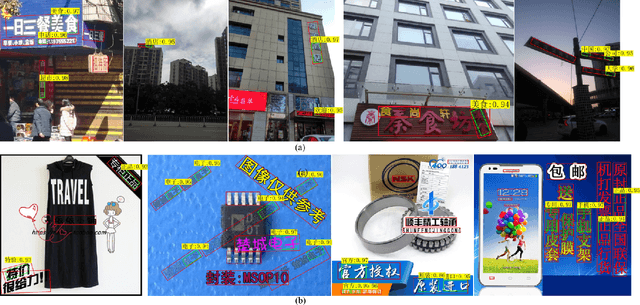
Chinese keyword spotting is a challenging task as there is no visual blank for Chinese words. Different from English words which are split naturally by visual blanks, Chinese words are generally split only by semantic information. In this paper, we propose a new Chinese keyword spotter for natural images, which is inspired by Mask R-CNN. We propose to predict the keyword masks guided by text line detection. Firstly, proposals of text lines are generated by Faster R-CNN;Then, text line masks and keyword masks are predicted by segmentation in the proposals. In this way, the text lines and keywords are predicted in parallel. We create two Chinese keyword datasets based on RCTW-17 and ICPR MTWI2018 to verify the effectiveness of our method.
RefineDetLite: A Lightweight One-stage Object Detection Framework for CPU-only Devices
Nov 20, 2019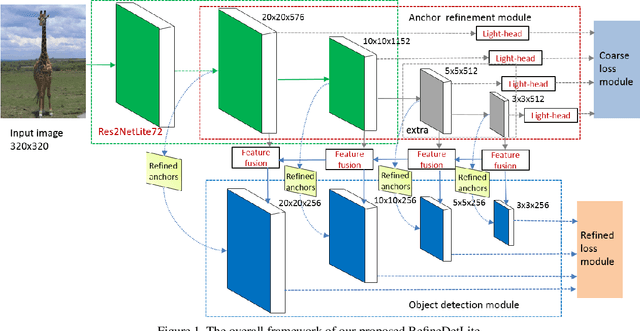
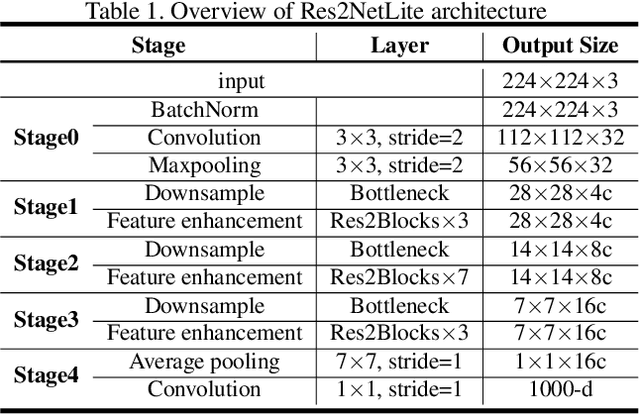
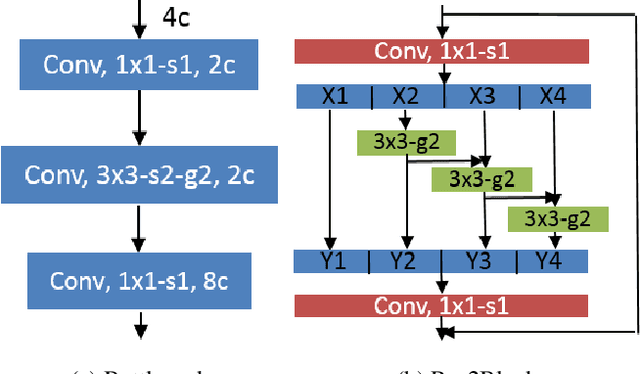
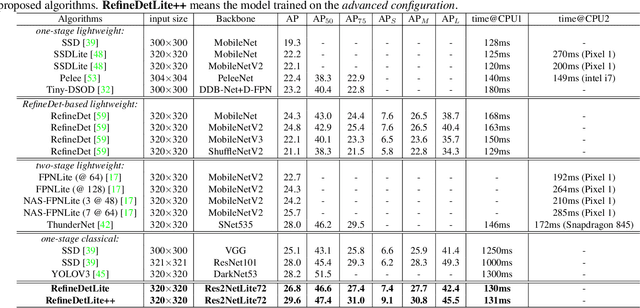
Previous state-of-the-art real-time object detectors have been reported on GPUs which are extremely expensive for processing massive data and in resource-restricted scenarios. Therefore, high efficiency object detectors on CPU-only devices are urgently-needed in industry. The floating-point operations (FLOPs) of networks are not strictly proportional to the running speed on CPU devices, which inspires the design of an exactly "fast" and "accurate" object detector. After investigating the concern gaps between classification networks and detection backbones, and following the design principles of