 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgrammatically Interpretable Reinforcement Learning
Jun 08, 2018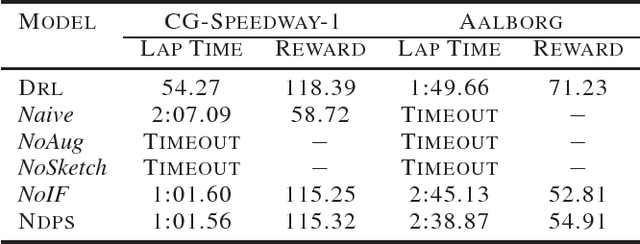


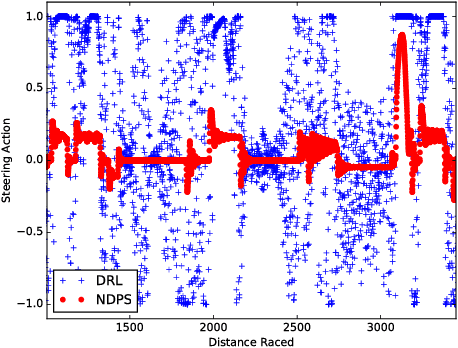
We present a reinforcement learning framework, called Programmatically Interpretable Reinforcement Learning (PIRL), that is designed to generate interpretable and verifiable agent policies. Unlike the popular Deep Reinforcement Learning (DRL) paradigm, which represents policies by neural networks, PIRL represents policies using a high-level, domain-specific programming language. Such programmatic policies have the benefits of being more easily interpreted than neural networks, and being amenable to verification by symbolic methods. We propose a new method, called Neurally Directed Program Search (NDPS), for solving the challenging nonsmooth optimization problem of finding a programmatic policy with maximal reward. NDPS works by first learning a neural policy network using DRL, and then performing a local search over programmatic policies that seeks to minimize a distance from this neural "oracle". We evaluate NDPS on the task of learning to drive a simulated car in the TORCS car-racing environment. We demonstrate that NDPS is able to discover human-readable policies that pass some significant performance bars. We also show that PIRL policies can have smoother trajectories, and can be more easily transferred to environments not encountered during training, than corresponding policies discovered by DRL.
Training verified learners with learned verifiers
May 29, 2018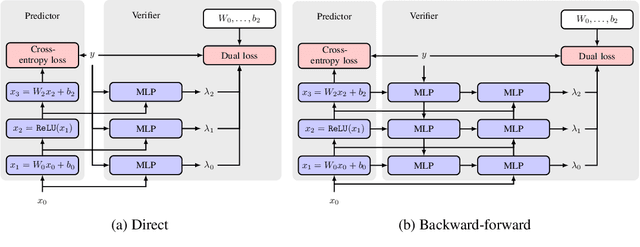
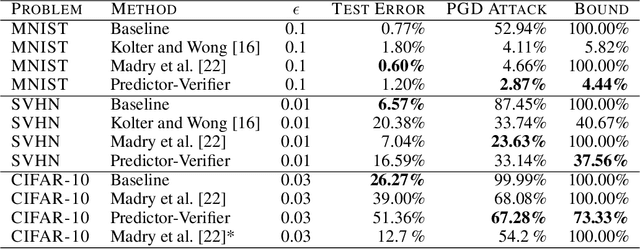
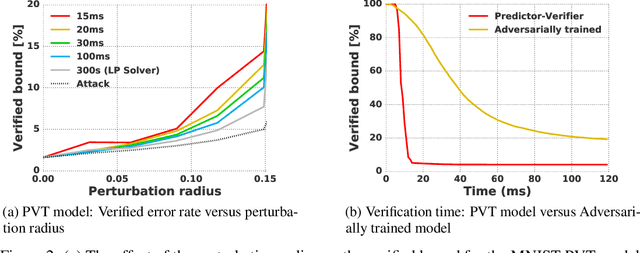
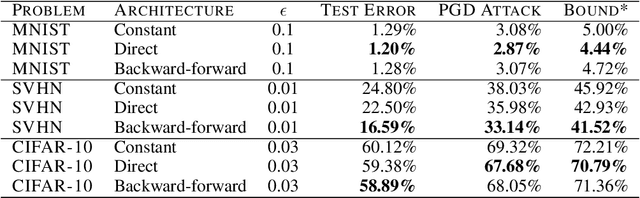
This paper proposes a new algorithmic framework, predictor-verifier training, to train neural networks that are verifiable, i.e., networks that provably satisfy some desired input-output properties. The key idea is to simultaneously train two networks: a predictor network that performs the task at hand,e.g., predicting labels given inputs, and a verifier network that computes a bound on how well the predictor satisfies the properties being verified. Both networks can be trained simultaneously to optimize a weighted combination of the standard data-fitting loss and a term that bounds the maximum violation of the property. Experiments show that not only is the predictor-verifier architecture able to train networks to achieve state of the art verified robustness to adversarial examples with much shorter training times (outperforming previous algorithms on small datasets like MNIST and SVHN), but it can also be scaled to produce the first known (to the best of our knowledge) verifiably robust networks for CIFAR-10.
