 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Event Classification Using Imperfect Real-world PMU Data
Oct 19, 2021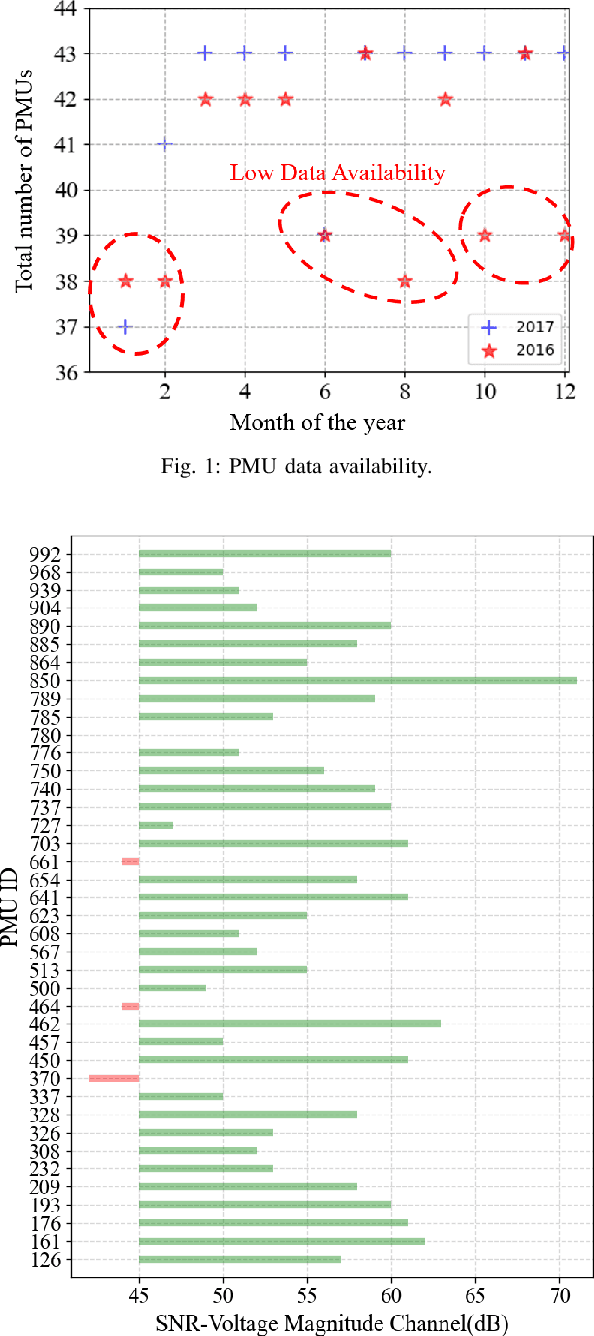
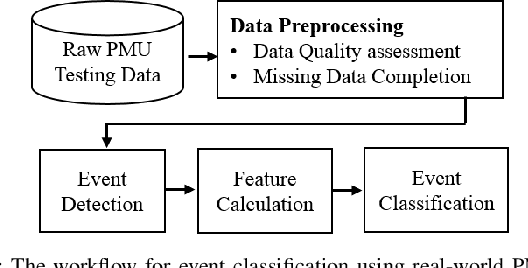
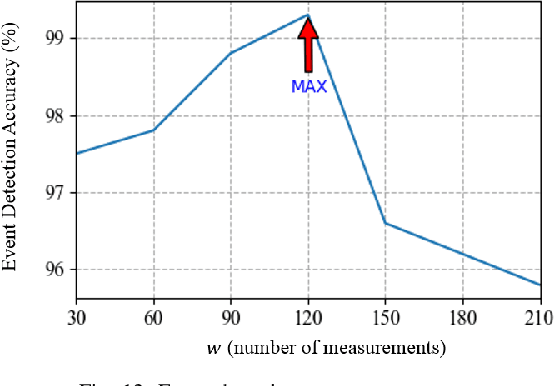
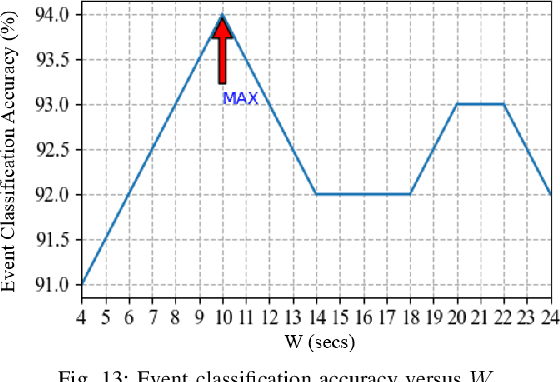
This paper studies robust event classification using imperfect real-world phasor measurement unit (PMU) data. By analyzing the real-world PMU data, we find it is challenging to directly use this dataset for event classifiers due to the low data quality observed in PMU measurements and event logs. To address these challenges, we develop a novel machine learning framework for training robust event classifiers, which consists of three main steps: data preprocessing, fine-grained event data extraction, and feature engineering. Specifically, the data preprocessing step addresses the data quality issues of PMU measurements (e.g., bad data and missing data); in the fine-grained event data extraction step, a model-free event detection method is developed to accurately localize the events from the inaccurate event timestamps in the event logs; and the feature engineering step constructs the event features based on the patterns of different event types, in order to improve the performance and the interpretability of the event classifiers. Based on the proposed framework, we develop a workflow for event classification using the real-world PMU data streaming into the system in real-time. Using the proposed framework, robust event classifiers