efficient networks, we propose a lightweight residual-like backbone with large receptive fields and wide dimensions for low-level features, which are crucial for detection tasks. Correspondingly, we also design a light-head detection part to match the backbone capability. Furthermore, by analyzing the drawbacks of current one-stage detector training strategies, we also propose three orthogonal training strategies---IOU-guided loss, classes-aware weighting method and balanced multi-task training approach. Without bells and whistles, our proposed RefineDetLite achieves 26.8 mAP on the MSCOCO benchmark at a speed of 130 ms/pic on a single-thread CPU. The detection accuracy can be further increased to 29.6 mAP by integrating all the proposed training strategies, without apparent speed drop.
K-BERT: Enabling Language Representation with Knowledge Graph
Sep 17, 2019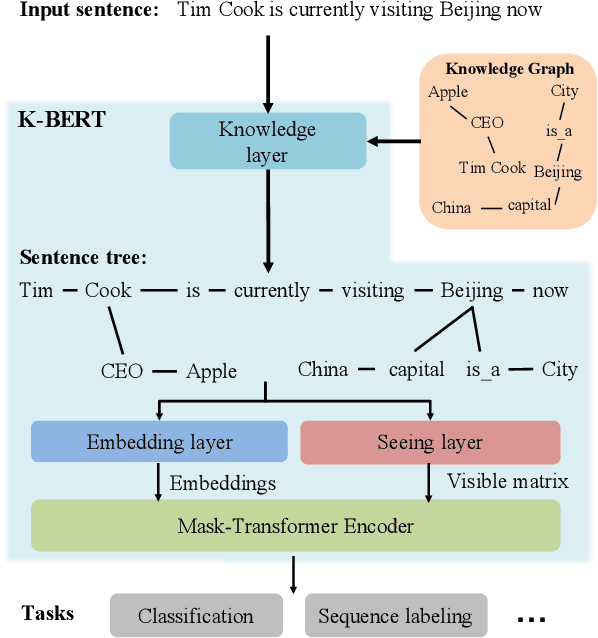
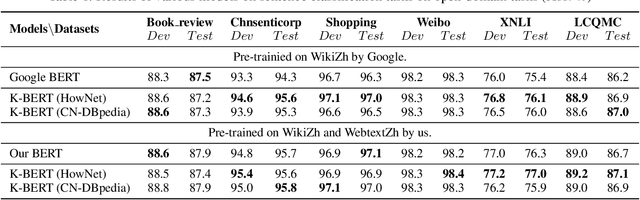
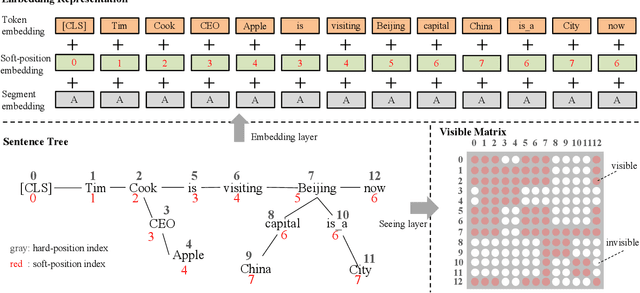
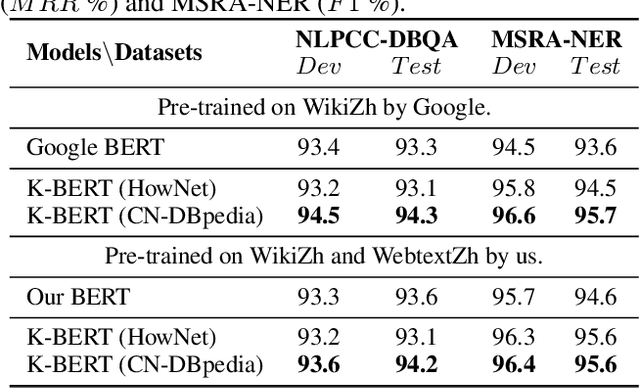
Pre-trained language representation models, such as BERT, capture a general language representation from large-scale corpora, but lack domain-specific knowledge. When reading a domain text, experts make inferences with relevant knowledge. For machines to achieve this capability, we propose a knowledge-enabled language representation model (K-BERT) with knowledge graphs (KGs), in which triples are injected into the sentences as domain knowledge. However, too much knowledge incorporation may divert the sentence from its correct meaning, which is called knowledge noise (KN) issue. To overcome KN, K-BERT introduces