Value Propagation Networks
May 28, 2018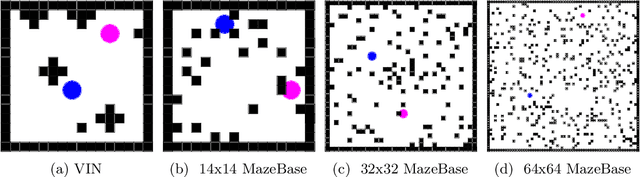

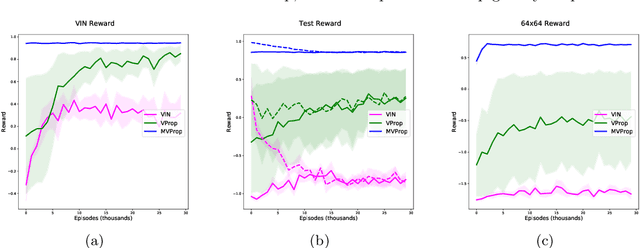
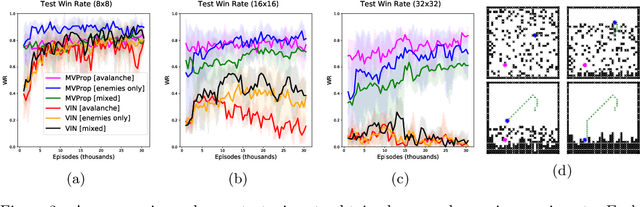
We present Value Propagation (VProp), a parameter-efficient differentiable planning module built on Value Iteration which can successfully be trained using reinforcement learning to solve unseen tasks, has the capability to generalize to larger map sizes, and can learn to navigate in dynamic environments. Furthermore, we show that the module enables learning to plan when the environment also includes stochastic elements, providing a cost-efficient learning system to build low-level size-invariant planners for a variety of interactive navigation problems. We evaluate on static and dynamic configurations of MazeBase grid-worlds, with randomly generated environments of several different sizes, and on a StarCraft navigation scenario, with more complex dynamics, and pixels as input.
A Unified View of Piecewise Linear Neural Network Verification
May 22, 2018
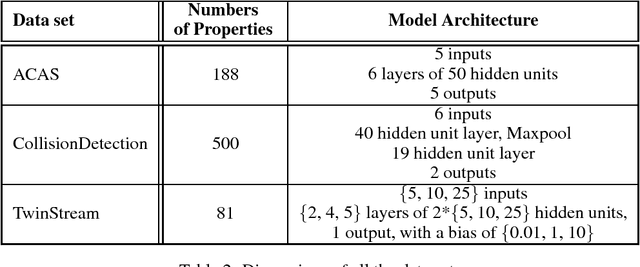
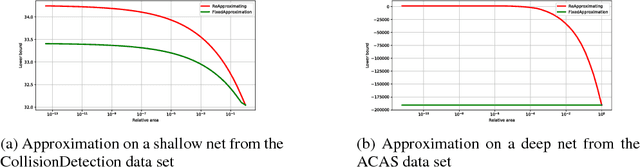
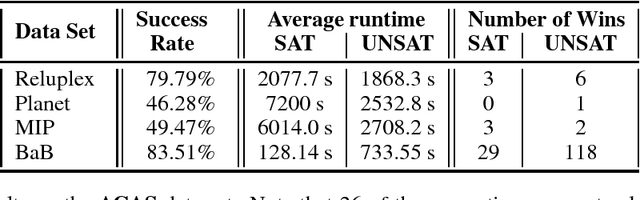
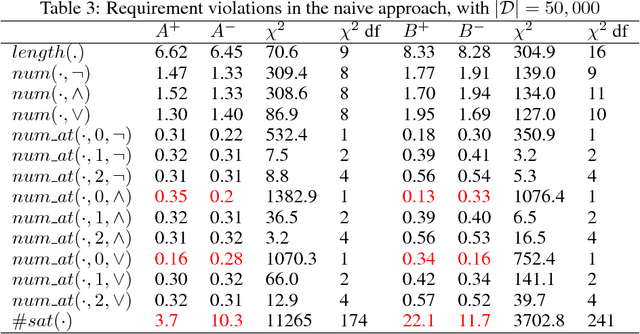
The success of Deep Learning and its potential use in many safety-critical applications has motivated research on formal verification of Neural Network (NN) models. Despite the reputation of learned NN models to behave as black boxes and the theoretical hardness of proving their properties, researchers have been successful in verifying some classes of models by exploiting their piecewise linear structure and taking insights from formal methods such as Satisifiability Modulo Theory. These methods are however still far from scaling to realistic neural networks. To facilitate progress on this crucial area, we make two key contributions. First, we present a unified framework that encompasses previous methods. This analysis results in the identification of new methods that combine the strengths of multiple existing