can be efficiently trained based on many off-the-shelf lightweight machine learning models. Numerical experiments using the real-world dataset from the Western Interconnection of the U.S power transmission grid show that the event classifiers trained under the proposed framework can achieve high classification accuracy while being robust against low-quality data.
QTN-VQC: An End-to-End Learning framework for Quantum Neural Networks
Oct 12, 2021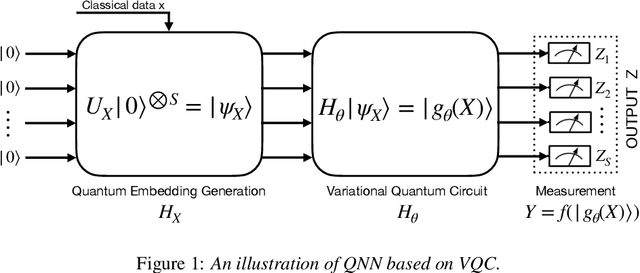
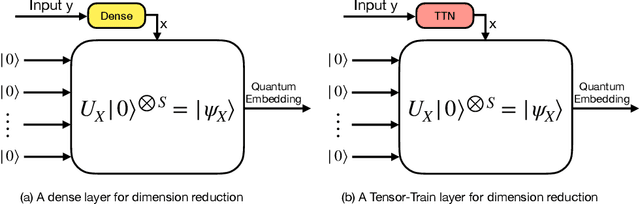

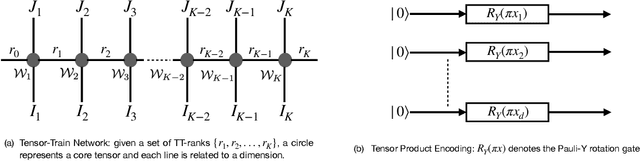
The advent of noisy intermediate-scale quantum (NISQ) computers raises a crucial challenge to design quantum neural networks for fully quantum learning tasks. To bridge the gap, this work proposes an end-to-end learning framework named QTN-VQC, by introducing a trainable quantum tensor network (QTN) for quantum embedding on a variational quantum circuit (VQC). The architecture of QTN is composed of a parametric tensor-train network for feature extraction and a tensor product encoding for quantum encoding. We highlight the QTN for quantum embedding in terms of two perspectives: (1) we theoretically characterize QTN by analyzing its representation power of input features; (2) QTN enables an end-to-end parametric model pipeline, namely QTN-VQC, from the generation of quantum embedding to the output measurement. Our experiments on the MNIST dataset demonstrate the advantages of QTN for quantum embedding over other quantum embedding approaches.