soft-position and visible matrix to limit the impact of knowledge. K-BERT can easily inject domain knowledge into the models by equipped with a KG without pre-training by-self because it is capable of loading model parameters from the pre-trained BERT. Our investigation reveals promising results in twelve NLP tasks. Especially in domain-specific tasks (including finance, law, and medicine), K-BERT significantly outperforms BERT, which demonstrates that K-BERT is an excellent choice for solving the knowledge-driven problems that require experts.
UER: An Open-Source Toolkit for Pre-training Models
Sep 12, 2019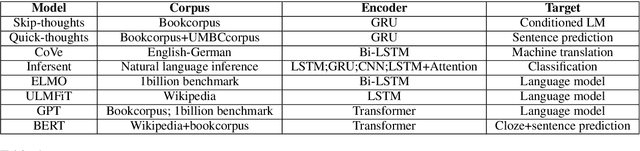
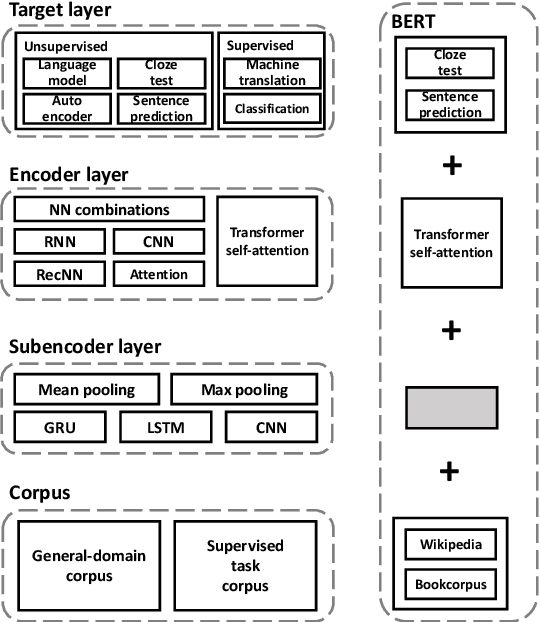
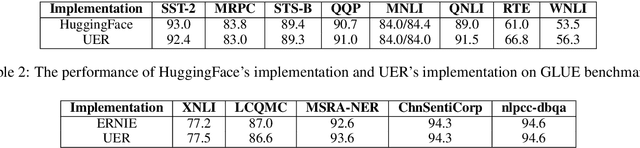
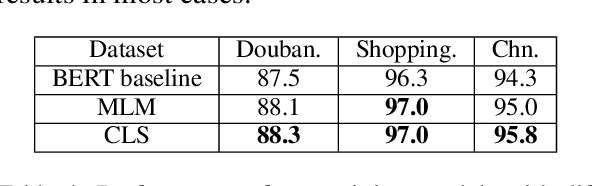
Existing works, including ELMO and BERT, have revealed the importance of pre-training for NLP tasks. While there does not exist a single pre-training model that works best in all cases, it is of necessity to develop a framework that is able to deploy various pre-training models efficiently. For this purpose, we propose an assemble-on-demand pre-training toolkit, namely Universal Encoder Representations (UER). UER is loosely coupled, and encapsulated with rich modules. By assembling modules on demand, users can either reproduce a state-of-the-art pre-training model or develop a pre-training model that remains unexplored. With UER, we have built a model zoo, which contains pre-trained models based on different corpora, encoders, and targets (objectives). With proper pre-trained models, we could achieve new state-of-the-art results on a range of downstream datasets.