approaches, accomplishing a speedup of two orders of magnitude compared to the previous state of the art. Second, we propose a new data set of benchmarks which includes a collection of previously released testcases. We use the benchmark to provide the first experimental comparison of existing algorithms and identify the factors impacting the hardness of verification problems.
Leveraging Grammar and Reinforcement Learning for Neural Program Synthesis
May 22, 2018
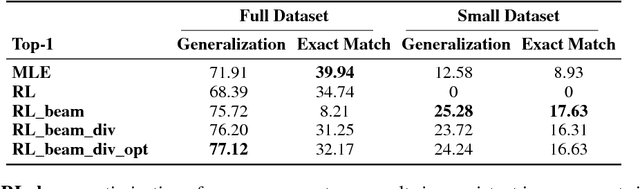
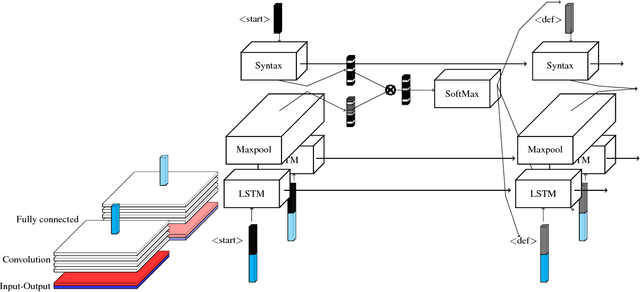
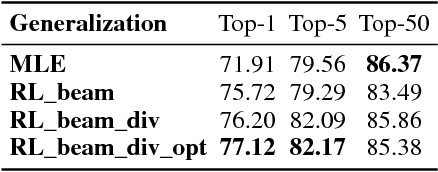
Program synthesis is the task of automatically generating a program consistent with a specification. Recent years have seen proposal of a number of neural approaches for program synthesis, many of which adopt a sequence generation paradigm similar to neural machine translation, in which sequence-to-sequence models are trained to maximize the likelihood of known reference programs. While achieving impressive results, this strategy has two key limitations. First, it ignores Program Aliasing: the fact that many different programs may satisfy a given specification (especially with incomplete specifications such as a few input-output examples). By maximizing the likelihood of only a single reference program, it penalizes many semantically correct programs, which can adversely affect the synthesizer performance. Second, this strategy overlooks the fact that programs have a strict syntax that can be efficiently checked. To address the first limitation, we perform reinforcement learning on top of a supervised model with an objective that explicitly maximizes the likelihood of generating semantically correct programs. For addressing the second limitation, we introduce a training procedure that directly maximizes the probability of generating syntactically correct programs that fulfill the specification. We show that our contributions lead to improved accuracy of the models, especially in cases where the training data is limited.