Why Lottery Ticket Wins? A Theoretical Perspective of Sample Complexity on Pruned Neural Networks
Oct 12, 2021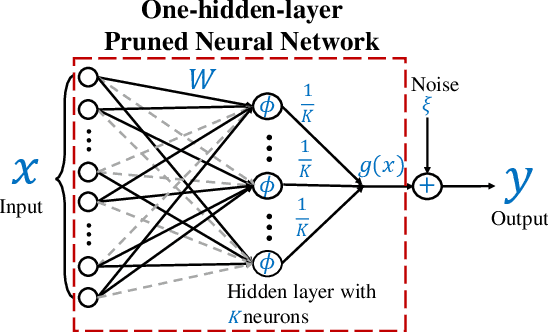
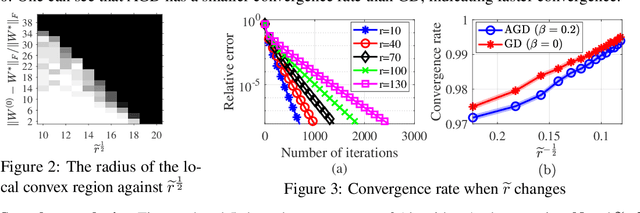
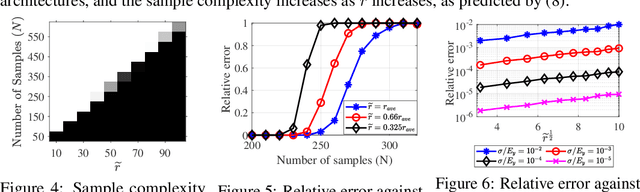
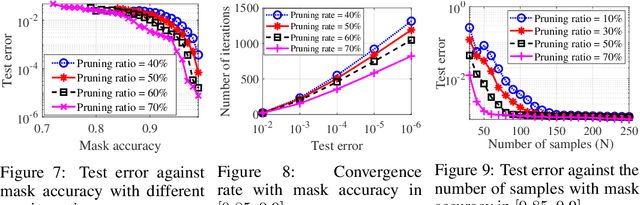
The \textit{lottery ticket hypothesis} (LTH) states that learning on a properly pruned network (the \textit{winning ticket}) improves test accuracy over the original unpruned network. Although LTH has been justified empirically in a broad range of deep neural network (DNN) involved applications like computer vision and natural language processing, the theoretical validation of the improved generalization of a winning ticket remains elusive. To the best of our knowledge, our work, for the first time, characterizes the performance of training a pruned neural network by analyzing the geometric structure of the objective function and the sample complexity to achieve zero generalization error. We show that the convex region near a desirable model with guaranteed generalization enlarges as the neural network model is pruned, indicating the structural importance of a winning ticket. Moreover, when the algorithm for training a pruned neural network is specified as an (accelerated) stochastic gradient descent algorithm, we theoretically show that the number of samples required for achieving zero generalization error is proportional to the number of the non-pruned weights in the hidden layer. With a fixed number of samples, training a pruned neural network enjoys a faster convergence rate to the desired model than training the original unpruned one, providing a formal justification of the improved generalization of the winning ticket. Our theoretical results are acquired from learning a pruned neural network of one hidden layer, while experimental results are further provided to justify the implications in pruning multi-layer neural networks.
A Study of Low-Resource Speech Commands Recognition based on Adversarial Reprogramming
Oct 08, 2021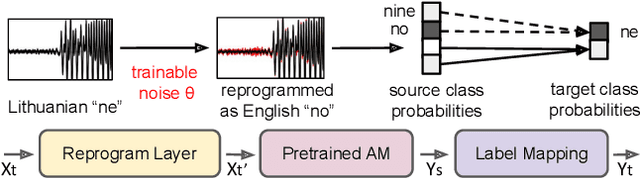
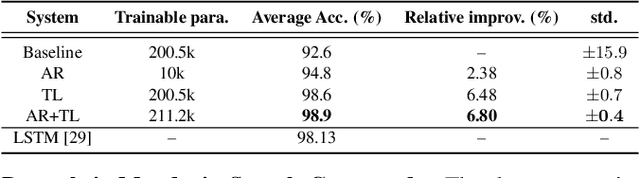
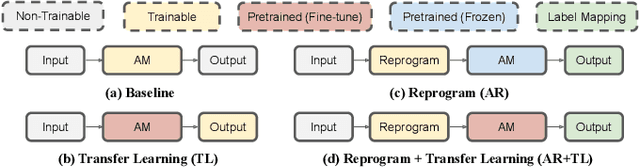
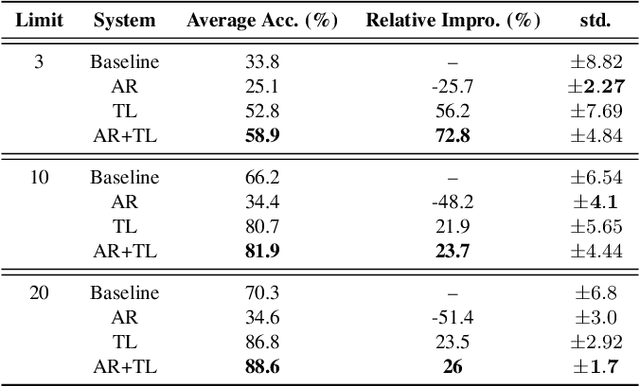
In this study, we propose a novel adversarial reprogramming (AR) approach for low-resource spoken command recognition (SCR), and build an AR-SCR system. The AR procedure aims to modify the acoustic signals (from the target domain) to repurpose a pretrained SCR model (from the source domain). To solve the label mismatches between source and target domains, and further improve the stability of AR, we propose a novel similarity-based label mapping technique to align classes. In addition, the transfer learning (TL) technique is combined with the original AR process to improve the model adaptation capability. We evaluate the proposed AR-SCR system on three low-resource SCR datasets, including Arabic, Lithuanian, and dysarthric Mandarin speech. Experimental results show that with a pretrained AM trained on a large-scale English dataset, the proposed AR-SCR system outperforms the current state-of-the-art results on Arabic and Lithuanian speech commands datasets, with only a limited amount of training data.
