 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Optical Flow from Event Camera with Rendered Dataset
Mar 20, 2023



We study the problem of estimating optical flow from event cameras. One important issue is how to build a high-quality event-flow dataset with accurate event values and flow labels. Previous datasets are created by either capturing real scenes by event cameras or synthesizing from images with pasted foreground objects. The former case can produce real event values but with calculated flow labels, which are sparse and inaccurate. The later case can generate dense flow labels but the interpolated events are prone to errors. In this work, we propose to render a physically correct event-flow dataset using computer graphics models. In particular, we first create indoor and outdoor 3D scenes by Blender with rich scene content variations. Second, diverse camera motions are included for the virtual capturing, producing images and accurate flow labels. Third, we render high-framerate videos between images for accurate events. The rendered dataset can adjust the density of events, based on which we further introduce an adaptive density module (ADM). Experiments show that our proposed dataset can facilitate event-flow learning, whereas previous approaches when trained on our dataset can improve their performances constantly by a relatively large margin. In addition, event-flow pipelines when equipped with our ADM can further improve performances.
Improving the Robustness of Deep Convolutional Neural Networks Through Feature Learning
Mar 11, 2023Deep convolutional neural network (DCNN for short) models are vulnerable to examples with small perturbations. Adversarial training (AT for short) is a widely used approach to enhance the robustness of DCNN models by data augmentation. In AT, the DCNN models are trained with clean examples and adversarial examples (AE for short) which are generated using a specific attack method, aiming to gain ability to defend themselves when facing the unseen AEs. However, in practice, the trained DCNN models are often fooled by the AEs generated by the novel attack methods. This naturally raises a question: can a DCNN model learn certain features which are insensitive to small perturbations, and further defend itself no matter what attack methods are presented. To answer this question, this paper makes a beginning effort by proposing a shallow binary feature module (SBFM for short), which can be integrated into any popular backbone. The SBFM includes two types of layers, i.e., Sobel layer and threshold layer. In Sobel layer, there are four parallel feature maps which represent horizontal, vertical, and diagonal edge features, respectively. And in threshold layer, it turns the edge features learnt by Sobel layer to the binary features, which then are feeded into the fully connected layers for classification with the features learnt by the backbone. We integrate SBFM into VGG16 and ResNet34, respectively, and conduct experiments on multiple datasets. Experimental results demonstrate, under FGSM attack with $\epsilon=8/255$, the SBFM integrated models can achieve averagely 35\% higher accuracy than the original ones, and in CIFAR-10 and TinyImageNet datasets, the SBFM integrated models can achieve averagely 75\% classification accuracy. The work in this paper shows it is promising to enhance the robustness of DCNN models through feature learning.
Dense RGB SLAM with Neural Implicit Maps
Jan 21, 2023There is an emerging trend of using neural implicit functions for map representation in Simultaneous Localization and Mapping (SLAM). Some pioneer works have achieved encouraging results on RGB-D SLAM. In this paper, we present a dense RGB SLAM method with neural implicit map representation. To reach this challenging goal without depth input, we introduce a hierarchical feature volume to facilitate the implicit map decoder. This design effectively fuses shape cues across different scales to facilitate map reconstruction. Our method simultaneously solves the camera motion and the neural implicit map by matching the rendered and input video frames. To facilitate optimization, we further propose a photometric warping loss in the spirit of multi-view stereo to better constrain the camera pose and scene geometry. We evaluate our method on commonly used benchmarks and compare it with modern RGB and RGB-D SLAM systems. Our method achieves favorable results than previous methods and even surpasses some recent RGB-D SLAM methods. Our source code will be publicly available.