Stabilising Experience Replay for Deep Multi-Agent Reinforcement Learning
May 21, 2018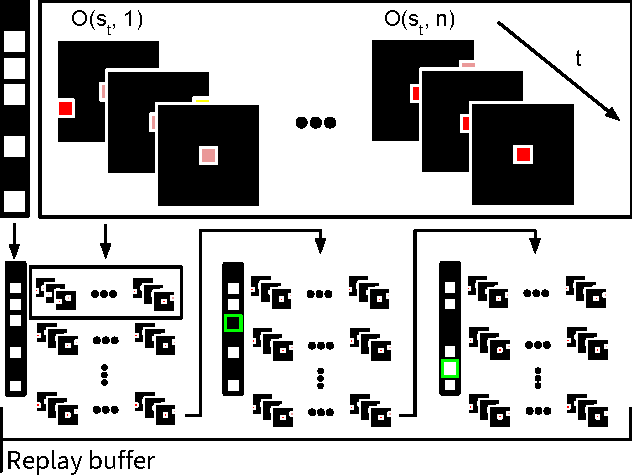

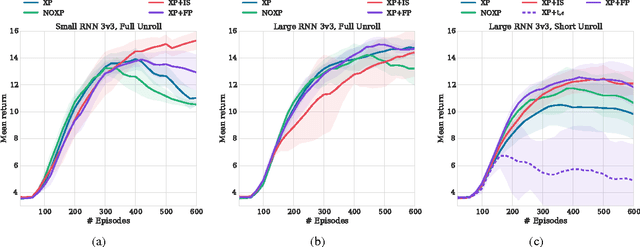
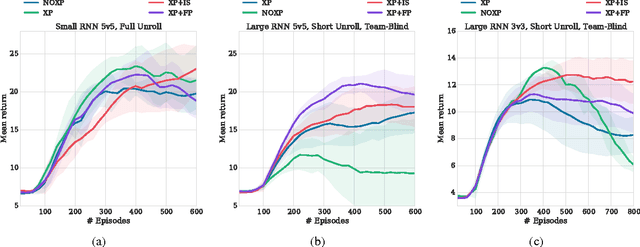
Many real-world problems, such as network packet routing and urban traffic control, are naturally modeled as multi-agent reinforcement learning (RL) problems. However, existing multi-agent RL methods typically scale poorly in the problem size. Therefore, a key challenge is to translate the success of deep learning on single-agent RL to the multi-agent setting. A major stumbling block is that independent Q-learning, the most popular multi-agent RL method, introduces nonstationarity that makes it incompatible with the experience replay memory on which deep Q-learning relies. This paper proposes two methods that address this problem: 1) using a multi-agent variant of importance sampling to naturally decay obsolete data and 2) conditioning each agent's value function on a fingerprint that disambiguates the age of the data sampled from the replay memory. Results on a challenging decentralised variant of StarCraft unit micromanagement confirm that these methods enable the successful combination of experience replay with multi-agent RL.
Batched Large-scale Bayesian Optimization in High-dimensional Spaces
May 16, 2018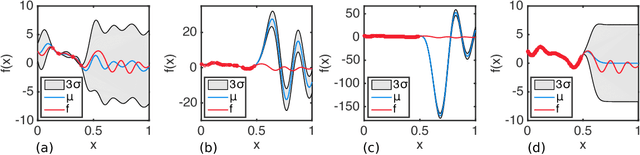
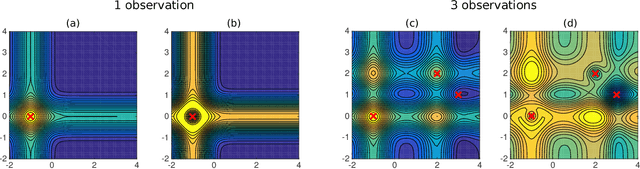

Bayesian optimization (BO) has become an effective approach for black-box function optimization problems when function evaluations are expensive and the optimum can be achieved within a relatively small number of queries. However, many cases, such as the ones with high-dimensional inputs, may require a much larger number of observations for optimization. Despite an abundance of observations thanks to parallel experiments, current BO techniques have been limited to merely a few thousand observations. In this paper, we propose ensemble Bayesian optimization (EBO) to address three current challenges in BO simultaneously: (1) large-scale observations; (2) high dimensional input spaces; and (3) selections of batch queries that balance quality and diversity. The key idea of EBO is to operate on an ensemble of additive Gaussian process models, each of which possesses a randomized strategy to divide and conquer. We show unprecedented, previously impossible results of scaling up BO to tens of thousands of observations within minutes of computation.
Can Neural Networks Understand Logical Entailment?