AI Explainability 360: Impact and Design
Sep 24, 2021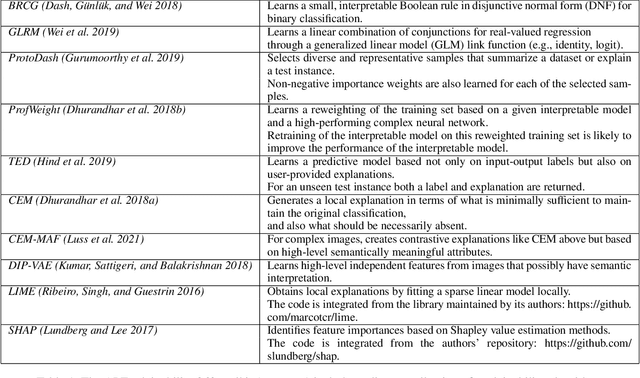
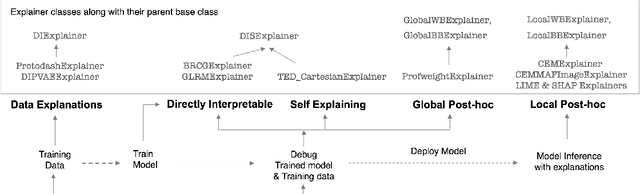

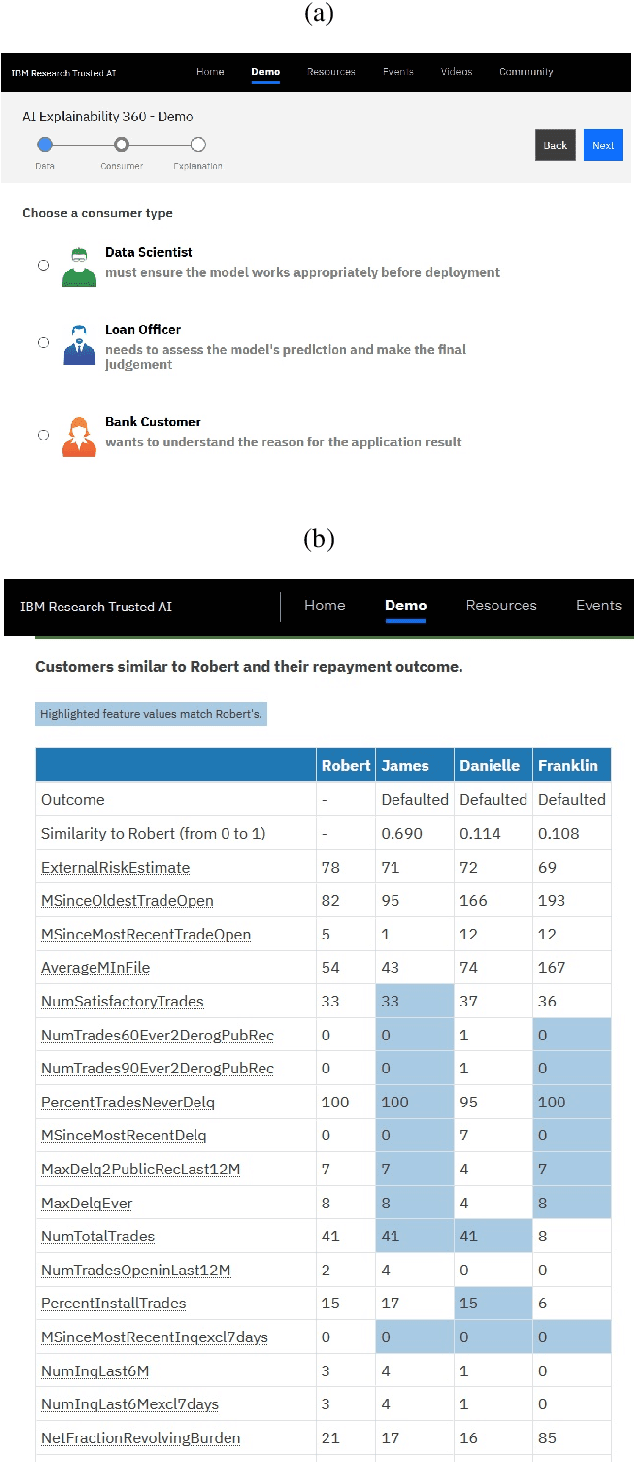
As artificial intelligence and machine learning algorithms become increasingly prevalent in society, multiple stakeholders are calling for these algorithms to provide explanations. At the same time, these stakeholders, whether they be affected citizens, government regulators, domain experts, or system developers, have different explanation needs. To address these needs, in 2019, we created AI Explainability 360 (Arya et al. 2020), an open source software toolkit featuring ten diverse and state-of-the-art explainability methods and two evaluation metrics. This paper examines the impact of the toolkit with several case studies, statistics, and community feedback. The different ways in which users have experienced AI Explainability 360 have resulted in multiple types of impact and improvements in multiple metrics, highlighted by the adoption of the toolkit by the independent LF AI & Data Foundation. The paper also describes the flexible design of the toolkit, examples of its use, and the significant educational material and documentation available to its users.
Real-World Adversarial Examples involving Makeup Application