Improving Image Captioning with Conditional Generative Adversarial Nets
Sep 06, 2018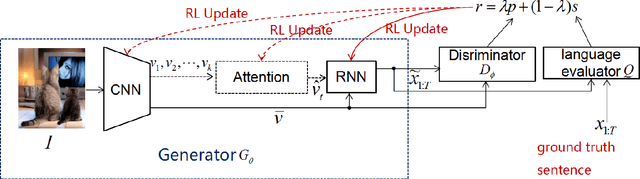
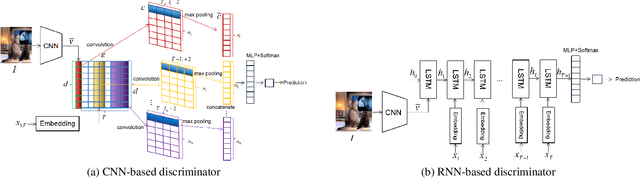
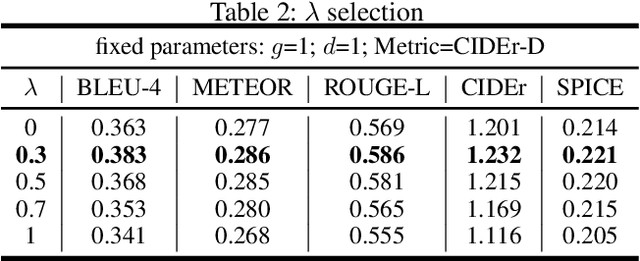
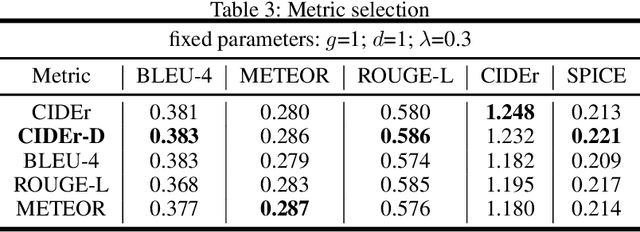
In this paper, we propose a novel conditional-generative-adversarial-nets-based image captioning framework as an extension of traditional reinforcement-learning (RL)-based encoder-decoder architecture. To deal with the inconsistent evaluation problem among different objective language metrics, we are motivated to design some "discriminator" networks to automatically and progressively determine whether generated caption is human described or machine generated. Two kinds of discriminator architectures (CNN and RNN-based structures) are introduced since each has its own advantages. The proposed algorithm is generic so that it can enhance any existing RL-based image captioning framework and we show that the conventional RL training method is just a special case of our approach. Empirically, we show consistent im- provements over all language evaluation metrics for different state-of-the-art image captioning models. In addition, the well-trained discriminators can also be viewed as objective image captioning evaluators