Feb 23, 2018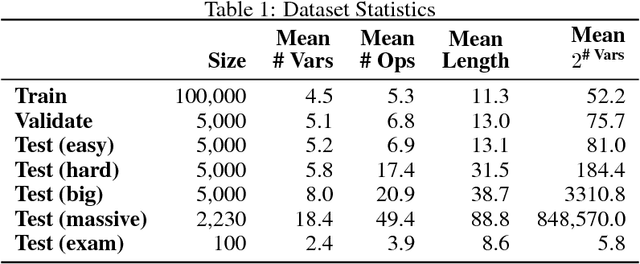
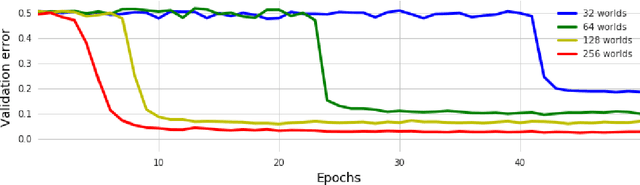
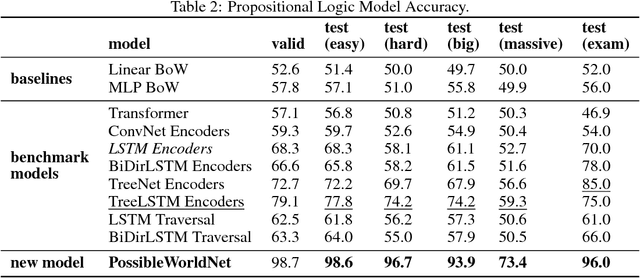
We introduce a new dataset of logical entailments for the purpose of measuring models' ability to capture and exploit the structure of logical expressions against an entailment prediction task. We use this task to compare a series of architectures which are ubiquitous in the sequence-processing literature, in addition to a new model class---PossibleWorldNets---which computes entailment as a "convolution over possible worlds". Results show that convolutional networks present the wrong inductive bias for this class of problems relative to LSTM RNNs, tree-structured neural networks outperform LSTM RNNs due to their enhanced ability to exploit the syntax of logic, and PossibleWorldNets outperform all benchmarks.
Batched High-dimensional Bayesian Optimization via Structural Kernel Learning
Jan 06, 2018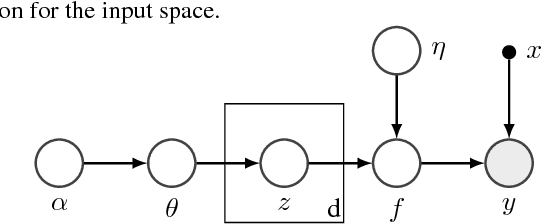
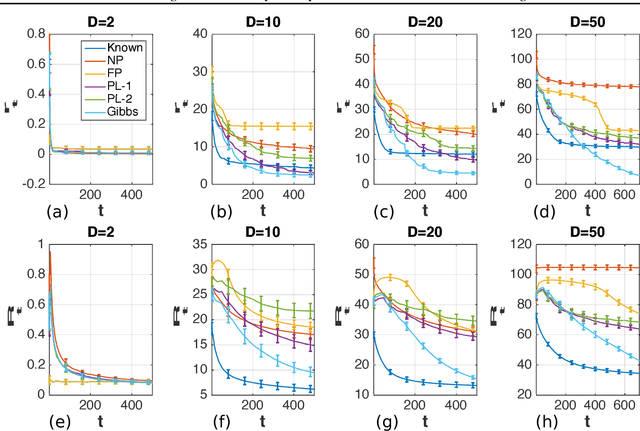
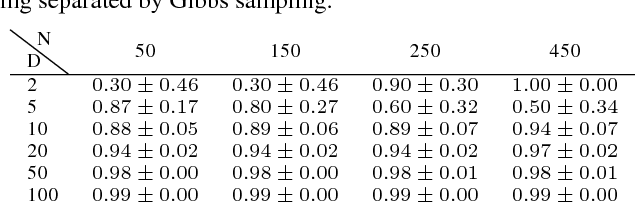
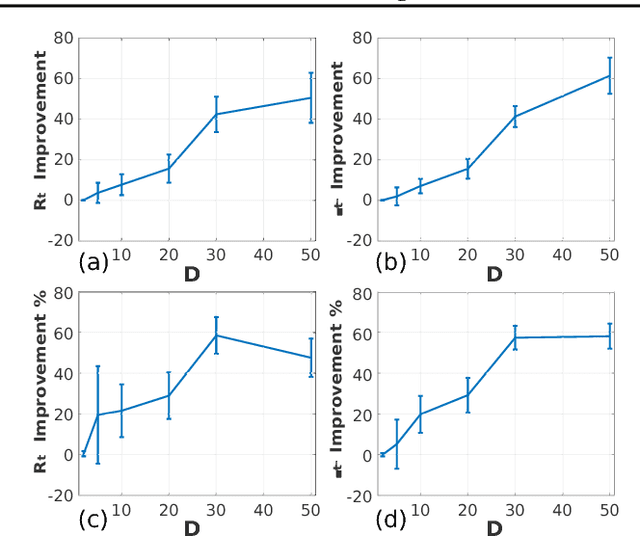
Optimization of high-dimensional black-box functions is an extremely challenging problem. While Bayesian optimization has emerged as a popular approach for optimizing black-box functions, its applicability has been limited to low-dimensional problems due to its computational and statistical challenges arising from high-dimensional settings. In this paper, we propose to tackle these challenges by (1) assuming a latent additive structure in the function and inferring it properly for more efficient and effective BO, and (2) performing multiple evaluations in parallel to reduce the number of iterations required by the method. Our novel approach learns the latent structure with Gibbs sampling and constructs batched queries using determinantal point processes. Experimental validations on both synthetic and real-world functions demonstrate that the proposed method outperforms the existing state-of-the-art approaches.