Sep 04, 2021
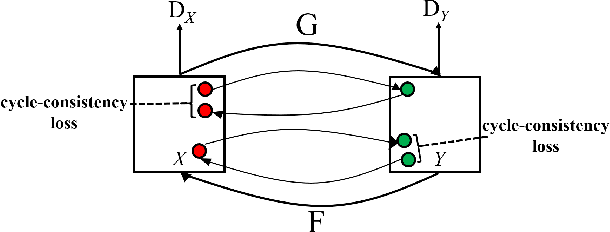
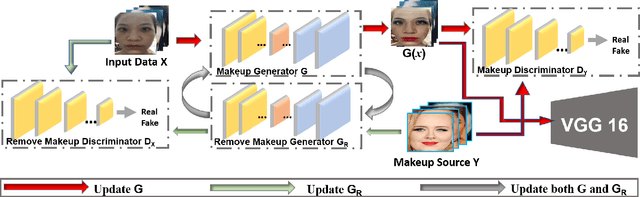

Deep neural networks have developed rapidly and have achieved outstanding performance in several tasks, such as image classification and natural language processing. However, recent studies have indicated that both digital and physical adversarial examples can fool neural networks. Face-recognition systems are used in various applications that involve security threats from physical adversarial examples. Herein, we propose a physical adversarial attack with the use of full-face makeup. The presence of makeup on the human face is a reasonable possibility, which possibly increases the imperceptibility of attacks. In our attack framework, we combine the cycle-adversarial generative network (cycle-GAN) and a victimized classifier. The Cycle-GAN is used to generate adversarial makeup, and the architecture of the victimized classifier is VGG 16. Our experimental results show that our attack can effectively overcome manual errors in makeup application, such as color and position-related errors. We also demonstrate that the approaches used to train the models can influence physical attacks; the adversarial perturbations crafted from the pre-trained model are affected by the corresponding training data.