RAGO: Recurrent Graph Optimizer For Multiple Rotation Averaging
Dec 14, 2022This paper proposes a deep recurrent Rotation Averaging Graph Optimizer (RAGO) for Multiple Rotation Averaging (MRA). Conventional optimization-based methods usually fail to produce accurate results due to corrupted and noisy relative measurements. Recent learning-based approaches regard MRA as a regression problem, while these methods are sensitive to initialization due to the gauge freedom problem. To handle these problems, we propose a learnable iterative graph optimizer minimizing a gauge-invariant cost function with an edge rectification strategy to mitigate the effect of inaccurate measurements. Our graph optimizer iteratively refines the global camera rotations by minimizing each node's single rotation objective function. Besides, our approach iteratively rectifies relative rotations to make them more consistent with the current camera orientations and observed relative rotations. Furthermore, we employ a gated recurrent unit to improve the result by tracing the temporal information of the cost graph. Our framework is a real-time learning-to-optimize rotation averaging graph optimizer with a tiny size deployed for real-world applications. RAGO outperforms previous traditional and deep methods on real-world and synthetic datasets. The code is available at https://github.com/sfu-gruvi-3dv/RAGO
* Accepted by CVPR 2022
NeuMap: Neural Coordinate Mapping by Auto-Transdecoder for Camera Localization
Nov 21, 2022



This paper presents an end-to-end neural mapping method for camera localization, encoding a whole scene into a grid of latent codes, with which a Transformer-based auto-decoder regresses 3D coordinates of query pixels. State-of-the-art camera localization methods require each scene to be stored as a 3D point cloud with per-point features, which takes several gigabytes of storage per scene. While compression is possible, the performance drops significantly at high compression rates. NeuMap achieves extremely high compression rates with minimal performance drop by using 1) learnable latent codes to store scene information and 2) a scene-agnostic Transformer-based auto-decoder to infer coordinates for a query pixel. The scene-agnostic network design also learns robust matching priors by training with large-scale data, and further allows us to just optimize the codes quickly for a new scene while fixing the network weights. Extensive evaluations with five benchmarks show that NeuMap outperforms all the other coordinate regression methods significantly and reaches similar performance as the feature matching methods while having a much smaller scene representation size. For example, NeuMap achieves 39.1% accuracy in Aachen night benchmark with only 6MB of data, while other compelling methods require 100MB or a few gigabytes and fail completely under high compression settings. The codes are available at https://github.com/Tangshitao/NeuMap.
Streaming Radiance Fields for 3D Video Synthesis
Oct 26, 2022We present an explicit-grid based method for efficiently reconstructing streaming radiance fields for novel view synthesis of real world dynamic scenes. Instead of training a single model that combines all the frames, we formulate the dynamic modeling problem with an incremental learning paradigm in which per-frame model difference is trained to complement the adaption of a base model on the current frame. By exploiting the simple yet effective tuning strategy with narrow bands, the proposed method realizes a feasible framework for handling video sequences on-the-fly with high training efficiency. The storage overhead induced by using explicit grid representations can be significantly reduced through the use of model difference based compression. We also introduce an efficient strategy to further accelerate model optimization for each frame. Experiments on challenging video sequences demonstrate that our approach is capable of achieving a training speed of 15 seconds per-frame with competitive rendering quality, which attains $1000 \times$ speedup over the state-of-the-art implicit methods. Code is available at https://github.com/AlgoHunt/StreamRF.
