 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHealing Unsafe Dialogue Responses with Weak Supervision Signals
May 25, 2023Recent years have seen increasing concerns about the unsafe response generation of large-scale dialogue systems, where agents will learn offensive or biased behaviors from the real-world corpus. Some methods are proposed to address the above issue by detecting and replacing unsafe training examples in a pipeline style. Though effective, they suffer from a high annotation cost and adapt poorly to unseen scenarios as well as adversarial attacks. Besides, the neglect of providing safe responses (e.g. simply replacing with templates) will cause the information-missing problem of dialogues. To address these issues, we propose an unsupervised pseudo-label sampling method, TEMP, that can automatically assign potential safe responses. Specifically, our TEMP method groups responses into several clusters and samples multiple labels with an adaptively sharpened sampling strategy, inspired by the observation that unsafe samples in the clusters are usually few and distribute in the tail. Extensive experiments in chitchat and task-oriented dialogues show that our TEMP outperforms state-of-the-art models with weak supervision signals and obtains comparable results under unsupervised learning settings.
MERGE: Fast Private Text Generation
May 25, 2023Recent years have seen increasing concerns about the private inference of NLP services and Transformer models. However, existing two-party privacy-preserving methods solely consider NLU scenarios, while the private inference of text generation such as translation, dialogue, and code completion remains unsolved. Besides, while migrated to NLG models, existing privacy-preserving methods perform poorly in terms of inference speed, and suffer from the convergence problem during the training stage. To address these issues, we propose MERGE, a fast private text generation framework for Transformer-based language models. Specifically, MERGE reuse the output hidden state as the word embedding to bypass the embedding computation, and reorganize the linear operations in the Transformer module to accelerate the forward procedure. Based on these two optimizations, extensive experiments show that MERGE can achieve a 26.5x speedup under the sequence length 512, and reduce 80\% communication bytes, with an up to 10x speedup to existing state-of-art models.
Adaptive loose optimization for robust question answering
May 06, 2023



Question answering methods are well-known for leveraging data bias, such as the language prior in visual question answering and the position bias in machine reading comprehension (extractive question answering). Current debiasing methods often come at the cost of significant in-distribution performance to achieve favorable out-of-distribution generalizability, while non-debiasing methods sacrifice a considerable amount of out-of-distribution performance in order to obtain high in-distribution performance. Therefore, it is challenging for them to deal with the complicated changing real-world situations. In this paper, we propose a simple yet effective novel loss function with adaptive loose optimization, which seeks to make the best of both worlds for question answering. Our main technical contribution is to reduce the loss adaptively according to the ratio between the previous and current optimization state on mini-batch training data. This loose optimization can be used to prevent non-debiasing methods from overlearning data bias while enabling debiasing methods to maintain slight bias learning. Experiments on the visual question answering datasets, including VQA v2, VQA-CP v1, VQA-CP v2, GQA-OOD, and the extractive question answering dataset SQuAD demonstrate that our approach enables QA methods to obtain state-of-the-art in- and out-of-distribution performance in most cases. The source code has been released publicly in \url{https://github.com/reml-group/ALO}.
Multi-Action Dialog Policy Learning from Logged User Feedback
Feb 27, 2023Multi-action dialog policy, which generates multiple atomic dialog actions per turn, has been widely applied in task-oriented dialog systems to provide expressive and efficient system responses. Existing policy models usually imitate action combinations from the labeled multi-action dialog examples. Due to data limitations, they generalize poorly toward unseen dialog flows. While reinforcement learning-based methods are proposed to incorporate the service ratings from real users and user simulators as external supervision signals, they suffer from sparse and less credible dialog-level rewards. To cope with this problem, we explore to improve multi-action dialog policy learning with explicit and implicit turn-level user feedback received for historical predictions (i.e., logged user feedback) that are cost-efficient to collect and faithful to real-world scenarios. The task is challenging since the logged user feedback provides only partial label feedback limited to the particular historical dialog actions predicted by the agent. To fully exploit such feedback information, we propose BanditMatch, which addresses the task from a feedback-enhanced semi-supervised learning perspective with a hybrid objective of semi-supervised learning and bandit learning. BanditMatch integrates pseudo-labeling methods to better explore the action space through constructing full label feedback. Extensive experiments show that our BanditMatch outperforms the state-of-the-art methods by generating more concise and informative responses. The source code and the appendix of this paper can be obtained from https://github.com/ShuoZhangXJTU/BanditMatch.