Understanding the Limits of Unsupervised Domain Adaptation via Data Poisoning
Jul 08, 2021
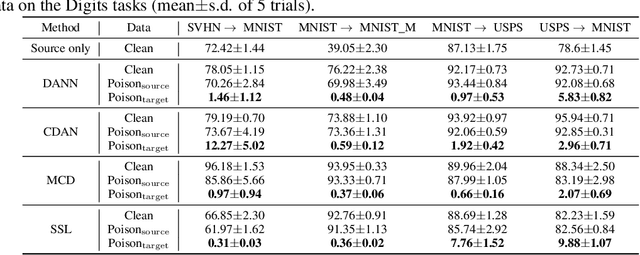
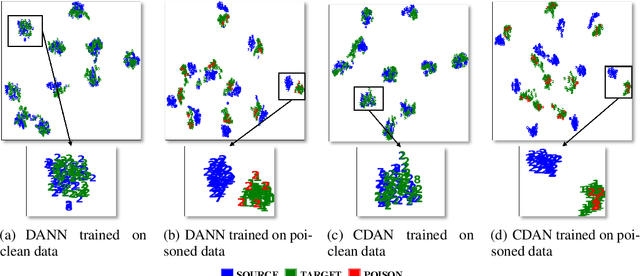
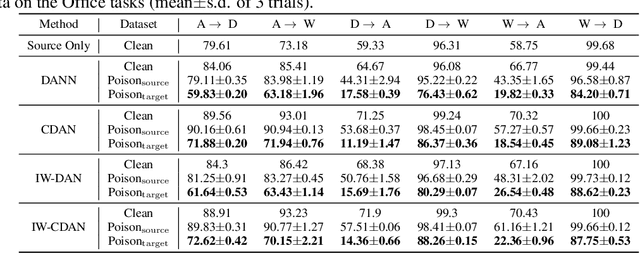
Unsupervised domain adaptation (UDA) enables cross-domain learning without target domain labels by transferring knowledge from a labeled source domain whose distribution differs from the target. However, UDA is not always successful and several accounts of "negative transfer" have been reported in the literature. In this work, we prove a simple lower bound on the target domain error that complements the existing upper bound. Our bound shows the insufficiency of minimizing source domain error and marginal distribution mismatch for a guaranteed reduction in the target domain error, due to the possible increase of induced labeling function mismatch. This insufficiency is further illustrated through simple distributions for which the same UDA approach succeeds, fails, and may succeed or fail with an equal chance. Motivated from this, we propose novel data poisoning attacks to fool UDA methods into learning representations that produce large target domain errors. We evaluate the effect of these attacks on popular UDA methods using benchmark datasets where they have been previously shown to be successful. Our results show that poisoning can significantly decrease the target domain accuracy, dropping it to almost 0\% in some cases, with the addition of only 10\% poisoned data in the source domain. The failure of UDA methods demonstrates the limitations of UDA at guaranteeing cross-domain generalization consistent with the lower bound. Thus, evaluation of UDA methods in adversarial settings such as data poisoning can provide a better sense of their robustness in scenarios unfavorable for UDA.
MAML is a Noisy Contrastive Learner
Jun 29, 2021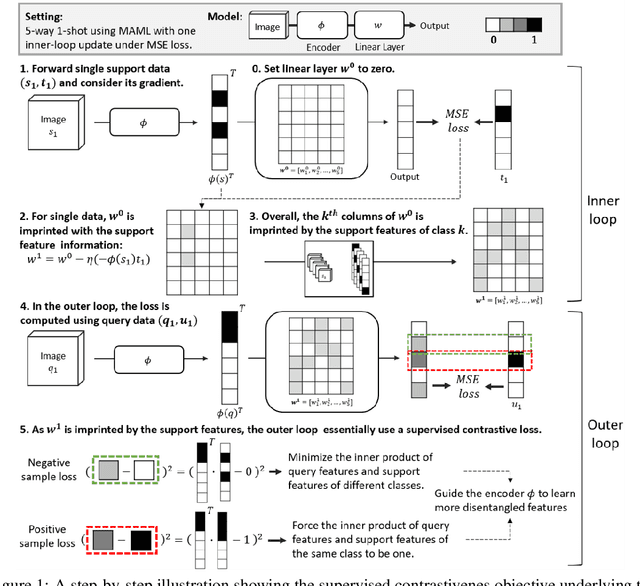
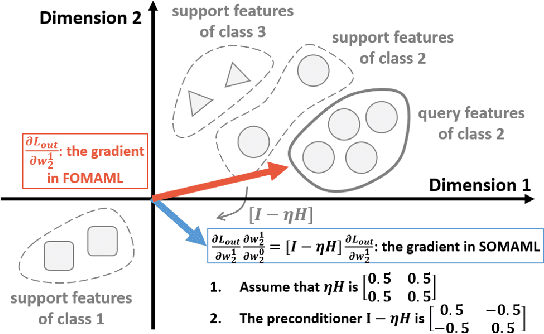
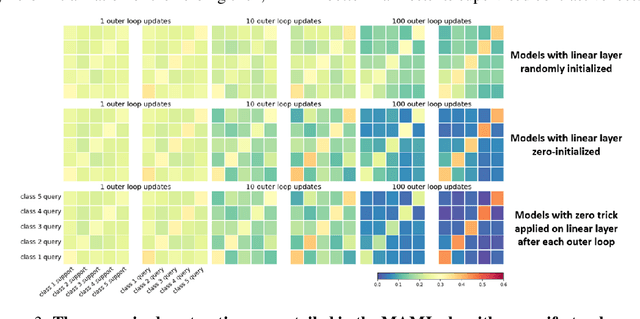
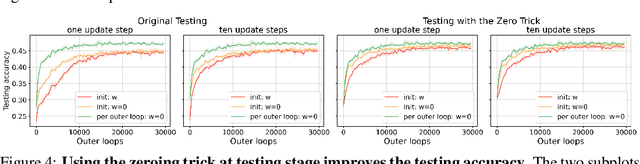