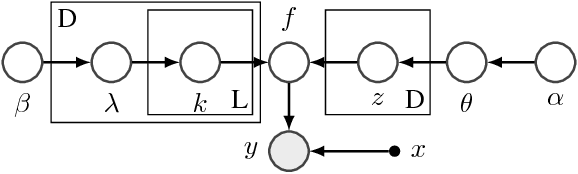
Learning Disentangled Representations with Semi-Supervised Deep Generative Models
Nov 13, 2017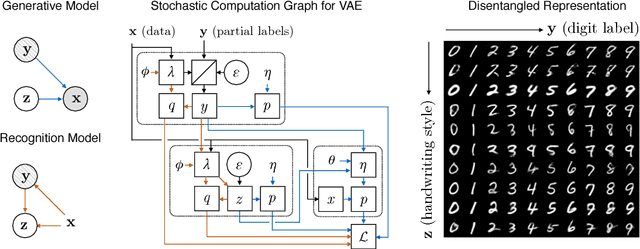

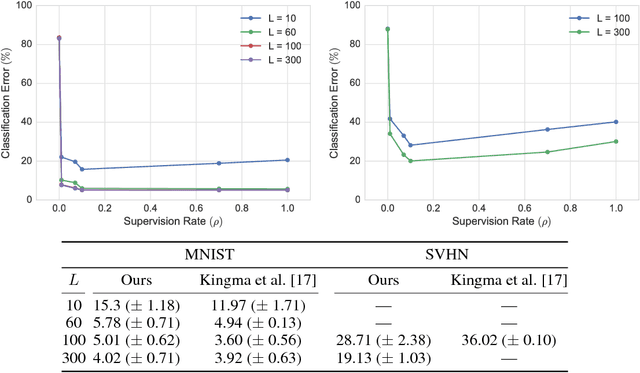
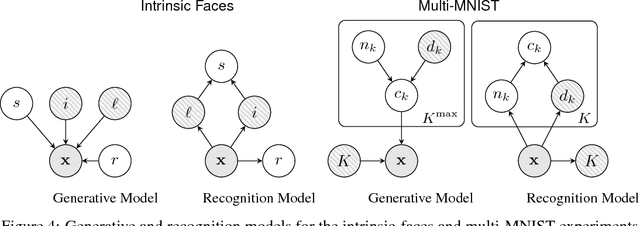
Variational autoencoders (VAEs) learn representations of data by jointly training a probabilistic encoder and decoder network. Typically these models encode all features of the data into a single variable. Here we are interested in learning disentangled representations that encode distinct aspects of the data into separate variables. We propose to learn such representations using model architectures that generalise from standard VAEs, employing a general graphical model structure in the encoder and decoder. This allows us to train partially-specified models that make relatively strong assumptions about a subset of interpretable variables and rely on the flexibility of neural networks to learn representations for the remaining variables. We further define a general objective for semi-supervised learning in this model class, which can be approximated using an importance sampling procedure. We evaluate our framework's ability to learn disentangled representations, both by qualitative exploration of its generative capacity, and quantitative evaluation of its discriminative ability on a variety of models and datasets.