Fast Gumbel-Max Sketch and its Applications
Feb 10, 2023



The well-known Gumbel-Max Trick for sampling elements from a categorical distribution (or more generally a non-negative vector) and its variants have been widely used in areas such as machine learning and information retrieval. To sample a random element $i$ in proportion to its positive weight $v_i$, the Gumbel-Max Trick first computes a Gumbel random variable $g_i$ for each positive weight element $i$, and then samples the element $i$ with the largest value of $g_i+\ln v_i$. Recently, applications including similarity estimation and weighted cardinality estimation require to generate $k$ independent Gumbel-Max variables from high dimensional vectors. However, it is computationally expensive for a large $k$ (e.g., hundreds or even thousands) when using the traditional Gumbel-Max Trick. To solve this problem, we propose a novel algorithm, FastGM, which reduces the time complexity from $O(kn^+)$ to $O(k \ln k + n^+)$, where $n^+$ is the number of positive elements in the vector of interest. FastGM stops the procedure of Gumbel random variables computing for many elements, especially for those with small weights. We perform experiments on a variety of real-world datasets and the experimental results demonstrate that FastGM is orders of magnitude faster than state-of-the-art methods without sacrificing accuracy or incurring additional expenses.
Federated Learning over Coupled Graphs
Jan 26, 2023Graphs are widely used to represent the relations among entities. When one owns the complete data, an entire graph can be easily built, therefore performing analysis on the graph is straightforward. However, in many scenarios, it is impractical to centralize the data due to data privacy concerns. An organization or party only keeps a part of the whole graph data, i.e., graph data is isolated from different parties. Recently, Federated Learning (FL) has been proposed to solve the data isolation issue, mainly for Euclidean data. It is still a challenge to apply FL on graph data because graphs contain topological information which is notorious for its non-IID nature and is hard to partition. In this work, we propose a novel FL framework for graph data, FedCog, to efficiently handle coupled graphs that are a kind of distributed graph data, but widely exist in a variety of real-world applications such as mobile carriers' communication networks and banks' transaction networks. We theoretically prove the correctness and security of FedCog. Experimental results demonstrate that our method FedCog significantly outperforms traditional FL methods on graphs. Remarkably, our FedCog improves the accuracy of node classification tasks by up to 14.7%.
"Think Before You Speak": Improving Multi-Action Dialog Policy by Planning Single-Action Dialogs
Apr 25, 2022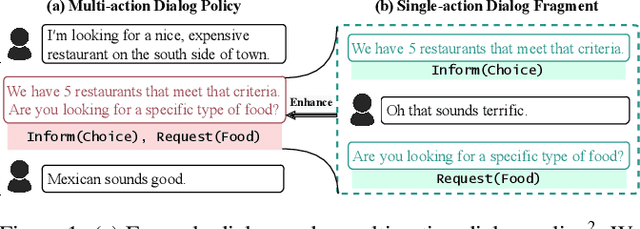
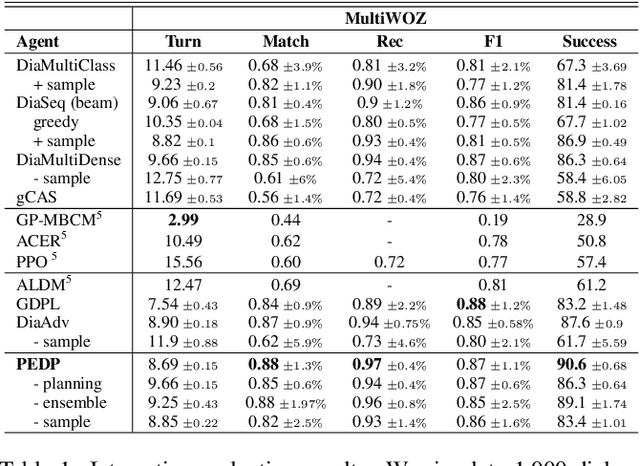
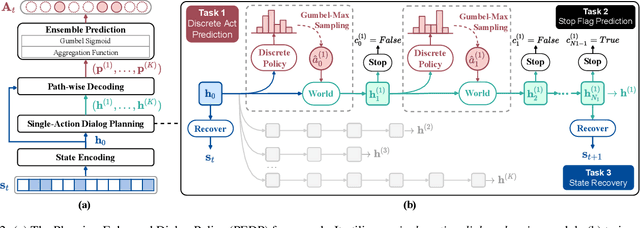
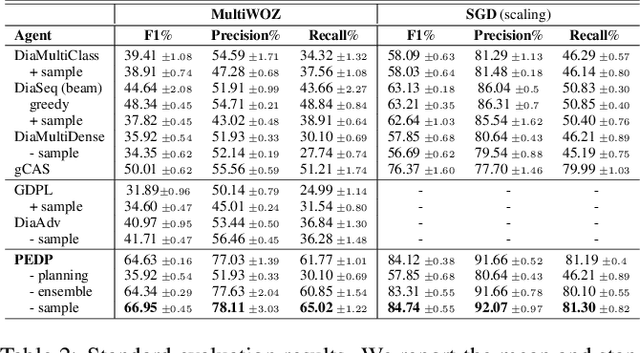
Multi-action dialog policy (MADP), which generates multiple atomic dialog actions per turn, has been widely applied in task-oriented dialog systems to provide expressive and efficient system responses. Existing MADP models usually imitate action combinations from the labeled multi-action dialog samples. Due to data limitations, they generalize poorly toward unseen dialog flows. While interactive learning and reinforcement learning algorithms can be applied to incorporate external data sources of real users and user simulators, they take significant manual effort to build and suffer from instability. To address these issues, we propose Planning Enhanced Dialog Policy (PEDP), a novel multi-task learning framework that learns single-action dialog dynamics to enhance multi-action prediction. Our PEDP method employs model-based planning for conceiving what to express before deciding the current response through simulating single-action dialogs. Experimental results on the MultiWOZ dataset demonstrate that our fully supervised learning-based method achieves a solid task success rate of 90.6%, improving 3% compared to the state-of-the-art methods.