DART: Articulated Hand Model with Diverse Accessories and Rich Textures
Oct 14, 2022
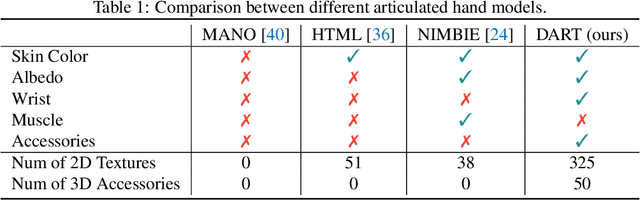


Hand, the bearer of human productivity and intelligence, is receiving much attention due to the recent fever of digital twins. Among different hand morphable models, MANO has been widely used in vision and graphics community. However, MANO disregards textures and accessories, which largely limits its power to synthesize photorealistic hand data. In this paper, we extend MANO with Diverse Accessories and Rich Textures, namely DART. DART is composed of 50 daily 3D accessories which varies in appearance and shape, and 325 hand-crafted 2D texture maps covers different kinds of blemishes or make-ups. Unity GUI is also provided to generate synthetic hand data with user-defined settings, e.g., pose, camera, background, lighting, textures, and accessories. Finally, we release DARTset, which contains large-scale (800K), high-fidelity synthetic hand images, paired with perfect-aligned 3D labels. Experiments demonstrate its superiority in diversity. As a complement to existing hand datasets, DARTset boosts the generalization in both hand pose estimation and mesh recovery tasks. Raw ingredients (textures, accessories), Unity GUI, source code and DARTset are publicly available at dart2022.github.io
Domain Randomization-Enhanced Depth Simulation and Restoration for Perceiving and Grasping Specular and Transparent Objects
Aug 07, 2022Commercial depth sensors usually generate noisy and missing depths, especially on specular and transparent objects, which poses critical issues to downstream depth or point cloud-based tasks. To mitigate this problem, we propose a powerful RGBD fusion network, SwinDRNet, for depth restoration. We further propose Domain Randomization-Enhanced Depth Simulation (DREDS) approach to simulate an active stereo depth system using physically based rendering and generate a large-scale synthetic dataset that contains 130K photorealistic RGB images along with their simulated depths carrying realistic sensor noises. To evaluate depth restoration methods, we also curate a real-world dataset, namely STD, that captures 30 cluttered scenes composed of 50 objects with different materials from specular, transparent, to diffuse. Experiments demonstrate that the proposed DREDS dataset bridges the sim-to-real domain gap such that, trained on DREDS, our SwinDRNet can seamlessly generalize to other real depth datasets, e.g. ClearGrasp, and outperform the competing methods on depth restoration with a real-time speed. We further show that our depth restoration effectively boosts the performance of downstream tasks, including category-level pose estimation and grasping tasks. Our data and code are available at https://github.com/PKU-EPIC/DREDS
RenderNet: Visual Relocalization Using Virtual Viewpoints in Large-Scale Indoor Environments
Jul 26, 2022
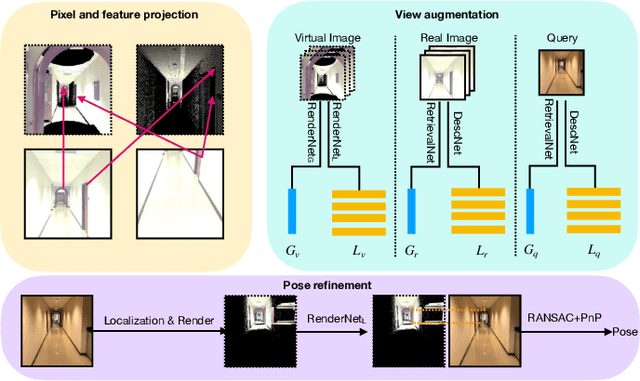
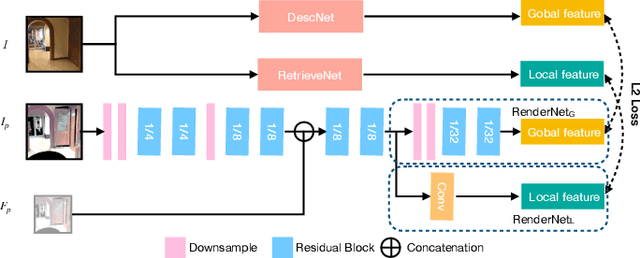

Visual relocalization has been a widely discussed problem in 3D vision: given a pre-constructed 3D visual map, the 6 DoF (Degrees-of-Freedom) pose of a query image is estimated. Relocalization in large-scale indoor environments enables attractive applications such as augmented reality and robot navigation. However, appearance changes fast in such environments when the camera moves, which is challenging for the relocalization system. To address this problem, we propose a virtual view synthesis-based approach, RenderNet, to enrich the database and refine poses regarding this particular scenario. Instead of rendering real images which requires high-quality 3D models, we opt to directly render the needed global and local features of virtual viewpoints and apply them in the subsequent image retrieval and feature matching operations respectively. The proposed method can largely improve the performance in large-scale indoor environments, e.g., achieving an improvement of 7.1\% and 12.2\% on the Inloc dataset.