Model-agnostic meta-learning (MAML) is one of the most popular and widely-adopted meta-learning algorithms nowadays, which achieves remarkable success in various learning problems. Yet, with the unique design of nested inner-loop and outer-loop updates which respectively govern the task-specific and meta-model-centric learning, the underlying learning objective of MAML still remains implicit and thus impedes a more straightforward understanding of it. In this paper, we provide a new perspective to the working mechanism of MAML and discover that: MAML is analogous to a meta-learner using a supervised contrastive objective function, where the query features are pulled towards the support features of the same class and against those of different classes, in which such contrastiveness is experimentally verified via an analysis based on the cosine similarity. Moreover, our analysis reveals that the vanilla MAML algorithm has an undesirable interference term originating from the random initialization and the cross-task interaction. We therefore propose a simple but effective technique, zeroing trick, to alleviate such interference, where the extensive experiments are then conducted on both miniImagenet and Omniglot datasets to demonstrate the consistent improvement brought by our proposed technique thus well validating its effectiveness.
Fold2Seq: A Joint Sequence(1D)-Fold(3D) Embedding-based Generative Model for Protein Design
Jun 24, 2021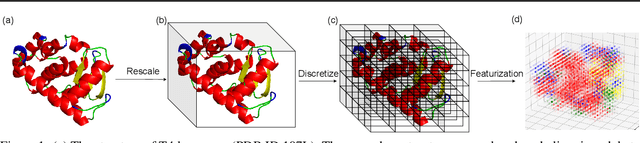
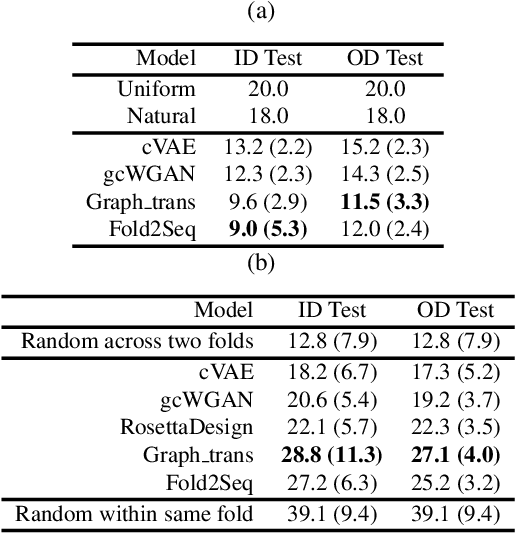
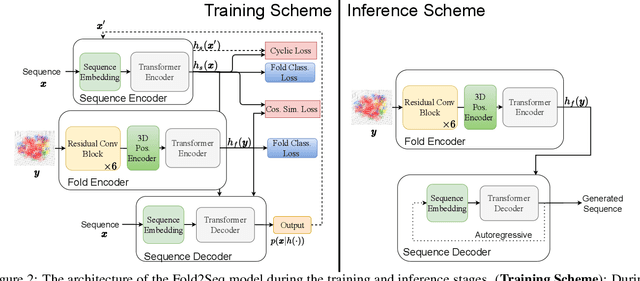
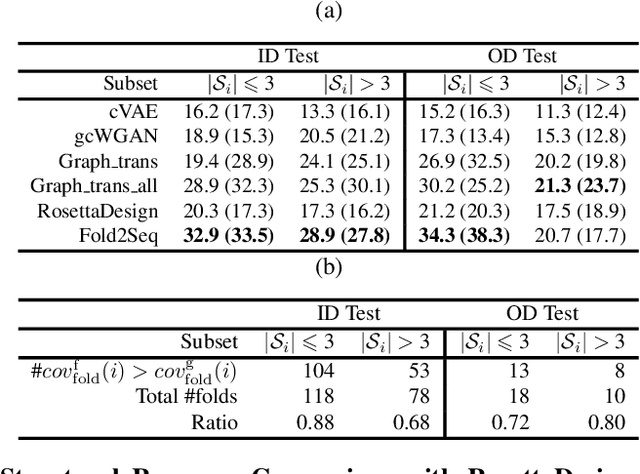
Designing novel protein sequences for a desired 3D topological fold is a fundamental yet non-trivial task in protein engineering. Challenges exist due to the complex sequence--fold relationship, as well as the difficulties to capture the diversity of the sequences (therefore structures and functions) within a fold. To overcome these challenges, we propose Fold2Seq, a novel transformer-based generative framework for designing protein sequences conditioned on a specific target fold. To model the complex sequence--structure relationship, Fold2Seq