Learning to Check Contract Inconsistencies
Dec 15, 2020
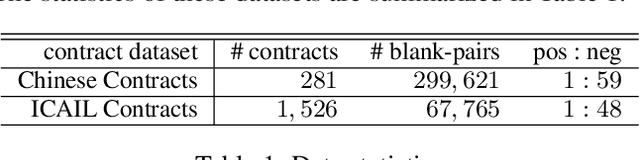
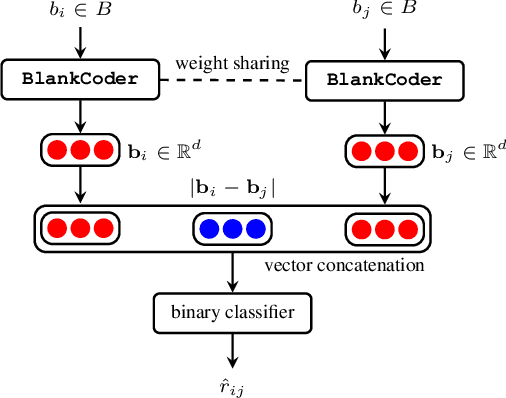
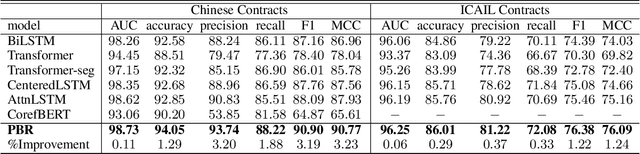
Contract consistency is important in ensuring the legal validity of the contract. In many scenarios, a contract is written by filling the blanks in a precompiled form. Due to carelessness, two blanks that should be filled with the same (or different)content may be incorrectly filled with different (or same) content. This will result in the issue of contract inconsistencies, which may severely impair the legal validity of the contract. Traditional methods to address this issue mainly rely on manual contract review, which is labor-intensive and costly. In this work, we formulate a novel Contract Inconsistency Checking (CIC) problem, and design an end-to-end framework, called Pair-wise Blank Resolution (PBR), to solve the CIC problem with high accuracy. Our PBR model contains a novel BlankCoder to address the challenge of modeling meaningless blanks. BlankCoder adopts a two-stage attention mechanism that adequately associates a meaningless blank with its relevant descriptions while avoiding the incorporation of irrelevant context words. Experiments conducted on real-world datasets show the promising performance of our method with a balanced accuracy of 94.05% and an F1 score of 90.90% in the CIC problem.