Unseen Object 6D Pose Estimation: A Benchmark and Baselines
Jun 23, 2022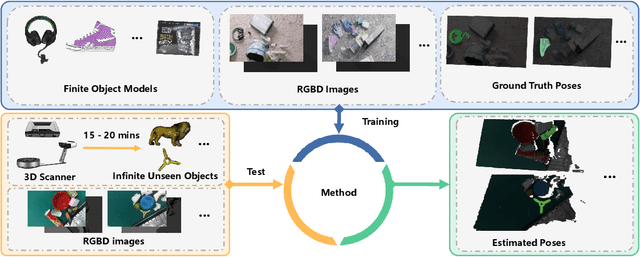
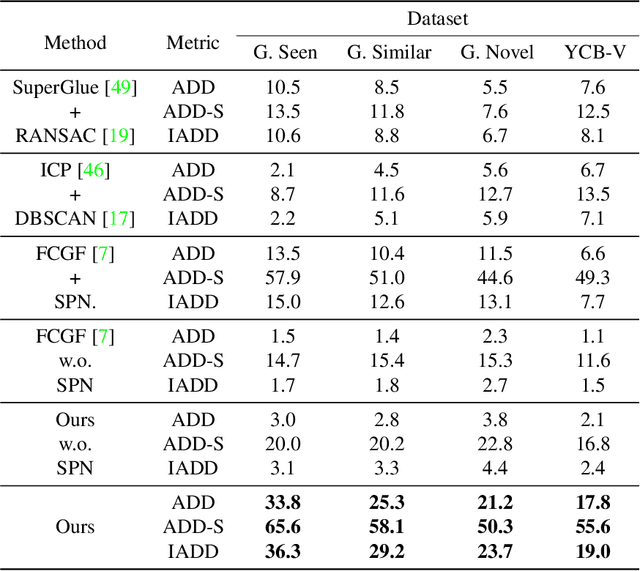

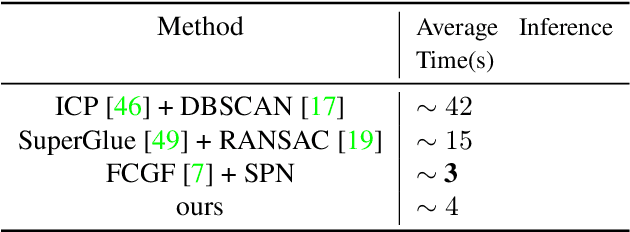
Estimating the 6D pose for unseen objects is in great demand for many real-world applications. However, current state-of-the-art pose estimation methods can only handle objects that are previously trained. In this paper, we propose a new task that enables and facilitates algorithms to estimate the 6D pose estimation of novel objects during testing. We collect a dataset with both real and synthetic images and up to 48 unseen objects in the test set. In the mean while, we propose a new metric named Infimum ADD (IADD) which is an invariant measurement for objects with different types of pose ambiguity. A two-stage baseline solution for this task is also provided. By training an end-to-end 3D correspondences network, our method finds corresponding points between an unseen object and a partial view RGBD image accurately and efficiently. It then calculates the 6D pose from the correspondences using an algorithm robust to object symmetry. Extensive experiments show that our method outperforms several intuitive baselines and thus verify its effectiveness. All the data, code and models will be made publicly available. Project page: www.graspnet.net/unseen6d