jointly learns a sequence embedding using a transformer and a fold embedding from the density of secondary structural elements in 3D voxels. On test sets with single, high-resolution and complete structure inputs for individual folds, our experiments demonstrate improved or comparable performance of Fold2Seq in terms of speed, coverage, and reliability for sequence design, when compared to existing state-of-the-art methods that include data-driven deep generative models and physics-based RosettaDesign. The unique advantages of fold-based Fold2Seq, in comparison to a structure-based deep model and RosettaDesign, become more evident on three additional real-world challenges originating from low-quality, incomplete, or ambiguous input structures. Source code and data are available at https://github.com/IBM/fold2seq.
Voice2Series: Reprogramming Acoustic Models for Time Series Classification
Jun 17, 2021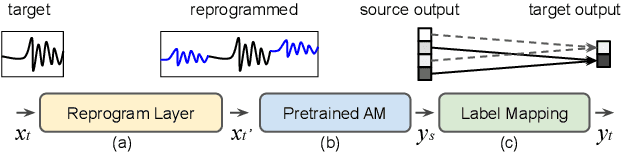

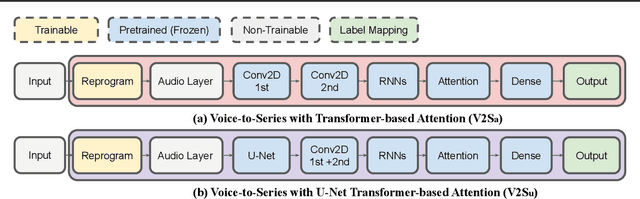
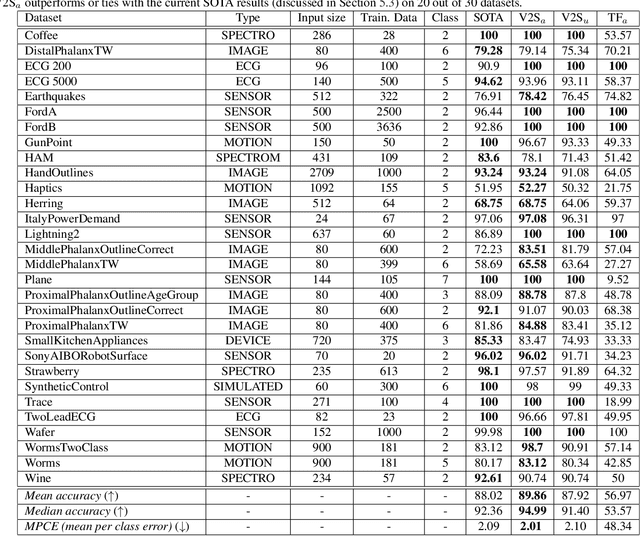
Learning to classify time series with limited data is a practical yet challenging problem. Current methods are primarily based on hand-designed feature extraction rules or domain-specific data augmentation. Motivated by the advances in deep speech processing models and the fact that voice data are univariate temporal signals, in this paper, we propose Voice2Series (V2S), a novel end-to-end approach that reprograms acoustic models for time series classification, through input transformation learning and output label mapping. Leveraging the representation learning power of a large-scale pre-trained speech processing model, on 30 different time series tasks we show that V2S either outperforms or is tied with state-of-the-art methods on 20 tasks, and improves their average accuracy by 1.84%. We further provide a theoretical justification of V2S by proving its population risk is upper bounded by the source risk and a Wasserstein distance accounting for feature alignment via reprogramming. Our results offer new and effective means to time series classification.