Node Classification on Graphs with Few-Shot Novel Labels via Meta Transformed Network Embedding
Jul 06, 2020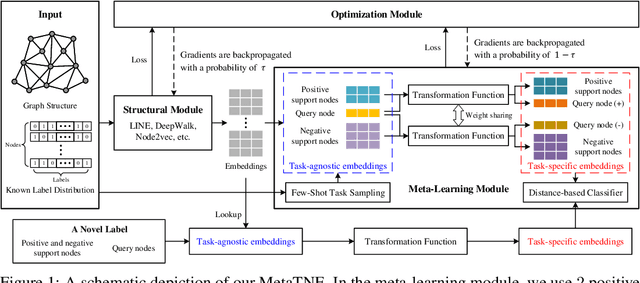
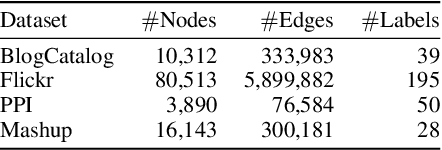
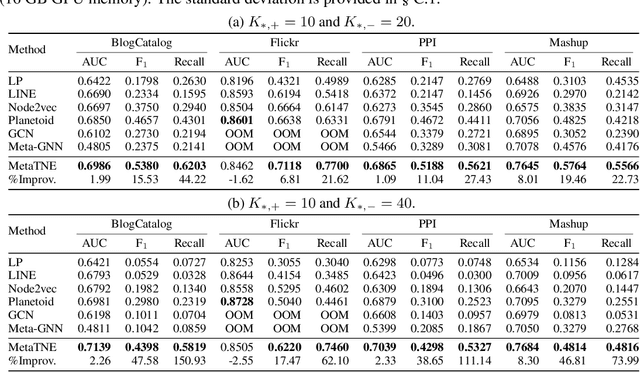
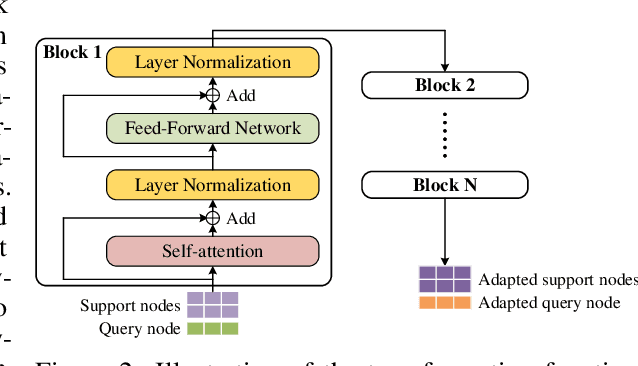
We study the problem of node classification on graphs with few-shot novel labels, which has two distinctive properties: (1) There are novel labels to emerge in the graph; (2) The novel labels have only a few representative nodes for training a classifier. The study of this problem is instructive and corresponds to many applications such as recommendations for newly formed groups with only a few users in online social networks. To cope with this problem, we propose a novel Meta Transformed Network Embedding framework (MetaTNE), which consists of three modules: (1) A \emph{structural module} provides each node a latent representation according to the graph structure. (2) A \emph{meta-learning module} captures the relationships between the graph structure and the node labels as prior knowledge in a meta-learning manner. Additionally, we introduce an \emph{embedding transformation function} that remedies the deficiency of the straightforward use of meta-learning. Inherently, the meta-learned prior knowledge can be used to facilitate the learning of few-shot novel labels. (3) An \emph{optimization module} employs a simple yet effective scheduling strategy to train the above two modules with a balance between graph structure learning and meta-learning. Experiments on four real-world datasets show that MetaTNE brings a huge improvement over the state-of-the-art methods.
Distinguish Confusing Law Articles for Legal Judgment Prediction
Apr 23, 2020
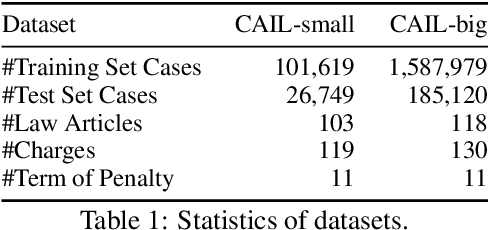

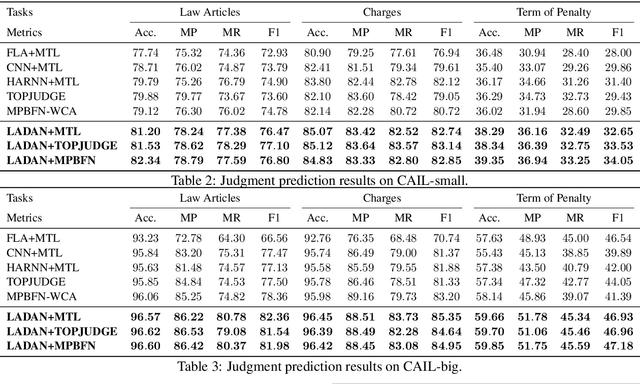
Legal Judgment Prediction (LJP) is the task of automatically predicting a law case's judgment results given a text describing its facts, which has excellent prospects in judicial assistance systems and convenient services for the public. In practice, confusing charges are frequent, because law cases applicable to similar law articles are easily misjudged. For addressing this issue, the existing method relies heavily on domain experts, which hinders its application in different law systems. In this paper, we present an end-to-end model, LADAN, to solve the task of LJP. To distinguish confusing charges, we propose a novel graph neural network to automatically learn subtle differences between confusing law articles and design a novel attention mechanism that fully exploits the learned differences to extract compelling discriminative features from fact descriptions attentively. Experiments conducted on real-world datasets demonstrate the superiority of our LADAN.